隨著業務資料量的激增,海量資料的儲存成本與分析效率成為許多企業面臨的核心挑戰。為應對這一情境,PolarDB MySQL版提供了X-Engine列存表功能。該功能基於列式儲存、高效壓縮和並行計算技術,可將您的資料存放區成本降低至未經處理資料的10%,同時將分析查詢效能提升一個數量級,協助您在完全相容MySQL生態的同時,實現海量資料的低成本歸檔與高效能即時分析。
功能簡介
X-Engine列存表採用計算儲存分離架構,計算資源和儲存資源可以獨立彈性擴充,為您提供PB級的海量資料處理能力。其儲存層基於Distributed File System和Object Storage Service實現,計算層則通過對查詢最佳化工具、執行運算元和儲存引擎的深度最佳化,實現高效能分析。
技術架構
PolarDB整體架構
PolarDB採用存算分離的架構,其底層為分布式儲存層。通過ParallelRaft協議,系統確保多副本的一致性,並且透明地支援OSSObject Storage Service。計算節點由一個讀寫節點(RW)和一個或多個唯讀節點(RO)組成,同時支援InnoDB和X-Engine兩種引擎。資料庫代理充當應用程式與計算節點之間的橋樑,提供讀寫分離及負載平衡的功能。
列存表架構
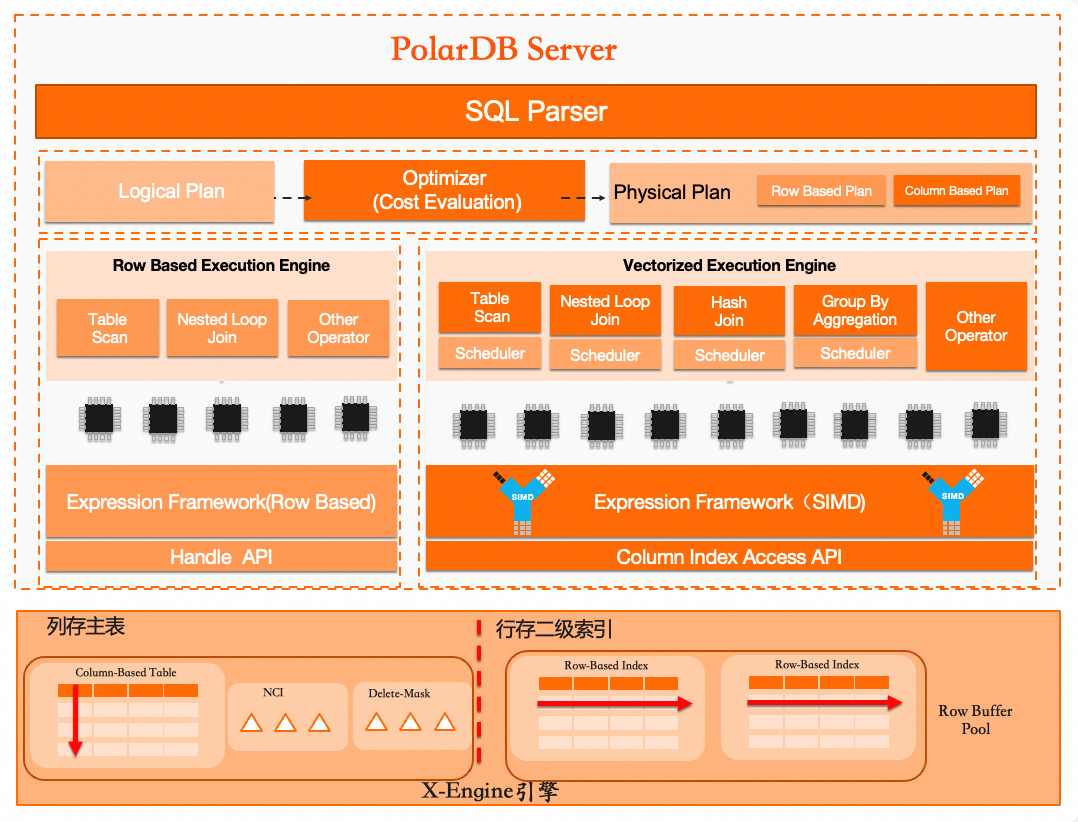
其核心技術組件包括:
查詢最佳化工具:內建面向行列混合儲存的代價最佳化器(CBO),能夠根據查詢請求的代價,智能判斷並自動選擇最優的執行計畫(選擇行存或列存)。
執行運算元:採用面向列存的向量化和並存執行技術,通過批處理模式大幅度提升單表和多表關聯的分析查詢速度。
儲存引擎:支援即時的事務更新。主表採用列式儲存,並通過NCI(Non-Clustered Index)組件保障快速更新能力。通過Delete-mask機制標記刪除資料,在不影響即時寫入的同時提供高效的並行查詢。同時,其行存二級索引可以快速過濾無效資料,進一步提升查詢效率。
方案對比
為協助您理解並選擇合適的表類型,下表對比了傳統行存表(如InnoDB)與PolarDB列存表的核心差異:
對比維度 | 行存表(X-Engine引擎) | 列存表 |
資料群組織方式 | 以行為單位連續儲存,一行資料的所有列儲存在一起。 | 以列為單位連續儲存,一列資料的所有值儲存在一起。 |
資料壓縮率 | 中。相較於InnoDB最高可將資料壓縮至原始大小的3/10。 | 高。通過列式儲存和專用編碼(如字典編碼),相較於InnoDB可將資料壓縮至原始大小的1/10。 |
查詢效能 | 點查效能高。適用於根據主鍵或索引快速讀取單行或少數行資料的情境(OLTP)。 | 分析效能強。僅需讀取查詢涉及的列,有效減少I/O。同時配合向量化並行計算,彙總分析效能比行存表提升一個數量級。 |
更新與刪除效能 | 高。直接定位到行進行修改。 | 相對較低。具備即時更新能力,藉助於NCI組件,可以快速定位到需要修改的記錄。 |
適用情境 | 聯機交易處理(OLTP),如高並發的增、刪、改、查操作。 | 線上分析處理(OLAP),如資料歸檔、報表產生、即席查詢、海量資料彙總分析。 |
功能優勢
高成本效益:通過列式儲存、高效編碼和高壓縮比演算法,並結合OSS的低成本儲存介質,可將海量資料存放區處理成本降低90%。
高效能即時分析:資料寫入後可立即用於分析查詢。利用多核並行、向量化及MPP技術,查詢效能媲美專用AnalyticDB,可滿足嚴苛的即時分析需求。
