概述
我們可以將關聯式模式的計算邏輯簡單歸納為如下2點:
只有當前查詢的欄位和關聯欄位參與計算(若查詢中只包含其中1張邏輯表的欄位,則關聯式模式中其他邏輯表不會參與計算)
保證度量欄位的完整性
大致的處理流程如下圖所示,相比於直接物理關聯,關聯式模式可以有效避免資料膨脹:
以上只是關聯式模式處理邏輯的簡單介紹,在實際情境中,不同的關聯基數、資料匹配度,以及拖入不同種類的欄位都會觸發不同的處理方法,可參考以下的具體樣本。
以具體的例子介紹
模型配置
資料表欄位
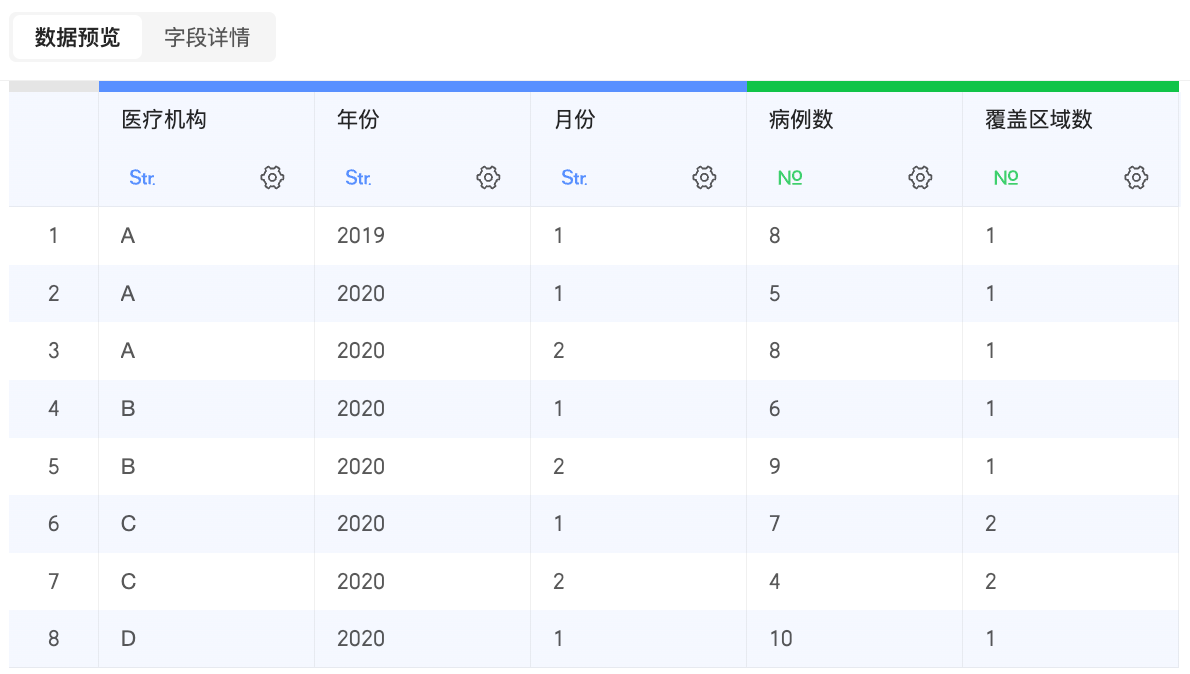
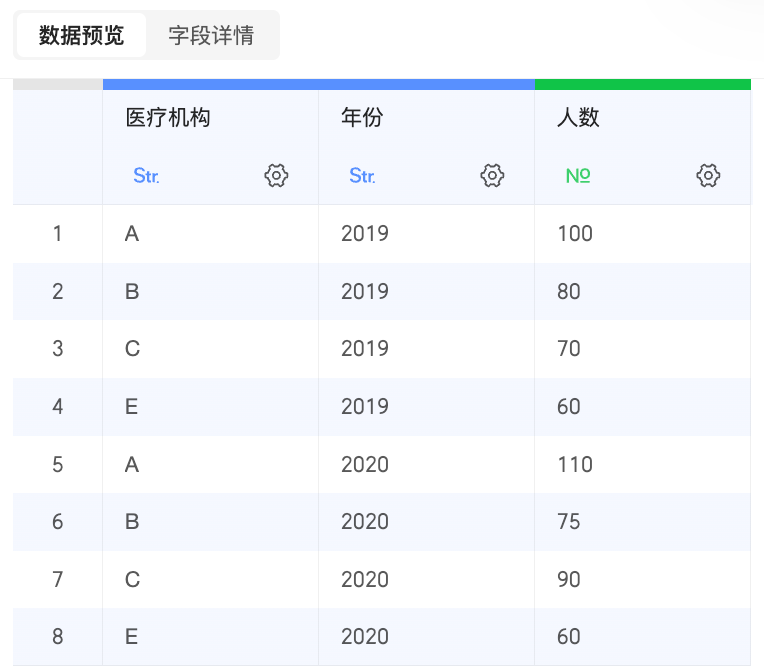
主表:病例表 | 從表:人數表 |
|
|
關聯式模式結構
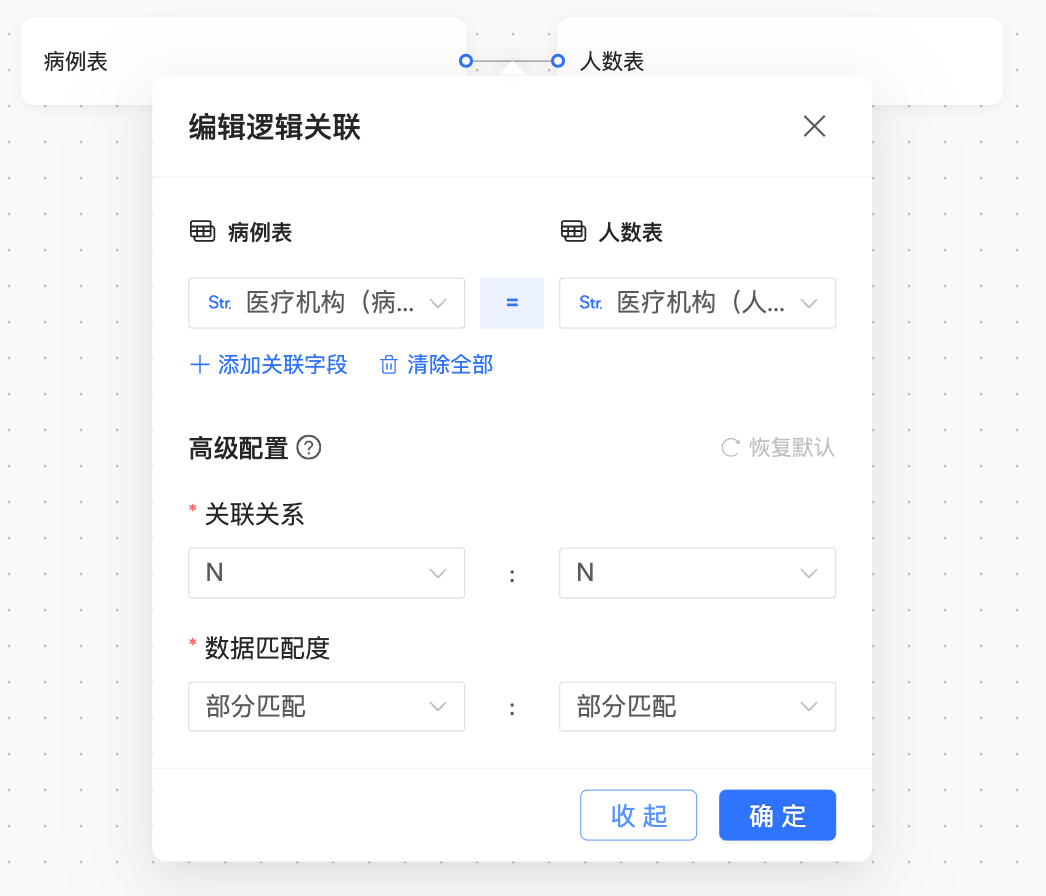
其中:
關聯鍵:醫學機構 = 醫學機構
關聯關係:N:N
資料匹配度:部分匹配:部分匹配
圖表配置及計算方法
只使用單表欄位:從單表中取數,不做關聯
圖表配置
維度 | 醫學機構(人數表)、年份(人數表) |
度量 | 人數-求和(人數表) |
結果資料

使用多表欄位,只有維度:通過INNER JOIN進行關聯
圖表配置
維度 | 月份(病例表)、年份(人數表) |
度量 | - |
結果資料
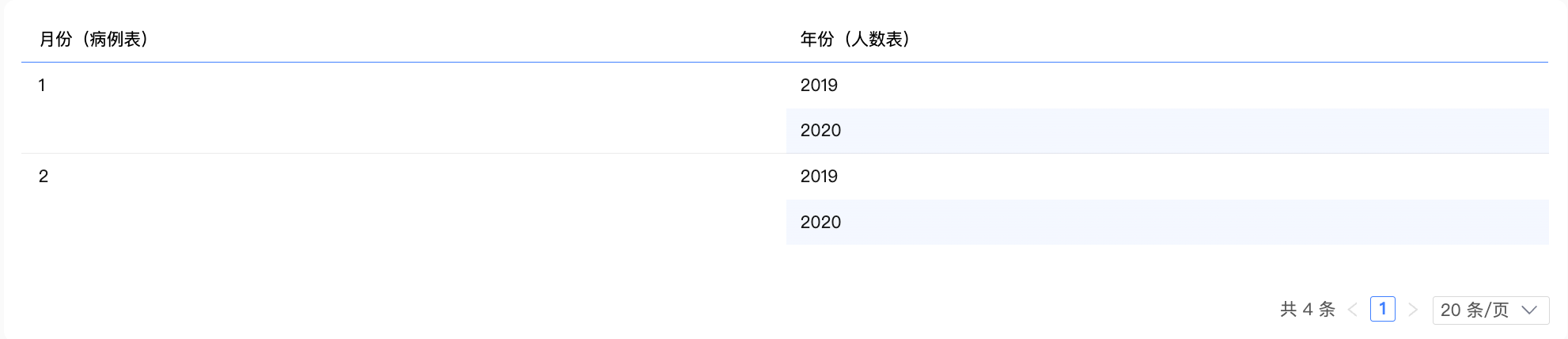
解釋說明
使用INNER JOIN:圖表中只有維度時,我們認為必須能夠匹配上的資料才是有意義的,無法匹配的資料(比如醫學機構D和E)是沒有意義的。
2張表通過“醫學機構”欄位進行內關聯,形成中間過程如下,去重後,展示結果資料。
