本文介紹了向量金字塔模型的用途、基本構成和快速入門等內容。
模型用途
簡介
向量金字塔模型是為了大規模空間幾何資料(千萬級以上)快速顯示而設計的一種結構。向量金字塔可以對空間幾何資料建立稀疏索引、按規則對密集地區預先處理、輸出標準的mvt-pbf格式。通過GanosBase提供的向量金字塔功能,可實現億條空間幾何記錄,分鐘級預先處理,終端秒級顯示的效果。
GanosBase Geometry Pyramid是對象關係型資料庫PostgreSQL相容版本(PolarDB PostgreSQL版)的一個時空引擎擴充,Geometry Pyramid(向量金字塔)通過對一個包含Geometry屬性列的表構建向量金字塔,使用者可以快速查詢得到地圖不同層級的向量瓦片並用於前端繪製查看。和傳統的地圖切片方案相比,GanosBase的向量金字塔具有“快”和“省”的優勢:
“快”是指構建效率高,實測在一台配置普通的8核PolarDB PostgreSQL版叢集上,僅需6分鐘即可完成構建七千萬房屋面資料的向量金字塔。
“省”是指儲存開銷小,向量金字塔忽略資料量稀疏的地區,僅儲存包含資料量較多的向量瓦片,有效地節省了儲存成本。
功能概述
向量金字塔的使用分為建立、查詢、更新,以及刪除四個部分。
建立:使用ST_BuildPyramid函數或ST_BuildPyramidUseGeomSideLen函數對包含Geometry對象的表建立向量金字塔,要求已經有Geometry列的空間索引。
查詢:使用ST_Tile函數或ST_AsPNG函數查詢由參數指定的地圖瓦片,其中ST_Tile返回的是MVT格式的向量瓦片,ST_AsPNG返回的是渲染成PNG格式的圖片。
刪除:使用ST_DeletePyramid函數刪除已有的向量金字塔。
更新:使用ST_UpdatePyramid函數對資料表發生更新的向量金字塔進行更新。
功能詳情請參見Geometry Pyramid SQL參考。
主要業務情境
Geometry對象可以表示現實世界的空間資料實體,如道路、建築物、POI 等。可視化Geometry對象能夠展示不同空間資料實體在地圖上的位置分布,更加直觀地向使用者展示空間資料包含的資訊。向量金字塔可用於任意將資料儲存為Geometry對象且需要高效的資料視覺效果的應用情境。下面分別從可視化點、線、面三種不同類型的Geometry資料來舉例說明向量金字塔的實際應用。
可視化POI、軌跡點
在地圖或移動對象應用情境中,需要處理的資料(POI或者軌跡點)主要是以Geometry Point的形式儲存在資料庫中。通過在資料集上預建向量金字塔,使用者可快速查看POI或者軌跡點在不同地區的密集程度,以此確定不同地區的繁忙程度。
可視化道路、航道線
在出行應用情境中,道路和航運公司的航道線主要是以Geometry Linestring的形式儲存在資料庫中。通過向量金字塔,使用者可以快速查看不同道路和航道線路的分布情況,從而更好地規划出行路線,效果圖如下所示:
可視化房屋、河流、林地
在城市規劃情境中,房屋、河流和林地這些資料常以Geometry Polygon的形式儲存在資料庫中。向量金字塔可以讓使用者快速查看城市或更大範圍內的建築、河流等分布情況,助力使用者做出決策,效果圖如下所示:
基本構成
概念
向量切片
向量切片是指把待顯示的資料的向量資訊寫入名為向量瓦片的載體上,寫入的資訊包括向量的類型(點、線或者面)、組成向量的各個點在向量瓦片上的相對座標等。使用者的前端軟體(瀏覽器或者GIS軟體)能夠把向量瓦片裡的向量資訊提取出來,把每個向量根據使用者自訂的顯示樣式(點或者線的顏色、面的填充色等)繪製出來。通俗的理解是,向量瓦片告訴前端軟體應該給使用者看哪些東西,然後前端軟體根據使用者指定的繪畫風格一筆一畫地畫出來。由於現在的硬體發展,使用者端軟體能夠高效率地完成向量瓦片的繪製,因此向量切片因其顯示效果好的優點受到越來越多使用者的青睞。
MVT
MVT(Mapbox Vector Tile)是一套廣泛採用的用於儲存和傳輸向量瓦片的格式,其定義了對一組向量要素及其屬性資訊的編碼方法。MVT的內部結構包含一組命名的圖層。每個圖層包含幾何要素和中繼資料資訊,其中幾何要素部分包含幾何類型的編碼、座標的編碼、命令的編碼(MoveTo、LineTo、ClosePath等)等,中繼資料資訊部分以索引值對的形式分別記錄屬性名稱和屬性值。主流的前端軟體都支援MVT,因此本文後面會使用MVT來代指向量瓦片。
動態向量瓦片