100%相容MySQL:提供與MySQL一致的資料類型系統和協議,支援靈活的類型轉換,您現有的應用和工具無需改造即可接入。
獨立的Auto Scaling:計算與儲存分離的架構允許計算節點和儲存空間獨立按需擴充,從容應對業務峰值和資料增長。
強大的寬表支援:單表最多可支援10000列,滿足大寬表格儲存體和高並發寫入的業務需求。
出色的易用性:在單一資料庫引擎內同時支援高壓縮比儲存和高效能分析,並提供完整的DDL和DML操作支援,簡化了您的技術棧和營運管理。
應用情境
海量歷史資料低成本歸檔
業務痛點:隨著業務增長,核心資料庫中的歷史訂單、日誌、流水等資料急劇膨脹,佔據了大量昂貴的儲存空間。傳統的資料移轉方案雖然能降低成本,但會導致資料離線,無法直接線上查詢,增加了資料使用的複雜度。
解決方案:推薦使用列存表進行線上資料歸檔。您可以將行存表(InnoDB)中的冷資料或整個歷史資料表遷移至同一PolarDB叢集內的列存表中。
核心價值:
成本驟降:得益於高達10:1的壓縮率和對低成本儲存介質(如OSS)的利用,儲存成本可降低90%。
資料線上:歸檔資料始終保持線上可用,您可以隨時通過標準SQL對其進行查詢和分析,無需複雜的資料回遷過程。
業務無感:對於應用程式層而言,只是操作一張普通的MySQL表,無需改造。
構建專用資料倉儲
業務痛點:企業在搭建專用資料倉儲時,常面臨高昂的硬體成本、複雜的資料同步鏈路(ETL)以及較高的營運門檻,尤其是在引入新的技術棧(如ClickHouse)時。
解決方案:依託於PolarStore的海量資料存放區能力,可將來自多個上遊資料來源的資料匯聚於此,並統一使用X-Engine列存表進行儲存,您可以在享受海量、低成本儲存能力的同時,獲得即時的彙總分析效能。
核心價值:
成本與複雜度顯著降低:無需採購昂貴的專用硬體或引入異構分析系統,在熟悉的MySQL生態內即可構建資料倉儲,有效簡化了技術棧和營運管理。
即時資料分析:支援將上遊資料即時匯聚至列存表中進行分析,避免了傳統ETL方案帶來的T+1資料延遲。
海量資料處理能力:依託於X-Engine的儲存架構和高效壓縮,能夠以低成本儲存和處理PB級海量資料。
聯邦查詢分析
業務痛點:企業的業務資料通常分散儲存,一部分在PolarDB等線上資料庫中,另一部分以Parquet、ORC等開放格式儲存在Object Storage Service上。要對這兩部分資料進行聯合分析,通常需要複雜的ETL過程將OSS資料匯入資料庫。
解決方案:利用PolarDB的外表功能,直接關聯OSS上的資料。
核心價值:
原地分析:無需移動或匯入資料,直接在PolarDB中為OSS上的檔案建立外表,即可用SQL進行查詢。
聯邦查詢:可以輕鬆地將PolarDB內的本地表(行存或列存)與OSS外表進行
JOIN操作,實現對線上資料和離線資料的統一分析。
效能測試報告
以下效能資料均在特定測試環境下得出,為評估列存表的收益提供參考。
本文的TPC-H的實現基於TPC-H的基準測試,並不能與發行的TPC-H基準測試結果相比較,本文中的測試並不完全符合TPC-H的所有要求。
資料裝載效能
以下資料基於32核256 GB規格的測試環境,使用TPC-H和Airline資料集,對比了列存表與ClickHouse、Doris在資料裝載和儲存方面的表現。
裝載速度
TPC-H資料集:列存表裝載速度達571萬行/秒,寫入吞吐50 GB/min,約為ClickHouse的2.7倍。
Airline資料集:列存表裝載速度達430萬行/秒,寫入吞吐27 GB/min,約為ClickHouse的2倍。
