本文介紹如何在PAI-RAG的Web 介面進行各項配置,包括知識庫、Code沙箱、模型、搜尋服務和MCP工具等。
配置模型
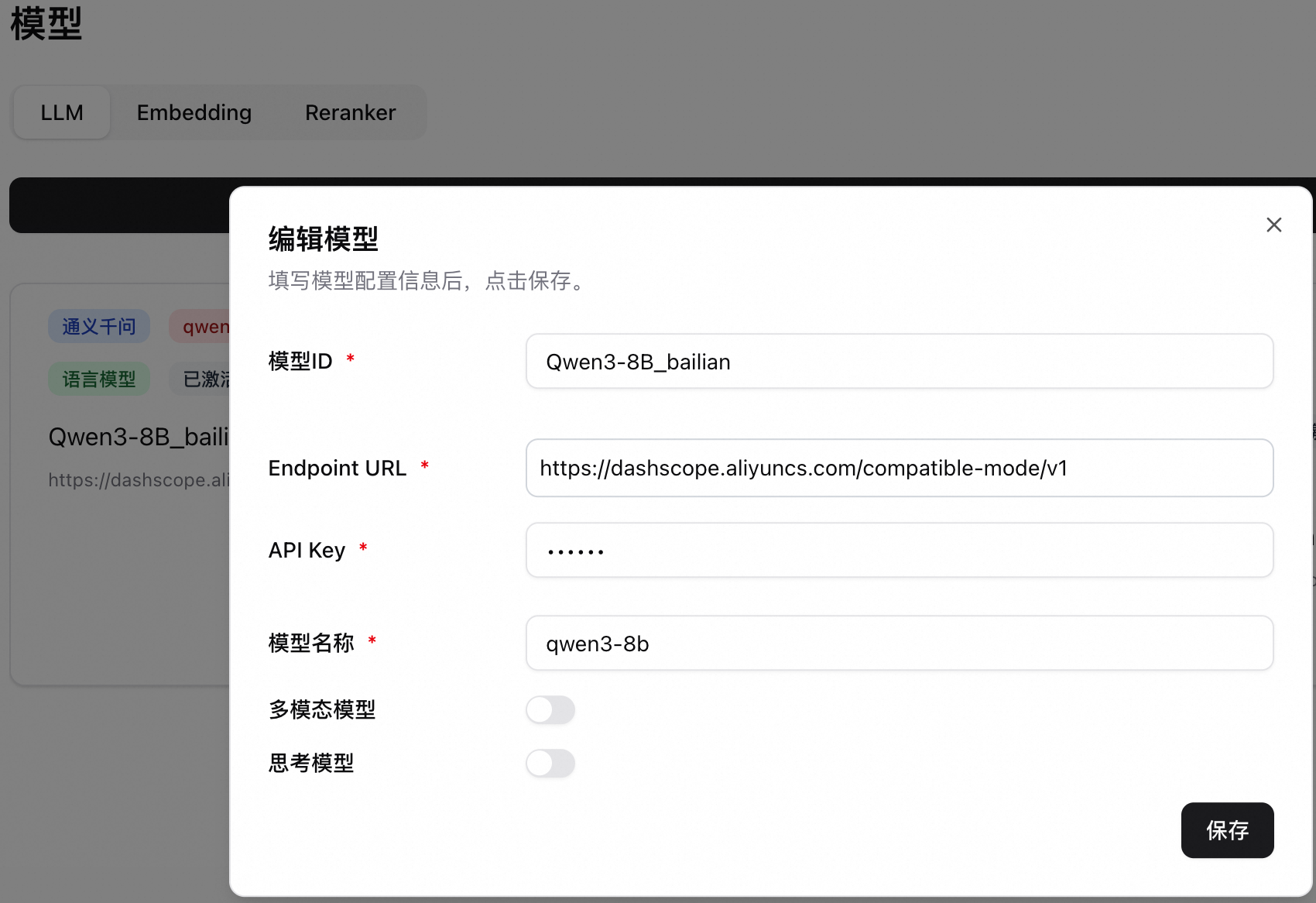
單擊左下角設定 > 模型,進入模型配置。在LLM頁簽添加模型。
如果是一體化部署,會自動產生一條模型配置記錄。還可以繼續添加其他來源的模型。
模型ID:區分不同的模型配置。
Endpoint URL:填寫模型服務地址。
說明阿里雲百鍊模型調用需單獨計費,請參見阿里雲百鍊計費項目說明。
如為EAS模型服務,在服務詳情的基本信息地區單擊查看调用信息。注意在調用地址後添加
/v1。使用公網調用地址需為RAG服務配置有公網訪問能力的專用網路。
使用VPC調用地址需RAG服務與LLM服務處於同一專用網路內。
API Key:阿里雲百鍊參見擷取API Key填寫。EAS服務則填寫調用資訊中的Token。