醫學機構(病例表)
月份(病例表)
醫學機構(人數表)
年份(人數表)
A
1
A
2020
A
1
A
2019
B
1
B
2020
B
1
B
2019
C
1
C
2020
C
1
C
2019
A
2
A
2020
A
2
A
2019
B
2
B
2020
B
2
B
2019
C
2
C
2020
C
2
C
2019
A
1
A
2020
A
1
A
2019
使用多表欄位,只有度量:兩表資料分別彙總後再拼接
圖表配置
維度 | - |
度量 | 病例數-求和(病例表)、人數-求和(人數表) |
結果資料

解釋說明
只有度量,沒有維度時,彙總後只會有1行資料。
此時只需要病例表、人數表的度量分別進行彙總,拼接展示即可。
使用多表欄位,包含維度和度量
樣本1 - 左表維度(關聯鍵)、右表度量
圖表配置
維度 | 醫學機構(病例表) |
度量 | 人數-求和(人數表) |
結果資料

解釋說明
第1步:取圖表中的維度欄位【醫學機構(病例表)】和度量所在表的關聯欄位【醫學機構(人數表)】,計算出維度組合。
因為該查詢中包含了“人數表”的度量,所以在該步驟進行關聯時需要保留“人數表”完整的維度,從而保證後續的計算中“人數表”的度量也是完整的。
醫學機構(人數表) | 醫學機構(病例表) |
A | A |
B | B |
C | C |
E | - |
第2步:將維度組合關聯到“人數表”,形成中間表。由於只關聯了維度組合,且維度組合中每個“醫學機構”都只有唯一一行,此時並不會產生資料膨脹。
醫學機構(人數表) | 醫學機構(病例表) | 人數(人數表) |
A | A | 100 |
B | B | 80 |