資料集 | ClickHouse(萬行/秒) | Doris(萬行/秒) | 列存表(萬行/秒) |
TPC-H | 210 | 454 | 571 |
Airline | 140 | 215 | 430 |
儲存空間
TPC-H資料集:未經處理資料100 GB,列存表壓縮比達4倍。
Airline資料集:未經處理資料75 GB,列存表壓縮比達18倍。
以下為Airline資料集(未經處理資料75 GB)的儲存空間對比:
類型/產品 | ClickHouse | Doris | 列存表 |
儲存空間(GB) | 9.29 | 4.49 | 3.97 |
壓縮比 | 約8倍 | 約16倍 | 約18倍 |
TPC-H查詢效能
TPC-H 100 GB資料集效能測試,列存表22條查詢的總耗時為17.994秒,ClickHouse為76.9秒,列存表整體效能約為ClickHouse的4.3倍。
查詢
列存表(秒)
ClickHouse(秒)
Q1
1.175
2.2
Q2
0.178
0.9
Q3
0.577
1.6
Q4
0.433
1.3
Q5
0.522
3.3
Q6
0.366
0.32
Q7
0.633
1.7
Q8
0.528
1.8
Q9
2.817
12
Q10
0.935
2.3
Q11
0.218
0.66
Q12
0.535
1.4
Q13
1.255
4.4
Q14
0.442
0.3
Q15
0.889
0.42
Q16
0.553
0.6
Q17
0.738
4.2
Q18
2.381
4.3
Q19
0.759
2
Q20
0.453
0.6
Q21
1.308
29.6
Q22
0.299
1
合計
17.994
76.9
多節點並行分析:在TPC-H 1 TB資料集的效能測試中,列存表通過多節點並行加速,查詢總耗時從單節點的1420.551秒降至6節點的167.948秒。
查詢
1台(秒)
2台(秒)
4台(秒)
6台(秒)
Q1
76.849
36.831
23.031
20.022
Q2
5.841
2.805
1.527
1.09
Q3
133.69
26.131
15.833
4.75
Q4
51.466
19.02
3.353
2.362
Q5
52.965
26.844
13.715
4.269
Q6
34.577
21.831
35.17
11.274
Q7
75.996
29.659
17.279
5.717
Q8
54.989
28.922
15.651
3.375
Q9
155.33
78.216
40.38
25.983
Q10
72.222
31.659
17.177
4.594
Q11
4.149
2.049
1.351
1.069
Q12
50.997
27.79
16.207
2.977
Q13
73.009
31.742
17.605
16.255
Q14
36.887
22.093
4.475
3.778
Q15
66.217
38.628
7.583
6.451
Q16
11.493
4.49
2.528
1.758
Q17
59.225
37.101
11.434
8.767
Q18
132.604
53.578
17.164
10.797
Q19
72.794
38.416
23.759
16.651
Q20
42.621
22.432
5.62
4.768
Q21
149.245
54.803
12.758
8.793
Q22
7.385
5.684
2.972
2.448
合計
1420.551
640.724
306.572
167.948