本文從營運和SRE團隊角度介紹監控分析平台的建設與選擇。
背景資訊
營運和SRE團隊承載著重要的職責,其工作內容複雜而廣泛,從應用部署、效能和可用性監控、警示、值班,到容量規劃、業務支撐等都有涉及。隨著雲原生、容器化和微服務的快速發展,迭代節奏愈發加快,營運和SRE團隊面臨更多挑戰,營運和SRE團隊面臨常見的困境如下:
業務線廣泛
業務線分布廣泛,包括用戶端、前端Web、應用後端。
同時支援幾條甚至數十條業務線。
人力嚴重短缺
相對開發人員,不少公司的營運和SRE團隊人員不到1%,甚至更低。
線上穩定性壓力大
經常扮演救火隊員的角色。
業務複雜、組件眾多,快速排障和業務恢複的難度陡增。
缺乏統一而有效監控分析平台
從不同的維度對各類資料進行監控,指令碼泛濫、工具眾多、煙囪林立。
各類資料落在不同的系統中,欠缺關聯分析,無法快速進行根因定位。
閾值警示缺乏靈活性,一個系統可能出現數千條警示規則,管理成本高昂,並且容易造成警示泛濫,引起誤判、漏判。
因此,一套簡單易用、高效、分析能力強的監控分析平台,對於提高營運和SRE團隊的工作效率、快速而準確進行根因定位、保證商務持續性至關重要。
監控分析平台需要解決的資料問題
營運和SRE團隊為了保證業務穩定和支援業務發展,需要對大量的資料進行採集和分析,包括機器硬體、網路指標、使用者行為等多方面的資料。在完成資料擷取後,還需要有一套合適的系統進行轉換、儲存、處理、分析,滿足多樣的需求。資料問題主要包括:
資料多樣
各類系統資料:cpu、mem、net、disk等通用硬體指標,系統日誌。
業務黃金指標:延時、流量、錯誤、飽和度。
業務訪問日誌:Access Log。
應用日誌:Java應用日誌、錯誤記錄檔。
使用者行為資料:Web click。
App埋點資料:Android、iOS App中埋點統計。
各類架構資料:被廣泛使用的K8s架構產生的資料。
服務調用鏈:各類Tracing資料。
需求多樣
對於各類資料,營運和SRE團隊不僅需要保障業務穩定,還需要支援其他業務團隊進行資料的使用,對於資料的使用也是多樣的,常見需求如下:
監控、警示:即時處理(流式,小批量),秒級~分鐘級延時。
客服、問題排查:快速檢索,例如通過關鍵詞過濾,秒級延時。
風控:即時資料流量處理,秒級延時。
營運、分析:大規模資料分析,如OLAP情境,秒級到小時級延時。
資源需求估算難
對於快速發展的業務,各類資料的規模在一開始是很難準確估算的,經常遇到:
新業務接入,資料量無準確估算參考。
業務快速發展,資料暴增。
資料使用需求變動,原有儲存方式,儲存時間不符合使用需求。
構建監控分析平台方案選擇
由於資料來源廣、樣式雜,需求多,營運和SRE團隊往往需要使用和維護多套系統,才能滿足多樣的監控和業務需求,常見的開源組合如下:
Telegraf+Influxdb+Grafana
Telegraf是一個輕量級的採集架構,通過豐富的外掛程式採集作業系統、資料庫、中介軟體等各類指標,配合Influxdb對時序資料進行高效讀寫、儲存和分析,然後在Grafana上進行可視化展示和互動式查詢。
Prometheus
在雲原生K8s的生態中,Prometheus基本上作為時序資料的標配,配合靈活的exporter可以非常方便地採集Metric資料,同時Prometheus也可以和Grafana整合。
ELK
在日誌資料多維度查詢和分析上,ELK套件是常用的開源組件,提供快速、靈活、強大的查詢能力,可滿足研發、營運、客服團隊的大部分查詢需求。
Tracing類工具
在微服務、分布式的系統中,請求調用鏈路複雜,沒有一套合適的Tracing系統,很難進行高效的問題根因定位,從Zipkin、Jaeger到逐漸形成行業標準的OpenTelemetry、SkyWalking都是不錯的Tracing系統,而這些Tracing系統並未提供資料存放區組件,需要配合ES或Cassandra來儲存Tracing資料。
Kafka+Flink
對於資料清洗、風控等需求,需要構建一套即時資料通道和流式系統,支撐資料的全量即時消費,一般使用Kafka和Flink組合。
ClickHouse、Presto、Druid
在營運分析、報表等情境中,為了追求更高的即時響應性,通常還會將資料匯入OLAP引擎,在秒級到分鐘級內完成海量資料分析需求,以及各類Adhoc的查詢。
不同組件面向不同的資料類型和處理需求,資料需要在其中流轉,有時候同一份資料需要同時儲存在多個系統中,增加系統複雜度和使用成本。
當資料越來越多,使用需求越來越廣時,保障這些組件的穩定性、滿足多種業務效能需求、進行有效成本控制,又要對大量業務線進行高效支撐,都是非常繁重而又有挑戰的工作。
