圖資料庫(Graph Database)用於儲存圖資料,適合處理社交網路、知識圖譜等複雜關係。使用圖查詢語言(如Cypher、Gremlin)進行操作。PolarDB相容OpenCypher文法,支援建立、查詢、更新和刪除圖資料,包括模式比對、過濾、MERGE避免重複、視覺化檢視等功能,簡化圖資料的管理和應用。
適用範圍
支援的PolarDB PostgreSQL版的版本如下:
PostgreSQL 16(核心小版本2.0.16.8.3.0及以上)
PostgreSQL 15(核心小版本2.0.15.12.4.0及以上)
PostgreSQL 14(核心小版本2.0.14.12.24.0及以上)
基本概念
圖(Graph):圖是由節點和邊組成的資料結構。例如,社交網路就是一個典型的圖,其中每個人都是一個節點,他們之間的關係(如朋友、家人、同事等)就是邊。

節點(Node):節點是圖資料庫中的基本元素,表示資料庫中的實體。節點可以具有屬性,用於儲存與實體相關的資訊。例如,在一個社交網路中,節點可以表示使用者、公司、組織等實體。
邊(Edge):邊是串連節點的關係。邊可以具有權重、方向等屬性,用於表示關係的強度和方向。例如,在一個社交網路中,邊可以表示使用者之間的關注、好友、粉絲等關係。
標籤(Label):標籤是一種用於標識節點或邊的分類或屬性。標籤協助您語義化資料,以便更容易地進行查詢和理解。例如,在社交網路中,節點的分類可以是人(Person),或公司(Company),邊的標籤可以是認識(Knows)或工作與(WorkIn)等。
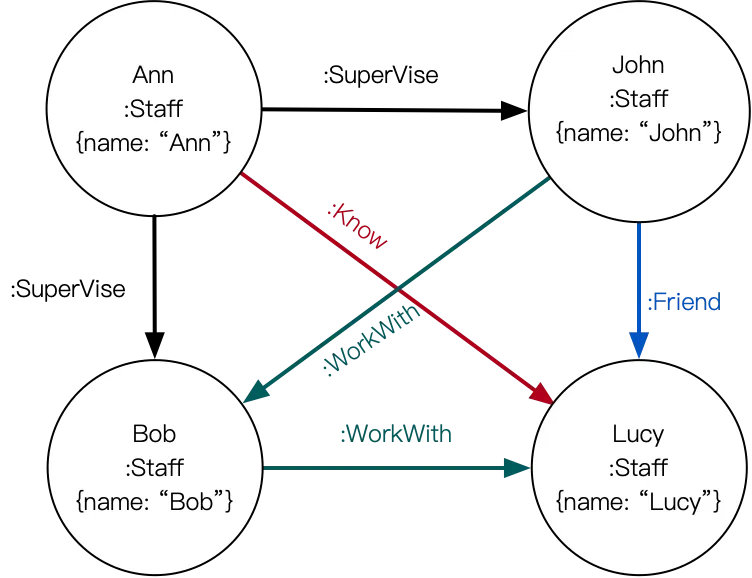
屬性圖:如果節點包含屬性(包含有關主題的詳細資料)或邊包含屬性(關係的詳細資料),則稱為屬性圖。以下為一個同事關係的屬性圖,節點和邊上都帶有相關的屬性:
圖資料庫(Graph Database):是一種特殊的資料庫,使用圖來儲存資料,節點(Node)表示實體,邊(Edge)表示關係。非常適合處理複雜的關係資料,如社交網路、信任網路、知識圖譜等。
圖資料庫使用圖查詢語言(Graph Query Language)查詢資料,如Cypher、Gremlin等。PolarDB相容OpenCypher文法。OpenCypher是Cypher的一個開源子集,其大部分特性可以認為等同於Cypher。
模式
屬性
在Cypher語言中,使用一對花括弧{}來表示屬性。屬性由索引值對(Key-Value)組成,類似於常見的JSON結構。鍵名為一個字串,屬性值可以是字串、數值,也可以是數組。例如,{name: 'Reeves'}表示名字叫Reeves。
節點
在Cypher語言中,使用一對括弧()來表示節點。以下是一些節點表示的樣本:
()
(matrix)
(:Movie)
(matrix:Movie)
(matrix:Movie {title: 'The Matrix'})
(matrix:Movie {title: 'The Matrix', released: 1997})其中:
最簡單的形式
(),表示一個匿名且未表徵的節點。若需在其他位置引用該節點,可以添加一個變數,例如:
(matrix)。變數僅適用於單個語句,在其他語句中則可能具有不同或無意義的含義。:Movie模式聲明節點的標籤。這允許我們限制模式,從而防止其匹配其他標籤的節點。{title: 'The Matrix'}聲明節點的屬性,例如,屬性可用於儲存資訊或限制模式。
