ApsaraDB for SelectDB支援基於Push模式驅動的Pipeline執行引擎。其減少了線程切換和線程阻塞所導致的執行開銷,提高了CPU的利用效率,並減少了大查詢對小查詢的資源擠占問題。從而提高CPU在混合負載SQL上執行時的效率,提升了SQL查詢的效能。
功能簡介
Pipeline執行引擎是SelectDB在新版本新增的核心功能。旨在替換原有的SelectDB執行引擎,充分發揮多核CPU的計算能力,並對SelectDB的查詢線程數量進行限制,以解決SelectDB執行線程膨脹的問題。其具體設計、實現和效果請參見Support Pipeline Exec Engine。
原理
SelectDB原有的SQL執行引擎基於傳統的火山模型設計,在單機多核的情境下存在以下問題:
無法充分利用多核計算能力提升查詢效能。在大多數情況下,進行效能調優時需要手動設定並行度,而在生產環境中幾乎很難進行這樣的設定。
單機查詢的每個執行個體(Instance)對應線程池的一個線程,這會帶來以下的兩個問題。
一旦線程池達到最大容量,SelectDB的查詢引擎將陷入假死結狀態,無法響應後續的查詢。同時,存在一定機率發生邏輯死結的情況,例如所有線程都在執行某個執行個體的探測(Probe)任務。
阻塞的運算元佔用了線程資源,導致線程資源無法讓渡給可調度的執行個體,從而整體資源使用率不高。
阻塞運算元依賴作業系統的線程調度機制,線程切換開銷較大(尤其在系統混布的情境中)。
這一系列的問題,促使SelectDB需要適應現代多核CPU體繫結構的執行引擎。
如下圖所示,基於多核CPU的特點,Pipeline執行引擎經過重新設計,成為由資料驅動的執行引擎,從而提高CPU在混合負載SQL上執行時的效率,提升了SQL查詢的效能。
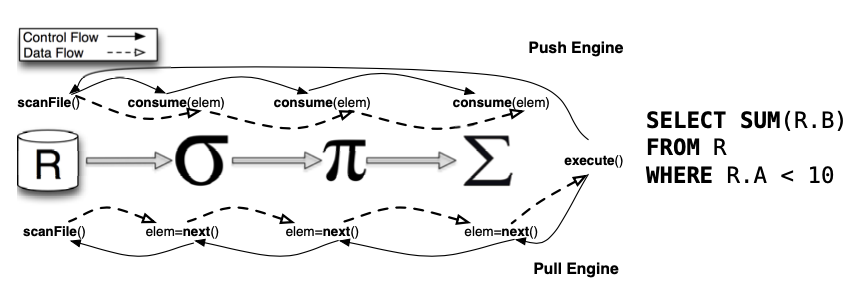
將傳統基於Pull拉模數式驅動的執行引擎,改造為基於Push模式驅動的執行引擎。
將阻塞操作非同步化,減少了線程切換、線程阻塞導致的執行開銷,CPU利用更高效。
控制了執行線程的數目,通過時間片切換的控制,在混合負載的情境中,減少大查詢對於小查詢的資源擠占問題。
使用方式
設定Session變數
enable_pipeline_engine
將會話變數
enable_pipeline_engine設定為true,則BE(叢集)在進行查詢執行時開啟基於Pipeline的執行方式,預設開啟。set enable_pipeline_engine = true;parallel_pipeline_task_num
parallel_pipeline_task_num代表了SQL查詢進行並發執行的Pipeline Task數目。SelectDB預設的配置為0,會自動化佈建為CPU核心數的一半。您也可以根據自己的實際情況進行調整。set parallel_pipeline_task_num = 0;您可以通過設定
max_instance_num來限制自動化佈建的並發數上限(預設為64)。