PolarDB MySQL版基於列存索引(IMCI)推出原生列存全文檢索索引功能,支援在現有表上直接建立全文索引,通過MATCH函數及最佳化的LIKE加速能力,實現毫秒級模糊查詢。相比Elasticsearch等外部搜尋引擎方案,IMCI實現了資料與索引的事務一致性,在避免資料同步延遲的同時,降低了整體架構的複雜度。
核心概念
理解PolarDB IMCI全文檢索索引,需掌握以下核心概念:
概念 | 描述 |
文檔(Document) | 進行索引的未經處理資料單元,在PolarDB IMCI中特指列存中的一行資料。 |
詞項(Term) | 從文檔中經過分詞器處理後提取出的基礎語言單位,是索引和查詢的最小單元。 |
分詞器(Tokenizer) | 將原始文本切分為詞項序列的組件。PolarDB IMCI提供多種分詞器(如 |
倒排索引(Inverted Index) | 全文檢索索引的核心資料結構,用於記錄每個詞項與包含它的文檔列表之間的映射關係。它由詞項字典和倒排表兩部分組成,可加速文字查詢。 |
詞項字典(Term Dictionary) | 儲存所有詞項的集合,並提供快速尋找能力。PolarDB IMCI採用FST(Finite State Transducer)演算法構建詞典,查詢時間複雜度為O(len(詞項)),空間佔用少。 |
倒排表(Posting List) | 記錄了包含某個特定詞項的所有文檔ID(在IMCI中為64位行號)的列表。PolarDB IMCI採用RBM(Roaring Bitmap)演算法對倒排表進行壓縮和計算,在稀疏和稠密資料情境下均表現良好。 |
PolarDB IMCI內建方案與“資料庫+Elasticsearch”外部方案的對比如下:
對比維度 | PolarDB IMCI 全文檢索索引 | “資料庫 + Elasticsearch” 方案 |
資料一致性 | 強一致性。索引更新與資料寫入在同一事務內完成,遵循ACID原則,無資料延遲或不一致風險。 | 最終一致性。資料需從資料庫同步至ES,存在同步延遲,無法保證資料的即時性與事務原子性。 |
架構複雜度 | 簡單。功能內建於資料庫,無需引入新組件,架構清晰。 | 複雜。需要額外部署、維護一套獨立的ES叢集及資料同步鏈路,增加了系統異構性。 |
查詢方式 | 統一。所有資料(結構化、非結構化)均通過標準SQL進行查詢。 | 割裂。需要同時使用SQL和ES的DSL進行查詢,常導致“先查ES再查DB”的兩段式查詢,增加延遲和代碼複雜度。 |