邊
在Cypher語言中,使用一對短劃線--表示無向邊,使用一端帶有箭頭 <--、-->表示有向邊。方括號運算式[...]可用於添加詳細資料,包括變數、屬性和類型資訊。以下是一些邊表示的樣本:
--
-->
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ['Neo']}]->其中:
--表示一個匿名的無向邊。-->表示一個匿名的有向邊。可以定義一個變數(例如,
role),以便在語句的其他地方使用。關係的標籤(例如,
:ACTED_IN)類似於節點的標籤。屬性(例如,
roles: ['Neo'])與節點屬性定義方法一致。
操作樣本
以下通過一個簡單的樣本展示PolarDB中圖的基本使用方法。樣本資料為一個基礎的電影資料庫,涵蓋了演員及電影的相關資訊。
建立外掛程式
請使用高許可權帳號執行如下語句,建立高許可權帳號請參考建立資料庫帳號。
age外掛程式目前暫不支援您手動建立,如需使用該功能,請提交工單與我們聯絡,以便為您建立外掛程式。
CREATE EXTENSION age;設定資料庫
對於每次串連,都需要將ag_catalog添加到search_path以簡化查詢,並通過get_cypher_keywords函數實現外掛程式的載入:
使用Data Management(Data Management)用戶端設定search_path時,可能會存在相容性問題,您可使用PolarDB-Tools執行相關語句。
SET search_path = ag_catalog, "$user", public;
SELECT * FROM get_cypher_keywords() limit 0;強烈建議使用高許可權帳號設定資料庫參數,以永久載入外掛程式,從而在每次串連時無需重複執行上述操作,以簡化使用流程。
ALTER DATABASE <dbname> SET search_path = "$user", public, ag_catalog;
ALTER DATABASE <dbname> SET session_preload_libraries TO 'age';允許普通使用者使用AGE
在ag_catalog模式為普通使用者授予USAGE許可權。
GRANT USAGE ON SCHEMA ag_catalog TO <username>;如普通使用者只是RW使用者,需要額外授予建立表的CREATE許可權。
GRANT CREATE ON DATABASE <dbname> TO <username>;查詢結構
PolarDB中的Cypher查詢是通過調用ag_catalog中的一個名為cypher的函數構建的,該函數返回一個SETOF records。以下是一個典型的查詢樣本:
SELECT * FROM cypher('graph_name', $$
/* 在此處編寫 Cypher 查詢 */
$$) AS (result1 agtype, result2 agtype);其中,graph_name是圖的名稱,/* */內部分可使用實際Cypher查詢進行替代。
建立圖
在使用圖之前,首先需要進行圖的建立。建立圖使用位於ag_catalog命名空間中的create_graph函數。
文法如下:
SELECT create_graph('<graph_name>');樣本:
建立一個名為moviedb的圖。
SELECT create_graph('moviedb');插入資料