C | C | 70 |
A | A | 110 |
B | B | 75 |
C | C | 90 |
- | E | 60 |
- | E | 60 |
第3步:將中間表按照圖表中拖入的維度進行彙總,得出最終結果。
因“醫學機構E”未能與“醫學資料”匹配,因此結果中會存在一行資料,醫學機構為空白值。
樣本2 - 左表維度(非關聯鍵)、右表度量【錯誤示範】
圖表配置
維度 | 年份(病例表) |
度量 | 人數-求和(人數表) |
結果資料

解釋說明
第1步:取圖表中的維度欄位【年份(病例表)】和度量所在表的關聯欄位【醫學機構(人數表)】,計算出維度組合(為了便於理解,此處我們把【醫學機構(病例表)】也展示出來)。
因為該查詢中包含了“人數表”的度量,所以在該步驟進行關聯時需要保留“人數表”完整的維度,從而保證後續的計算中“人數表”的度量也是完整的。
醫學機構(人數表) | 醫學機構(病例表) | 年份(病例表) |
A | A | 2019 |
A | A | 2020 |
B | B | 2020 |
C | C | 2020 |
E | - | - |
由於在“病例表”中,醫學機構A有2019、2020兩行資料,導致維度組合中“醫學機構(人數表)”出現2行“A”。
第2步:將維度組合關聯到“人數表”,形成中間表。
年份(病例表) | 醫學機構(人數表) | 人數(人數表) |
2019 | A | 100 |
2020 | A | 100 |
2020 | B | 80 |
2020 | C | 70 |
2019 | A | 110 |
2020 | A | 110 |
2020 | B | 75 |
2020 | C | 90 |