營運成本 | 低。複用PolarDB的營運和高可用體系,無需額外的專業營運技能和伺服器資源。 | 高。需要獨立的伺服器資源和專業的ES營運能力,儲存雙份資料也增加了儲存成本。 |
工作原理
PolarDB IMCI的全文檢索索引基於倒排索引技術實現,通過將非結構化的文本資料轉化為結構化的索引結構,顯著提升關鍵詞查詢效能。其核心流程如下圖所示:
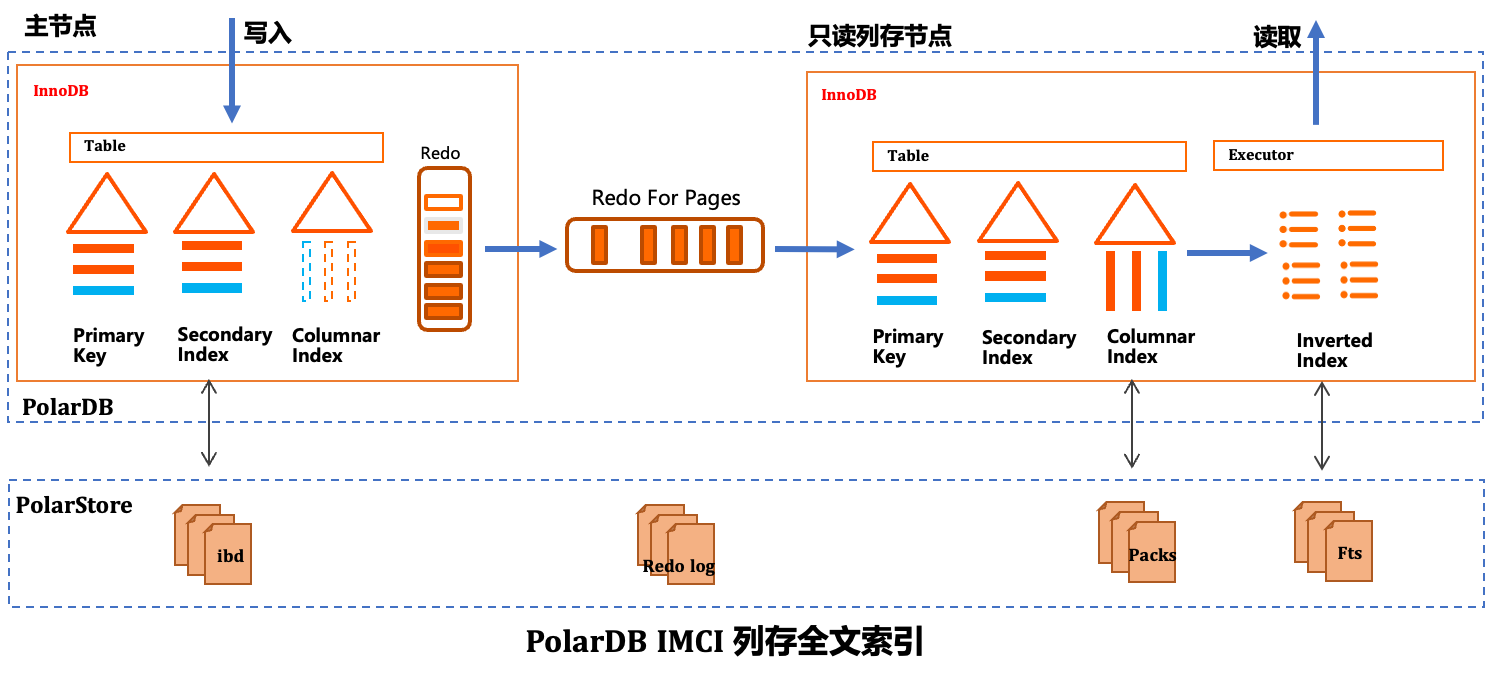
資料寫入時,InnoDB表中的內容經由列存索引同步至PolarStore的Pack檔案;在查詢階段,執行器基於列存資料構建倒排索引,並利用Fts檔案高效完成全文匹配。該架構實現了行存與列存的協同,兼顧寫入效能與複雜查詢能力。
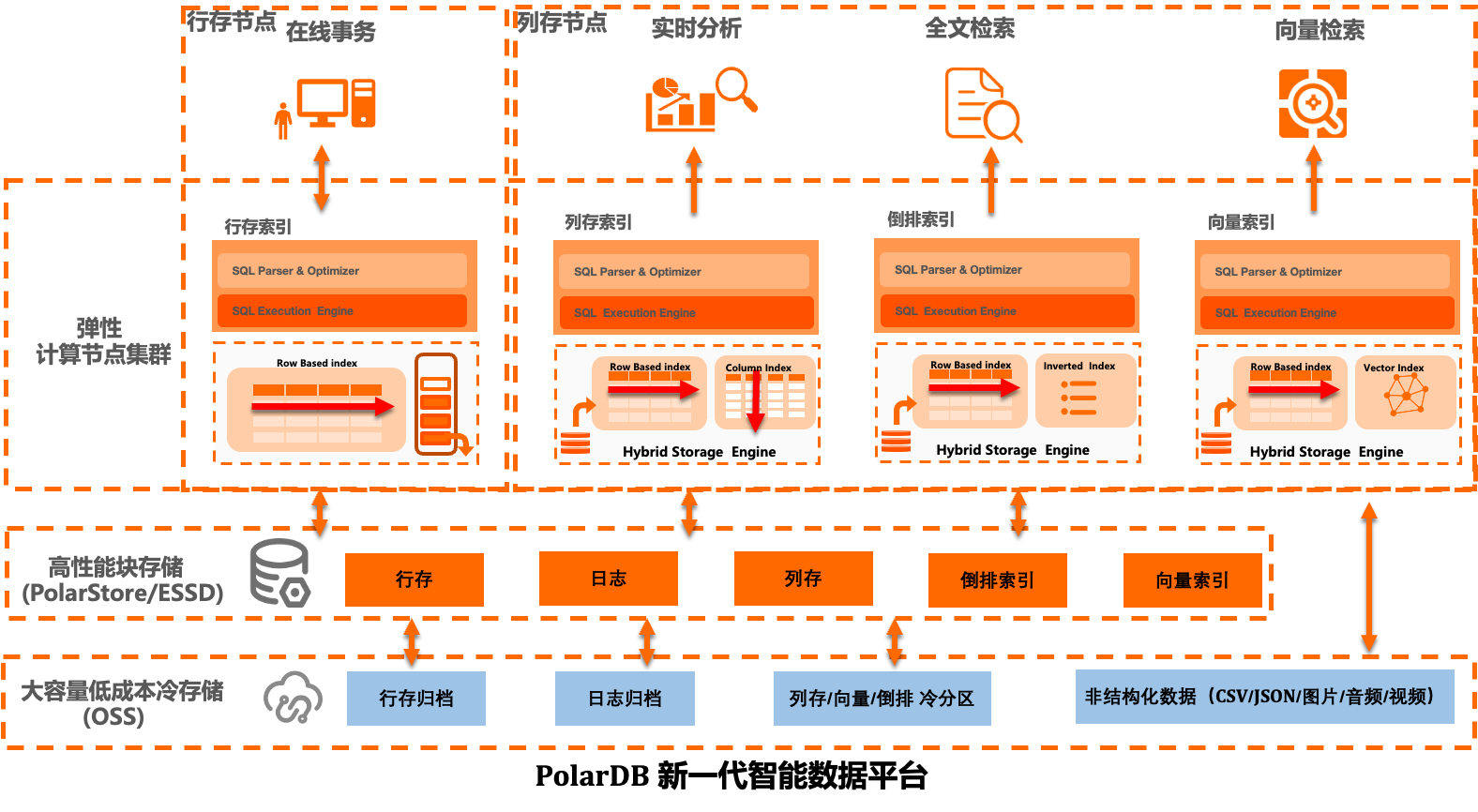
PolarDB IMCI採用統一的混合儲存架構,支援多種查詢模式。如圖所示,全文檢索索引依託Hybrid Storage Engine構建並維護倒排索引,實現高效的文本搜尋;同時結合彈性計算節點與階層式存放區,兼顧高吞吐寫入與低延遲查詢。在此基礎上,整合內建向量索引能力,進一步支援文本與向量的多模態聯合檢索。該架構廣泛適用於電商商品搜尋、日誌分析、知識庫檢索等情境,為使用者提供集OLTP、即時分析、全文檢索索引與向量搜尋於一體的一站式資料服務平台。
分詞器
分詞是將文本拆解為詞項的過程,是全文檢索索引的基礎。選擇合適的分詞器對檢索的準確性和效能至關重要。IMCI支援以下分詞器:
分詞器 | 描述 |
token | 基於空格、標點符號等非字母數字字元進行分詞,適用於英文等以空格為分隔字元的語言。 |
ngram | 將文本按預設的字元長度(n)切分成連續的詞項。 |
jieba | 基於 |
ik | 基於 |
json | 通過JSONPath運算式提取JSON對象中的特定索引值或數組元素作為詞項,用於對JSON資料進行深度檢索。 |
此外,PolarDB IMCI還提供dbms_imci.fts_tokenize分詞工具函數來測試分詞效果,其支援所有分詞器與對應屬性。不同分詞結果可能會導致全文索引的查詢結果不符合預期或MATCH與LIKE不一致等,此時可以通過該分詞工具函數來驗證分詞結果。
倒排列表
倒排表(Postings List)直觀點來說就是文檔ID集合,其關鍵技術點在於高效壓縮儲存與高效能運算(如交集)。
在PolarDB IMCI全文索引中,倒排表格儲存體的是包含某個詞項的所有列存索引的行號集合與其對應的詞頻(可選)及文檔頻率(可選),每一詞項對應一個倒排表。
IMCI使用RBM(Roaring Bitmaps)演算法對倒排表(即文檔ID集合)進行壓縮和計算。