模型名稱:根據實際情況填寫。如果是EAS部署的LLM服務且推理引擎為vLLM,請務必填寫具體的模型名稱。可通過
/v1/models介面擷取模型名稱。對於其他部署模式,則只需將模型名稱設定為default即可。多模態模型:如果是多模態模型,則勾選,否則不勾選(預設不勾選)。
思考模型:有思考與非思考兩種模式的模型,可通過該選項來控制是否思考。預設不勾選。
配置成功後建議先測試模型配置。單擊左側建立對話,在對話頁面上方選擇模型進行對話測試。

配置MCP
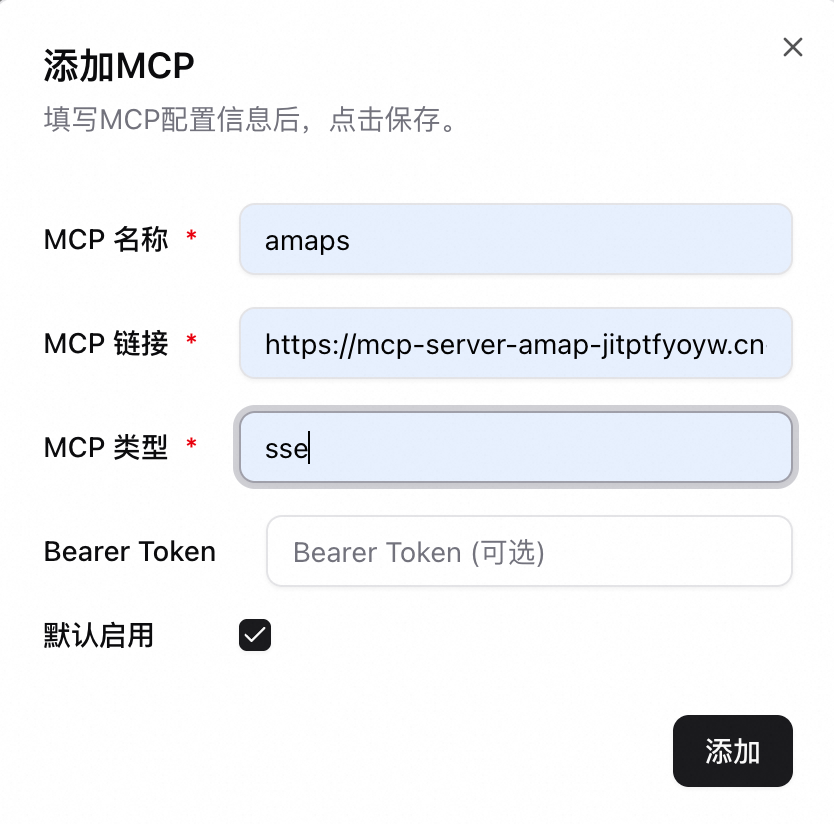
單擊左下角設定 > MCP,如下添加MCP。
MCP連結:MCP 服務的完整訪問端點 URL。
MCP類型:支援 SSE / STDIO / Streamable HTTP。
Bearer Token:(可選)使用Bearer令牌認證,需填寫有效存取權杖。