- | E | 60 |
- | E | 60 |
維度資料表中重複的2行“A”在關聯到人數表時,將會造成“醫學機構A”的人數產生重複行,這將導致最終結果的膨脹。
第3步:將中間表按照圖表中拖入的維度進行彙總,得出最終結果。
在該情境中,即使使用者使用了關聯式模式,卻還是造成了資料膨脹。為儘可能規避類似的問題,我們建議:
關聯鍵配置正確:比如在當前樣本中,應當把“醫學機構”、“年份”設定成關聯鍵,這樣在“第2步”產生中間表時,將不會形成錯誤的資料膨脹。
在不需要跨表的情況下,使用同一個邏輯表中的維度、度量:比如在當前樣本中,選擇“人數表”中的醫學機構、人數進行查詢,資料將能正確呈現。
樣本3 - 右表維度(非關聯鍵)、左表度量【錯誤示範】
圖表配置
維度 | 年份(人數表) |
度量 | 覆蓋地區數-求和(病例表) |
結果資料

解釋說明
第1步:取圖表中的維度欄位【年份(人數表)】和度量所在表的關聯欄位【醫學機構(病例表)】,計算出維度組合(為了便於理解,此處我們把【醫學機構(人數表)】也展示出來)。
因為該查詢中包含了“病例表”的度量,所以在該步驟進行關聯時需要保留“病例表”完整的維度,從而保證後續的計算中“病例表”的度量也是完整的。
醫學機構(病例表) | 醫學機構(人數表) | 年份(人數表) |
A | A | 2020 |
A | A | 2019 |
B | B | 2020 |
B | B | 2019 |
C | C | 2020 |
C | C | 2019 |
D | - | - |
由於在“人數表”中,醫學機構A、B、C、E都有2019、2020兩行資料,導致維度組合中“醫學機構(病例表)”出現2行“A”、2行“B”和2行“C”(醫學機構E沒有關聯上)。