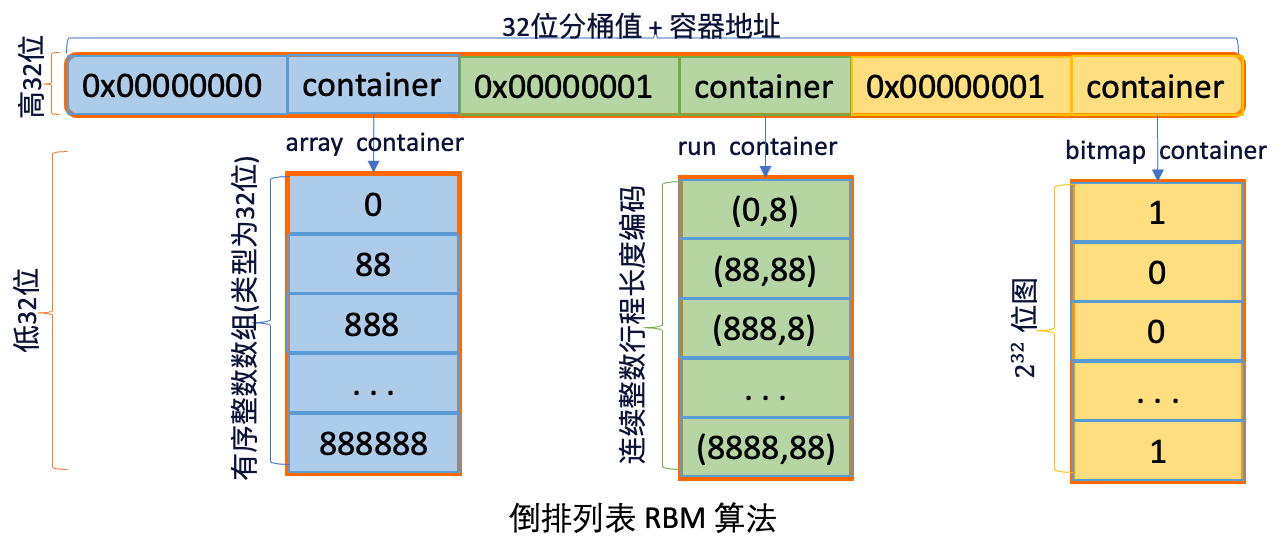
RBM實現基於CRoaring庫,並根據資料密度動態選擇儲存策略:
當倒排表中文檔ID數量小於預設閾值時,使用
std::array儲存。當數量超過閾值時,切換為
roaring::Roaring64Map類型,以應對大規模稀疏或稠密資料,並保持高壓縮率。
效能特性:
支援在構建索引時進行O(logN) 複雜度的尋找。
支援在進行交集、並集等集合運算時使用SIMD指令加速。
支援在資料落盤時進行空間整理,減少片段。
支援在查詢時利用
minimum/maximum值進行快速過濾和迭代器最佳化。
詞項字典
倒排索引的核心思想是利用詞典來快速尋找詞項所對應的倒排表,如何設計詞項到倒排表映射關係的詞典就顯得尤為重要,如字典樹、B+樹與FST等。
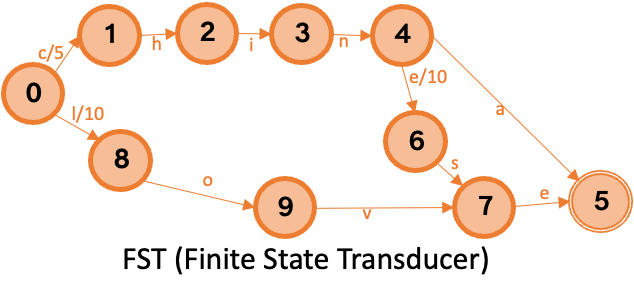
IMCI 採用 FST(Finite State Transducer)演算法構建詞項字典,以實現時間和空間效率的平衡。
空間效率:通過共用詞項的公用首碼和尾碼,有效壓縮了儲存空間。
時間效率:查詢詞項的時間複雜度為 O(L),其中 L 是詞項的長度。
例如,對於按序輸入的詞項 China、Chinese、love,假設其倒排表地址位移分別為 5、10、15,構建出詞典如下圖所示,從圖可以看出 FST 不僅可以共同首碼和尾碼以節省空間的,而且保證不同的轉移有唯一的關聯值。查詢則從初始狀態0開始依次按詞項中字元尋找是否有該字元的出邊,存在則累計關聯值,否則判斷是否為結束狀態,如 Chinese 得到關聯值為 15 且最後字元為結束狀態,即表示詞典中存在該詞項;此外 FST 的首碼計算基於位元組而不是字元,因此也是支援 utf8 等編碼。
倒排構建
PolarDB IMCI採用SPIMI演算法構建倒排索引,通過單次掃描、分詞並批量產生詞典與倒排表,支援高效、記憶體可控的局部索引構建。
PolarDB IMCI全文索引使用SPIMI構建時會不斷讀取對應列的列存資料,接著對每一行資料進行分詞得到詞項集合,然後將每一詞項和對應行號添加到散列表中,同時會累加記憶體統計值,當超過段大小閾值時則會將散列表中詞項和倒排表構建出詞典和重設記憶體繼續處理一下行,直到處理完所有列存資料。而散列表(std::unordered_map)構建詞典(FST)主要流程是首先對散列表按詞項(鍵)進行排序,接著按序將散列表中所有倒排表序列化到磁碟中並記錄其磁碟相對位移地址,然後按序將詞項和該詞項的倒排表位移地址依次添加 FST 演算法構建出詞典,最後將詞典壓縮後落盤並記錄當段資訊(包括詞典大小、詞典起始地址、倒排表起始地址、行號範圍等)到中繼資料中。
