AI Agent在多輪對話中需要持續追蹤上下文,對記憶層的延遲和並發能力要求極高。本文以淘寶閃購"一句話點外賣"情境為例,介紹如何使用Tair的資料結構、分布式鎖和彈性擴充能力構建高效能的Agent短期記憶系統。
業務背景
淘寶閃購Agent支援使用者通過自然語言完成從導購到下單支付的完整點單流程,目標是將傳統3-5分鐘的點單耗時壓縮至30秒以內。
當使用者說"幫我點杯霸王茶姬的伯牙絕弦,少糖去冰,送到公司",背後的AI Agent需要在數秒內完成意圖識別、位址解析、商品搜尋、規格匹配、加購下單等一系列操作,每一步都依賴對"之前發生了什麼"的準確記憶。
在淘寶閃購與千問合作的"一句話點外賣"專案中,Tair承擔了Agent短期記憶層的核心角色。本文將從這一真實業務情境出發,介紹Tair在AI Agent記憶管理中的資料模型設計與並發控制等關鍵實踐。
適用情境
本文的設計模式適用於以下AI Agent情境:
需要維護多輪對話內容相關的會話式Agent(如客服、導購、助手)
對話鏈路延遲敏感、需要毫秒級記憶讀寫的即時互動情境
存在並發寫入風險的多工具調用情境(如Agent同時調用多個工具)
流量波動大、需要彈性擴充的線上業務
為什麼記憶系統需要Tair
AI Agent的記憶系統對延遲極度敏感。根據Little定律"並發數 ≈ QPS × 延遲",記憶訪問延遲從5ms上升到50ms,系統在途請求數就會膨脹10倍,這可能迅速耗盡串連、線程和隊列資源。而Agent每輪對話涉及多次記憶讀寫,延遲會被反覆疊加放大,最終可能引發排隊、逾時乃至雪崩。
5ms和50ms的差別,不是體驗上的最佳化,而是系統能否穩定擴充的分水嶺。這正是淘寶閃購Agent選用Tair作為記憶層的核心原因——通過自研多線程核心提供穩定的低延遲,將記憶訪問穩定在安全水位,從根本上避免高並發下的惡性迴圈。
整體架構
淘寶閃購Agent的記憶層(Memory Service)位於Agent中樞與底層工具服務之間,通過Tair提供會話級的狀態管理能力。
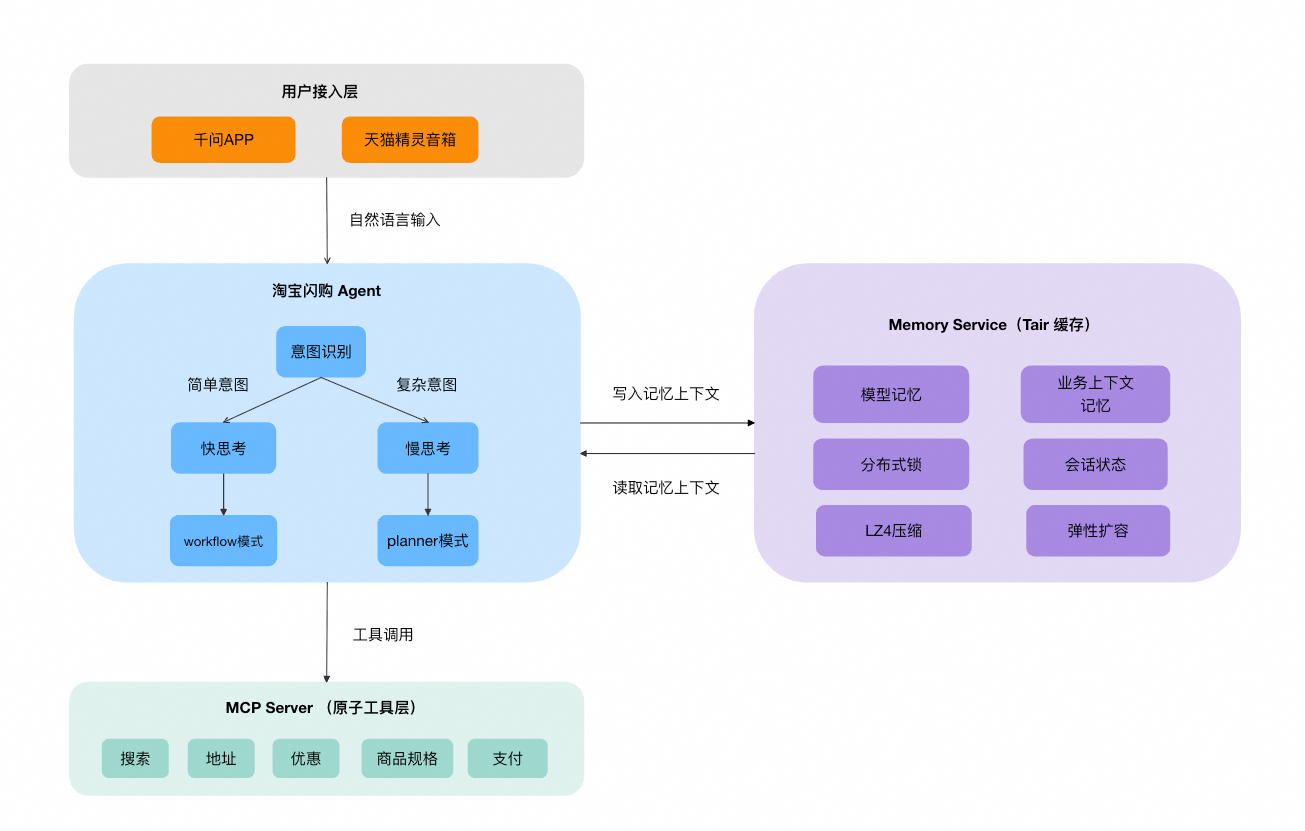
記憶分類與Tair資料模型設計
淘寶閃購Agent選擇Tair作為短期記憶儲存引擎,核心考量包括:
低延遲:Agent對話鏈路對回應時間極度敏感,Tair自研多線程核心提供微秒級讀寫能力,可滿足即時互動需求。
豐富的資料結構:不同類型的記憶資料可以選用最匹配的資料結構,簡化業務開發。
彈性擴充能力:支援叢集無感擴縮容和突發彈性頻寬,在流量洪峰期快速擴充、業務無感。
TTL生命週期管理:會話記憶具有自然到期屬性,TTL機制可自動清理到期資料。
短期記憶被劃分為兩大類,分別對應不同的Tair資料結構:
模型記憶(Model Memory)— List
模型記憶儲存供大語言模型消費的對話歷史。每輪對話中使用者的輸入和Agent的回複,都會被記錄並在下一輪推理時作為上下文傳入模型。
使用Tair的List結構儲存,每個會話一個Key:
Key: memory:model:{sessionId}
Type: List
樣本資料:
[