配置搜尋
當知識庫內容不足以覆蓋使用者問題,或者需要即時資訊時,可以啟用搜尋服務(Tavily )作為補充。
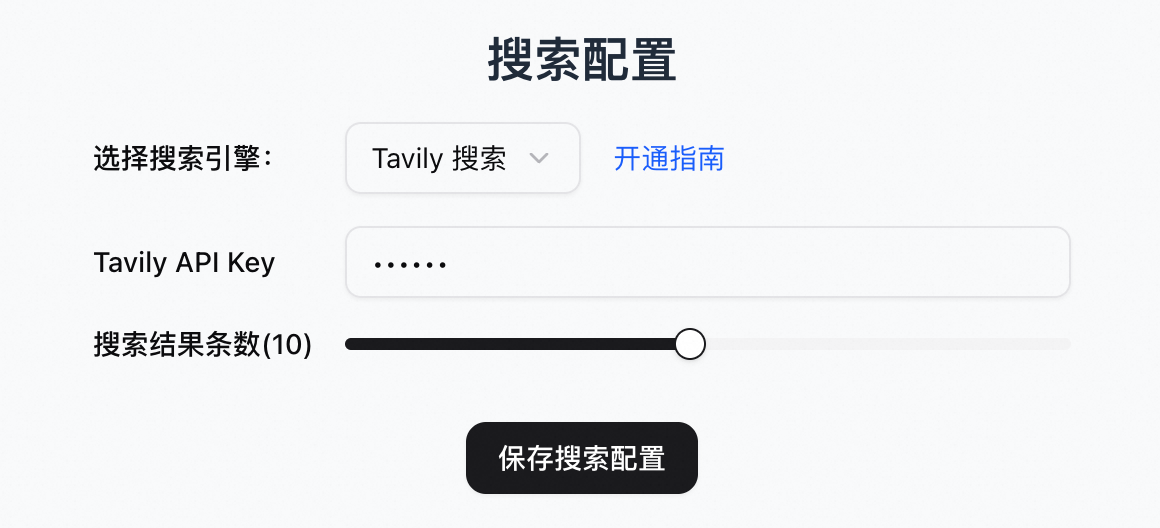
單擊左下角設定 > 搜尋,進入搜尋配置。
Tavily搜尋
訪問 Tavily 官網註冊賬戶,並擷取API Key。
配置 Code 沙箱
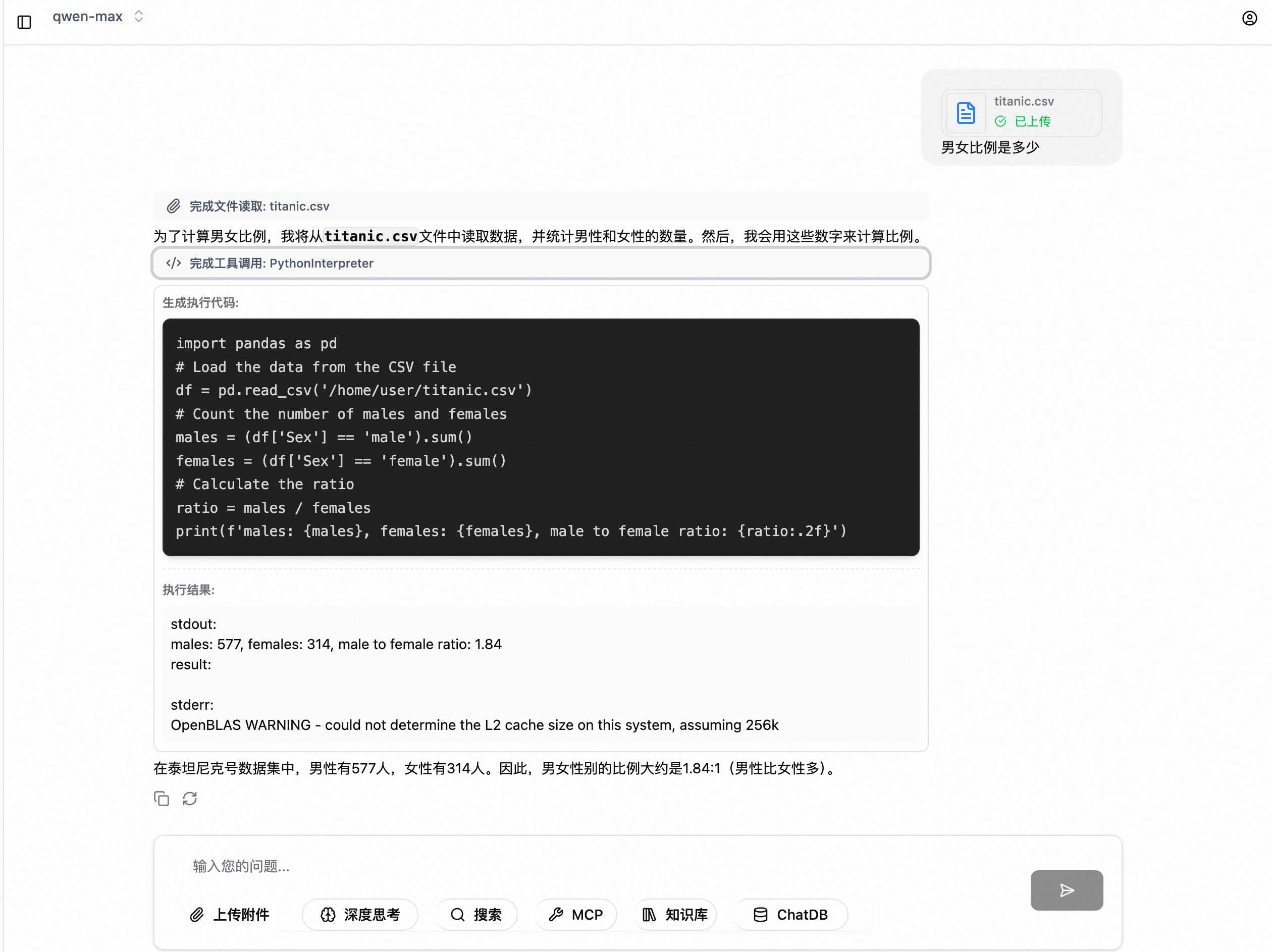
Code沙箱提供安全的 Python 代碼運行環境。開啟 Code 沙箱功能後,當 AI 助手需要執行代碼時,會自動調用Code沙箱工具。
使用情境
資料分析:執行資料統計、彙總、過濾等操作。例如:"幫我分析銷售資料,計算各地區的平均銷售額"。
資料視覺效果:組建圖表、繪製趨勢圖等。例如:“繪製過去一年的銷售趨勢圖”。