監控分析平台的挑戰
能夠維護好多套系統又能有效支援眾多業務線,這是一個巨大的挑戰。
穩定性保障
依賴系統:資料在多套系統中流轉,系統之間又存在依賴關係,當某系統出現問題時,對其他系統造成影響。例如下遊ES系統寫入變慢後,用於快取資料的Kafka叢集儲存水位變高,可能導致叢集寫滿。
Burst問題:在互連網環境下,流量Burst是非常常見的情況。對於監控分析平台也一樣,當大量資料需要寫入系統時,保證系統不被壓垮,同時保證讀取功能正常運轉,是一項巨大的挑戰。
資源隔離:不同資料的優先順序有高低,如果過分依賴資源物理隔離將導致叢集資源嚴重浪費和營運成本極大提高,而當資料共用資源時,需要儘可能保證相互之間不受幹擾。例如某些系統中,一次超大規模的查詢,可能拖垮整個叢集。
技術門檻:各類系統都有大量參數需要調優,面對不同的情境和需求,調優模式也不盡相同,需要投入大量的時間和精力,根據實際情況進行對比和最佳化。
效能可預期
資料規模:對系統的效能有非常大的影響。例如時序資料在千萬級到億級時間軸下讀寫,ES在10億到100億行資料中的查詢效能保證,都非常有挑戰。
QoS控制:任意一個系統的硬體資源都是有限的,需要對不同資料的QPS、並發進行合理的分配和管理,必要時進行降級處理,否則某個業務的使用可能導致其他業務效能受損。而開源組件一般很少考慮QoS的控制。
成本控制
資源成本:各類組件的部署都需要消耗硬體資源,特別是當資料同時存在多個系統中的時候,硬體的資源消耗將更加嚴重。另外一個常見問題是很難準確估算業務的資料量。很多時候,採用相對保守手段來降低系統水位,這又將造成資源浪費。
接入成本:支援各企業營運資料接入也是一個繁重的工作,涉及到資料格式的適配、環境管理、配置設定和維護、資源估算等一系列工作,需要有工具或平台協助業務線自主完成,否則營運和SRE團隊將陷入大量的瑣事中。
支援成本:使用各種系統難免會遇到各類問題,必要的支援人員必不可缺,但問題種類多樣。例如使用模式不合適、參數配置不合理等。遇到開源軟體本身BUG導致的問題,又是一筆額外的成本。
營運成本:各系統的軟硬體難免會出故障,硬體替換、縮擴容、軟體版本升級,都需要投入不小的人力和精力。
費用分攤:只有將資源消耗清晰準確地分攤到實際業務線中,才能更有效利用資源,制定合理的預算和規劃。這也需要監控分析平台能提供有效計量資料進行費用分攤。
實際情境類比
業務背景
公司有100多應用,每個應用都有Nginx訪問日誌和Java應用服務日誌。
各應用日誌規模變化巨大,單日1 GB到1 TB不等,每天新增10 TB資料,需儲存7天~90天,平均15天。
日誌資料主要用於業務監控和警示、線上問題排查以及即時風控使用。
業務架構選型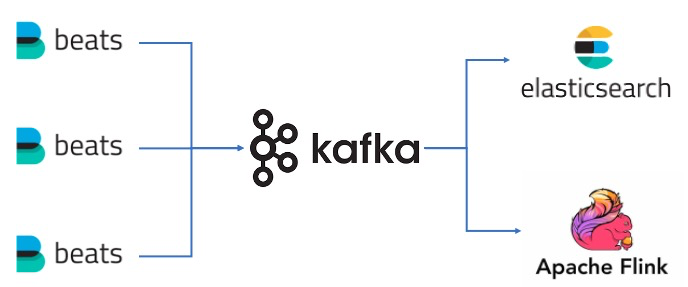
Beats:即時採集資料發送至Kafka。
Kafka:資料臨時儲存,用於Flink即時消費和匯入Elasticsearch。
Flink:對業務資料即時分析,進行即時監控、風控。
Elasticsearch:日誌查詢與分析,問題排查。
在以上看似簡單的架構中,也隱藏了大量細節需要關注,以ES為例:
容量規劃:未經處理資料*膨脹係數*(1+副本數)*(1+預留空間), 一般膨脹係數取1.1~1.3,1個副本,25%的預留(剩餘空間,臨時檔案等), 實際磁碟空間是原始空間的2.75~3.5倍。如果需要開啟_all參數設定,資料膨脹會更嚴重,也需要預留更多空間。
冷熱分離:所有資料全部儲存到SSD上,成本過高。需要根據資料的重要程度和時間因素,將部分索引資料直接儲存至HDD磁碟或使用Rollover功能遷移索引資料。
索引設定:每個應用的兩類日誌,分別按照時間周期性建立索引,根據資料大小合理設定Shard數,單Shard以30~50 GB為宜,但是各應用的日誌量很難準確估計,常在遇到寫入或查詢問題後再調整,然而重建索引的消耗又非常大。
Kafka消費設定:使用Logstash消費Kafka資料再寫入到ES,需要Kafka topic的partition數和logconsumer_threads相匹配,否則容易導致各partition消費不均。
ES參數調優:對寫入吞吐、可見度延時、資料安全性以及查詢效能等多方面因素進行綜合評估和權衡後,結合叢集CPU、記憶體,對ES一些列參數進行調優,才能更好發揮ES的特性。常見的參數包括線程數、記憶體控制、translog設定、隊列長度、各類操作的間隔interval、merge參數等。