{"role": "user", "content": "幫我點杯奶茶"},
{"role": "assistant", "content": "為你找到附近3家奶茶店...", "cards": [...]},
{"role": "user", "content": "就這個,少糖去冰"},
{"role": "assistant", "content": "已選擇:伯牙絕弦 少糖去冰 大杯..."}
]核心操作:
# 每輪對話結束後,追加新的對話記錄
RPUSH memory:model:{sessionId} "{對話記錄JSON}"
# 模型推理前,讀取最近N輪對話作為上下文
LRANGE memory:model:{sessionId} -{N} -1
# 設定會話到期時間(如30分鐘)
EXPIRE memory:model:{sessionId} 1800對話記錄在寫入前,會將未經處理資料(包含文本和卡片等富媒體內容)轉換為模型更易理解的自然語言格式,減少Token消耗。
業務上下文記憶(Business Context Memory)— Hash
業務上下文記憶記錄商務程序中的結構化狀態資訊,供Agent的工具層和意圖處理器在執行商務邏輯時查詢和更新。
按業務領域拆分為6個子模組,使用Tair的Hash結構儲存:
Key: memory:context:{sessionId}
Type: Hash
Field 結構:
{
"session": "{會話元資訊: 使用者ID、渠道、會話階段等}",
"search": "{搜尋狀態: 當前query、搜尋結果、推薦商品列表等}",
"order": "{訂單狀態: 購物車內容、已選SKU、商品數量等}",
"conversation": "{對話狀態: 當前意圖、上一輪意圖、意圖切換標記等}",
"coupon": "{優惠資訊: 可用優惠券列表、已選優惠等}",
"bizState": "{業務狀態: 收貨地址、配送方式、支付狀態等}"
}核心操作:
# 單獨更新某個子模組(如使用者確認了收貨地址)
HSET memory:context:{sessionId} bizState "{更新後的業務狀態JSON}"
# 讀取特定子模組
HGET memory:context:{sessionId} order
# 一次性讀取所有上下文(用於意圖識別等需要全域資訊的情境)
HGETALL memory:context:{sessionId}
# 設定到期時間
EXPIRE memory:context:{sessionId} 1800使用Hash的field級讀寫能力,各業務模組可以獨立更新,互不干擾,避免了讀取完整JSON再回寫的競爭問題。例如搜尋模組更新商品推薦結果時,不會影響訂單模組正在寫入的購物車資料。
資料結構選型對比
記憶類型 | Redis資料結構 | 選型理由 |
對話歷史 | List | 對話是有序時間序列,List支援有序追加(RPUSH)和範圍讀取(LRANGE) |
業務上下文 | Hash | 按領域拆分為多個欄位,支援field級獨立讀寫,避免讀寫競爭 |
