效能洞察(Performance Insights)是一項專註於使用者資料庫執行個體效能調優、負載監控和關聯分析的重要工具。它能夠協助您直觀地評估資料庫負載、識別資源等待的源頭及相關SQL查詢語句,從而實現精準的效能最佳化。
功能簡介
效能洞察能夠協助您快速、方便且直接地識別資料庫執行個體的負載,以及導致效能問題的SQL語句。主要包含以下功能:
關鍵效能指標趨勢圖:記憶體/CPU使用率、會話串連、TPS和IOPS的變化趨勢圖。
平均活躍會話(AAS,Average Active Sessions):即時追蹤執行個體負載,清晰展示負載來源。
多維負載資訊:從SQL、使用者(User)、資料庫(Databases)、等待事件(Waits)、用戶端主機(Hosts)、應用(Applications)和會話類別(Session Type)等維度展示執行個體負載資訊。
適用範圍
RDS PostgreSQL滿足以下要求:
資料庫大版本:RDS PostgreSQL 13及以上。
產品系列:高可用系列、叢集系列。
核心小版本:20240530及以上。
操作步驟
步驟一:開啟效能洞察
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側導覽列中,選擇監控與警示。在性能洞察頁簽。
單擊開啟效能洞察按鈕,在彈出的對話方塊中單擊確定開啟功能。
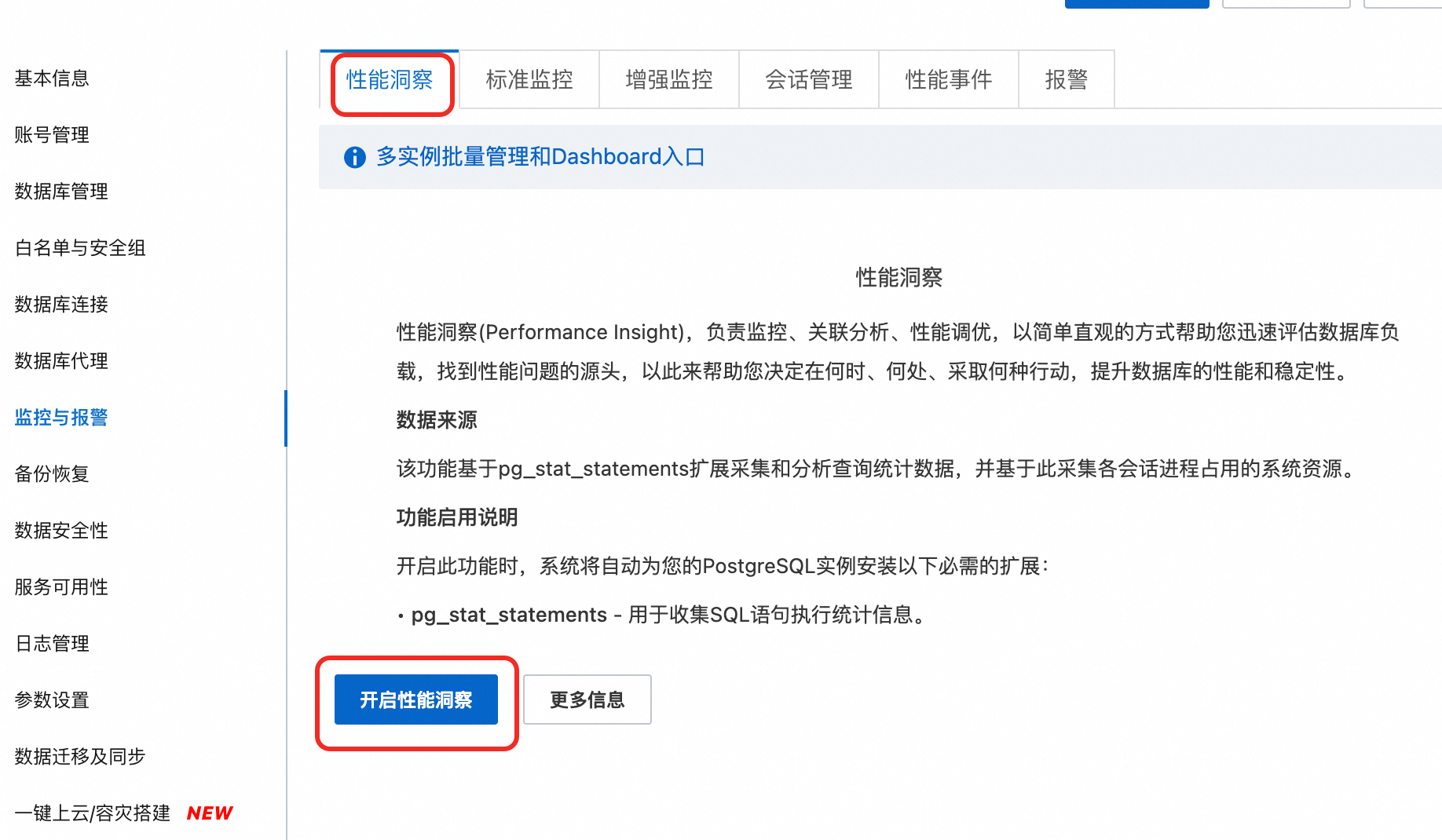 說明
說明如果您不再使用效能洞察功能,可以單擊性能洞察頁面的關閉性能洞察,關閉此功能。
開啟後,等待片刻,效能洞察頁面將開始展示資料。
步驟二:使用效能洞察進行分析
成功開啟功能後,您可以在效能洞察頁面內進行全面的效能分析。
目前效能洞察處於免費公測期,資料保留7天。正式版支援按需延長資料保留時間長度,收費將提前通知。
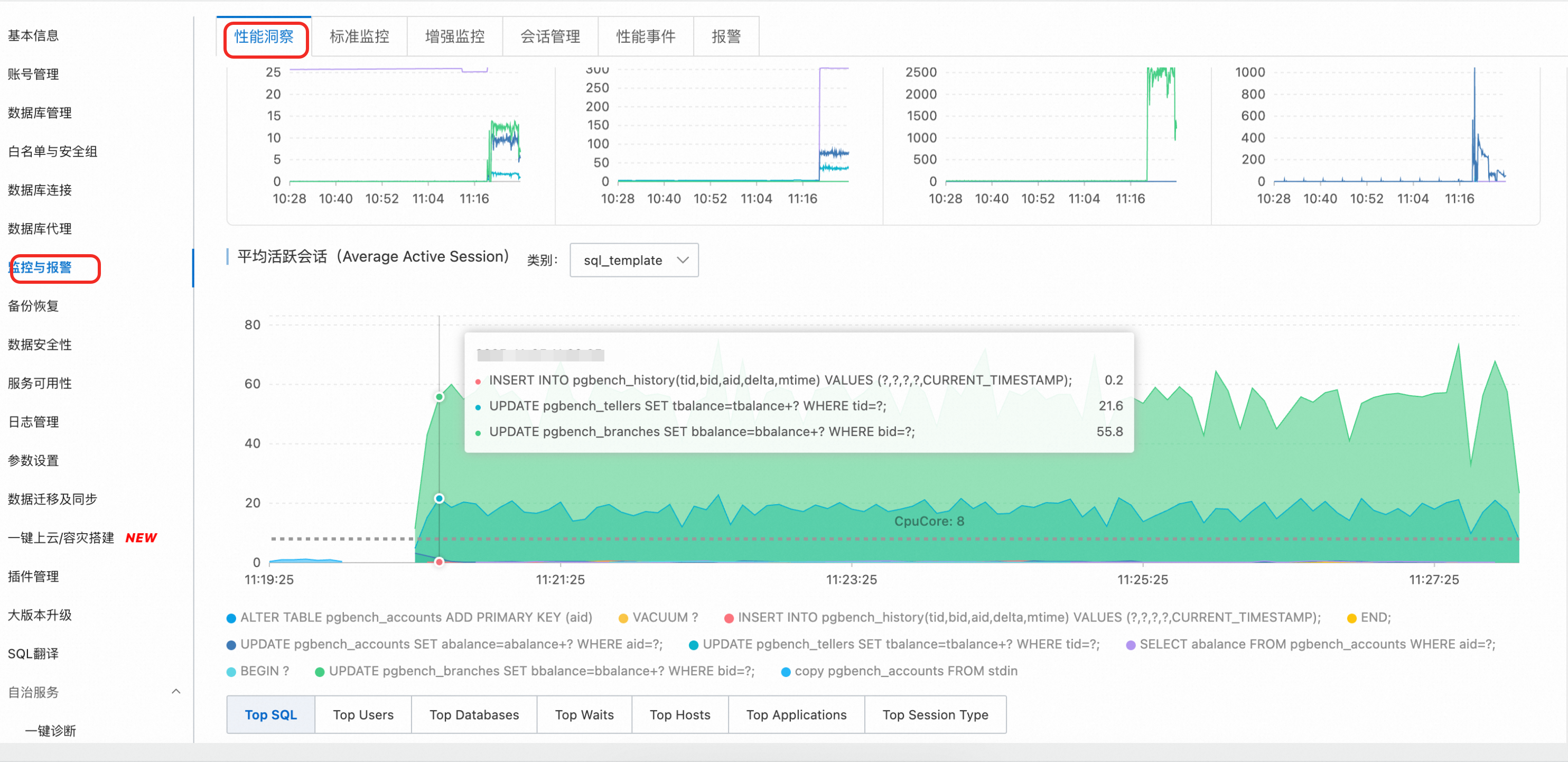
查看效能概覽(預設視圖)
進入效能洞察頁面後,您可以選擇時間範圍,單擊查看,分析以下核心資訊:
關鍵效能指標趨勢圖:快速瞭解執行個體的CPU/記憶體、串連數、TPS和IOPS等核心指標在選定時間段內的變化趨勢。
