可視化MapReduce模型在MapReduce模型的基礎上,新增了可視化可營運的能力。您無需修改後端代碼,只需在SchedulerX控制台將分布式模型改為可視化MapReduce,即可新增一個子任務列表頁面,並且可以查看每個子任務的詳情、結果和日誌,同時支援每個子任務層級的重跑。
注意事項
低版本SDK有安全性漏洞,請升級到1.12.2以上版本。
僅專業版支援。
子任務個數不能超過1000個。
單個子任務的大小不能超過64 KB。
子任務顯示自訂標籤資訊時,子任務對象需要實現指定介面。
ProcessResult的result傳回值不能超過1000 Byte。
如果使用reduce,所有子任務結果會緩衝在Master節點,該情況對Master節點記憶體壓力較大,建議子任務個數和result傳回值不要太大。如果沒有reduce需求,使用MapJobProcessor介面即可。
SchedulerX不保證子任務絕對執行一次。在特殊條件下會failover,可能導致子任務重複執行,需要業務方自行實現等冪。
介面
繼承MapReduce模型所有介面,任務處理代碼開發模型與MapReduce模型完全一致。具體資訊,請參見MapReduce模型。
(可選)在MapReduce模型介面基礎上,支援設定每個子任務的標籤展示(子任務對象需要實現com.alibaba.schedulerx.worker.processor.BizSubTask介面)。