第2步:將維度組合關聯到“病例表”,形成中間表。
醫學機構(病例表) | 年份(人數表) | 覆蓋地區數(病例表) |
A | 2020 | 1 |
A | 2019 | 1 |
B | 2020 | 1 |
B | 2019 | 1 |
C | 2020 | 2 |
C | 2019 | 2 |
A | 2020 | 1 |
A | 2019 | 1 |
B | 2020 | 1 |
B | 2019 | 1 |
C | 2020 | 2 |
C | 2019 | 2 |
D | - | 1 |
A | 2020 | 1 |
A | 2019 | 1 |
維度資料表中重複的醫學機構A、B、C在關聯到病例表時,將會造成的覆蓋地區數產生重複行,這將導致最終結果的膨脹。
第3步:將中間表按照圖表中拖入的維度進行彙總,得出最終結果。
該查詢對醫學機構A、B、C的“覆蓋地區總數”都進行了重複計算,導致資料不正確,原因和建議同“樣本2”
關聯鍵配置正確:應當把“醫學機構”、“年份”設定成關聯鍵。
在不需要跨表的情況下,使用同一個邏輯表中的維度、度量:應當選擇“病例表”中的年份、覆蓋地區數進行查詢。
與物理建模對比
Quick BI舊版本提供的資料集建模能力是物理建模,即:通過可視化配置,構造出多表關聯、合并的資料集模型,形成一整張資料大寬表。
物理建模需要明確指定關聯方式,如:左關聯(Left Join)、內關聯(Inner Join)、全關聯(Full Join)等等,這要求使用者在進行資料建模時,對資料情況要有清晰的掌控,對資料完整性、唯一性進行提前處理,否則將出現嚴重的資料膨脹等問題。
以具體的例子介紹