平均活躍會話(AAS):這是效能診斷的核心圖表。通過它,您可以直觀地看到執行個體的總負載(AAS值)以及負載的構成(按等待事件、SQL等維度)。AAS圖中的高峰通常對應效能瓶頸點。
多維負載資訊:在AAS圖表下方,您可以從SQL、使用者(User)、資料庫(Databases)、等待事件(Waits)等多個維度下鑽分析,快速定位是哪些SQL、使用者或等待事件造成了高負載。
故障診斷案例:慢SQL突增導致的鎖爭用問題
故障現象
監控顯示從某時刻開始,慢SQL數量急劇上升,應用回應時間顯著惡化。
診斷分析
步驟1:效能指標趨勢分析
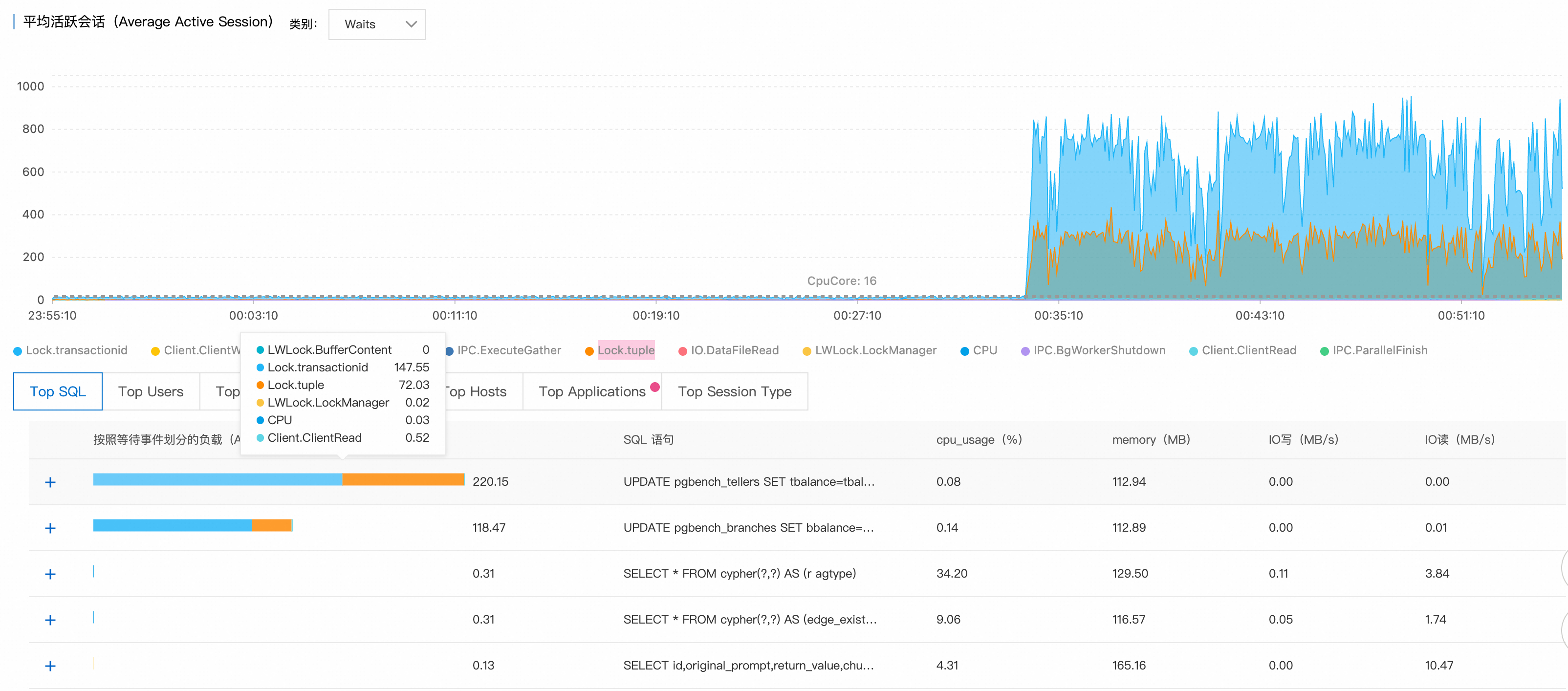
檢查關鍵效能指標趨勢圖,發現00:34時刻活躍會話數從正常的十幾個大幅上升至1100+,超過PostgreSQL執行個體的合理並發處理能力。
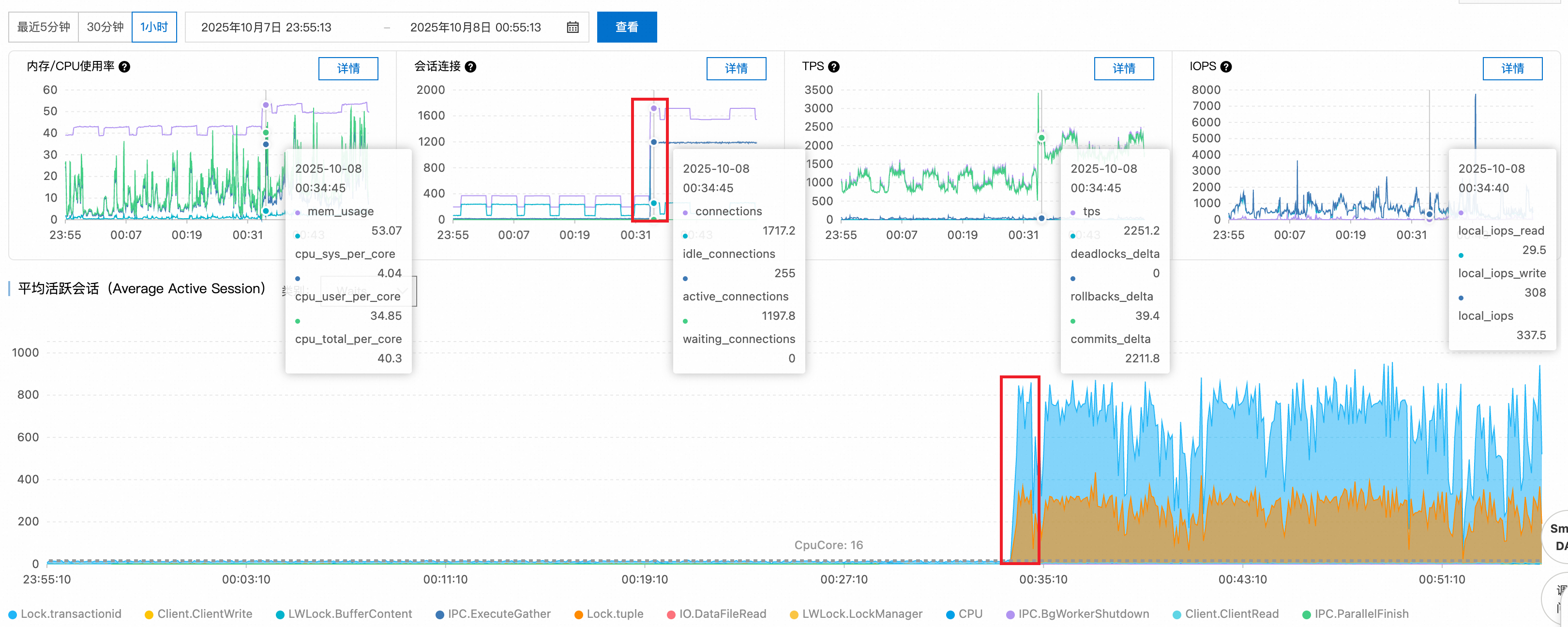
步驟2:等待事件分析