數學計算:執行複雜的數學運算、方程求解。例如:“計算這個數列的標準差”。
檔案處理:解析CSV、Excel等檔案,提取和轉換資料。
其他需要代碼執行的任務
前置準備
配置Code沙箱前需要完成以下準備工作:
開通Function Compute服務:訪問Function Compute控制台,按照提示開通服務。
建立AgentRun解譯器:訪問AgentRun控制台,左側導覽列選擇Sandbox 沙箱,建立沙箱模板,類型選擇代碼解譯器。注意:
說明網路類型預設選擇允許預設網卡訪問公網,要求RAG服務能訪問公網。
可以選擇允許訪問VPC,並確保與RAG服務配置同樣的專用網路。
擷取訪問憑證:擷取阿里雲帳號ID、沙箱 ID用於後續配置。如設定了訪問憑證還需API Key。
配置方式
單擊左下角設定 > Code沙箱,配置以下參數:
啟用沙箱:開啟/關閉沙箱功能。
沙箱類型:當前僅支援阿里雲FC沙箱。
阿里雲ID:阿里雲帳號ID。
解譯器ID:沙箱 ID。
解譯器名稱:代碼解譯器名稱。
API Key:填寫存取金鑰,用於身分識別驗證。
預設逾時(秒):代碼執行的最大時間長度(秒)。預設50秒。
設定檔分塊策略
分段設定用於配置知識庫中文檔的切片方式,決定文檔如何被切分成若干片段(chunk),以便後續做向量化與檢索。合理的分段設定能提升檢索命中率與回答品質。
支援知識庫和檔案層級的配置:
知識庫分段設定:上傳到該知識庫的檔案在解析時會預設使用當前知識庫的分段設定。
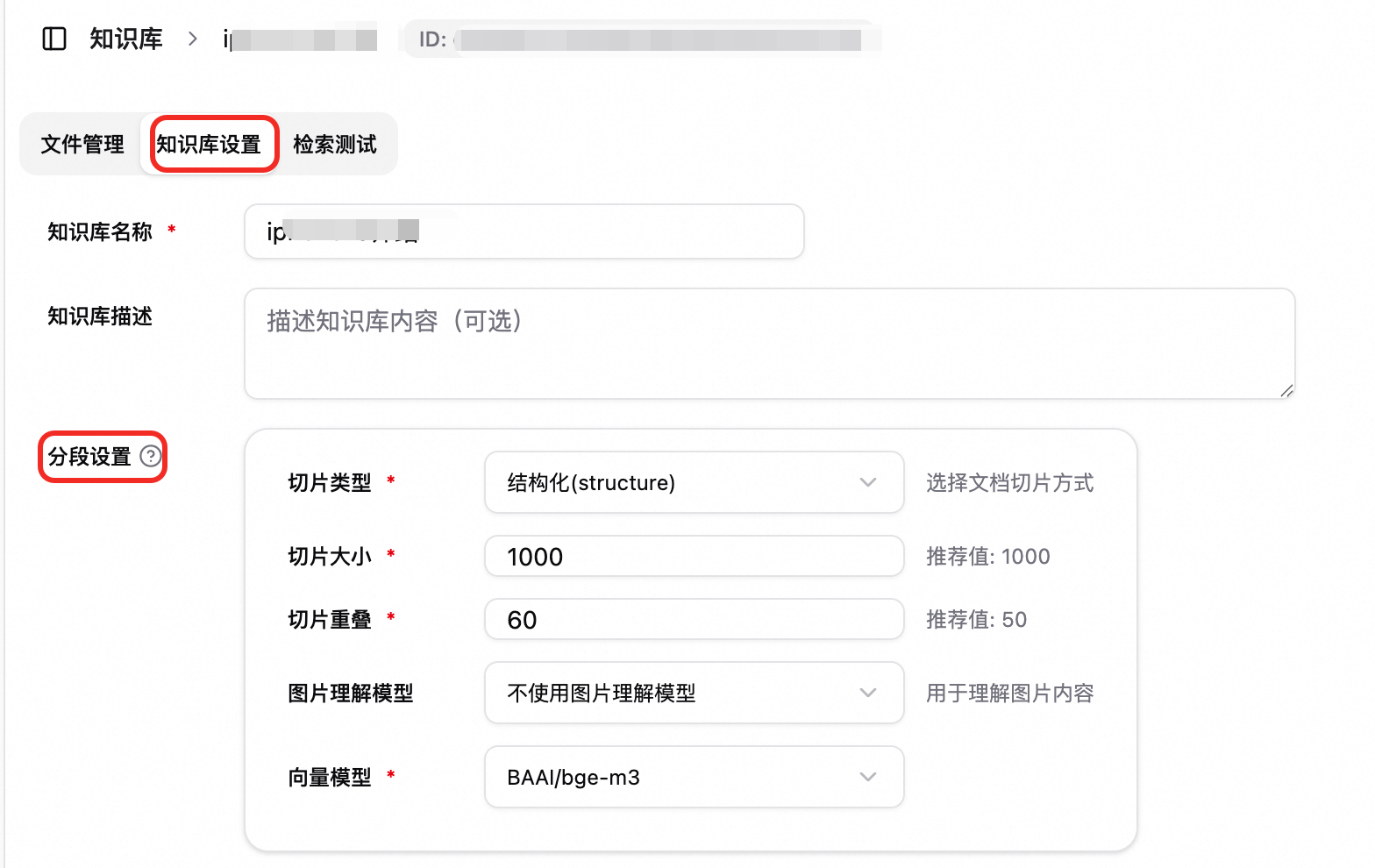
指定檔案的分段設定:
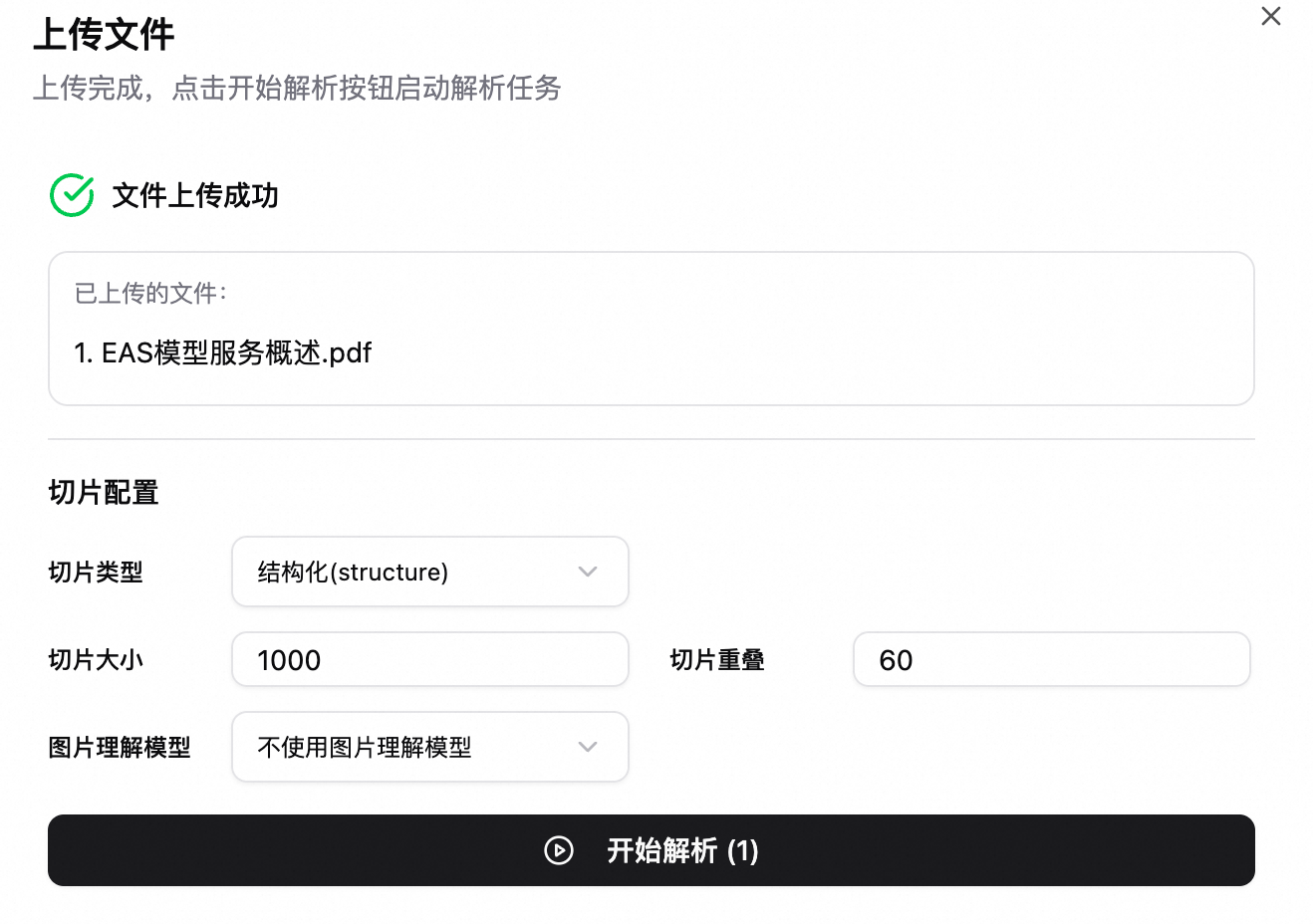
在上傳檔案時,可為該檔案單獨指定分段參數;
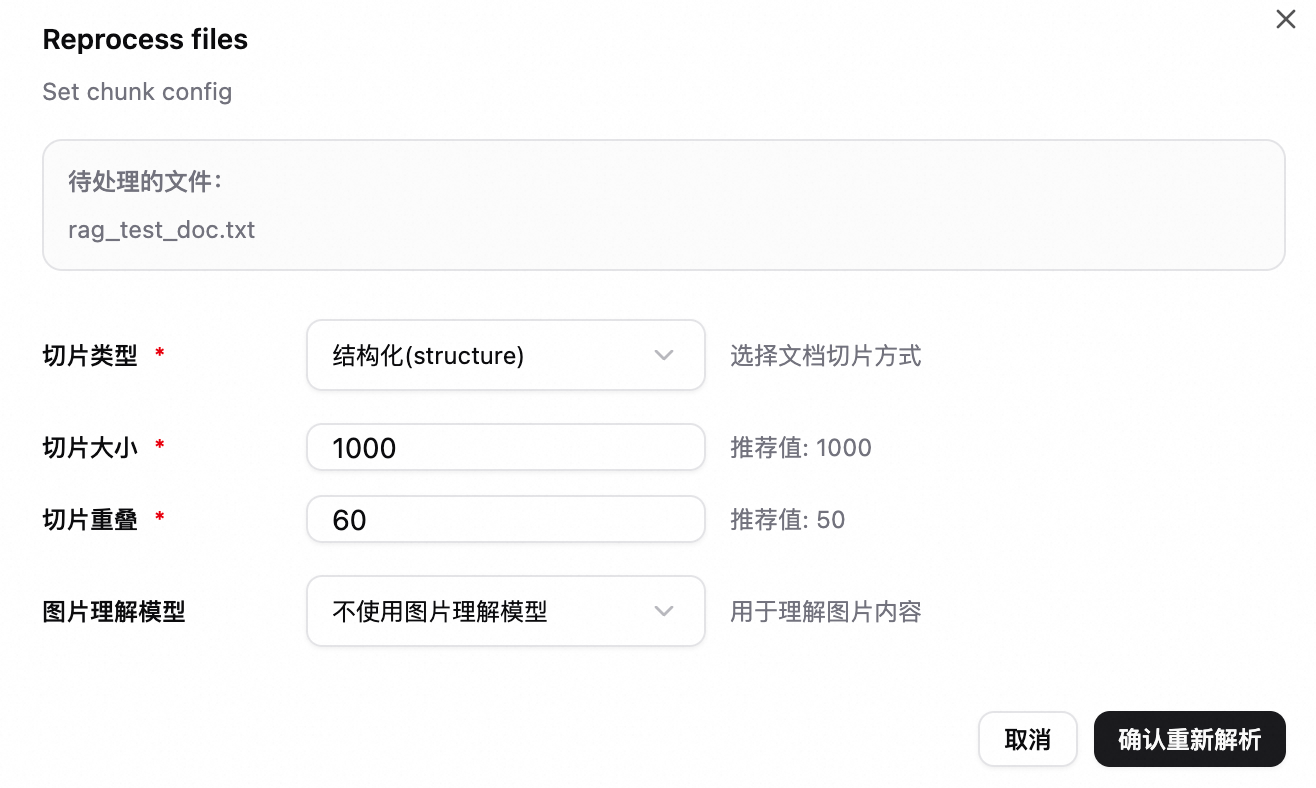