介面
解釋
是否必選
public Map<String, String> labelMap()實現輸出子任務標籤資訊,用於展示對應子任務對象的業務自訂特徵資訊(如:賬戶名、商品Code、城市地區等)。
否
與MapReduce對比
對比項 | MapReduce | 可視化MapReduce |
子任務數量 | 可支援百萬級 | 小於等於1000。 |
任務開發模式 | 兩者相同 | |
子任務列表 | 不支援 | 支援。 |
子任務運行詳情 | 不支援 | 支援,單個子任務執行記錄、執行狀態、日誌、鏈路追蹤、運行堆棧。 |
子任務標籤 | 不支援 | 支援,子任務實現BizSubTask介面可查看業務標籤資訊。 |
子任務操作 | 不支援 | 支援,單個子任務支援停止、重跑。 |
任務開發示範
賬戶批量處理
案例描述:對一批銀行賬戶進行批量處理,每個帳號作為獨立的子任務在整個叢集中進行全域平行處理,並且每一個子任務在執行列表中需要顯示其對應的賬戶資訊以便查看,可以方便的掌握每一個帳號地處理狀態及其執行詳細資料。如下將提供相應demo代碼供參考使用。
自訂帳號資訊子任務對象,每個子任務對象支援展示其標籤資訊,需實現介面com.alibaba.schedulerx.worker.processor.BizSubTask,並實現labelMap方法。
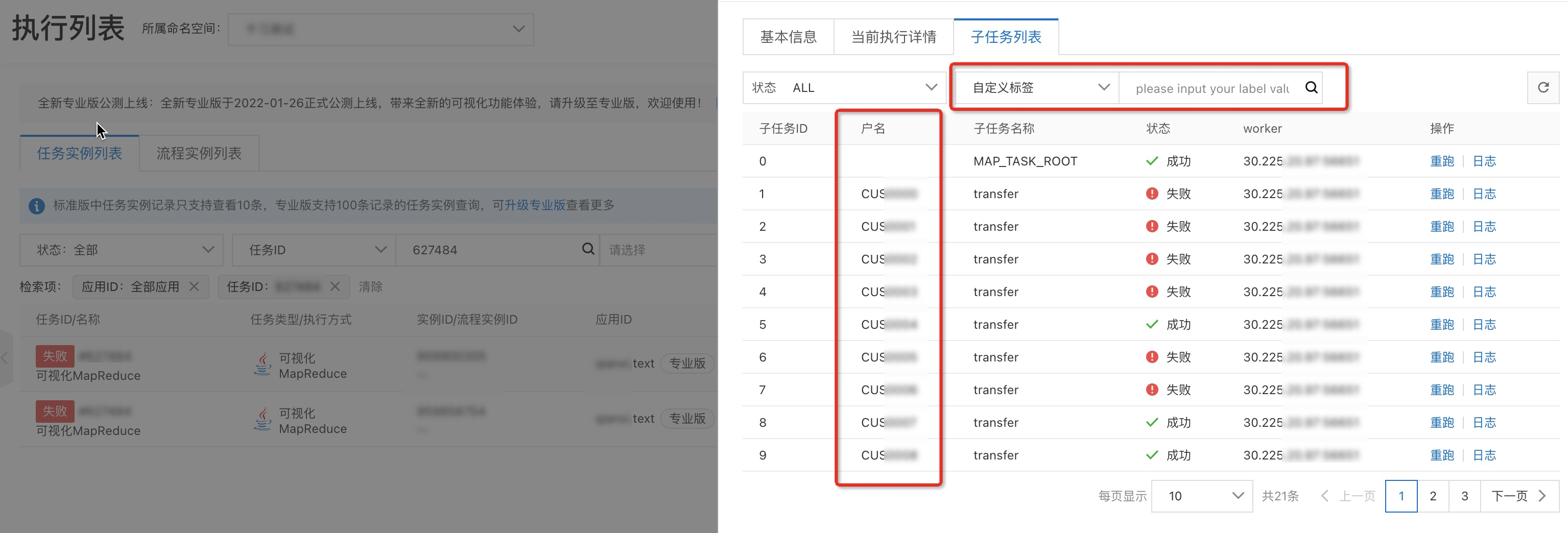
public class ParallelAccountInfo implements BizSubTask { /** * 主鍵 */ private long id; private String name; private String accountId; public ParallelAccountInfo(long id, String name, String accountId) { this.id = id; this.name = name; this.accountId = accountId; } /** * 實現labelMap方法,用於設定對應子任務的標籤資訊 * @return */ @Override public Map<String, String> labelMap() { Map<String, String> labelMap = new HashMap(); labelMap.put("戶名", name); return labelMap; } }子任務對象實現對應介面後,子任務列表才可展示出每個子任務對象專屬的標籤資訊(例如:案例中的戶名)用於區分每一個賬戶對象的業務處理情況,且支援按標籤搜尋。