通過平均活躍會話(AAS)圖表的等待事件分布,識別出主要瓶頸集中在:
Lock/transactionid:事務ID鎖等待,通常由長事務或死結引起。Lock/tuple:行級鎖等待,表明存在嚴重的並發寫入衝突。
活躍會話數超過16核CPU的理論處理上限,確認系統處於嚴重的鎖爭用狀態。
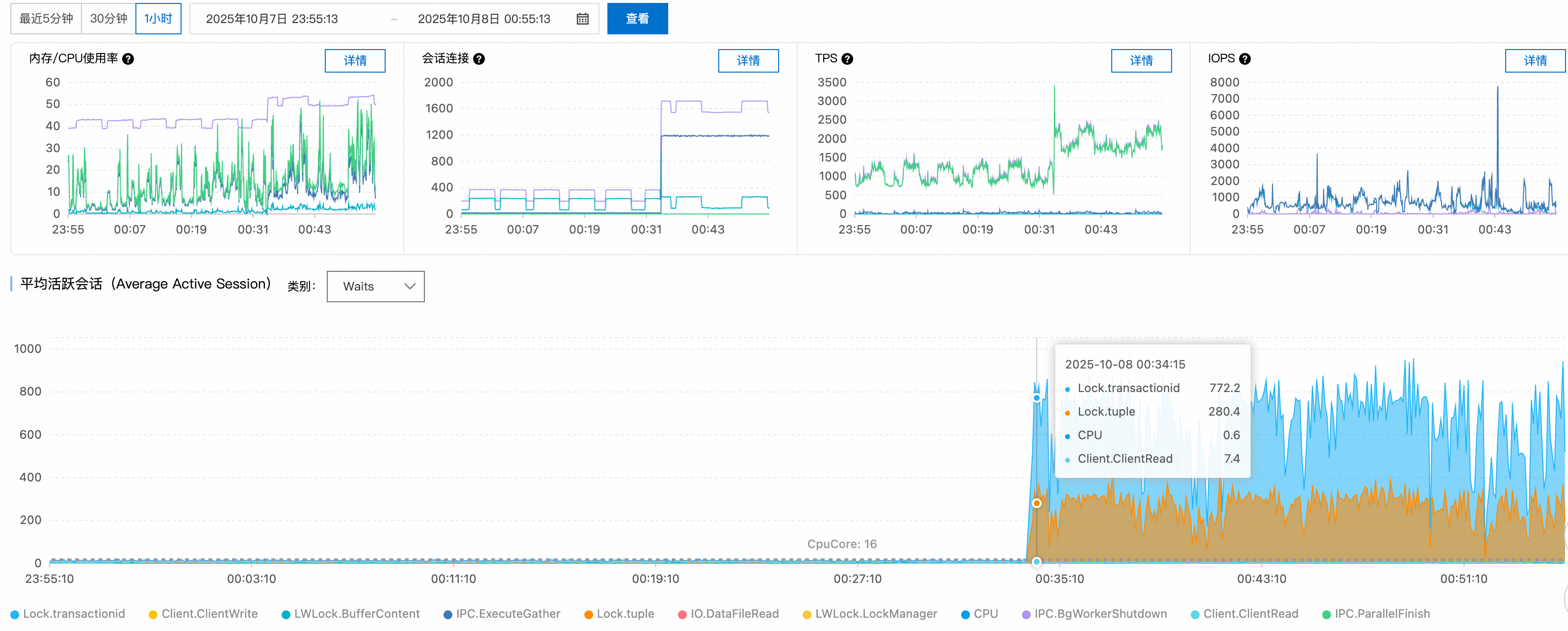
步驟3:SQL語句分析
Top SQL排行顯示,前兩個查詢分別有220和119個會話在等待鎖資源釋放,這些SQL成為整個鎖等待鏈的關鍵節點。
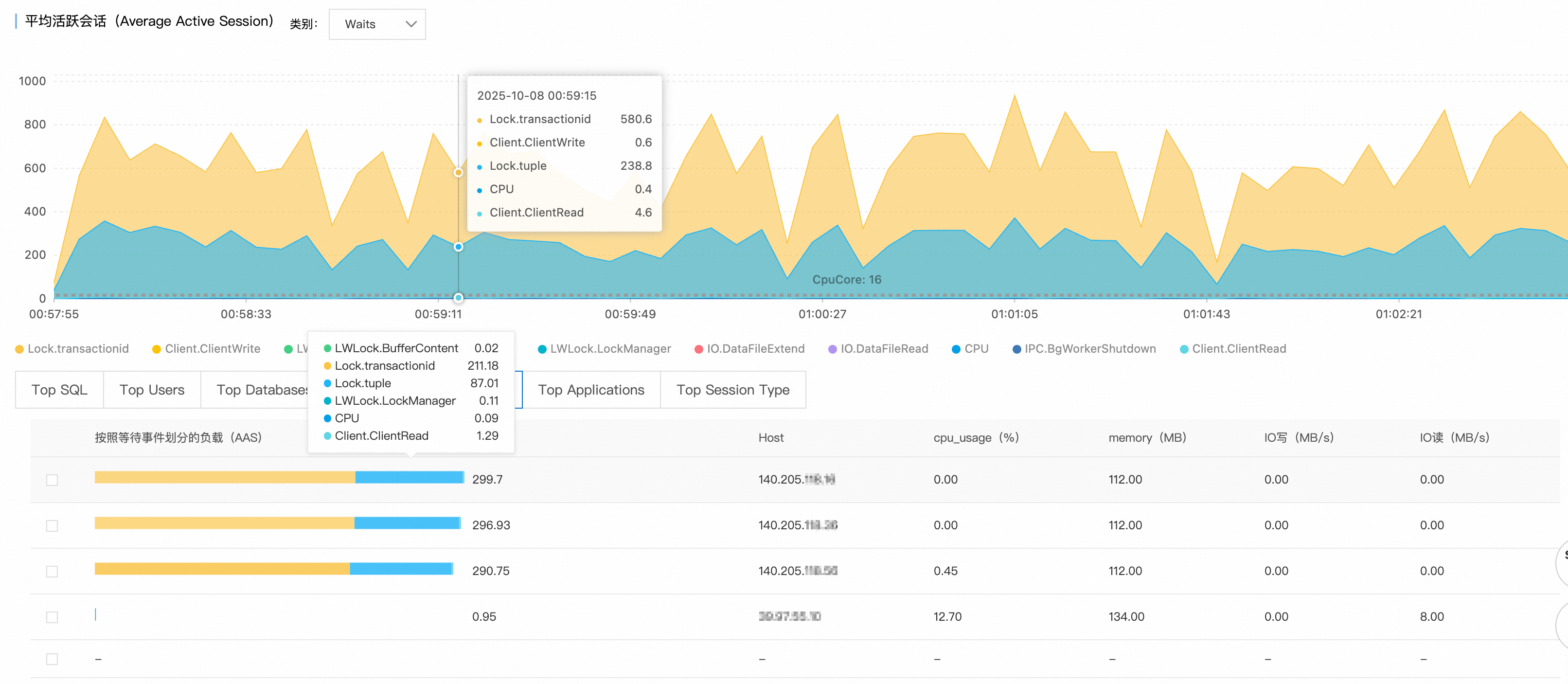
步驟4:來源追溯
結合Top Hosts和Top Databases資料,鎖定問題源頭:
異常用戶端:
140.205.XXX.XXX目標資料庫:
perf_test
根因分析
故障類型:鎖爭用雪崩
技術原理:
觸發原因:用戶端對
perf_test資料庫發起高並發DML操作,可能涉及熱點行更新或大交易處理失控機制:PostgreSQL的鎖管理機制中,當多個事務競爭相同資源時,後續事務將進入等待隊列。由於缺乏串連數限制和鎖等待逾時控制,新串連持續湧入,形成鎖等待的惡性迴圈。