PolarDB 不追求構建全域詞典以避免外排(全域詞典還需要按首碼切分並構建出詞項索引),而是考慮到列存儲存追加寫模型則採用輕量級構建方式,根據記憶體閾值構建出多個局部詞典,如下圖所示。當然在記憶體充足情況下盡量可能放大記憶體閾值,這樣會讓同一詞項儘可能多落到同一倒排段中,有助於節省空間的和提高查詢效能。

除上述正常構建倒排外,PolarDB IMCI全文索引還支援後台空閑時非同步合并倒排索引。 PolarDB IMCI列存索引作為普通表的二級索引,insert時資料總是以插入序按列追加到列存儲存引擎中,delete時採用標記刪除方式,update則轉換為delete + insert,其使用 array InsertMask標記列存資料中每一行的插入版本作為可見度判斷,lsm DeleteMask 則對已存在的某行進行標記刪除,同時非同步Compaction與Recycle等後台操作進行資料重整和空間回收等。PolarDB IMCI全文索引作為列存引擎的一部分,同樣也會通過後台非同步倒排Compaction任務來不定時清理被標記為刪除的資料,有效節省空間的和提高查詢效能。倒排合并是按倒排段為單元,將多個倒排段合并為新倒排段,同時不會修改原倒排段,避免用於查詢的倒排快照對象失效,合并完成時會重建新倒排快照,新查詢時則使用新快照。 PolarDB IMCI全文索引得益於局部構建方式與標記刪除設計方案,大批量插入並不會觸發全域重建,僅需構建增量部分,同時更新成本也非常低,僅需要標記刪除,即使在頻繁更新情境下也不會影響寫入效能。此外,後台不定時非同步合并能夠有效合并出更緊湊的倒排索引以提高查詢效能,結合列存的並發查詢能力,即使在海量資料情境下也能夠滿足毫秒級響應要求。
倒排檢索
PolarDB IMCI 全文索引支援mysql官方MATCH函數和LIKE操作等。
MATCH函數PolarDB IMCI支援統一使用
MATCH函數進行全文檢索索引,無論行存是否建立全文索引:若行存未建索引,查詢將直接路由至列存節點;若已存在,則根據代價評估進行智能分流。為避免MySQL原生全文索引在最佳化階段觸發的輔助表同步、緩衝載入等耗時操作影響列存效能,PolarDB在查詢分流初期即跳過此類處理。執行階段,IMCI提供兩種檢索方式:
FtsTableScan運算元和MATCH運算式。前者通過倒排索引直接擷取命中行,適用於高篩選率情境;後者則基於行號回查索引,適合前置條件已大幅過濾資料的情形。兩者的執行效率取決於其他謂詞的過濾效果,因此列存最佳化器結合統計資訊估算過濾率,動態選擇最優策略。當選用運算元方式時,系統自動將MATCH函數重寫為FtsTableScan + Filter運算元。全文索引採用非同步構建機制,可能短暫延遲新增資料的可見度。預設情況下,列存執行器通過全表掃描補全未索引資料,確保查詢結果完整;同時提供參數控制是否跳過該步驟,以在高並發、巨量資料量情境下實現效能與一致性的靈活權衡。使用者亦可調整索引構建參數,加快資料同步頻率,減少全掃描範圍,進一步提升查詢效率。
LIKE加速PolarDB IMCI 在特定條件下支援
LIKE與MATCH的相互轉換,其中將LIKE轉換為MATCH主要用於查詢加速,以減少全表掃描中大量字串逐行比較的開銷。當前,該轉換僅在列存全文索引使用
ngram分詞器,且ngram分詞長度小於或等於LIKE模式字串長度時生效。在此條件下,最佳化器可將形如LIKE '%abc%'的謂詞重寫為FtsTableScan + Filter運算元,利用倒排索引快速篩選候選行。然而,由於
ngram分詞的匹配機制與LIKE的語義存在差異(例如"abbc"分詞為ab、bb、bc,與"abc"的ab和bc重疊,可能被誤判為匹配)。因此,原始LIKE運算式仍作為後續過濾條件保留,用於精確驗證,確保結果正確性。該機制在顯著提升查詢效能的同時,有效兼顧了語義準確性與執行效率。
PolarDB IMCI的倒排索引由多個倒排段組成,每個倒排段包含獨立的中繼資料、一個詞典和一系列倒排表,其中每個詞項唯一對應一個倒排表。中繼資料記錄詞典和倒排表的起始地址等資訊,體積較小,預設常駐記憶體,以加速索引訪問。
倒排檢索以倒排段為單位進行,主要流程包括:讀取詞典資料、構建FST(有限狀態轉換器)詞典對象、在詞典中尋找目標詞項、讀取對應的倒排表並構建RBM(Roaring Bitmap)倒排表對象。
具體查詢分為兩種模式:
運算元查詢:遍曆所有倒排段的中繼資料,擷取詞典起始地址並載入詞典資料,構建詞典對象後尋找目標詞項;若命中,則結合詞項的倒排表位移地址與段內起始地址,讀取完整的倒排表對象。
運算式查詢:根據行號確定所屬的倒排段集合,並利用中繼資料中的行號範圍進一步過濾,隨後對匹配的倒排段執行與運算元查詢類似的詞典尋找和倒排表讀取流程。
為提升效能,IMCI支援詞典緩衝功能,採用獨立的LRU緩衝機制,並由調度模組動態調整記憶體配額。由於單個倒排表通常較小(多數僅需一次 4KB IO),且數量龐大,快取命中率和收益有限,因此倒排表緩衝預設不啟用,以避免記憶體資源浪費。