工作階段狀態標記 | String | 原子性狀態標記(如會話階段),操作簡單 |
分布式鎖 | String | 基於SET NX EX實現,保障並發安全 |
並發安全:分布式鎖
在實際業務中,同一會話可能存在並發寫入。例如使用者快速連續發送訊息,或流式響應過程中使用者再次輸入,都會導致多個請求同時修改同一會話的記憶資料。
淘寶閃購Agent使用Tair分布式鎖保護記憶的讀寫一致性,鎖粒度為單個會話:
# 擷取會話級分布式鎖(鎖逾時3秒,防止異常阻塞)
SET lock:memory:{sessionId} {requestId} NX EX 3
# 成功擷取鎖後,執行記憶讀寫操作
HSET memory:context:{sessionId} order "{更新後的訂單狀態}"
RPUSH memory:model:{sessionId} "{新對話記錄}"
# 操作完成後釋放鎖(通過Lua指令碼確保只釋放自己持有的鎖)
EVAL
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
end鎖粒度為會話級(sessionId),而非全域鎖。不同使用者的會話之間完全無鎖競爭,不會影響系統整體吞吐。鎖逾時設定為秒級,避免持鎖進程異常退出時造成長時間阻塞。
應對流量洪峰
在千問春節紅包活動期間,淘寶閃購Agent承受了超過10倍於預估峰值的並發壓力。每次使用者對話可能觸發數十次Tair操作(讀取歷史、更新狀態、鎖操作等),Agent的並發請求量會被放大為數量級更高的Tair操作量。
淘寶閃購Agent的記憶層底層使用的是雲資料庫 Tair(相容 Redis)。相比自建Redis,Tair在核心效能、彈性擴充和營運方面的能力是應對此次流量洪峰的關鍵支撐。
Tair自研核心的效能優勢
Tair(企業版)記憶體型採用多執行緒模式,讀寫效能達到同規格Redis開源版執行個體的3倍。這意味著在相同的執行個體規格下,Tair能夠承載3倍於開源Redis的操作輸送量。
在AI Agent情境中,這一效能優勢尤為關鍵。一次使用者對話可能觸發數十次Tair操作(讀取對話歷史、更新業務上下文、分布式鎖擷取釋放等),如果使用開源Redis的單執行緒模式,在高並發情境下很容易成為瓶頸。Tair的多線程核心使得單個節點可以充分利用多核CPU資源,在不增加節點數量的前提下即可承載更高的並發量。
彈性擴充與無感擴縮容
在Agent對話鏈路中,記憶資料呈現典型的讀多寫少特徵:每輪推理前需要讀取完整的對話歷史和業務上下文(讀操作),而寫操作僅在每輪對話結束後追加一條記錄。讀寫比通常在5:1到10:1之間。
Tair支援叢集架構開啟讀寫分離功能,主節點掛載唯讀副本(Read Replica),讀請求自動分發到唯讀節點,寫請求路由到主節點。唯讀副本支援1~9個靈活調整,叢集分區支援2~256個水平擴充。在流量高峰前增加唯讀副本或分區即可線性提升吞吐,峰值過後縮減節點降低成本。
樣本
日常流量:叢集 8 分區,每分區 1 唯讀副本 → 滿足日常業務需求
春節活動(5~10 倍峰值):