使用以下SQL語句向moviedb圖中插入樣本資料:
SELECT * FROM cypher('moviedb', $$
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
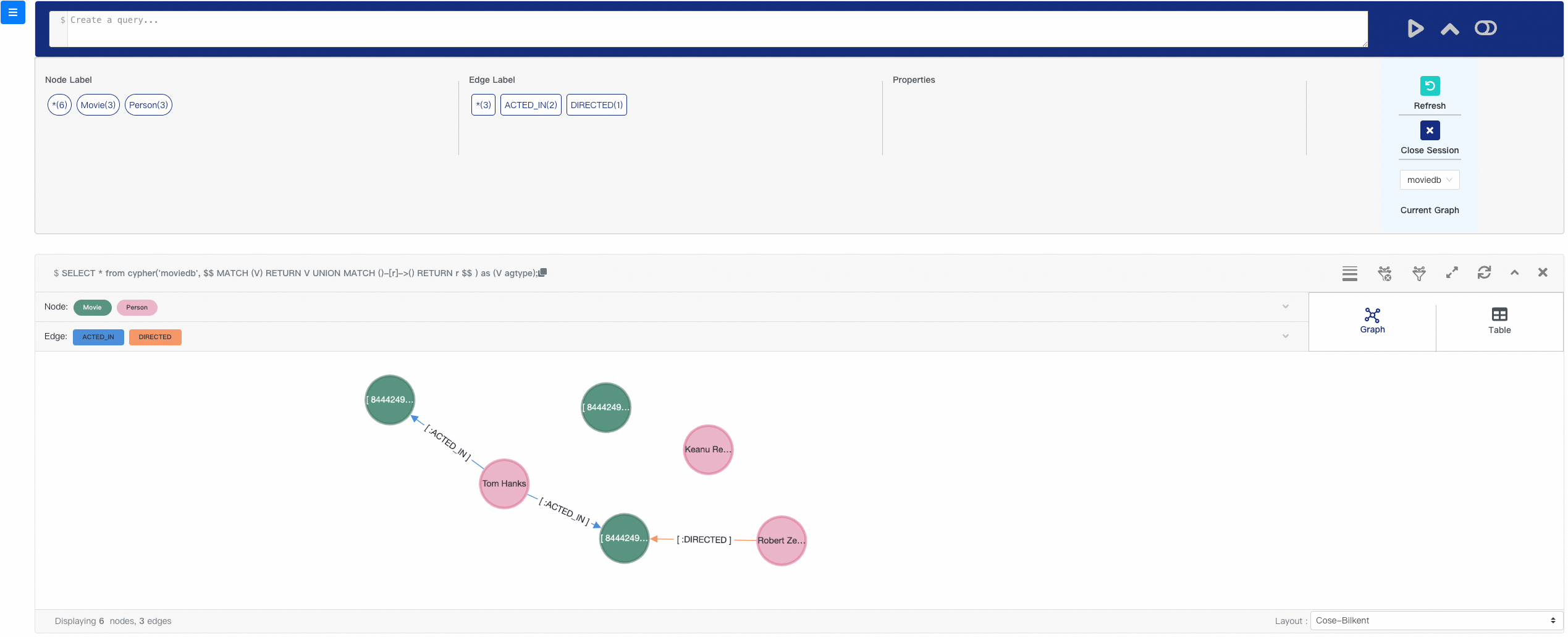
$$) AS (result1 agtype);其中,包含了6個節點,其中3個的標籤為電影(Movie),3個為人員(Person)。3條邊,其中2條邊的標籤為表演(ACTED_IN),一條邊為導演(DIRECTED)。關係圖如下所示:
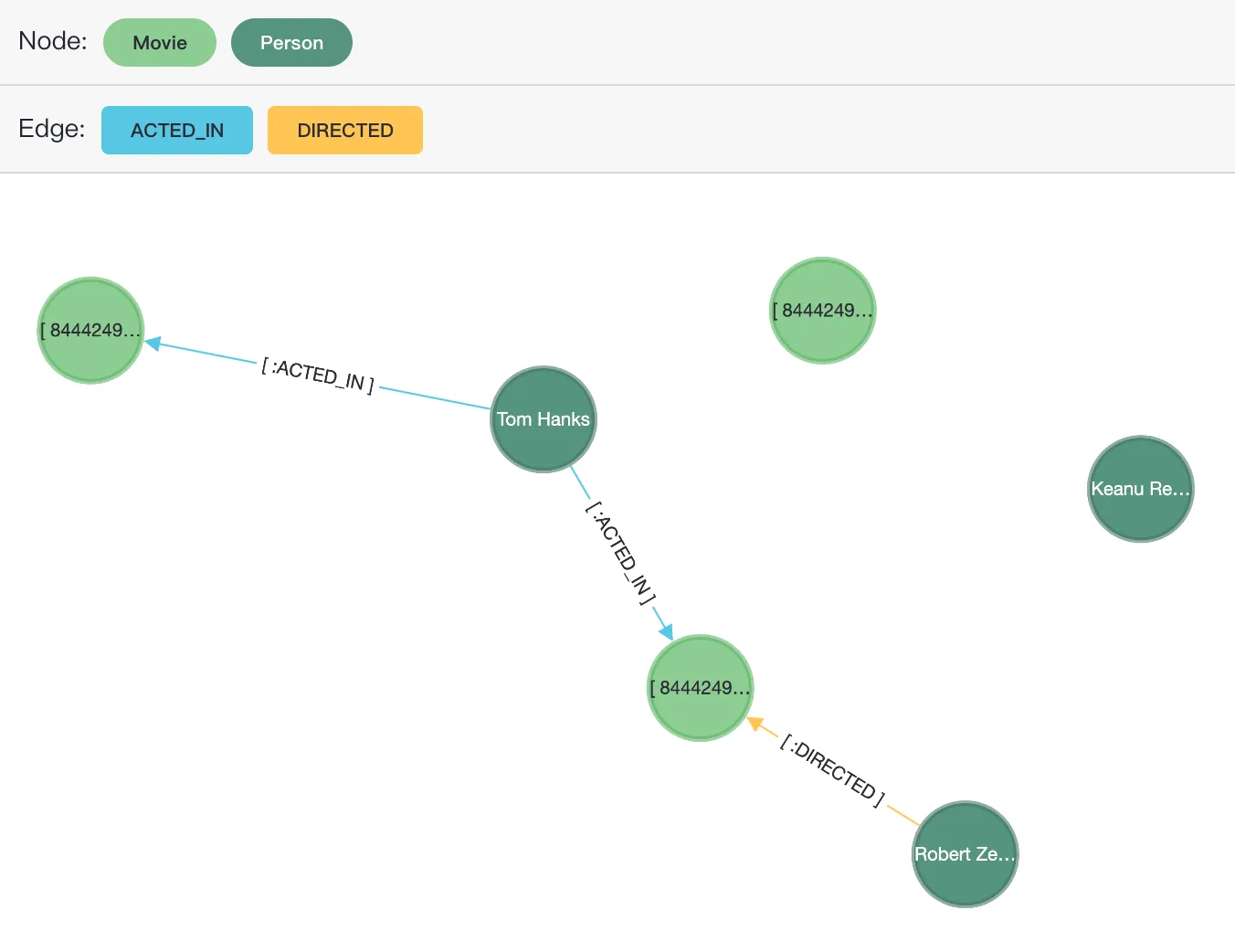
查詢資料
資料查詢
在Cypher中,使用MATCH+RETURN這兩個關鍵字實現資料的查詢。其中:
MATCH實現模式比對,用於尋找與指定模式相同的內容。RETURN關鍵字指定希望從Cypher查詢返回的值或結果。
文法如下:
SELECT * FROM cypher('graph_name', $$
MATCH <patterns>
RETURN <variables>
$$) AS (result1 agtype);樣本:
尋找包含
Movie標籤的所有節點。SELECT * FROM cypher('moviedb', $$ MATCH (m:Movie) RETURN m $$) AS (result1 agtype);尋找標籤為
ACTED_IN的串連Person和Movie的邊。SELECT * FROM cypher('moviedb', $$ MATCH (:Person)-[r:ACTED_IN]->(:Movie) RETURN r $$) AS (result1 agtype);
資料過濾
當在圖中進行模式比對並僅需返回感興趣的資料子集時,可以使用WHERE子句。該子句允許通過布林運算式對資料子集進行過濾。
樣本:
查詢標題為
The Matrix的所有電影。SELECT * FROM cypher('moviedb', $$ MATCH (m:Movie) WHERE m.title = 'The Matrix' RETURN m $$) AS (result1 agtype);查詢標題為
Forrest Gump的所有演員。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person)-[:ACTED_IN]->(m) WHERE m.title = 'Forrest Gump' RETURN p $$) AS (result1 agtype);查詢發布時間晚於2000年的電影的演員。
SELECT * FROM cypher('moviedb', $$ MATCH (p:Person)-[:ACTED_IN]->(m) WHERE m.released > 2000 RETURN p, m $$) AS (result1 agtype, result2 agtype);
建立節點或邊
在Cypher中,可以使用關鍵字CREATE建立一個全新的節點或邊。
文法如下:
SELECT * FROM cypher('<graph_name>', $$
CREATE <patterns>
$$) AS (result1 agtype);樣本:
建立一個標籤為
