該基準測試展示了PolarDB向量索引在OpenSearch協議與特定軟硬體設定下,處理億級千維向量的寫入與查詢效能。本文包括測試環境、資料集、關鍵配置參數、複現步驟及效能結果分析,為技術選型、容量規劃和效能調優提供資料參考。
適用範圍
效能資料基於特定的叢集環境和資料集。在應用這些資料進行決策前,需確認環境與以下條件相似。
叢集規格與版本
主節點:2核 8GB。
唯讀節點:2核 8GB。
搜尋節點:32核 256GB * 3。
用戶端延遲:0.097ms。
PolarDB向量索引版本:2.19.3。
資料集
分類 | 子項 | 詳情 |
軟體版本 | PolarDB-Vector | 2.19.3 |
資料集 | MSMARCO V2.1 | |
資料規模 | 文檔總數 | 113,520,750 |
向量維度 | 1024 | |
查詢集大小 | 1677 | |
演算法參數 | 距離度量 | L2(歐氏距離) |
索引類型 | HNSW |
測試步驟
以下步驟描述了如何複現索引建立、資料寫入和效能壓測。
若您有相關需求,請提交工單與我們聯絡,擷取測試指令碼以複現當前測試流程。
建立HNSW索引並寫入資料
建立索引:以下配置用於在億級資料規模下建立索引,以平衡構建速度、記憶體佔用和查詢效能。
定義索引結構和關鍵參數。
number_of_shards:設定為18,以在3個搜尋節點(共96個物理核心)間均勻分布資料和計算負載。ef_construction和m:HNSW索引構建時的關鍵參數,本次測試選擇128和8作為構建速度和索引品質的平衡點。refresh_interval和durability:為最大化測試效能進行的特定最佳化,不建議在生產環境直接使用。 詳細說明參見應用於生產環境。
執行以下命令建立索引。
curl -X PUT "http://<endpoint>:<port>/msmarco" -H 'Content-Type: application/json' -d' { "mappings": { "properties": { "docid": { "type": "keyword" }, "domain": { "type": "keyword" }, "emb": { "type": "knn_vector", "dimension": 1024, "method": { "engine": "faiss", "space_type": "l2", "name": "hnsw", "parameters": { "ef_construction": 128, "m": 8 } } }, "url": { "type": "text" } } }, "settings": { "index": { "replication": { "type": "DOCUMENT" }, "refresh_interval": "0s", "number_of_shards": "18", "translog": { "flush_threshold_size": "1gb", "sync_interval": "30s", "durability": "async" }, "knn.algo_param": { "ef_search": "64" }, "provided_name": "msmarco", "knn": "true", "number_of_replicas": "0" } } } '
寫入資料:將MSMARCO V2.1資料集寫入HNSW索引。
寫效能
總耗時:13523.85秒(約3.75小時),此時間包含資料網路傳輸、寫入translog以及後台HNSW索引構建的全部時間。
平均寫入輸送量:8394.11 docs/sec。
執行查詢效能測試
測試不同並發度和ef_search參數組合下的查詢輸送量(QPS)、延遲(Latency)和召回率(Recall)。
concurrency:類比從1到128個並發查詢。ef_search:查詢時在HNSW圖中搜尋的鄰居節點廣度。此值越大,理論上召回率越高,但計算開銷也越大,會導致QPS下降和延遲升高。
壓測命令
執行以下命令,對concurrency和ef_search的不同組合進行為期60秒的壓測。