帳號業務任務處理Processor,實現對單個帳號的商務邏輯處理,繼承com.alibaba.schedulerx.worker.processor.MapReduceJobProcessor。
操作步驟
任務配置
登入分布式任務調度平台,在左側導覽列,單擊任務管理。
在任務管理頁面,單擊建立任務。
在建立任務面板,執行模式下拉式清單選擇可視化MapReduce。
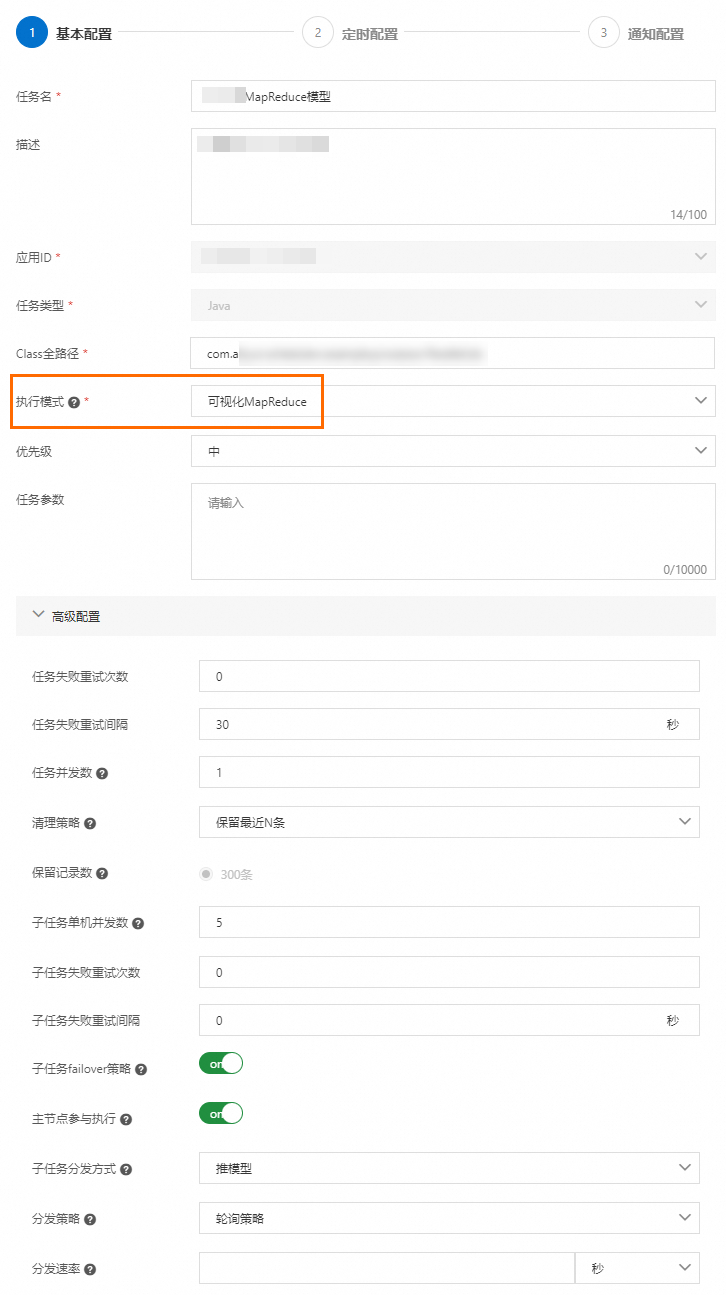
在進階配置地區配置相關資訊。其他配置項,請參見任務管理進階配置參數說明。
配置項
說明
分發策略
輪詢策略(預設):每個Worker平均分配等量子任務,適用於每個子任務處理耗時基本一致的情境。
負載最優策略:由主節點自動感知Worker節點的負載情況,適用於子任務和Worker機器處理耗時有較大差異的情境。
說明用戶端版本為1.10.14及以上。
子任務單機並發數
即單機執行線程數,預設為5。如需加快執行速度,可以調大該值。如果下遊或者資料庫無法承接,可適當調小。
子任務失敗重試次數
子任務失敗會自動重試,預設為0。
子任務失敗稍候再試
子任務失敗稍候再試,單位:秒,預設為0。
子任務failover策略