方案一:每分區擴充至 5 唯讀副本 → 讀吞吐線性提升
方案二:叢集擴至 16 分區 + 每分區 3 唯讀副本 → 讀寫能力同步翻倍
這些擴縮容操作對業務完全透明。傳統Redis叢集在Slot遷移過程中可能產生-ASK、-TRYAGAIN等錯誤,對Agent對話情境來說,任何一次請求失敗都可能導致對話中斷或記憶丟失。Tair雲原生版通過核心級最佳化實現了無感擴縮容——資料以Slot為單位原子性整體遷移(而非逐Key遷移),不會造成Slot分裂;同時通過中心化的控制組件協調叢集行為,遷移效率更高、決策更精準。
在資料移轉的最終階段,對應Slot的寫請求時延會略有增加,但不會失敗。對於Agent記憶服務而言,表現為個別請求延遲略升,但不會出現資料丟失或請求報錯。
頻寬彈性擴充
除了QPS壓力,活動期間還面臨顯著的頻寬挑戰。AI Agent每次記憶讀取涉及對話歷史和業務內容相關的傳輸,單次請求的資料量遠大於傳統緩衝情境中的簡單KV讀寫。在業務高峰期,頻寬很可能先於CPU和記憶體成為瓶頸。
Tair雲原生架構提供了兩層彈性機制:
叢集頻寬水平擴充:叢集架構可以通過增加LB數量來擴充執行個體總頻寬,單個LB頻寬上限20Gbps,當分區數超過8個時,可按需新增LB,新增過程中不會中斷現有串連。
突發彈性頻寬:當瞬時流量超過固定頻寬時,系統會秒級自動擴充頻寬(單節點最高可達288MB/s),流量回落後自動回收,按實際突發量計費。突發彈性頻寬以分區為粒度獨立生效。當某個分區因熱點Key出現頻寬瓶頸時,僅該分區的頻寬會被自動擴充,不會影響其他分區。
說明突發彈性頻寬特別適合Agent情境中不可預測的流量尖峰。相比提前購買高規格的固定頻寬包,按需突發在成本上更省。
TTL自動回收
所有會話Key設定合理的TTL(如30分鐘),流量高峰過後記憶體自動回落,無需人工幹預。結合Tair的彈性擴縮容能力,實現了"高峰擴、低穀縮、到期自動清理"的全自動資源管理。
最終,整套記憶服務在春節流量洪峰期間保持穩定運行,P99延遲始終控制在毫秒級。
總結與展望
在淘寶閃購"一句話點外賣"情境中,Tair作為AI Agent短期記憶層的核心儲存,提供了以下關鍵能力:
能力 | 實現方式 | 解決的問題 |
低延遲訪問 | Tair記憶體讀寫 | 匹配Agent對話鏈路的即時性要求 |
靈活的資料建模 | List + Hash + String組合 | 適配對話歷史、業務上下文等不同記憶類型 |
生命週期管理 | TTL自動到期 | 會話結束後自動清理,降低營運成本 |
並發安全 | 分布式鎖(SET NX EX) | 保障多請求並發寫入時的資料一致性 |
彈性抗壓 | 讀寫分離 + 突發彈性頻寬 | 支撐春節活動10倍峰值流量,業務無感彈性 |
隨著AI Agent技術的演化,記憶管理正在向更深層次發展。短期記憶之外,長期記憶(使用者偏好、歷史行為模式)的建設已在規劃之中,讓Agent不僅記住"這次對話說了什麼",更記住"這個使用者是誰、喜歡什麼"。
AI Agent的記憶系統,正在從"對話級"走向"使用者級",Tair在這一演化過程中將持續扮演關鍵角色。