該設計在保證查詢效率的同時,合理權衡了記憶體使用量與 I/O 開銷。
應用情境
PolarDB IMCI全文檢索索引功能適用於多種需要對常值內容進行快速搜尋的業務情境。
電商商品搜尋與站內查詢
在電商平台中,使用者常通過關鍵詞快速尋找商品。傳統基於
LIKE的模糊比對效能差,難以滿足高並發下的響應要求;而依賴外部Elasticsearch的方案雖能提速,卻常因資料同步延遲導致搜尋結果包含已下架、已調價或庫存為零的商品,影響使用者體驗。PolarDB IMCI提供原生全文檢索索引能力,可對商品標題、描述、屬性等文字欄位建立高效倒排索引。查詢時直接在資料庫內完成關鍵詞匹配,避免跨系統延遲,確保搜尋結果與商品即時狀態(如價格、庫存)強一致,真正實現“搜得到、買得到”。
日誌分析與可觀測性
營運和排障過程中,開發與營運人員需要從海量日誌中快速定位錯誤堆棧、追蹤請求鏈路或分析異常行為。傳統ELK架構雖功能強大,但組件繁多、部署複雜、維護成本高,且資料寫入到可查之間存在明顯延遲。
藉助 PolarDB IMCI,可直接在日誌表的
message或content欄位上建立全文索引,利用標準SQL實現毫秒級日誌檢索。無需額外搭建日誌分析平台,即可完成互動式查詢與上下文追溯,顯著簡化技術棧,降低儲存與營運負擔,讓問題定位更高效。文檔與知識庫檢索
企業內部的知識庫、產品手冊、FAQ或協助中心,核心訴求是讓使用者快速找到所需資訊。若依賴外部搜尋引擎,不僅需要維護雙寫邏輯,還容易出現內容更新不同步的問題。
通過PolarDB IMCI對文檔本文建立全文索引,並結合
jieba或ik等中文分詞器提升切詞準確性,可在同一資料庫內實現內容儲存與檢索一體化。內容更新後立即可搜,許可權模型複用現有系統,無需額外同步機制,真正實現“發布即可見、修改即生效”。使用者畫像與行為分析
精準的使用者營運依賴對非結構化文本的深度挖掘,例如從使用者評論、標籤、動態中提取興趣偏好。傳統做法需將資料匯出至數倉或分析系統,流程複雜且時效性差。
PolarDB IMCI支援對JSON欄位使用
json分詞器,或對長文字欄位使用jieba分詞器建立索引,使得在單條SQL中即可融合結構化屬性(如年齡、地區)與文本語義(如“喜歡戶外運動”“關注性價比”)進行聯合分析。無需資料移轉,即時完成使用者圈選與行為洞察,助力精細化營運與個人化推薦。
效能測試
ESRally是Elastic官方推出的Elasticsearch基準測試載入器。本文將使用其內建的http_logs資料集,對PolarDB IMCI列存全文索引的檢索效能進行測試評估。您也可參考解決方案PolarDB 列存索引加速複雜查詢進行操作示範,進一步瞭解其在實際情境中的效能表現。