記憶體:通常JVM堆記憶體大小在32 GB以內,剩餘的留給OS緩衝使用,如果頻繁GC會嚴重影響效能,甚至直接導致服務不可用。
master節點記憶體佔用和叢集中Shard數直接相關,一般叢集Shard需要控制在10,000個以內,ES預設配置中,單節點Shard數上限為1000個,需要合理控制索引和Shard數量。
data節點的記憶體由索引資料規模決定,如ES的FST會長期駐留在記憶體,雖然在7.3及之後版本中,提供了堆外記憶體方式(mmap),但緩衝被系統回收又會導致查詢效能下降,如果使用的是更低版本,則只能控制單節點資料大小。
查詢與分析:影響查詢與分析效能的因素非常多,需要花費大量時間不斷試錯和積累。
合理設定mapping,例如text和keyword的選擇,盡量避免無必要的nested mapping。
避免過大的查詢範圍和複雜度(過深的Group by語句等),以免急劇消耗系統資源。對結果集大小進行限制,否則複雜的彙總查詢或模糊查詢等,在過巨量資料集上甚至直接導致記憶體溢出(OOM)。
控制segment數量,必要時進行force merge,也需要評估force merge帶來的大量IO和資源消耗。
合理選擇Filter和Query。在無需計算的情境中,Filter可以更好使用Query Cache,速度要明顯快於Query。
script指令碼帶來的效能和穩定性問題。
合理使用好routing可以使得單次查詢只掃描某個Shard資料,提升效能。
資料損毀:如果遇到異常的crash,可能導致檔案損壞。在segment或translog檔案受損時,Shard可能無法載入,需要使用工具或手動將有問題的資料清理掉,但這也會導致部分資料丟失。
以上是在使用和營運ES叢集中,經常會遇到和需要注意的問題,穩定維護好ES叢集可真不是一件容易的事情,特別是當資料逐步擴大到數百TB,又有大量使用需求的情況下。同樣的問題也存在其他系統中,這對於平時工作極其繁忙的營運和SRE同學是不小的負擔。
雲上一體化服務選擇
針對營運和SRE團隊工作中的監控分析平台需求,以及平台搭建過程中遇到的種種問題,阿里雲Log Service團隊希望在雲上提供一套簡單易用、穩定可靠、高效能而又具有良好性價比的解決方案,以支援營運和SRE團隊更高效地工作。Log Service從原本只支援阿里巴巴集團和螞蟻集團內部日誌系統開始,逐步完善,演化成為同時支援Log、Metric、Trace的PB級雲原生觀測分析平台。
接入資料極其簡便
Logtail:經過多年百萬級伺服器錘鍊,簡便、可靠、高效能,介面化管理。
SDK/Producer:接入各類移動端Java、C、GO、iOS、Android、Web Tracking資料。
雲原生:雲上ACK原生支援,自建CRD一鍵接入。
即時消費和生態對接
秒級擴容能力,支援PB級資料即時寫入和消費。
原生支援Flink、Storm、Spark Streaming等主流系統。
海量資料查詢分析力
百億規模秒級查詢。
支援SQL92文法,支援互動式查詢,支援機器學習、安全檢測等函數。
資料加工
對比傳統的ETL,可節省90%的開發成本。
純託管、高可用、高彈性擴充。
Metric資料
雲原生Metric資料接入,支援億級時間軸的Prometheus儲存。
統一的Tracing方案
支援OpenTelemetry協議,相容Jaeger、Zipkin等OpenTracing協議,支援OpenCensus、SkyWalking等方案。
完善的監控和警示
一站式完成警示監控、降噪、交易管理、通知指派。
異常智能診斷
高效的無監督流式診斷和人工打標反饋機制,大大提高了監控效率和準確率。
相比開源多套系統的方案,Log Service採用All in one模式。在一個系統中,完整支援營運和SRE團隊工作中的監控分析平台需求,可以直接替代搭建Kafka、ES、Prometheus、OLAP等多套系統的組合,具有如下優勢:
降低營運複雜度
雲上服務、開箱即用、零營運成本、無需再維護和調優多套系統。
可視化管理、5分鐘完成接入、業務支援成本大大降低。
成本最佳化
資料只保留一份,無需將資料在多套系統中流轉。
按量使用,無預留資源的浪費。
提供完善的支援人員,人力成本大大降低。
完善的資源許可權管理
提供完整的消費資料,助力完成內部分賬和成本最佳化。
完整的許可權控制和資源隔離,避免重要訊息泄露。
Log Service希望通過自身的不斷進步,為Log、Metric、Trace等資料提供大規模、低成本、即時平台化服務,助力營運和SRE團隊更生產力,更有效支援業務快速發展。