寬表模式中對指定列的統計分析
寬表模式下,一張表擁有數十個列甚至上百個列,但查詢負載中只需要統計/分析部分列,此時可以使用列存索引進行加速。
背景
在很多SaaS業務系統中,一張表有幾十甚至上百個列,在查詢時往往會面臨較大的技術挑戰:
查詢時只需要分析其中的幾個列,但在使用行存結構時,會讀取大量無關的列,增加IO負擔。
查詢模式不固定,上百個列在查詢時會存在多種過濾條件,構建複合式索引時需要預先匹配所有的查詢情境,一旦改變查詢條件,複合式索引將失效。
列存索引可以很好地應對上述兩個情境。由於列存索引的內部結構以列為單位,所以讀取一個列時並不會影響另一個列,同時列之間也沒有循序關聯性,所以多個查詢條件的順序性也不會影響列存索引的效果。
效果展示
在一億條資料規模和4並行度模式下,採用列存索引方式的查詢效能為PostgreSQL原生並存執行的30倍。
查詢語句 | PostgreSQL原生並行 | 列存索引 |
Q1 | 243 s | 7.9 s |
實施步驟
步驟一:環境準備
請確認您的叢集版本與配置是否滿足以下條件:
叢集版本:
PostgreSQL 16(核心小版本為2.0.16.8.3.0及以上)
PostgreSQL 14(核心小版本為2.0.14.10.20.0及以上)
原表必須包含主鍵,且在建立列存索引時需要將主鍵列加入列存索引中。
wal_level參數的值需設定為logical,即在預寫式日誌WAL(Write-Ahead Logging)中增加支援邏輯編碼所需的資訊。說明您可以通過控制台設定wal_level參數。修改該參數後叢集將會重啟,請在修改參數前做好業務安排,謹慎操作。
開啟列存索引功能。
對於不同的PolarDB PostgreSQL版核心版本,開啟列存索引的方式不同:
目前的版本下的PolarDB PostgreSQL版叢集,支援兩種開啟方式,具體差異如下,請按需選擇:
對比項
【推薦】添加列存索引唯讀節點
直接使用預先安裝的列存索引外掛程式
操作方式
通過控制台實現可視化操作,手動添加列存索引節點。
無需任何操作,即可直接使用。
資源分派
列存引擎獨佔所有資源,能夠充分利用所有記憶體。
列存引擎只能使用25%的記憶體,其餘記憶體則分配給行存引擎使用。
業務影響
TP(事務)與AP(分析)業務在不同節點上相互隔離,互不影響。
TP(事務)與AP(分析)業務在同一節點,會互相影響。
費用
需額外收取列存索引唯讀節點的費用,按照普通計算節點收費。
無費用。
添加列存索引唯讀節點
您可選擇以下兩種方式中任意一種方式添加列存索引唯讀節點:
說明叢集中應包含一個唯讀節點,即單節點叢集不支援添加列存索引唯讀節點。
控制台添加
登入PolarDB控制台,選擇叢集所在地區。您可以按照如下兩種方式中的任意一種進入增删节点向导頁面:
在集群列表頁面,單擊操作欄的增删节点。

在目的地組群的基本信息頁面,数据库节点地區,單擊增删节点。

選擇增加列存索引只读节点選項,並單擊确定。
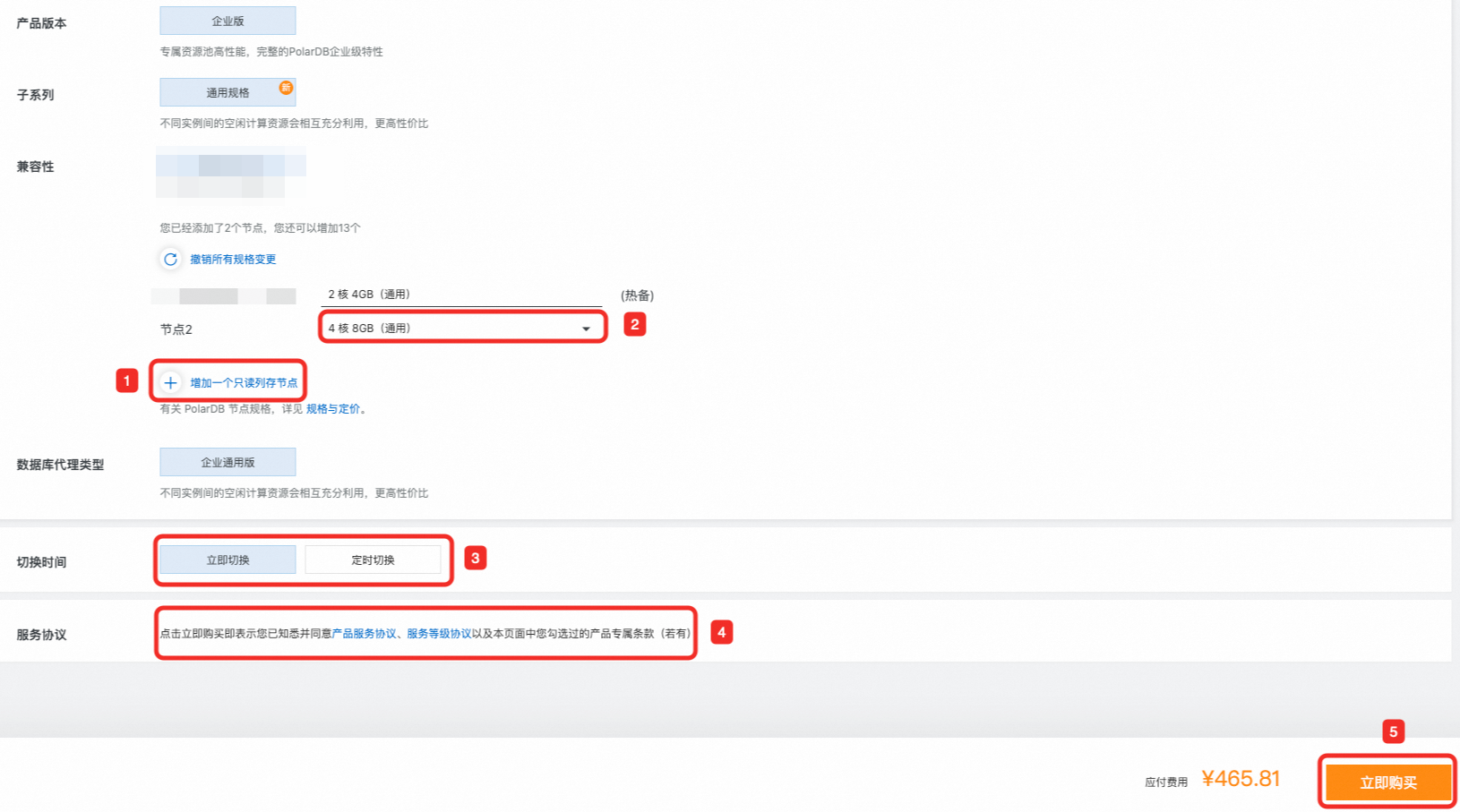
在叢集變更配置頁面,添加列存索引唯讀節點並支付。
單擊增加一个列存索引只读节点,選擇節點規格。
選擇切換時間。
(可選)查看產品服務合約、服務等級協議。
單擊立即购买。
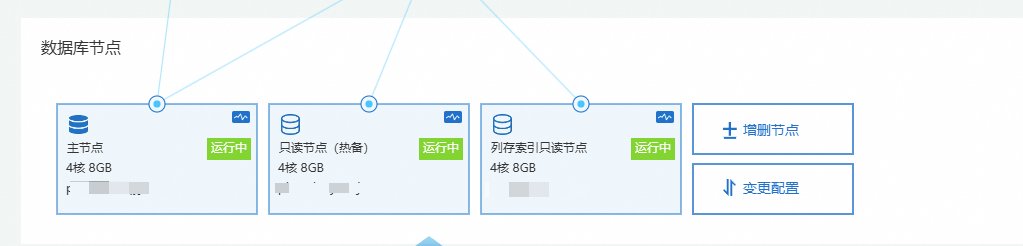
支付完成後,返回叢集詳情頁等待列存索引唯讀節點添加成功,即節點狀態為运行中。
購買時添加
在PolarDB購買頁的节点个数配置項中自行選擇列存索引唯讀節點數量。

目前的版本下的PolarDB PostgreSQL版叢集,列存索引作為外掛程式
polar_csi部署在資料庫叢集中,在使用之前需要在指定的資料庫中建立外掛程式。說明polar_csi外掛程式的範圍是Database層級,如果需要在叢集的多個Database中使用列存索引,需要為每個Database分別建立polar_csi外掛程式。安裝外掛程式使用的資料庫帳號必須為高許可權帳號。
您可以選擇以下兩種方式中的任意一種安裝
polar_csi外掛程式。控制台安裝
登入PolarDB控制台,在左側導覽列單擊集群列表,選擇叢集所在地區,並單擊目的地組群ID進入叢集詳情頁。
在左側導覽列選擇,在管理插件頁簽,選中未安装插件。
在頁面右上方選擇目標資料庫,單擊
polar_csi外掛程式操作列安装,在彈出的安装插件對話方塊,選擇目標数据库账号,單擊確定,即將外掛程式安裝到目標資料庫中。
命令列安裝
串連資料庫叢集,並在具有相應許可權的目標資料庫中執行以下語句,建立
polar_csi外掛程式。CREATE EXTENSION polar_csi;

步驟二:資料準備
以一張包含24個列的widecolumntable表為例,包含BIGINT、DECIMAL、TEXT、JSONB、TEXT[]等類型,現要對其中的id_1、domain、consumption、start_time和end_time等五個列進行統計分析,統計每個客戶在過去一年多個domain裡消費的金額。
建立一張名為