資料集準備
擷取資料集:
資料集詳情請參見Elasticsearch Rally Hub,擷取資料集方法如下所示,擷取到大約 1.7G 壓縮包rally-track-data-http_logs.tar,解壓後約32G,總行數為2.47億。
git clone https://github.com/elastic/rally-tracks.git cd rally-tracks ./download.sh http_logs建立表:
由於資料集存在少數行的json資料和mysql json類型不相容,因此使用varchar(512)來儲存json資料,導完資料後再通過虛擬列來解析出json的request欄位。
CREATE TABLE http_logs( logs varchar(4096) );匯入資料:
使用LOAD DATA匯入資料集到資料庫。
LOAD DATA INFILE '/home/xxx/http_logs/documents-181998.json' INTO TABLE http_logs COLUMNS TERMINATED BY '\n'; ... ...添加欄位:
通過虛擬列來解析出json的request欄位用於全文索引測試。
ALTER TABLE http_logs ADD COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END);建立列存索引:
列存倒排索引屬於列存索引一部分,需要先建立列存索引。
ALTER TABLE http_logs comment 'columnar=1';建立倒排索引:
通過ddl來修改列comment方式來列存倒排索引,ddl會秒級完成,而倒排索引會在後台非同步構建。
ALTER TABLE http_logs modify COLUMN request varchar(1024) AS (CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END) comment 'imci_fts(type=2 mode=1)';查看倒排索引:
建立後可以通過下面命令列分別查看NUM_PACKS和NEXT_PACK_ID,其中 NUM_PACKS表示列存資料區塊數目,NEXT_PACK_ID表示倒排索引已構建到資料區塊編號,兩者接近則表示倒排索引已經構建完成。