模型配置
資料表欄位
主表:病例表 | 從表:人數表 |
|
|
物理模型結構
物理模型寬表
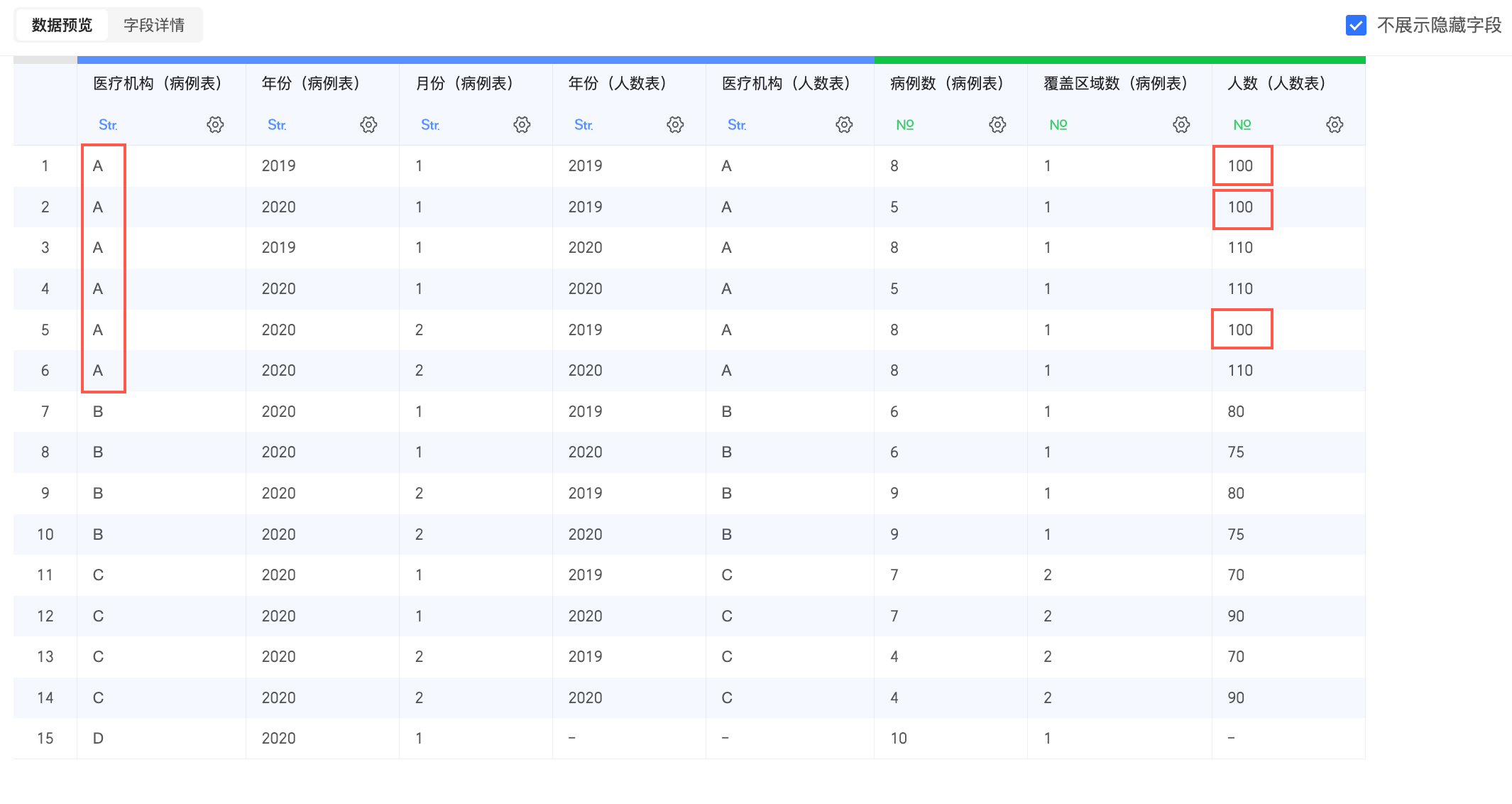
因“醫學機構”欄位不唯一,在物理建模後出現嚴重的資料膨脹,比如下圖中醫學機構為“A”,年份(人數表)為“2019”的人數(人數表),被錯誤地計算了3次。
圖表配置及計算方法
樣本1
圖表配置
維度 | 醫學機構(病例表) |
度量 | 人數-求和(人數表) |
結果資料

正確結果
樣本2
圖表配置
維度 | 年份(病例表) |
度量 | 人數-求和(人數表) |
結果資料

正確結果
物理建模缺點
物理建模時,需要使用者自己對建模結果的正確性進行判斷和把控。當資料不唯一,或存在資料缺失時,需要使用者進行特殊的處理來避免資料錯誤,比如:
關聯前,通過SQL對不唯一的資料進行彙總
通過LOD函數指定彙總粒度,避免最終的計算結果錯誤
通過SQL對缺失資料進行補充,或根據資料缺失情況調整關聯方式,避免資料丟失
以上操作都需要一定的SQL處理能力,對於零基礎的業務人員來說是比較困難的。並且,在物理建模的過程中,使用者需要反覆核對結果以保證正確性,非常繁瑣和複雜。
由於物理建模的特性,當關聯的資料表越多時,越容易出現資料膨脹的問題。而且當建模複雜時,問題的排查和解決也將變得困難。因此,物理建模適用於針對獨立的分析情境分別建模,從而儘可能減少關聯表的數量。這就導致資料集的數量隨著分析情境變多而逐漸堆積,最終難以治理和維護。
關聯式模式特殊說明
跨表欄位的處理
當計算欄位運算式中使用了來自多個邏輯表的欄位時,將產生跨表欄位。跨表欄位不屬於任何一張邏輯表,在資料集中將單獨歸類。
