PolarDB PostgreSQL版支援分區表的並行查詢(Parallel Append)功能,可以更好地處理大規模資料的查詢。
概述
當代電腦往往有更多的核心可以使用,並行查詢是現代資料庫必不可少的能力。PolarDB PostgreSQL版對分區表的並行查詢,和普通表相比有更加優異的效能。
使用說明
PolarDB PostgreSQL版的並行查詢功能預設開啟。
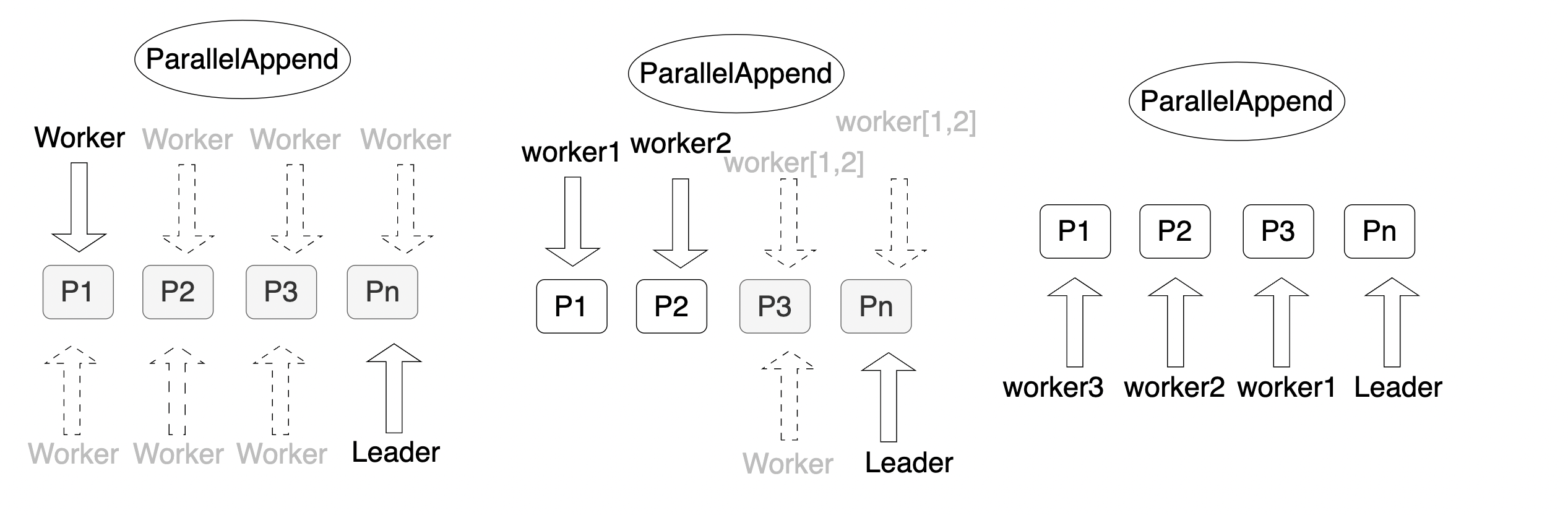
根據並行的方式,分區並行可分為分區間並行、分區內並行和混合并行。
以上三種並行方式都有自己的代價模型,最佳化器會根據實際情況選擇最優的一種。
分區間並行
分區間並行是指每個worker查詢一個分區,從而實現多個worker並行查詢整個分區表。
樣本:
EXPLAIN (COSTS OFF) select * from prt1;
QUERY PLAN
-----------------------------------------------
Gather
Workers Planned: 6
-> Parallel Append
-> Seq Scan on prt1_p5
-> Seq Scan on prt1_default
-> Seq Scan on prt1_p4
-> Seq Scan on prt1_p1
-> Seq Scan on prt1_p2
-> Seq Scan on prt1_p3
(9 rows)如上所示,prt1分區表中有6個分區:prt1_p1、prt1_p2、prt1_p3、prt1_p4、prt1_p5、prt1_default。整個分區表啟動了6個並行的Worker(Workers Planned: 6)。每個worker負責查詢一個分區。其中,明顯的標誌是有一個名為Parallel Append的運算元。
分區內並行
分區內並行是指每個分區內部並行查詢,但是整個分區表是串列的。
EXPLAIN (COSTS OFF) select * from prt1;
QUERY PLAN
-----------------------------------------------
Gather
Workers Planned: 6
-> Append
-> Parallel Seq Scan on prt1_p5
-> Parallel Seq Scan on prt1_default
-> Parallel Seq Scan on prt1_p4
-> Parallel Seq Scan on prt1_p1
-> Parallel Seq Scan on prt1_p2
-> Parallel Seq Scan on prt1_p3
(9 rows)如上所示,6個worker分別查詢分區prt1_p1、prt1_p2、prt1_p3、prt1_p4、prt1_p5、prt1_default。分區間是串列執行的,因此也能實現分區表的並行查詢。
混合并行
混合并行是指分區間和分區內都可以並存執行,以達到分區表整體的並存執行,這是並行度最高的一種並行查詢。
EXPLAIN (COSTS OFF) select * from prt1;
QUERY PLAN
-----------------------------------------------
Gather
Workers Planned: 8
-> Parallel Append
-> Parallel Seq Scan on prt1_p5
-> Parallel Seq Scan on prt1_default
-> Parallel Seq Scan on prt1_p4
-> Parallel Seq Scan on prt1_p1
-> Parallel Seq Scan on prt1_p2
-> Parallel Seq Scan on prt1_p3
(9 rows)如上所示,整個查詢使用了8個worker進行並行查詢(Workers Planned: 8),每個分區之間可以並行查詢,每個分區內部也可以並行查詢。