# 樣本命令,請替換為實際指令碼
python benchmark.py --concurrency 1/2/4/8/16/32/64/128 --ef-search 32/64/128/256 --max-duration 60效能測試結果
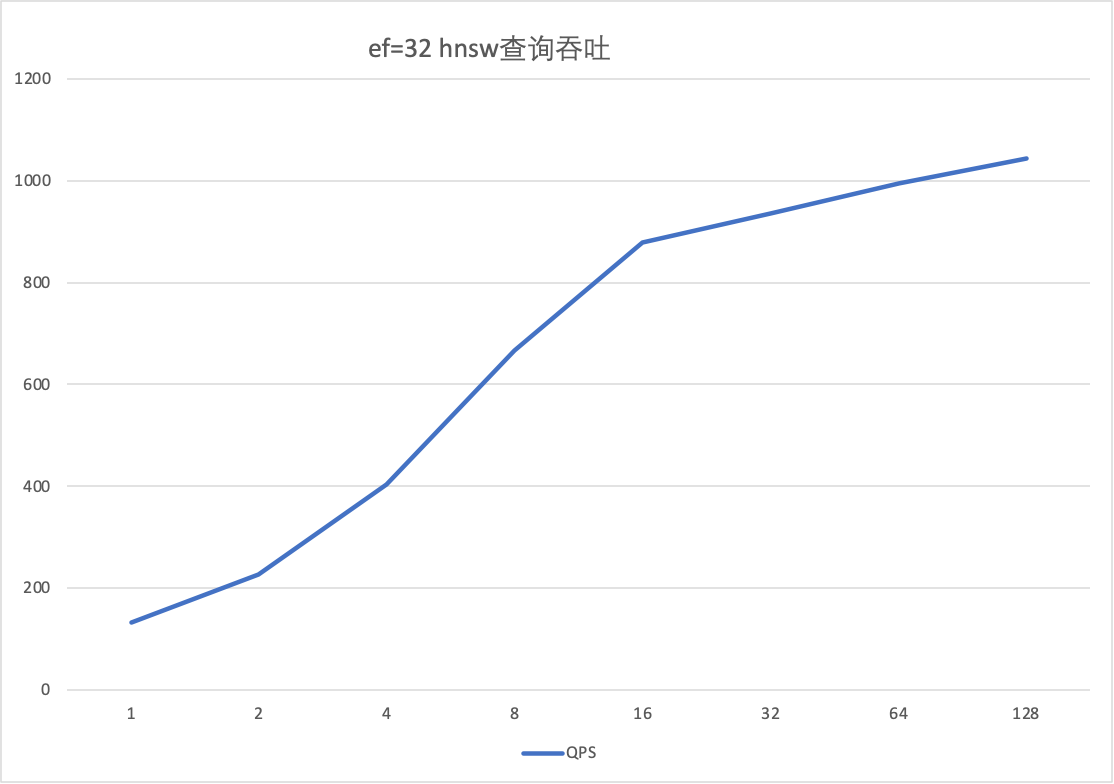
ef_search | concurrency | QPS | Avg(ms) | P99(ms) | Recall |
32 | 1 | 132.4 | 7.53 | 8.83 | 0.9585 |
32 | 16 | 878.19 | 18.13 | 30.14 | 0.9586 |
32 | 64 | 994.43 | 63.48 | 135.83 | 0.9621 |
32 | 128 | 1043.22 | 118.53 | 256.14 | 0.9693 |
64 | 1 | 132.82 | 7.5 | 8.82 | 0.9585 |
64 | 16 | 878.44 | 18.11 | 30.35 | 0.9586 |
64 | 64 | 989.47 | 63.77 | 136.55 | 0.9622 |
64 | 128 | 1062 | 116.74 | 238.94 | 0.9696 |
128 | 1 | 132.74 | 7.51 | 8.82 | 0.9585 |
128 | 16 | 884.77 | 17.99 | 29.91 | 0.9588 |
128 | 64 | 998.4 | 63.28 | 133.64 | 0.962 |
128 | 128 | 1063.91 | 116.85 | 244.43 | 0.9695 |
256 | 1 | 132.45 | 7.52 | 8.82 | 0.9585 |
256 | 16 | 881.95 | 18.05 | 30.16 | 0.9587 |
256 | 64 | 993.25 | 63.4 | 135.17 | 0.962 |
256 | 128 | 1067.68 | 116.09 | 227.54 | 0.9697 |
效能結論分析
並發擴充性:從QPS曲線可以看出,隨著並發數從1增加到64,系統輸送量(QPS)接近線性增長,表明PolarDB向量引擎具備良好的水平擴充能力。在64並發之後,QPS增長開始放緩,並在128並發時達到峰值,此時系統資源(很可能是CPU)已接近飽和,成為效能瓶頸。
延遲與並發關係:平均延遲(Avg)和P99延遲隨著並發數的增加而顯著升高,這符合系統負載增加的規律。在追求高QPS的情境下,需關注P99延遲是否滿足業務要求。
召回率表現:在所有測試條件下,召回率均穩定在95.8%以上,表明HNSW索引在當前參數下具有較高的搜尋準確性。
應用於生產環境
將測試環境的配置直接用於生產存在風險。以下內容提供關鍵參數的生產環境配置建議和資源規劃指導。
關鍵參數生產建議
以下參數為追求極限測試效能而設定,在生產環境使用時需謹慎評估。
"refresh_interval": "0s"測試目的:禁用自動重新整理,確保在寫入測試期間資料僅寫入記憶體和translog,在查詢測試前手動
refresh,以獲得不受背景工作幹擾的查詢效能資料。生產建議:禁止在生產環境設定為
0s。應根據業務對資料可見度的要求設定一個合理的值,例如1s,表示新寫入的資料最快在1秒後可被查詢到。
"durability": "async"測試目的:採用非同步刷盤(translog),資料先寫入記憶體後即返回成功,由後台線程非同步持久化到磁碟,以提升寫入輸送量。
生產建議:在高資料可靠性情境下慎用。
async模式在伺服器宕機等極端情況下,可能丟失最後幾秒鐘尚未刷盤的資料。若對資料可靠性要求高,應在生產環境使用預設的request模式。該模式會確保資料寫入translog並落盤後才返回成功,但會降低寫入效能。
資源使用率評估
瞭解系統在峰值負載下的資源消耗,對進行準確的容量規劃至關重要。
寫入密集型情境:在8394 docs/sec的峰值寫入期間,系統瓶頸主要體現在CPU(用於索引構建)和磁碟I/O(用於translog寫入)。
查詢密集型情境:在128並發、1067 QPS的峰值查詢期間,系統瓶頸主要為CPU密集型。