動態向量瓦片是指資料庫在執行使用者的可視化請求時,線上完成讀取待可視化的資料和將資料打包成MVT並返回的過程。以PostGIS為例,整個過程大致分為三步:
根據向量瓦片的空間範圍進行空間查詢,從資料表中拿到待可視化的Geometry對象。
將獲得的Geometry對象按照向量瓦片的空間範圍進行座標轉換,其中還涉及到對Geometry對象的簡化和過濾,這個過程由ST_AsMVTGeom函數完成。
將上一步的眾多Geometry對象按照MVT規範編碼、打包放到一個二進位結構裡,這個過程由ST_AsMVT函數完成。
GanosBase的快顯引擎針對上述三個步驟都提供了相關函數來改進PostGIS的可視化效率:
使用ST_IsRandomSampled函數僅讀取隨機採樣後的Geometry對象。
使用ST_AsMVTGeomEx函數過濾轉換到MVT座標系後像素數很少的Geometry對象。
使用ST_AsMVTEx函數過濾可視化後視覺上不重要的Geometry對象。
使用者可根據需要使用其中的一個或多個函數來提升動態向量瓦片的效率。
預切片
預切片是指離線產生MVT並將其儲存起來,在使用者的可視化請求到來時返回相應的MVT給使用者。
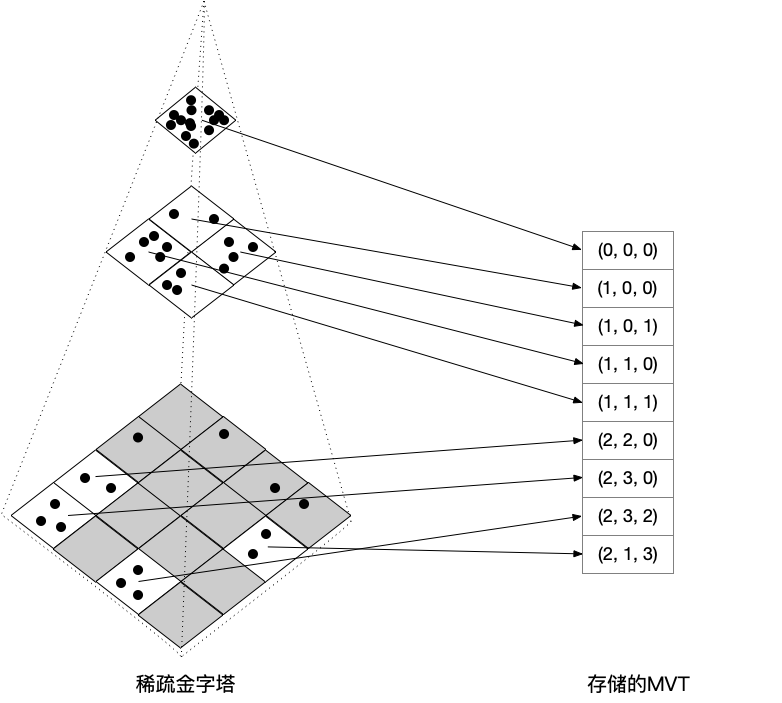
稀疏金字塔
GanosBase的向量金字塔技術採用了稀疏金字塔的結構,將預切片和動態向量瓦片結合起來,僅在資料密集的地區離線產生和儲存MVT,而資料稀疏的地區採用動態向量瓦片。下圖是稀疏金字塔的示意圖。只有包含兩個或以上Geometry對象的MVT會被儲存起來,在查詢這些MVT時,GanosBase可以直接從表中讀出對應的MVT返回給使用者。灰色的地區表示資料稀疏地區,執行可視化查詢時,GanosBase會動態產生這些地區的MVT。
渲染
前端軟體接收到MVT後,需要將MVT包含的資訊繪製成使用者可看的映像,這個過程被稱為渲染。MVT的渲染通常是由前端軟體來完成的,而GanosBase的向量金字塔技術既支援發送MVT交由前端軟體渲染,也支援在資料庫端將MVT渲染成圖片後再交給前端軟體直接給使用者查看。
流程
向量金字塔的使用流程為建立向量金字塔和查詢向量金字塔。如果建立金字塔後,資料表發生了更新,在查詢前需要先更新向量金字塔。
對比
和向量金字塔相比,動態瓦片無需事先構建任何其它結構即可使用(出於效能考慮,建議對Geometry列構建空間索引),但是在執行可視化請求時會多出讀取瓦片範圍內的Geometry資料以及線上產生MVT的開銷。另外,動態瓦片無需考慮資料更新問題,而向量金字塔在資料更新後,需要調用ST_UpdatePyramid函數進行更新。建議使用者先使用動態瓦片確認效能是否符合需求,若效能不符合預期,可考慮使用向量金字塔。
快速入門
簡介
快速入門文檔協助使用者快速理解GanosBase Geometry Pyramid引擎的基本用法,包括擴充建立、建立金字塔、讀取瓦片資料、更新金字塔、進階功能等部分。
文法說明
建立擴充。
CREATE EXTENSION ganos_geometry_pyramid CASCADE;說明建議將擴充安裝在public模式下,避免許可權問題。
CREATE extension ganos_geometry_pyramid WITH schema public;為空白間表建立金字塔。
-- 為資料表 test 建立金字塔 -- 指定表 test 的要素id欄位名, 必須為int4/int8類型 -- 指定表 test 的空間欄位名稱, 需要先為該欄位建立空間索引 -- 以JSON形式說明Geometry的座標係為EPSG:4326 SELECT ST_BuildPyramid('test', 'geom', 'id', '{"sourceSRS":4326}');從金字塔中讀取MVT資料。
-- 從金字塔中讀取瓦片編號為 '0_0_0' 的資料(任意編號,不管金字塔中是否存在,都可返回資料) -- 瓦片編號方式為: z_x_y,預設投影座標係為EPSG:3857 SELECT ST_Tile('test', '0_0_0');更新金字塔。
當資料表的資料發生更新時,需要對金字塔進行更新才能看到更新後的地圖可視化結果。使用者需要以參數形式傳入發生資料更新的空間範圍,調用ST_UpdatePyramid函數更新金字塔。