Person的節點,其中,屬性的名字叫Tom Tykwer,出生時間為1965。SELECT * FROM cypher('moviedb', $$ CREATE (:Person {name: 'Tom Tykwer', born: 1965}) $$) AS (result1 agtype);建立一個Person
Tom Tykwer和電影Cloud Atlas的邊,表示Tom Tykwer導演了電影Cloud Atlas。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person), (m:Movie) WHERE p.name='Tom Tykwer' AND m.title='Cloud Atlas' CREATE (p)-[:DIRECTED]->(m) $$) AS (result1 agtype);
使用MERGE避免插入重複資料
當相同的CREATE 語句執行多次時,將插入多條重複的資料。為避免此類重複資料的產生,可使用MERGE關鍵字進行插入。MERGE進行選擇或插入操作,首先會檢查資料是否已存在於資料庫中。如果資料存在,則會原樣返回該資料,或者對現有的節點或關係進行相應的更新。如果資料不存在,Cypher將根據指定的資訊進行建立。
文法如下:
SELECT * FROM cypher('<graph_name>', $$
MERGE <patterns>
$$) AS (result1 agtype);樣本:
建立一個標籤為
Person的節點,其中,屬性的名字叫Tom Cruise,出生時間為1962。SELECT * FROM cypher('moviedb', $$ MERGE (:Person {name: 'Tom Cruise', born: 1962}) $$) AS (result1 agtype);建立
Tom Hanks和Tom Cruise的邊,表示朋友關係。SELECT * FROM cypher('moviedb', $$ MATCH (t1:Person),(t2:Person) WHERE t1.name='Tom Hanks' AND t2.name='Tom Cruise' MERGE (t1)-[:FRIEND]-(t2) $$) AS (result1 agtype);
更新
對於資料中已經存在節點或關係,可以通過匹配所需尋找的模式修改其屬性,並使用SET關鍵字來添加或更新屬性以完成此操作。
文法如下:
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
SET <property>
RETURN <variable>
$$) AS (result1 agtype);樣本:
將Person
Tom Tykwer出生年份改為1970年。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person {name: 'Tom Tykwer', born: 1965}) SET p.born = 1970 RETURN p $$) AS (result1 agtype);為Person
Tom Tykwer添加一個性別屬性為male。SELECT * FROM cypher('moviedb', $$ MATCH (p:Person {name: 'Tom Tykwer', born: 1970}) SET p.gender = 'male' RETURN p $$) AS (result1 agtype);