當執行節點宕機下線後,是否將子任務重新分發給其他機器執行。開啟該配置後,發生failover時,子任務可能會重複執行,需自行做好等冪。
說明用戶端版本為1.8.13及以上。
主節點參與執行
主節點是否參與子任務執行。線上可運行Worker數量必須不低於2台,在子任務數量特別大時,推薦關閉該參數。
說明用戶端版本為1.8.13及以上。
可視化能力
任務執行後,您可以在執行列表頁面,單擊詳情查看對應子任務的詳細執行資訊。
在子任務列表頁簽查看每個子任務處理的狀態。
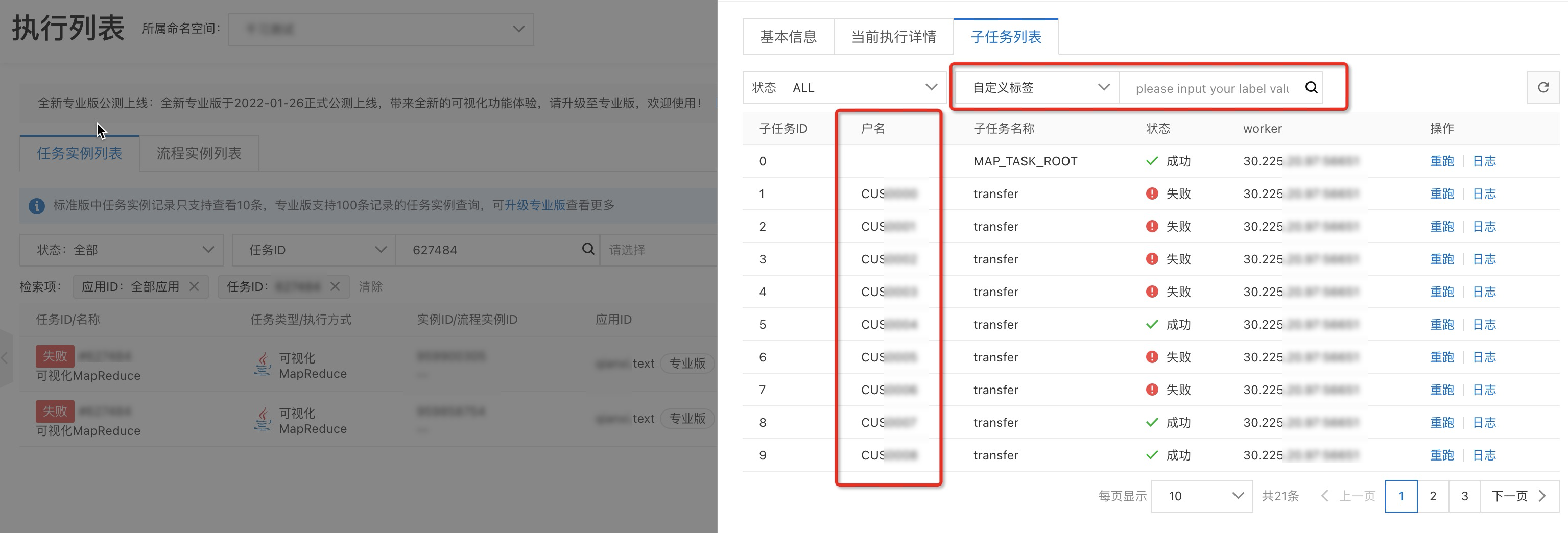
在子任務列表頁簽,單擊子任務操作列的日誌,可以查看每個子任務啟動並執行業務日誌資訊,分析執行狀態結果。
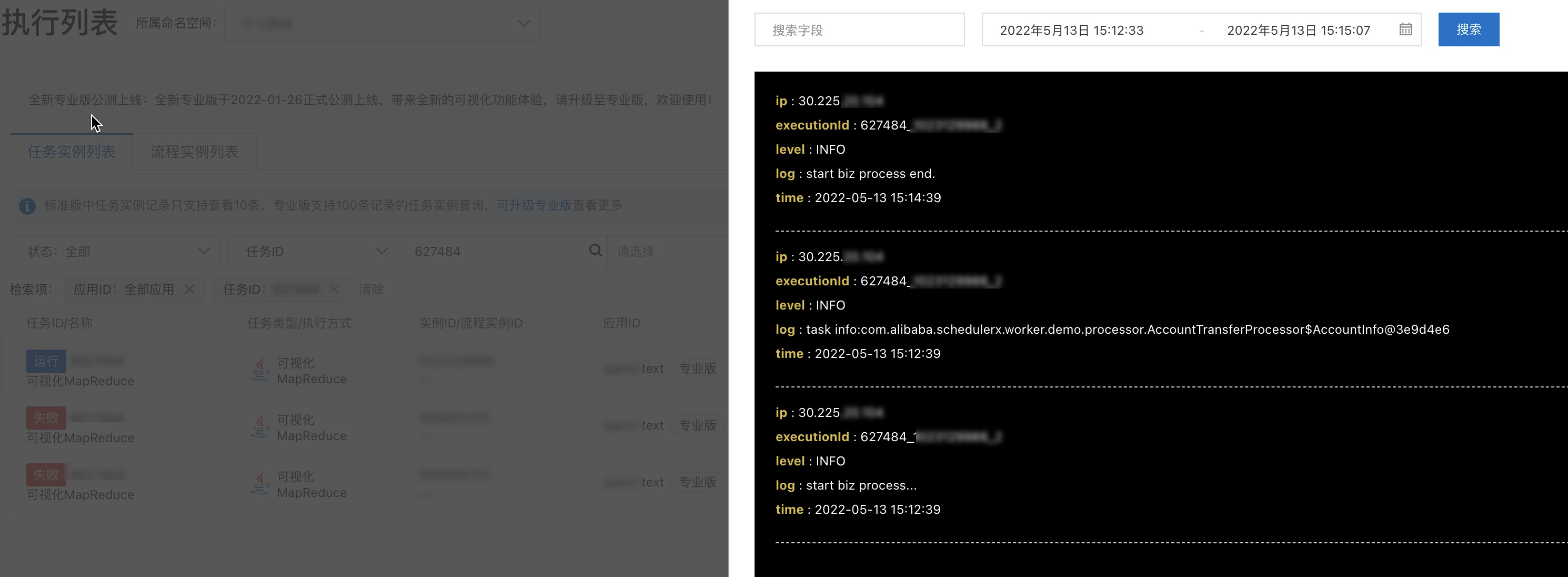
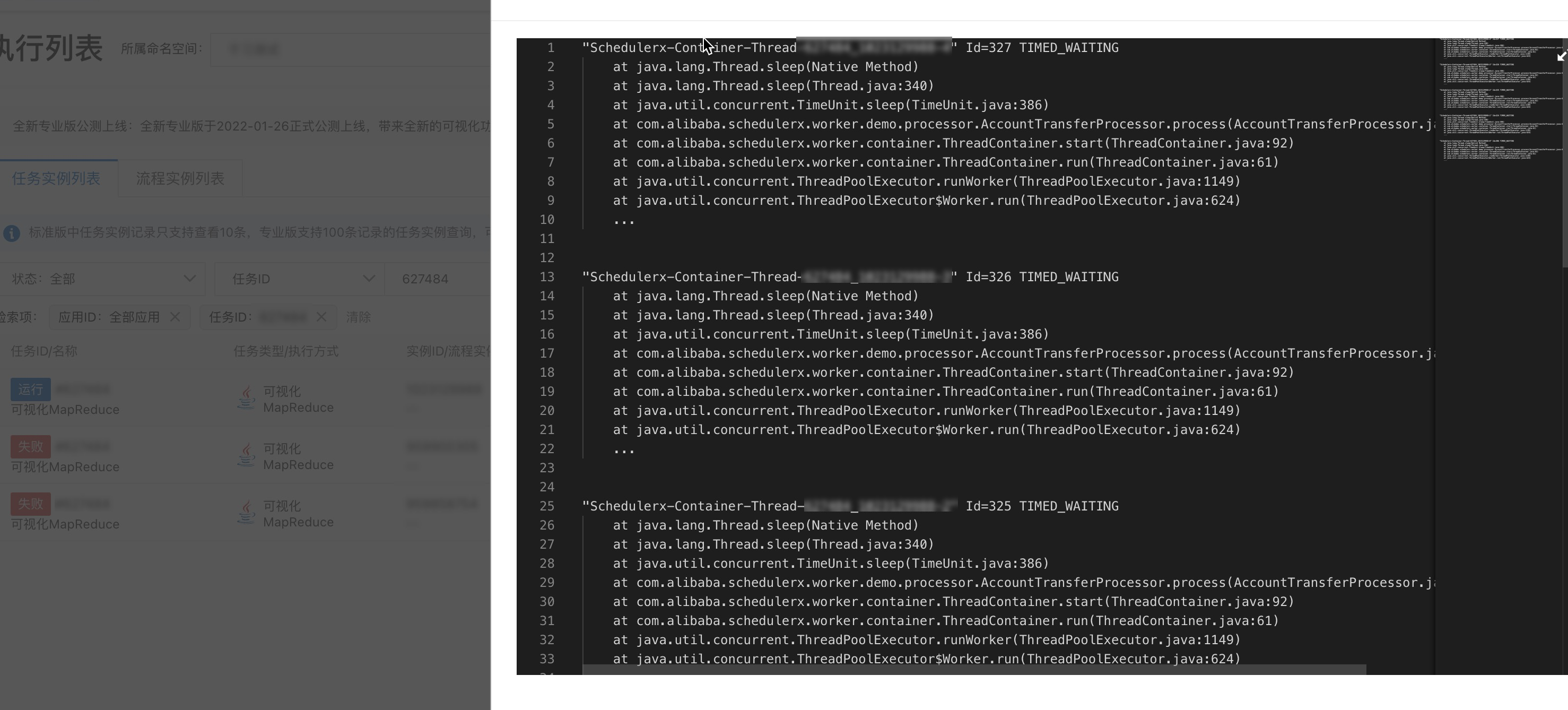
任務執行記錄在運行中時,在當前執行詳情頁簽,單擊查看堆棧,可以查看對應機器處理線程運行中的情況,分析當前任務運行異常情況。
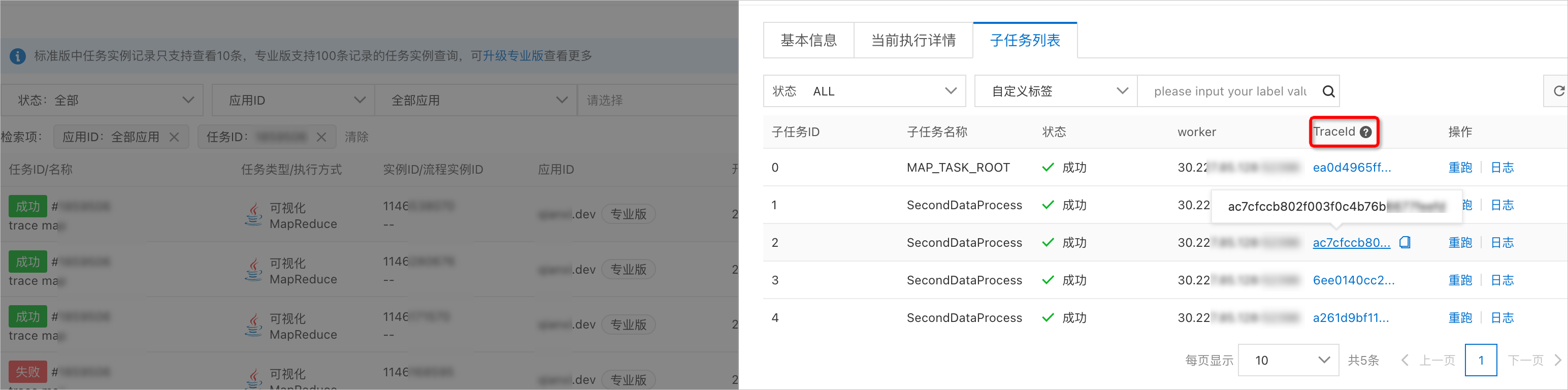
在子任務列表頁簽,當接入鏈路追蹤後,單擊對應的TraceId,可以查詢每個子任務的執行調用鏈路。具體操作,請參見如何接入鏈路追蹤。