-- 在局部空間範圍插入入3條新的Geometry對象 INSERT INTO test(id, geom) VALUES (1, ST_GeomFromEWKT('SRID=4326;POINT(10.1 10.1)')); INSERT INTO test(id, geom) VALUES (2, ST_GeomFromEWKT('SRID=4326;LINESTRING(10.1 10.1,11 11)')); INSERT INTO test(id, geom) VALUES (3, ST_GeomFromEWKT('SRID=4326;POLYGON((10 10,11 11,11 12,10 10))')); -- 更新向量金字塔,資料修改範圍由一個Box2D參數指定 SELECT ST_UpdatePyramid('test', 'geom', 'id', ST_SetSRID(ST_MakeBox2D(ST_Point(9, 9), ST_Point(12, 12)), 4326));ST_UpdatePyramid函數適用於資料表的更新發生在一個局部空間地區內的應用情境。例如,更新地區的面積不足全域面積的百分之一,此時ST_UpdatePyramid函數能夠高效完成金字塔的更新。若資料表發生大空間範圍的資料更新,建議使用ST_BuildPyramid函數重建新的金字塔。
-- 插入3條分布在不同地區的Geometry對象 INSERT INTO test(id, geom) VALUES (4, ST_GeomFromEWKT('SRID=4326;POINT(-59 -45)')); INSERT INTO test(id, geom) VALUES (5, ST_GeomFromEWKT('SRID=4326;LINESTRING(110 60,115 70)')); INSERT INTO test(id, geom) VALUES (6, ST_GeomFromEWKT('SRID=4326;POLYGON((-120 59,-110 65,-110 70,-120 59))')); -- 重建金字塔,ST_BuildPyramid會自動刪除舊的金字塔 SELECT ST_BuildPyramid('test', 'geom', 'id', '{"sourceSRS":4326}');刪除金字塔(可選)。
SELECT ST_DeletePyramid('test');刪除擴充(可選)。
DROP EXTENSION ganos_geometry_pyramid CASCADE;
使用進階
為金字塔命名
金字塔預設和資料表同名,也可指定金字塔名稱,實現一份資料,多個金字塔的目的。
-- 為 test 表建立一個名為 hello 的金字塔
SELECT ST_BuildPyramid('test', 'geom', 'id', '{"name": "hello"}');並行構建
指定構建向量金字塔的並行任務數,預設為0(表示並行最大化)。
並行任務數最大不應該超過CPU數量的4倍。
並行構建使用了兩階段事務機制,需要設定
max_prepared_transactions參數。設定資料庫參數
max_prepared_transactions = 100(或者更高,重啟生效)。
-- 使用4個並行任務來構建向量金字塔
SELECT ST_BuildPyramid('test', 'geom', 'id','{"parallel": 4}');瓦片參數
指定瓦片的尺寸、外擴大小。 尺寸最大值為4096,且必須是256的整數倍。 外擴大小最大為256,最小為0。
海量資料全幅顯示,應該設定較小的tileSize,提升分塊渲染並行度和出圖體驗。
-- 指定瓦片的大小為 512,外擴大小為 8
SELECT ST_BuildPyramid('test', 'geom', 'id','{
"tileSize": 512,
"tileExtend": 8
}');金字塔的最大層級
當地圖的zoom層級大於某級時,就不再使用這個圖層、或者不需要產生金字塔,可指定金字塔的最大層級。 如不設定,向量金字塔會根據資料的密度自動計算出合理的最大層級。最大層級的預設值為16。
-- 指定金字塔的最大層級為 12 級,超過12級則會即時讀取資料產生 mvt
SELECT ST_BuildPyramid('test', 'geom', 'id', '{"maxLevel": 12}');分層處理
可為金字塔的每個層級設定不同的處理條件,例如顯示欄位、過濾條件等。
通過添加
buildRules規則,為每個層級設定產生條件。頂層金字塔產生耗時較長,可以通過分層規則跳過頂層的處理。
-- 分層處理產生金字塔
-- 第0層到第5層,不顯示任何資料,設定過濾條件為 "1!=1" 產生空的mvt
