混合最佳化器的行列自動分流機制能夠對每個查詢進行深入分析,評估其在行存節點與列存節點上的執行成本,並基於評估結果選擇最優執行方案,從而有效降低查詢執行成本。這一機制確保了每個查詢能夠被合理地分配至最合適的處理節點。
問題描述
預設版本的行列自動分流機制採用基於預估執行代價的分流策略:當SQL語句的預估執行代價超過預設閾值時,資料庫代理(Proxy)將自動將該請求分流至唯讀列存節點處理;反之,若預估代價未達到閾值,則該請求由行存唯讀節點或主節點來處理。其主要缺陷在於並未真正比較SQL在行存和列存環境下的實際執行代價,而是簡單地以一個固定的閾值作為分流依據,這導致實際環境中經常出現分流不準確的現象。
版本限制
PolarDB叢集的核心版本需滿足以下條件之一:
PolarDB MySQL版8.0.1版本且修訂版本為8.0.1.1.43及以上。
PolarDB MySQL版8.0.2版本且修訂版本為8.0.2.2.26及以上。
您可以在叢集詳情頁查看叢集的核心版本。
注意事項
叢集地址已開啟行存/列存自動分流。
技術原理
在PolarDB MySQL中,存在三種類型的節點:
行存節點:使用InnoDB引擎,負責執行行存查詢任務。
列存節點:使用IMCI引擎,負責處理列存查詢任務。
Proxy節點:負責將用戶端請求轉寄至行存或列存節點。
一個查詢請求從用戶端提交至叢集時,其處理流程如下:
Proxy節點接收查詢請求後,首先將其轉寄至行存節點進行處理。
行存節點內的混合最佳化器對查詢進行分析,分別評估其在行存和列存環境下的執行成本,從而確定最優執行路徑。
如果判定該查詢更適合在行存環境下執行,將直接在本地行存節點上完成處理。
若判斷結果顯示列存環境更優,則行存節點將查詢請求轉寄至列存節點進行處理。
在這一流程中,混合最佳化器的行列路由決策是關鍵。為了實現精準的查詢分配,混合最佳化器為每個查詢分別計算其在兩種儲存模式下的執行代價。其中:
行存代價模型基於MySQL執行計畫,估算行存方案的執行代價。
列存代價模型根據IMCI執行計畫,估算列存方案的執行代價。
這兩種代價模型採用統一且具有物理意義的度量標準,代表預估的執行時間。通過比較行存和列存的代價估計值,混合最佳化器能夠智能地選擇最優執行方案,從而確保查詢效能的最佳化。
配額流程
混合最佳化器功能目前處於灰階發布階段。請前往配額中心,根據配額ID
polardb_mysql_hybrid_optimizer找到配額名稱"PolarDB MySQL混合最佳化器配額"在對應的操作列單擊申請來開通該功能。失效流程與生效流程步驟相似,配額申請值選擇“失效”待後續人工審批通過後即可關閉混合最佳化器功能。
點擊配額中心。輸入配額ID,進行相關搜尋,點擊申請按鈕。

配額申請對話方塊選擇生效,並填寫生效時間,失效時間、申請理由和是否通知調整結果。
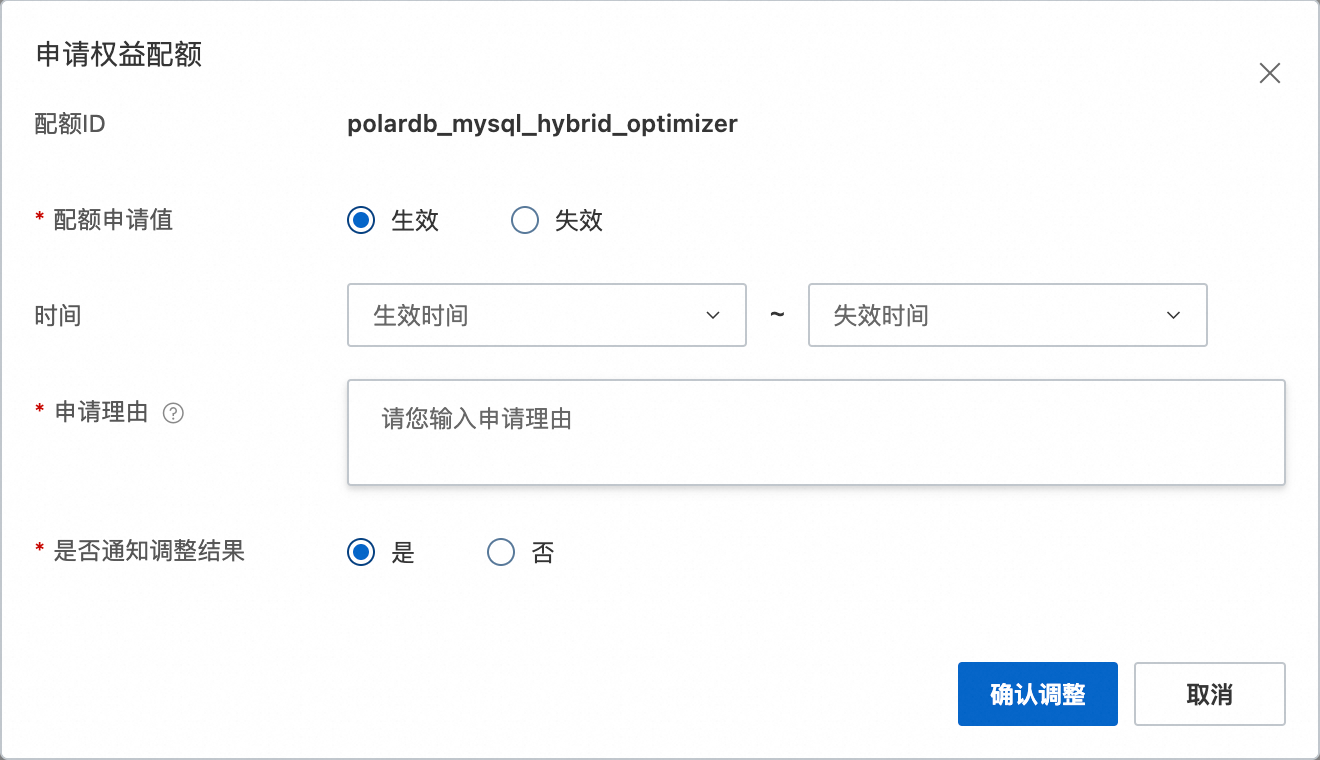
選擇確認調整。等待後續人工審批通過後即可開啟使用混合最佳化器功能。