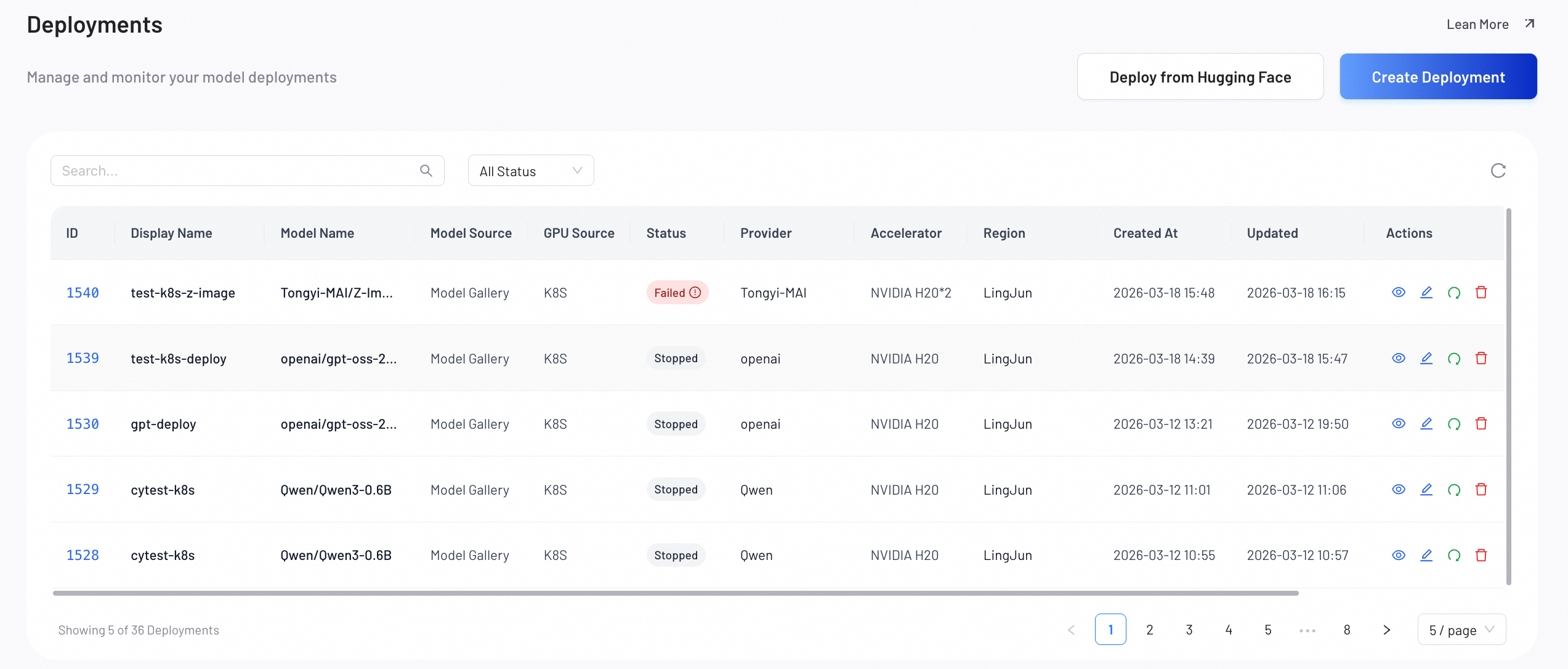
本文介紹了小程式叢集對接方案如何部署 Hugging Face 上的模型。
前提條件
開始之前,請確保您已準備好以下內容:
Hugging Face Model ID:您要部署的模型的唯一識別碼。
Hugging Face Access Token:(可選)僅在模型為私人或受限訪問時需要。
第一步:填寫模型資訊
Model ID:輸入 Hugging Face Model ID。
前往 Hugging Face Model Hub 瀏覽模型。
點擊您想使用的模型。
從頁面 URL 中複製倉庫名稱,格式為:
org-or-username/model-name。
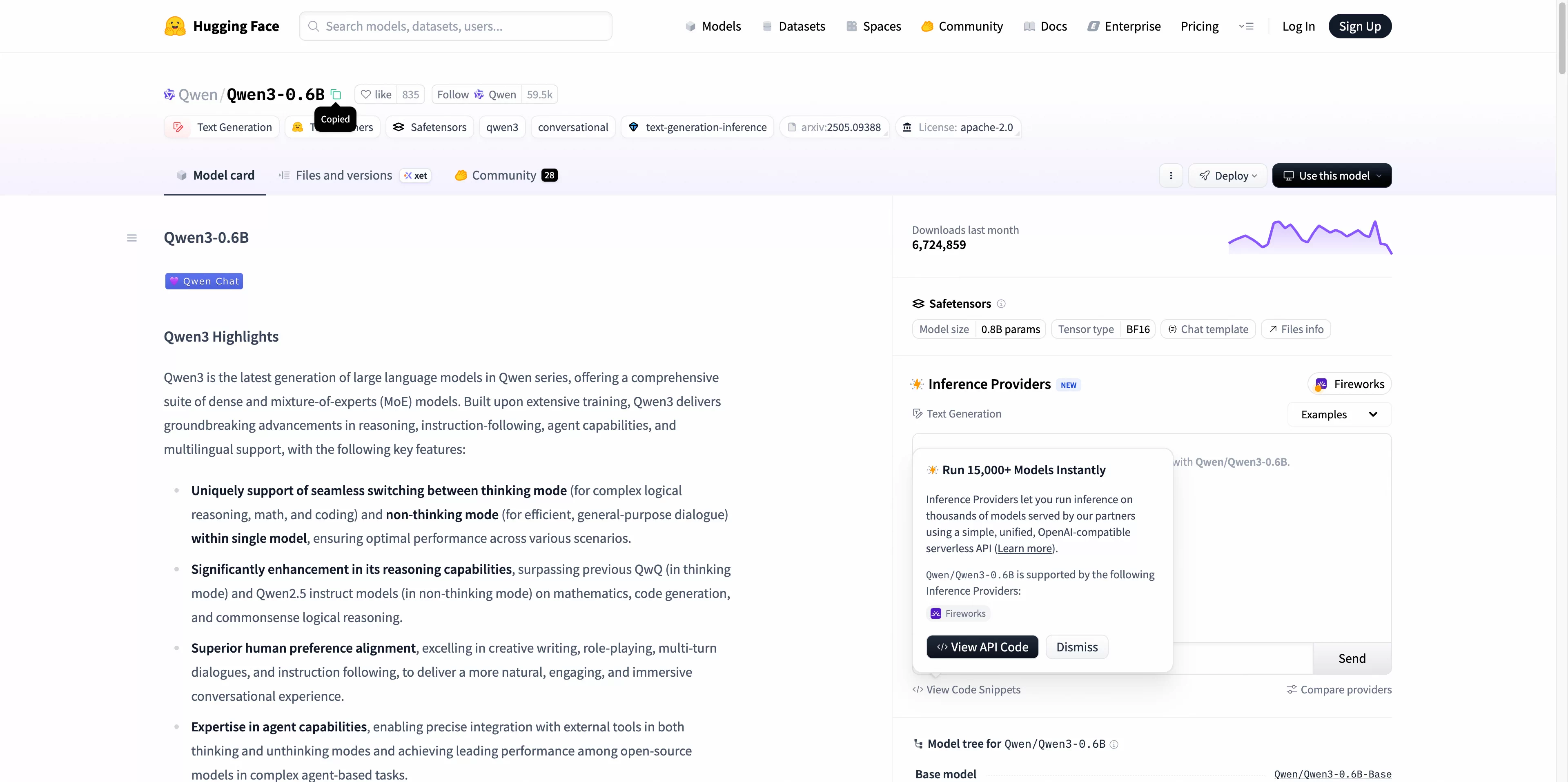
類型:選擇