刪除
在Cypher中,使用DELETE關鍵字來刪除節點和邊。
刪除邊
刪除邊需要使用MATCH關鍵字找到符合模式的邊,然後使用DELETE關鍵字進行刪除。
文法
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
DELETE <variable>
$$) AS (result1 agtype);樣本
刪除Person Tom Tykwer和電影Cloud Atlas的導演邊關係。
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person)-[r:DIRECTED]->(m:Movie)
WHERE p.name='Tom Tykwer' AND m.title='Cloud Atlas'
DELETE r
$$) AS (result1 agtype);刪除節點
刪除節點,同樣需要使用MATCH關鍵字找到合格節點,然後使用DELETE關鍵字進行刪除。
文法
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
DELETE <variable>
$$) AS (result1 agtype);樣本
刪除Person Tom Tykwer。
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Tykwer', born: 1970})
DELETE p
$$) AS (result1 agtype);刪除節點及邊
當節點存在相應的邊時,不允許直接刪除該節點。可以使用DETACH DELETE文法刪除該節點的邊關係,並刪除當前節點。
文法
SELECT * FROM cypher('<graph_name>', $$
MATCH <patterns>
DETACH DELETE <variable>
$$) AS (result1 agtype);樣本
刪除Person Tom Hanks以及其關聯的邊。
SELECT * FROM cypher('moviedb', $$
MATCH (p:Person {name: 'Tom Hanks', born: 1956})
DETACH DELETE p
$$) AS (result1 agtype);刪除屬性
當不再需要節點或邊的屬性時,可以使用REMOVE關鍵字刪除該屬性。
文法
SELECT * FROM cypher('<graph_name>', $$
MATCH <match_pattern>
REMOVE <property>
$$) AS (result1 agtype);樣本
刪除電影Cloud Atlas的released屬性。
SELECT * FROM cypher('moviedb', $$
MATCH (m:Movie {title: 'Cloud Atlas', released: 2012})
REMOVE m.released
RETURN m
$$) AS (result1 agtype);視覺化檢視
PolarDB PostgreSQL版通過整合開源圖引擎Apache AGE,讓您可以在同一個叢集中,可同時使用標準的SQL和業界主流的openCypher圖查詢語言。這使您能夠高效地儲存、查詢和分析圖資料,輕鬆應對複雜關係情境。詳細資料,請參見圖應用。