跨表欄位的計算一定會涉及到多個邏輯表,並且依賴當前邏輯表的關聯方式(取決於參與計算的度量、維度)。換句話說,只有在明確的查詢情境下才能計算出跨表欄位的資料,因此跨表欄位無法進行明細的預覽。
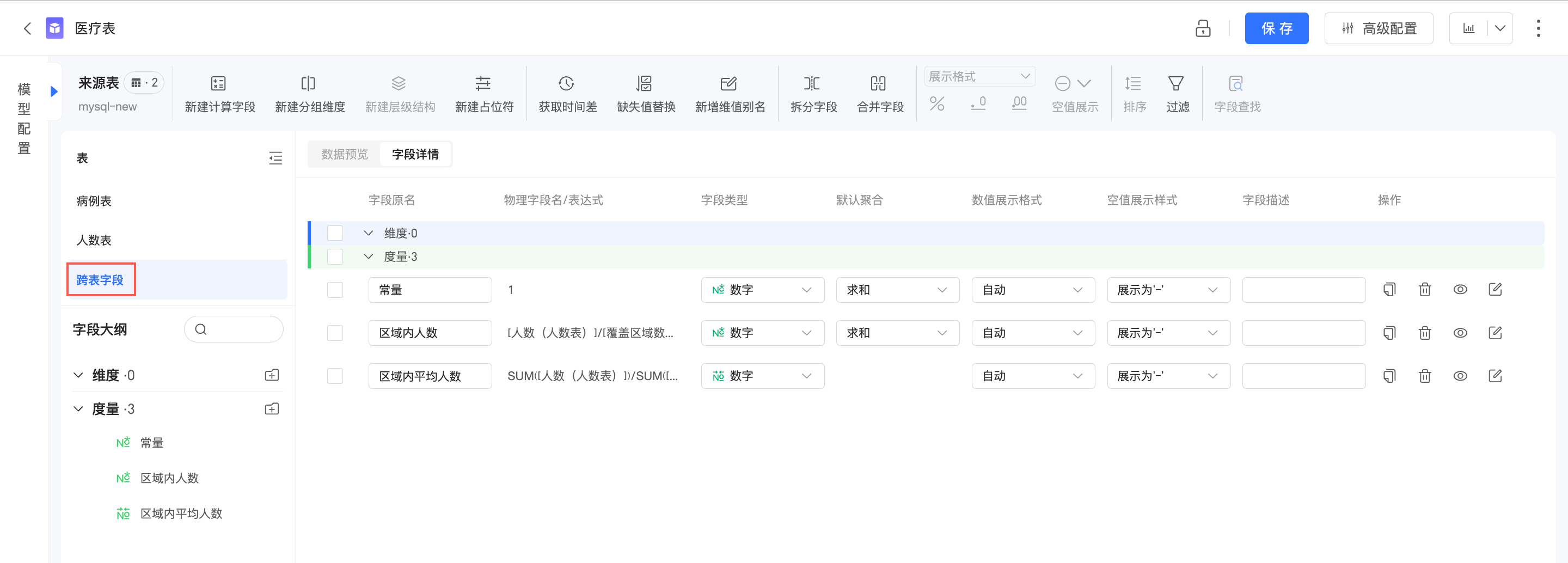
彙總後跨表
當單表的欄位分別彙總後再進行跨表的加減乘除計算時,該計算欄位為彙總後的跨表計算欄位。
例如:
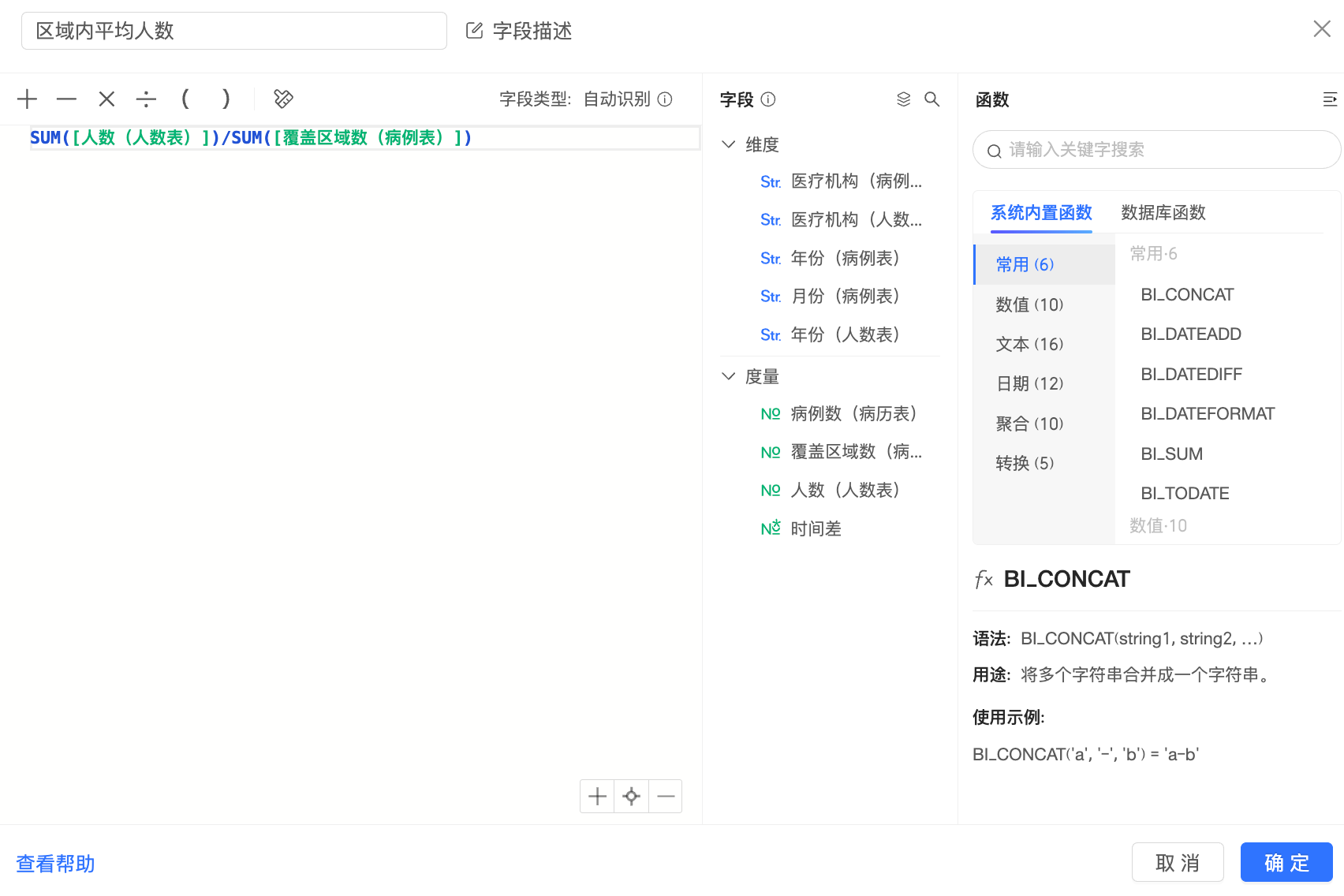
該欄位在計算時,Quick BI將分別在人數表中計算出SUM([人數(人數表)]),在病例表中計算出SUM([覆蓋地區數(病例表)]),得到2份中間表如下:
醫學機構(病例表) | SUM(人數(人數表)) |
A | 210 |
B | 155 |
C | 160 |
- | 120 |
醫學機構(病例表) | SUM(覆蓋地區數(病例表)) |
A | 3 |
B | 2 |
C | 4 |
D | 1 |
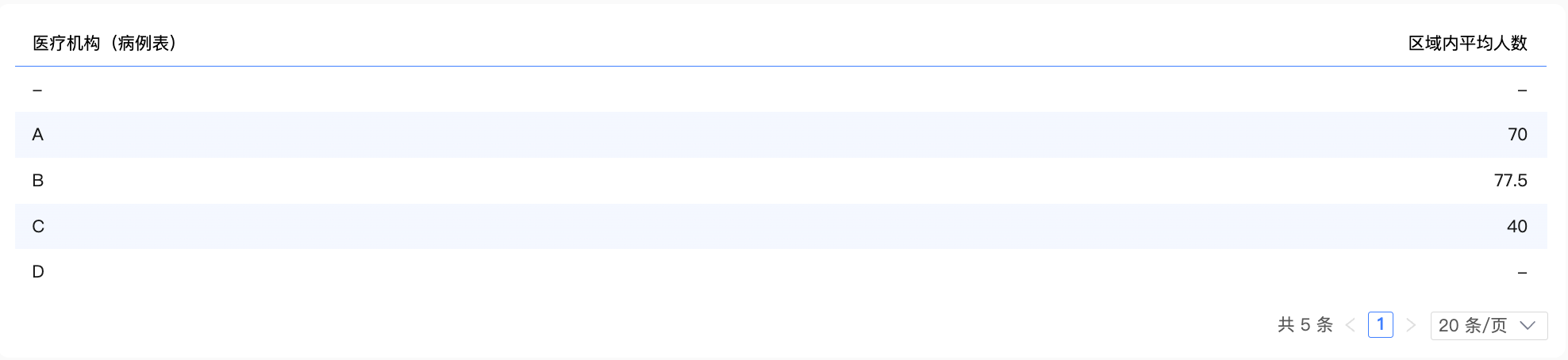
之後,將2份中間表進行關聯,並進行除法計算求出最終結果。
明細跨表
當單表的欄位直接在明細層進行跨表的加減乘除計算時,該計算欄位為明細的跨表計算欄位。
例如:
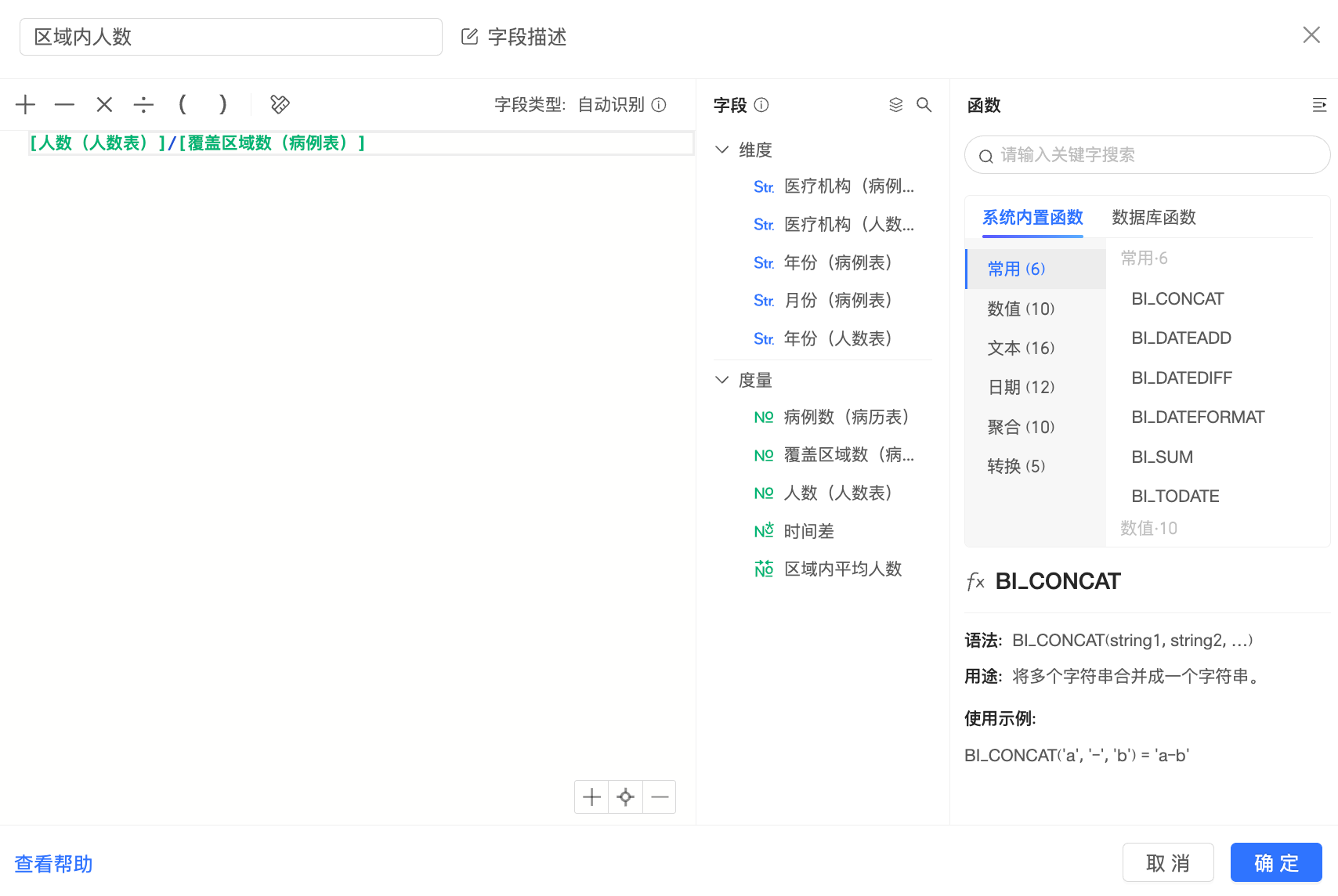
該欄位在計算時,Quick BI會先將“病例表”和“人數表”根據關聯鍵進行關聯,得到中間表:
醫學機構(病例表) | 覆蓋地區數(病例表) | 醫學機構(人數表) | 人數(人數表) |
A | 1 | A | 110 |
A | 1 | A | 100 |