LLM、VLM、Text-to-Image、Image-to-Image、Text-to-Video或Image-to-Video。架構:選擇推理架構(如 vLLM、SGLang)。
版本:選擇架構版本。
Access Token(可選):如果模型為私人模型,請在此處粘貼您的 Access Token。
 完成後,點擊 「分析模型」 繼續。
完成後,點擊 「分析模型」 繼續。
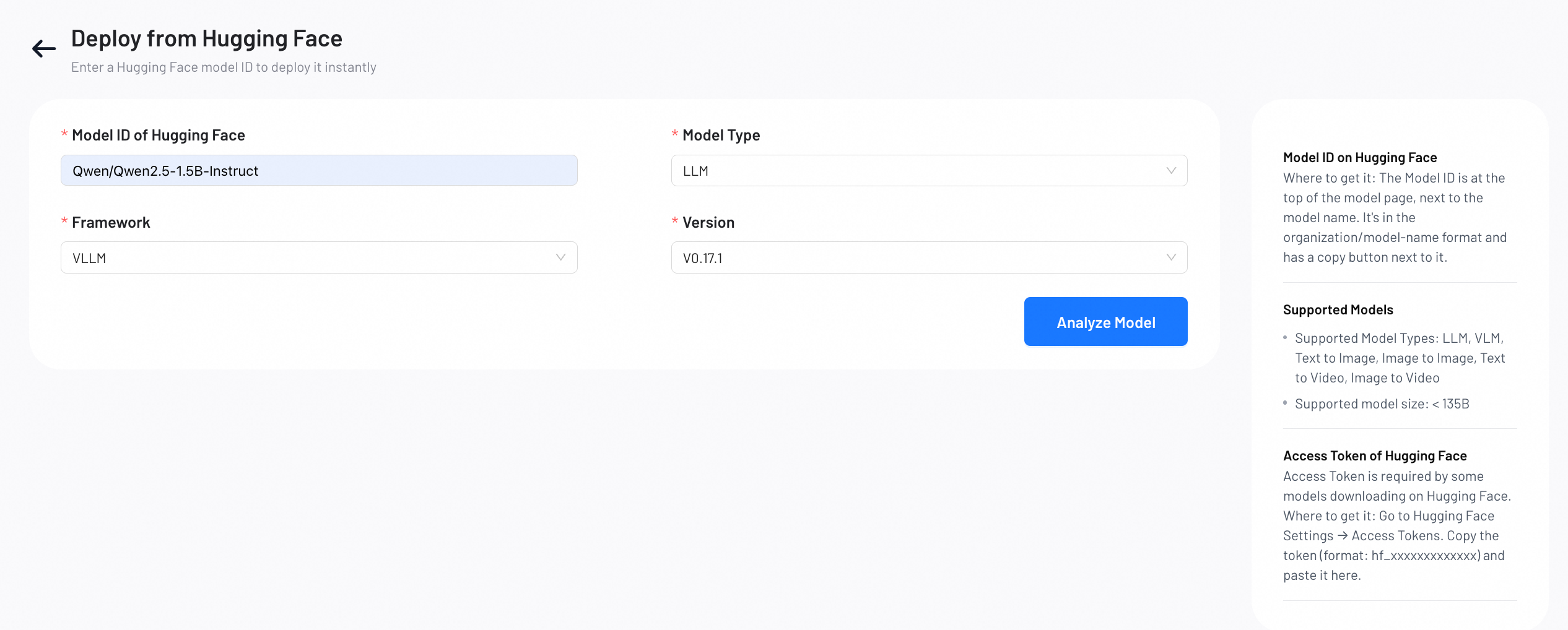
第二步:配置並確認部署
查看模型資訊,並完成部署設定。
顯示名稱:為您的部署指定一個描述性名稱。
GPU 類型:為您的模型選擇合適的 GPU 類型。
說明:可用的 GPU 類型及庫存因地區而異。如果您所在地區暫無所需 GPU,可聯絡我們尋求協助。
部署命令:用於啟動模型服務的命令。