-- 第6層到第9層,顯示code=1的資料,並且包含"name"欄位
-- 第10到第15級,無過濾條件,包含"name"、"width"兩個欄位
SELECT ST_BuildPyramid('test', 'geom', 'id', '{
"buildRules":[
{
"level":[0,1,2,3,4,5],
"value": {
"filter": "1!=1"
}
},
{
"level":[6,7,8,9],
"value": {
"filter": "code=1",
"attrFields": ["name"]
}
},
{
"level":[10,11,12,13,14,15],
"value": {
"attrFields": ["name", "width"]
}
}
]
}');提升金字塔的構建和更新效率
除了ST_BuildPyramid函數,GanosBase還提供了ST_BuildPyramidUseGeomSideLen函數來構建金字塔。和ST_BuildPyramid函數相比ST_BuildPyramidUseGeomSideLen函數能夠有效提升金字塔的建立和更新效率。ST_BuildPyramidUseGeomSideLen函數的使用條件是資料表存在一個表示Geometry屬性的x軸或y軸跨度的較大值的列,且為該列建立了一個索引。
-- 為表'test'增加一列'geom_side_len',表示'geom'屬性的x軸或y軸跨度的較大值
ALTER TABLE test
ADD COLUMN geom_side_len DOUBLE PRECISION;
CREATE OR REPLACE FUNCTION add_max_len_values() RETURNS VOID AS $$
DECLARE
t_curs CURSOR FOR
SELECT * FROM test;
t_row test%ROWTYPE;
gm GEOMETRY;
x_min DOUBLE PRECISION;
x_max DOUBLE PRECISION;
y_min DOUBLE PRECISION;
y_max DOUBLE PRECISION;
BEGIN
FOR t_row IN t_curs LOOP
SELECT t_row.geom INTO gm;
SELECT ST_XMin(gm) INTO x_min;
SELECT ST_XMax(gm) INTO x_max;
SELECT ST_YMin(gm) INTO y_min;
SELECT ST_YMax(gm) INTO y_max;
UPDATE test
SET geom_side_len = GREATEST(x_max - x_min, y_max - y_min)
WHERE CURRENT OF t_curs;
END LOOP;
END;
$$ LANGUAGE plpgsql;
SELECT add_max_len_values();
-- 為'geom_side_len'屬性構建B樹索引
CREATE INDEX ON test USING btree(geom_side_len);
-- 指定表示'geom'屬性的x軸或y軸跨度的較大值的列名為'geom_side_len'
SELECT ST_BuildPyramidUseGeomSideLen('roads', 'geom', 'geom_side_len', 'id',
'{"sourceSRS":4326}');進階功能
資料按規則融合
可按屬性規則對瓦片範圍內的資料進行融合,減少資料量。
設定 "buildRules" -> "value" -> "merge" 欄位,添加["code=1","code=2"]兩個條件運算式。
對屬性code的值為1的進行融合,串連空間上有touch關係的點,併合並成一個大的要素。
同樣過程對code值為2的進行融合。
對code值既不等於1、也不等於2的要素不採用融合操作。
-- 將 code=1、code=2 的資料,分別進行融合處理
SELECT ST_BuildPyramid('test', 'geom', 'id', '{
"buildRules":[
{
"level":[0,1,2,3,4,5],
"value": {
"merge": ["code=1","code=2"]
}
}
]
}');SQL參考
詳細SQL手冊請參見Geometry Pyramid SQL參考。