對已有檔案執行重新解析操作時,也可指定分段設定並觸發重新處理。
前置要求
在使用分段設定之前,您需要:
已建立知識庫:在系統中已有一個可用的知識庫。
已配置 Embedding:系統內已添加至少一個向量(Embedding)模型。
(可選)多模態模型:若需使用圖片理解模型,需在系統中配置支援視覺的模型。
參數說明
參數 | 說明 |
切片類型 | 根據文檔特點選擇合適的切片類型:
|
切片大小 | 每個切片的最大長度(字元數或 token 數,依類型而定)。推薦值:1000。 |
切片重疊 | 表相鄰切片之間重疊的長度,用於保留上下文、避免語義被截斷。推薦值:50。 重要 切片大小需大於切片重疊。 |
圖片理解模型 |
|
向量模型 |
|
調優建議:建議先使用預設配置上傳少量文檔進行測試,通過評估模組分析召回率和準確率,再根據實際效果調整參數。
使用建議
長文檔 RAG:設定切片類型為結構化、切片大小 1000、重疊 50,在保證內容相關的前提下控製片段長度。
需要嚴格按照分隔字元切分文檔:使用段落 (paragraph)切分方式,自訂分隔字元號。
表格式資料:切片類型選擇表格 (table) ,配置表頭行與行分隔字元,將 Excel/CSV 按行或按塊接入檢索,如果不勾選合并行選項,則是按照行切分,勾選合并行選項,可以按照切片大小的限制將行合并為塊。
多模態文檔:開啟圖片理解模型,使 PDF、帶圖文檔中的圖片內容參與檢索與回答。
配置應用 FAQ
FAQ(常見問題)功能允許為每個應用維護一套問題-答案知識庫,適用於產品說明書、客服話術、常見問題等。
應用啟用FAQ功能並配置好條目後,在對話時,流程如下:
AI 助手會優先從 FAQ 中檢索與使用者問題最相似的條目
若命中且滿足相似性閾值,將根據配置選擇直接返回 FAQ 答案或結合 FAQ 結果由模型產生回答