解決方案
即時措施:
限制異常用戶端IP的串連數:
ALTER ROLE target_user CONNECTION LIMIT 10; -- target_user:資料庫使用者名稱終止長時間等待的會話:
-- 先查看要終止的會話詳情 SELECT pid, -- 進程ID(會話標識) usename, -- 資料庫使用者名稱 state, -- 工作階段狀態(active/idle等) wait_event, -- 等待事件具體類型 now() - query_start AS query_duration, -- 當前查詢已執行時間長度 left(query, 50) AS query_preview -- SQL語句預覽(前50字元) FROM pg_stat_activity WHERE datname = 'perf_test' -- 限定資料庫名稱 AND client_addr = '140.205.XXX.XXX' -- 限定用戶端IP地址 AND state = 'active' -- 僅查詢活躍狀態的會話 AND wait_event_type = 'Lock' -- 僅查詢正在等待鎖的會話 AND pid <> pg_backend_pid() -- 排除當前執行此查詢的會話(避免自殺) AND now() - query_start > interval '5 minutes'; -- 查詢執行時間長度超過5分鐘 -- 確認無誤後再執行終止 SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'perf_test' AND client_addr = '140.205.XXX.XXX' AND state = 'active' AND wait_event_type = 'Lock' AND pid <> pg_backend_pid() AND now() - query_start > interval '5 minutes'; -- 確認目標會話是否已清理 SELECT pid, usename, state, query FROM pg_stat_activity WHERE datname = 'perf_test' AND client_addr = '140.205.XXX.XXX';
長期最佳化:
串連池配置:部署PgBouncer等串連池,控制最大並發串連數。
逾時參數調優:
-- 設定鎖等待逾時 ALTER DATABASE perf_test SET lock_timeout = '30s'; -- 設定語句執行逾時 ALTER DATABASE perf_test SET statement_timeout = '60s';應用程式層最佳化:
減小事務粒度,避免長事務。
使用樂觀鎖或分布式鎖機制處理熱點資料。
實施讀寫分離,將唯讀查詢分流至從庫。
監控警示:配置活躍串連數和鎖等待時間的監控閾值,實現故障預警。
通過這種系統性的診斷方法,可以快速定位PostgreSQL效能問題的根本原因,並制定針對性的解決方案。