widecolumntable表,表結構定義如下,然後按照您的需求插入測試資料。CREATE TABLE widecolumntable ( id_1 BIGINT NOT NULL PRIMARY KEY, id_2 BIGINT, id_3 BIGINT, id_4 BIGINT, id_5 BIGINT, id_6 BIGINT, version INT, domain TEXT, consumption DECIMAL(18,3), c_level CHARACTER varying(1) NOT NULL, priority BIGINT, operator TEXT, notify_policy TEXT, call_id UUID NOT NULL, provider_id BIGINT NOT NULL, name_1 TEXT NOT NULL, name_2 TEXT NOT NULL, name_3 TEXT, start_time TIMESTAMP WITH TIME ZONE NOT NULL, end_time TIMESTAMP WITH TIME ZONE NOT NULL, comment JSONB NOT NULL, description TEXT[] NOT NULL, created_at TIMESTAMP WITH TIME ZONE DEFAULT now() NOT NULL, updated_at TIMESTAMP WITH TIME ZONE DEFAULT now() NOT NULL );將
id_1、domain、consumption、start_time和end_time列加入到列存索引中。CREATE INDEX idx_wide_csi ON widecolumntable USING CSI(id_1, domain, consumption, start_time, end_time);
步驟三:執行查詢
使用不同執行引擎統計過去一年客戶在不同domain中消費金額,並按消費額進行排序。
使用列存索引。
---開啟列存索引,設定查詢並行度為4 SET polar_csi.enable_query to on; SET polar_csi.exec_parallel to 4; ---Q1 EXPLAIN ANALYZE SELECT id_1, domain,SUM(consumption) FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);關閉列存索引,使用行存引擎。
---關閉列存索引,使用行存引擎,並設定查詢並行度為4 SET polar_csi.enable_query to off; SET max_parallel_workers_per_gather to 4; ---Q1 EXPLAIN ANALYZE SELECT id_1, domain,SUM(consumption) FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);