若未命中或未啟用直接返回,則會繼續使用知識庫、搜尋等其它能力回答。
配置方式:
登入系統後,進入目標應用的配置頁。
啟用 FAQ:在應用配置中開啟啟用 FAQ開關並儲存。
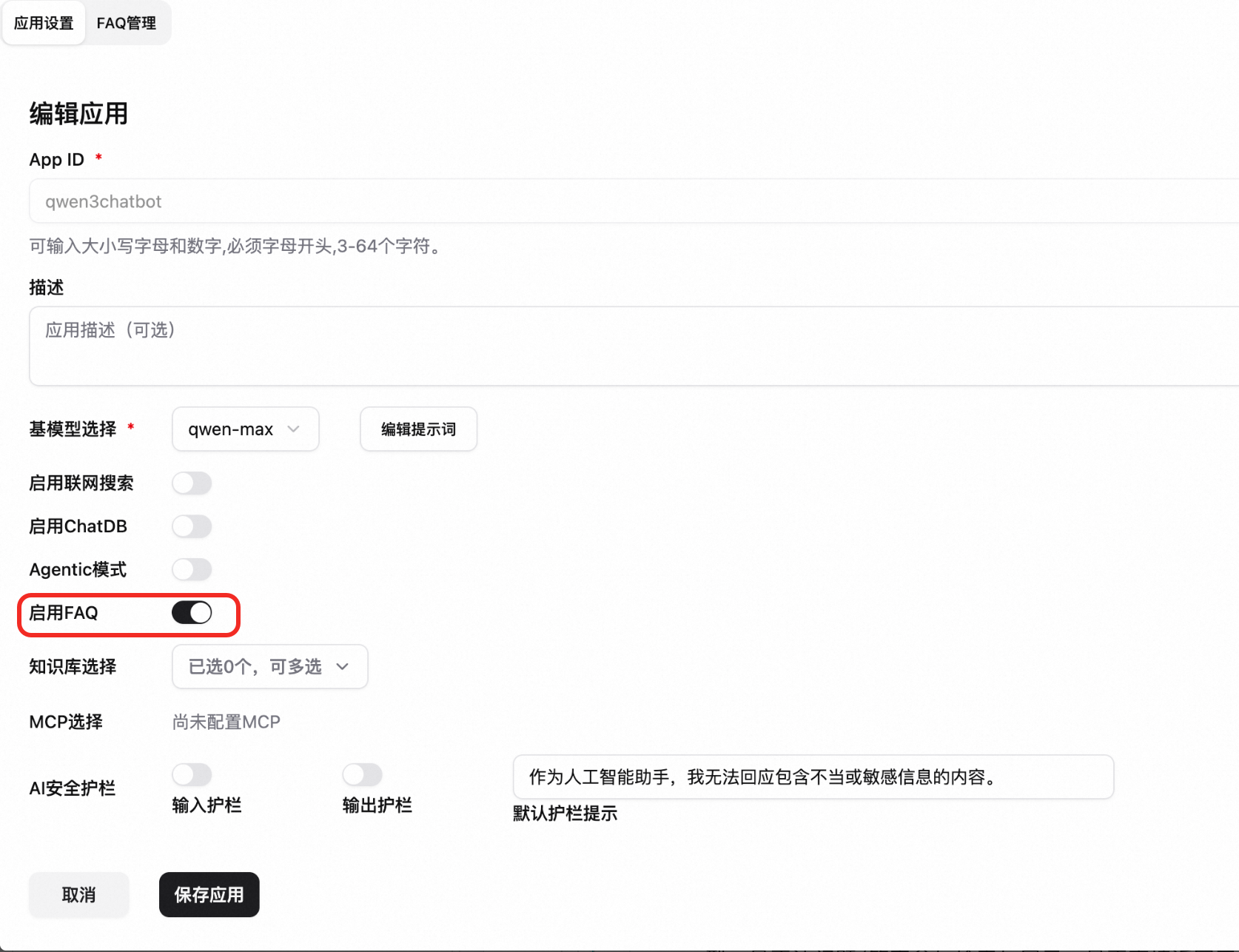
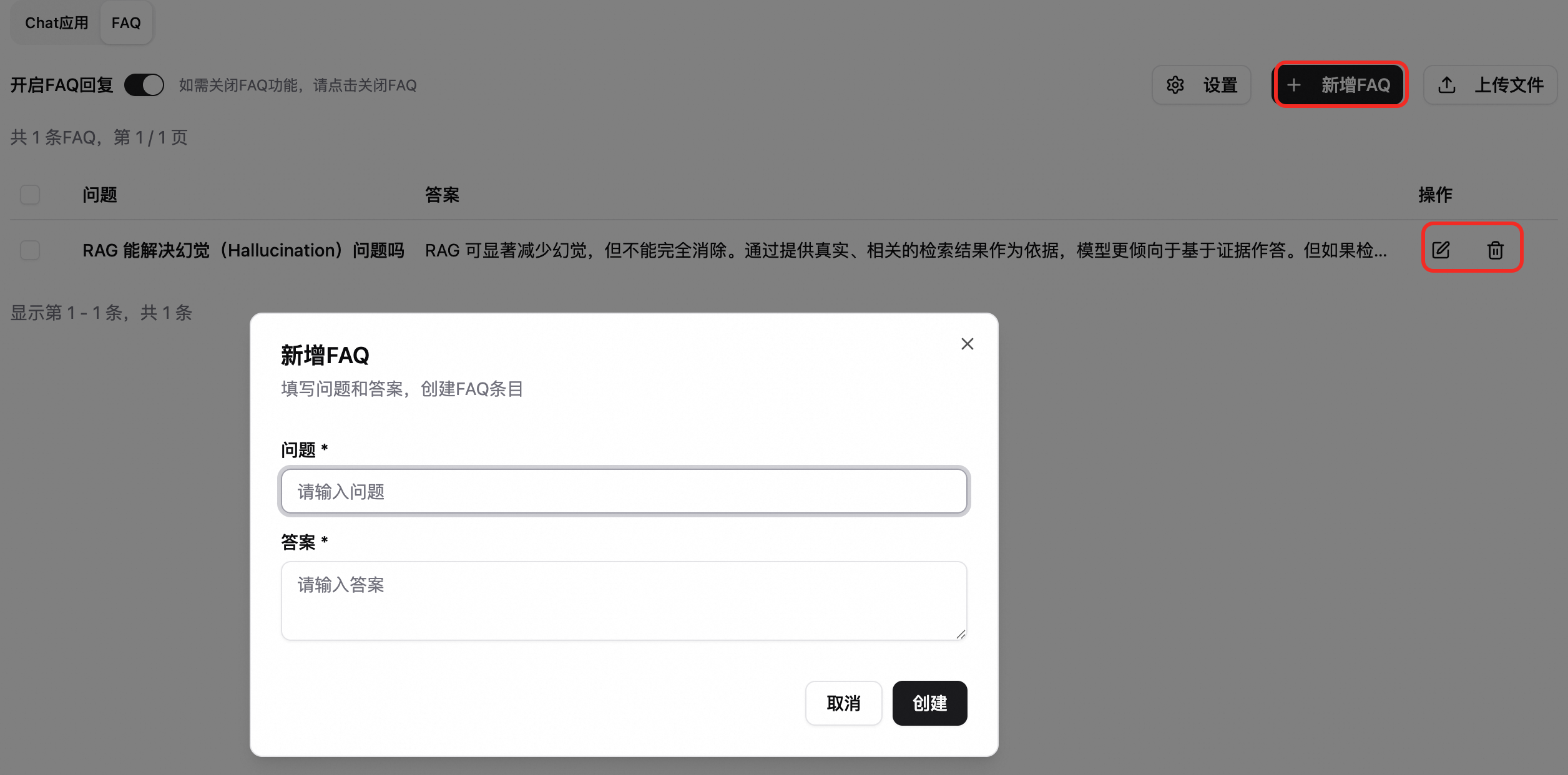
開啟FAQ管理,在 FAQ 管理頁面中可進行:
FAQ 回複設定:單擊設定按鈕,設定相似性的分數閾值(建議 0.8~1.0)、Embedding 模型、是否讓問題/答案參與檢索與展示、是否直接返回工具結果等。

維護 FAQ:
新增、編輯、刪除單條FAQ。
大量刪除

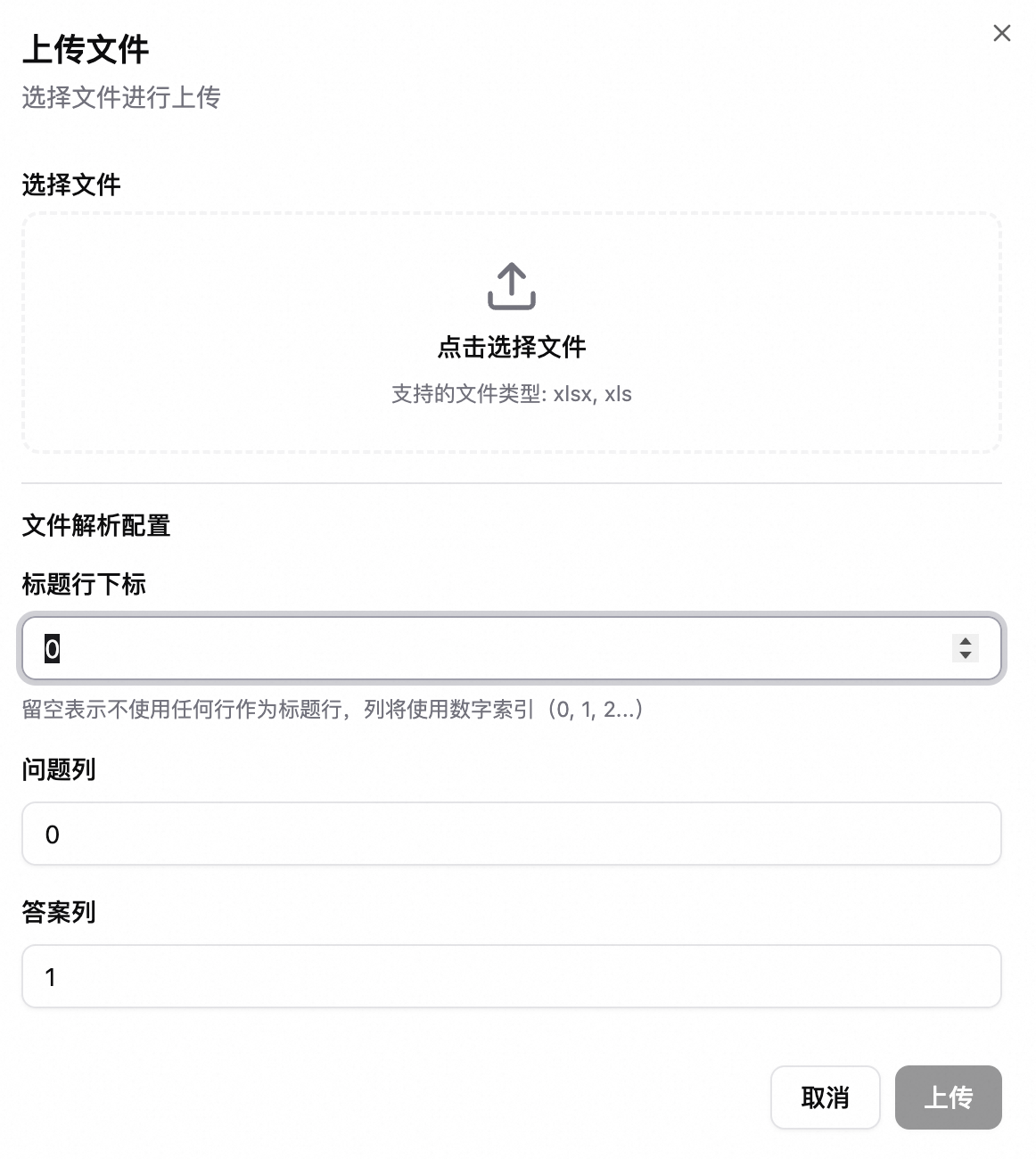
大量匯入:上傳 Excel 檔案,按列映射「問題列」「答案列」後一鍵匯入。
儲存後,該應用的對話將自動優先使用 FAQ 檢索結果。