SHOW imci indexes; SHOW imci indexes fulltext;
效能測試
倒排索引構建完成後,即可通過MATCH函數測試從高頻到低頻詞元的檢索效能表現。下圖展示了 LIKE、MATCH 與 Doris MATCH_ANY 在相同資料集下的查詢效能對比。
在熱資料情況下單線程測試結果如下:
查詢 | 高頻詞元 | 較高頻詞元 | 較低頻詞元 | 低頻詞元 |
LIKE | 1 min 21.96 sec | 1 min 18.44 sec | 1 min 24.59 sec | 1 min 31.19 sec |
SMID LIKE | 25.46 sec | 22.80 sec | 21.98 sec | 21.60 sec |
MATCH (自研 FTS庫) | 2.43 sec | 0.25 sec | 0.01 sec | 0.00 sec |
Doris MATCH_ANY (CLucene庫) | 3.49 sec | 0.24 sec | 0.03 sec | 0.03 sec |
如上表所見,MATCH 比 LIKE 有資料量提升,且基本不受冷熱資料影響。
常見問題
Q1:PolarDB IMCI全文檢索索引相比傳統資料庫(如MySQL InnoDB)內建的全文索引,有哪些優勢?
PolarDB IMCI在效能、功能和擴充性上均有優勢:
效能:基於列存和向量化執行引擎,結合FST、RBM等演算法,查詢效能優於傳統行存索引,在高並發、海量資料情境下可實現快速響應。
功能:內建
jieba、ik等中文分詞器和json分詞器,滿足複雜業務情境的需求。寫入效能影響:最佳化的索引構建和更新機制,對高頻寫入(INSERT/UPDATE)情境的效能影響遠小於傳統資料庫的全文索引。
水平擴充能力:受益於PolarDB存算分離架構,具備良好的水平擴充能力。
Q2:如何為業務資料選擇合適的分詞器?
根據資料類型和查詢需求來選擇:
處理中文文本:使用
jieba或ik分詞器,它們能進行語義分詞,提升中文檢索的準確率。處理英文或符號分割的文本:使用
token分詞器,它通過空格和標點符號進行分詞。實現模糊比對或任意子串搜尋:使用
ngram分詞器,它將文本切分為固定長度的短語(如二元、三元),適合替代低效的LIKE '%keyword%'查詢。檢索JSON欄位內的特定內容:使用
json分詞器,目前支援對JSON數組的值或JSON對象的鍵建立倒排索引。
如果不確定哪種分詞器最適合,可使用dbms_imci.fts_tokenize函數預覽不同分詞器對樣本文本的處理效果,以選擇最符合業務預期的分詞策略。