如何配置:
參考您所使用容器鏡像的文檔,擷取所需的啟動命令。
對於 Hugging Face Text Generation Inference 鏡像,常用樣本如下:text-generation-launcher --model-id <model-id> --port 8080
將 <model-id> 替換為您的 Hugging Face 模型倉庫 ID。
容器鏡像:包含部署模型所需完整運行環境的 Docker 或 OCI 鏡像。可從以下選項中選擇:
推薦鏡像:平台根據您的模型和架構自動選擇的最佳化鏡像,推薦大多數使用者使用。
Hugging Face 鏡像:
來自 Hugging Face 容器登錄(ghcr.io)的官方推理鏡像。詳情請參閱文檔。
自訂鏡像:如果您自行構建的鏡像滿足模型運行環境要求,也可以使用自訂鏡像。
副本數量:啟動並執行模型執行個體數量。副本數越多,負載平衡效果越好,可用性越高。
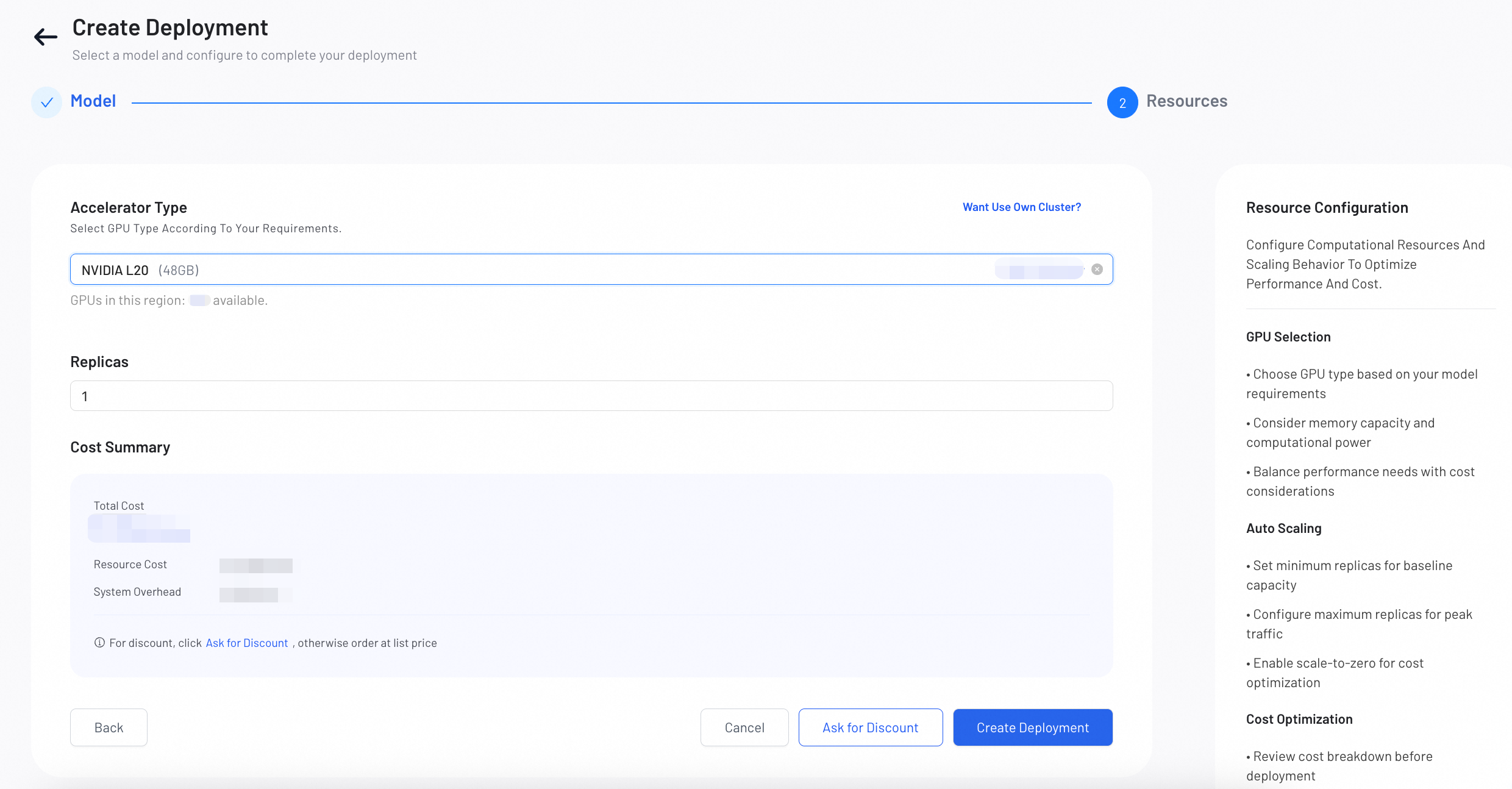
確認並部署
費用概覽
GPU 計算費用
系統開銷(當前為 $0)
說明:模型下載與儲存費用不計入費用概覽。如需申請折扣,請點擊「申請折扣」,否則將按標準定價收費。
第三步:監控狀態與故障排查
部署完成後,本步驟將指導您如何查看部署狀態,並在服務出現問題時進行故障排查。
部署狀態說明
以下是您的部署可能經歷的各種狀態:
下載中:系統正在從來源下載模型檔案。
部署中:系統正在分配 GPU、啟動容器並執行部署命令。
運行中:服務已上線,狀態健康,可接受推理請求。
失敗:部署過程中發生錯誤,服務未能成功啟動。
停止中:服務正在關閉並釋放相關資源。
已停止:服務已下線,不再佔用任何 GPU 資源。