B | 1 | B | 75 |
B | 1 | B | 80 |
C | 2 | C | 90 |
C | 2 | C | 70 |
A | 1 | A | 110 |
A | 1 | A | 100 |
B | 1 | B | 75 |
B | 1 | B | 80 |
C | 2 | C | 90 |
C | 2 | C | 70 |
A | 1 | A | 110 |
A | 1 | A | 100 |
在該中間表的基礎上,計算除法,之後根據圖表中的維度進行彙總,得到最終結果:

常量的處理
在關聯式模式中,常量(純文字、純數字等)將被處理為跨表欄位,但計算方式與跨表欄位也有所不同。
比如:在關聯式模式資料集中建立常量“1”,該欄位將落入“跨表欄位”中:
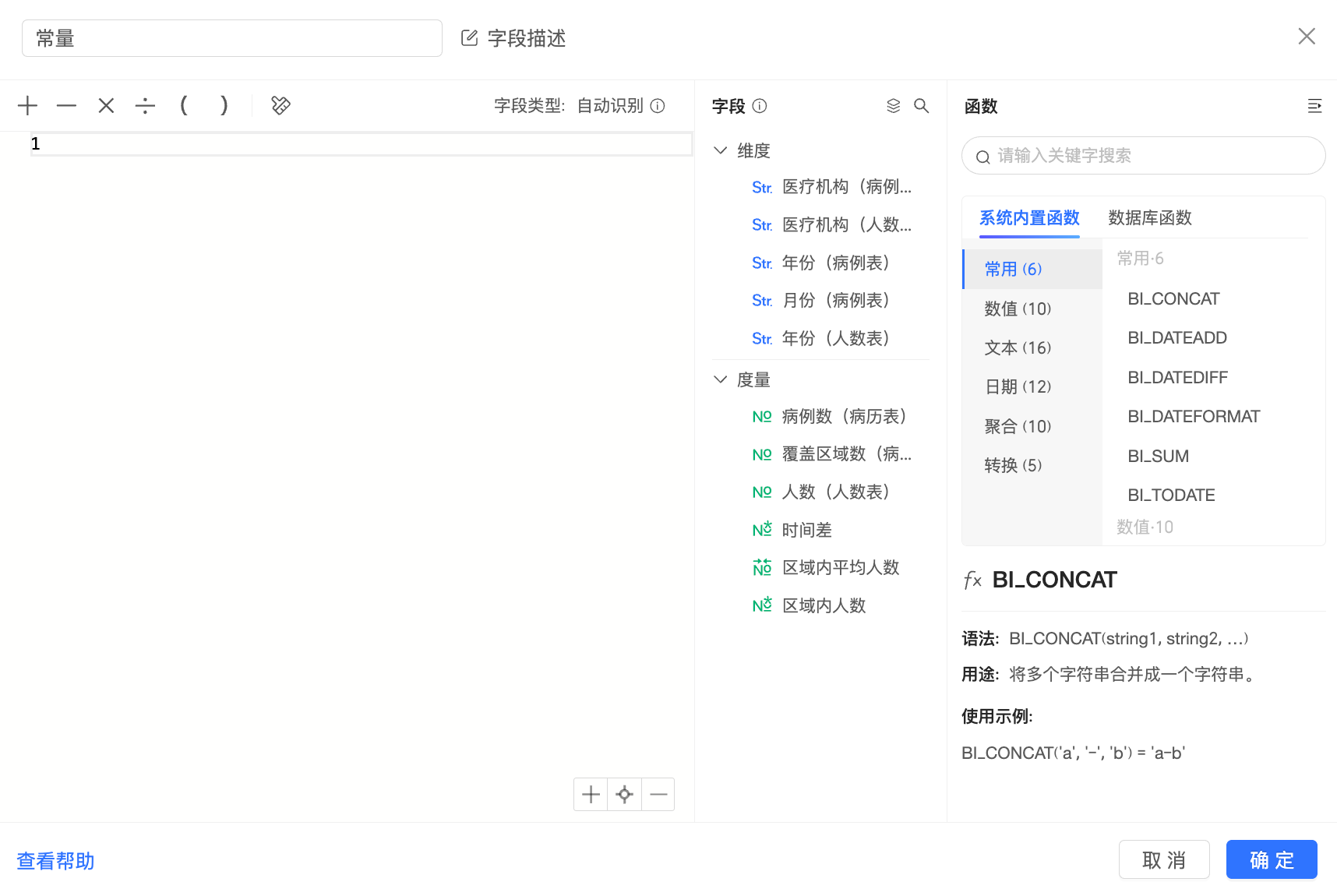
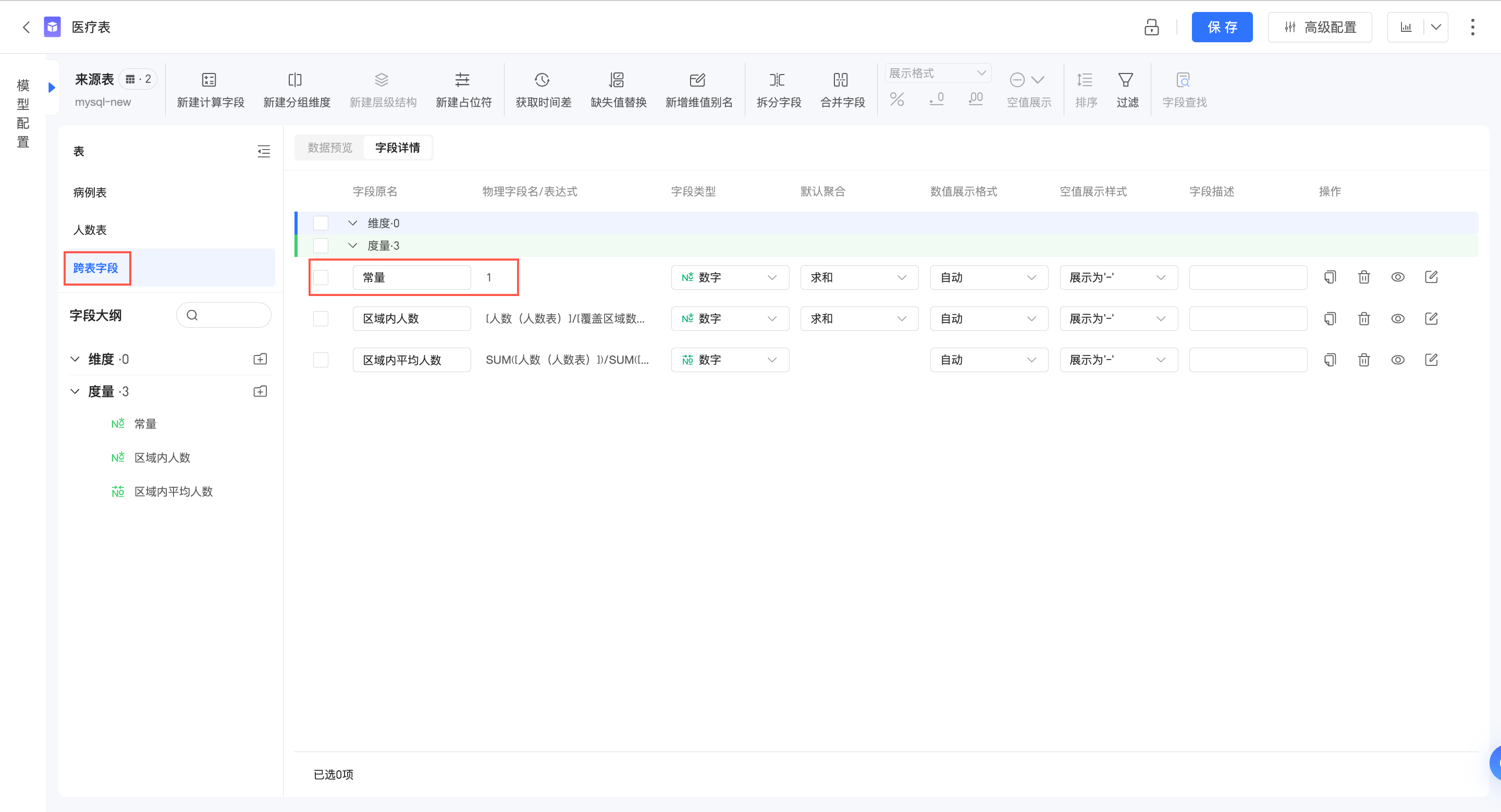
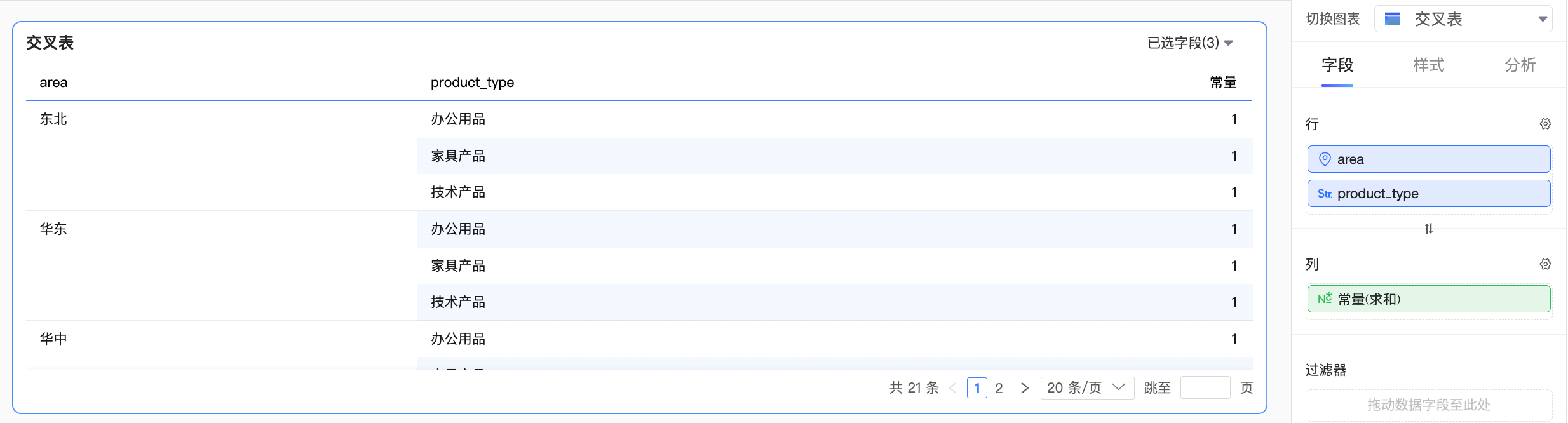
當常量與某一個邏輯表的欄位組合計算
此時,Quick BI將把常量處理為單表內的欄位,整體的計算按照單表查詢進行處理,效果如下:
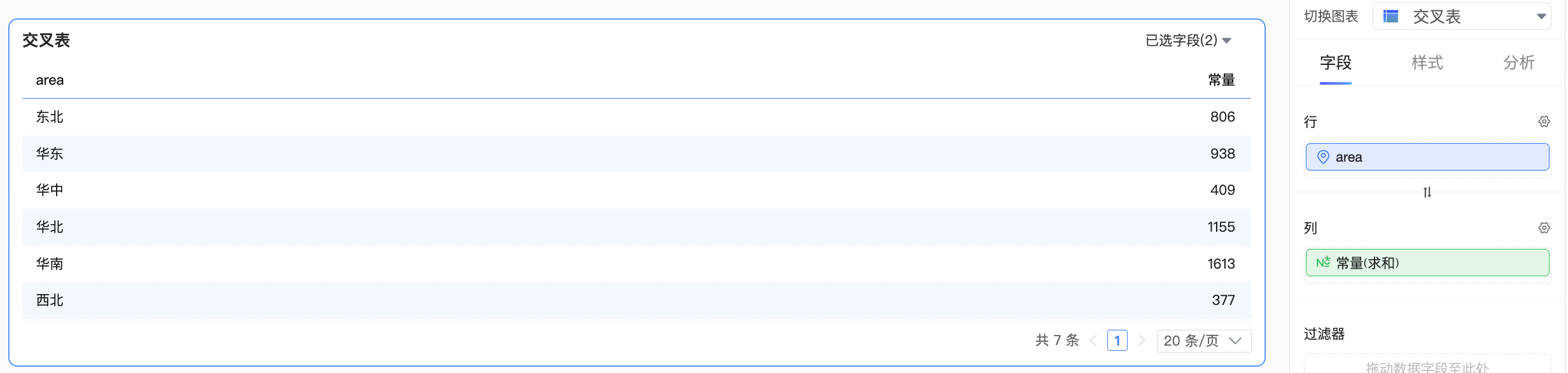
當常量與多個邏輯表的欄位組合計算
此時,該如何對常量進行處理會變得不明確。若將常量作為其中某一個表內的欄位去計算,那麼該歸屬於哪張表呢?常量歸屬於不同表時,計算的結果也會有所不同,這不一定符合使用者預期。
因此,在這種情境下,Quick BI將會把常量當作跨表欄位去處理。而此時,常量與所有表中的維度都失去了關聯性,因此不會參與到彙總計算中,效果如下: