本文為您介紹BloomFilter索引在ApsaraDB for SelectDB中使用時的注意事項以及相關操作。
功能介紹
BloomFilter是由Bloom在1970年提出的一種基於多雜湊函數映射的機率型資料結構。主要用於快速判斷某個元素是否屬於一個集合。
適用情境:適用於
in和=過濾查詢,通過過濾條件快速裁剪大部分無用資料。索引特點:
高效的空間利用率的資料結構:它由一個超長的二進位位元組和一系列的雜湊函數組成。
機率性結果:對於任意一個元素的判斷,BloomFilter會返回兩種結果:
true:該元素可能在集合中,(存在誤判機率)。
false:該元素一定不在集合中。
更多底層實現,請參見下述更多原理內容。
BloomFilter是由一個超長的二進位位元組和一系列的雜湊函數組成。二進位位元組初始全部為0,當給定一個待查詢的元素時,這個元素會被一系列雜湊Function Compute映射出一系列的值,所有的值在位元組的位移量處置為1。
下圖所示出一個m=18,k=3(m是該Bit數組的大小,k是Hash函數的個數)的BloomFilter樣本。集合中的x、y、z三個元素通過3個不同的雜湊函數散列到位元組中。當查詢元素w時,通過雜湊Function Compute之後因為有一個位元為0,因此w不在該集合中。
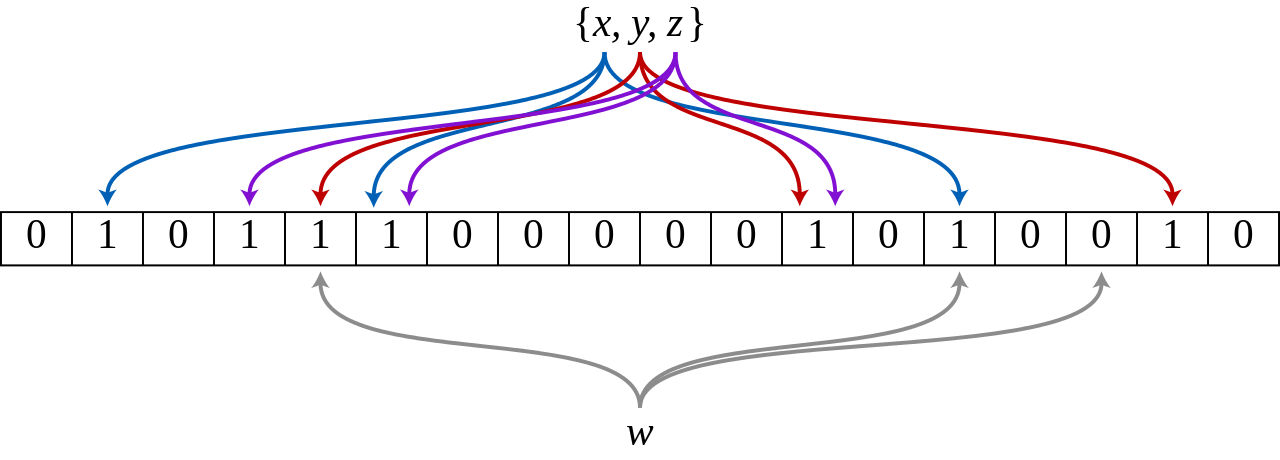
如何判斷某個元素是否在集合中,同樣是這個元素經過雜湊Function Compute後得到所有的位移位置,若這些位置全都為1,則判斷這個元素在這個集合中,若有一個不為1,則判斷這個元素不在這個集合中。
注意事項
列類型為Tinyint、Float、Double不支援建立BloomFilter索引。
Bloom Filter索引只對
in和=過濾查詢有加速效果。查看某個查詢是否命中了BloomFilter索引,可以通過查詢的Profile資訊查看。
建立索引
BloomFilter索引是以Block為粒度建立的。每個Block中,指定列的值作為一個集合產生一個
ApsaraDB for SelectDB的BloomFilter索引可以通過建表的時候指定,或者通過表的ALTER操作來完成。
建表時建立索引
建表時建立BloomFilter索引,是通過在建表語句的PROPERTIES裡加上"bloom_filter_columns"="k1,k2,k3"這個配置屬性來進行的。其中,k1,k2,k3是要建立的BloomFilter索引的Key列名稱。
例如對錶sale_detail_bloom建立BloomFilter索引saler_id、category_id。
CREATE TABLE IF NOT EXISTS sale_detail_bloom(
sale_date date NOT NULL COMMENT "銷售時間",
customer_id int NOT NULL COMMENT "客戶編碼",
saler_id int NOT NULL COMMENT "銷售人員",
sku_id int NOT NULL COMMENT "商品編號",
category_id int NOT NULL COMMENT "商品分類",
sale_count int NOT NULL COMMENT "銷售數量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "單價",
sale_amt DECIMAL(20,2) COMMENT "銷售總金額"
)
Duplicate KEY(sale_date, customer_id, saler_id, sku_id, category_id)
distributed BY hash(customer_id) buckets 3
PROPERTIES("bloom_filter_columns"="saler_id, category_id");已有表增加索引
為已存在的表增加索引,即修改表的bloom_filter_columns屬性,文法如下。
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");查看索引
查看錶中建立的BloomFilter索引,文法如下。
SHOW CREATE TABLE <table_name>;以sale_detail_bloom表為例,樣本如下。
SHOW CREATE TABLE sale_detail_bloom;查詢結果如下。
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| sale_detail_bloom | CREATE TABLE `sale_detail_bloom` (
`sale_date` datev2 NOT NULL COMMENT '銷售時間',
`customer_id` int(11) NOT NULL COMMENT '客戶編碼',
`saler_id` int(11) NOT NULL COMMENT '銷售人員',
`sku_id` int(11) NOT NULL COMMENT '商品編號',
`category_id` int(11) NOT NULL COMMENT '商品分類',
`sale_count` int(11) NOT NULL COMMENT '銷售數量',
`sale_price` decimalv3(12, 2) NOT NULL COMMENT '單價',
`sale_amt` decimalv3(20, 2) NULL COMMENT '銷售總金額'
) ENGINE=OLAP
DUPLICATE KEY(`sale_date`, `customer_id`, `saler_id`, `sku_id`, `category_id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`customer_id`) BUCKETS 3
PROPERTIES (
"bloom_filter_columns" = "category_id, saler_id",
"light_schema_change" = "true"
); |
+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.03 sec)刪除索引
刪除索引即為刪除索引列中bloom_filter_columns屬性,文法如下。
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");查看索引變更進度
建立、修改、刪除索引是非同步過程,可通過命令查看任務進度,文法如下。
SHOW ALTER TABLE COLUMN;最佳實務
滿足以下幾個條件時可以考慮對某列建立BloomFilter索引。
非首碼過濾時。
查詢會根據該列高頻過濾,而且查詢條件大多是
in和=過濾。不同於Bitmap,BloomFilter適用於高基數列,比如UserID。因為如果建立在低基數的列上,比如“性別”列,則每個Block幾乎都會包含所有取值,導致BloomFilter索引失去意義。
樣本
要尋找一個佔用100 Byte儲存空間大小的短行,一個64 KB的HFile資料區塊應該包含(64*1024)/100=655.53行,大約700行。如果僅能在整個資料區塊的起始行鍵上建立索引,那麼它是無法提供細粒度的索引資訊的。因為要尋找的行資料可能會落在該資料區塊的行區間上,可能行資料沒在該資料區塊上,也可能是表中根本就不存在該行資料,或者是行資料在另一個HFile裡,甚至在MemStore裡。以上這幾種情況,都會導致從磁碟讀取資料區塊時帶來額外的IO開銷,也會濫用資料區塊的緩衝,當面對一個巨大的資料集且處於高並發讀時,會嚴重影響效能。
因此,HBase提供了布隆過濾器,它允許您對儲存在每個資料區塊的資料做一個反向測試。當某行被請求時,通過布隆過濾器先檢查該行是否不在這個資料區塊,布隆過濾器確定回答該行不在,或者回答它不知道。這就是我們稱的反向測試。布隆過濾器也可以應用到行裡的單元上,當訪問某列標識符時可以先使用同樣的反向測試。
但布隆過濾器是有代價的,儲存這個額外的索引層次會佔用額外的空間。布隆過濾器隨著它們的索引對象資料增長而增長,所以行級布隆過濾器比列標識符級布隆過濾器佔用空間要少。當空間不是問題時,它們可以協助您充分利用系統的效能潛力。
SelectDB的BloomFilter索引可以通過建表的時候指定,或者通過表的ALTER操作來完成。
BloomFilter索引也是以Block為粒度建立的。每個Block中,指定列的值作為一個集合產生一個BloomFilter索引條目,用於在查詢時快速過濾不滿足條件的資料。