本文為您介紹如何使用SD WebUI進行PAI ArtLab Stable Diffusion模型的生圖實踐,包括具體步驟和注意事項。
點擊登入PAI ArtLab控制台。
背景資訊
Stable Diffusion是由Stability AI開發的映像AI大模型,能夠根據文本指令產生或修改映像。Stable Diffusion WebUI是由AUTOMATIC1111為該模型開發的可視化瀏覽器介面,使用者即使不具備編程知識,也能通過直觀的前端互動便於使用模型功能。
通過WebUI,您可以享受直觀的操作體驗,並通過裝載不同的外掛程式和模型滿足定製化需求,創造更為可控的視覺作品。
模型切換地區
將下載的模型上傳至OSS對應目錄中,然後重新整理WebUI頁面更新模型。推薦模型下載地址:C站。
如果無法訪問,您可能需要設定代理後再嘗試重新訪問。
文生圖
通用prompt結構
常見的通用範式: 首碼(畫質詞+畫風詞+鏡頭效果+光照效果) + 主體(人物&對象+姿勢+服裝+道具) + 情境(環境+細節)
使用半形括弧
()可以提高權重,將想要強調的提示詞括起來,在提示詞後面增加冒號和權重值,例如(beautiful:1.3)。權重取值範圍推薦(0.4~1.6),權重過低容易被忽略,權重過高容易過擬合導致圖片畸形;也可以直接使用半形括弧()來疊加權重,每增加一層相當於提高1.1倍權重,例如:(((cute)))權重計算公式:
(PromptA:權重):用於提高或降低該提示詞的權重比例,註:數值大於1提高,小於1降低。(PromptB):PromptB的權重為1.1=(PromptA:1.1) {PromptC}:PromptC的權重為1.05=(PromptB:1.05) [PromptD]:PromptD的權重減弱0.952=(PromptC:0.952) ((PromptE)=(PromptE:1.1*1.1) {{PromptF}}=(PromptF:1.05*1.05) [[PromptG]]=(PromptG:0.952*0.952)
使用
<>可以調取LoRA和超網路模型,輸入格式為:<lora:filename:multiplier>,<hypernet:filename:multiplier>提示詞混合調度:
[promptA:promptB:factor],factor表示從promptA切換到promptB步驟的百分比,範圍為0~1。例如
a girl holding an [apple :peach:0.9]和a girl holding an [apple :peach:0.2],使用相同的Seed值,通過調整factor數值,在產生高度相似的圖片的同時,對圖片進行微調,實現更換映像中的某一個元素的功能。常見提示詞描述
正向提示詞(希望在圖片中出現)
負向提示詞(不希望在圖片中出現)
prompt
描述
negative prompt
描述
HDR,UHD,8K,4K
可以提高圖片的品質
mutated hands and fingers
變異的手和手指
best quality
豐富圖片的細節
deformed
畸形的
masterpiece
傑作
bad anatomy
解剖不良
Highly detailed
增加圖片細節
disfigured
毀容
Studio lighting
添加演播室燈光,可以給圖片增加紋理
poorly drawn face
臉部畫得不好
ultra-fine painting
超精細繪畫
mutated
變異的
sharp focus
聚焦清晰
extra limb
多餘的肢體
physically-based rendering
基於物理渲染
ugly
醜陋
extreme detail description
刻畫細節
poorly drawn hands
手部畫得很差
Vivid Colors
增加圖片色彩
missing limb
missing limb
(EOS R8, 50mm, F1.2, 8K, RAW photo:1.2)
專業攝影描述
floating limbs
漂浮的四肢
Boken
虛化模糊背景,突出主體。
disconnected limbs
肢體不連貫
Sketch
素描
malformed hands
畸形的手
Painting
繪畫
變異的
脫離焦點
-
-
long neck
長頸
-
-
long body
身體長
效果展示
簡單prompt:在對應地區輸入正向提示詞和反向提示詞,提示詞越多,AI繪圖結果會更加精準。
複雜prompt:
正向prompt:8k portrait of beautiful cyborg with brown hair, intricate, elegant, highly detailed, majestic, digital photography, art by artgerm and ruan jia and greg rutkowski surreal painting gold butterfly filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr
負向prompt:canvas frame, cartoon, 3d, ((disfigured)), ((bad art)), ((deformed)),((extra limbs)),((close up)),((b&w)), wired colors, blurry, (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), Photoshop, video game, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, 3d render
prompt來源:請參見C站。
說明如果無法訪問,您可能需要設定代理後再嘗試重新訪問。
prompt:越靠前的詞權重越大,根據自己的需求調整詞語的順序,例如:主體(Subject)、繪畫介質(Medium)、繪畫風格(Style)、藝術家名(Artist)、網站(Website)、清晰度(Resolution)、細節描述(Additional details)、顏色(Color)、光影效果(Lighting)。在實際編寫的指令中,不需要包含以上所有分組裡的關鍵詞,根據自己的需求來設定關鍵詞和順序即可。除基本模型外,已經訓練好的模型一般會有隱藏設定,自動觸發一些固定風格,或捨棄部分prompt,根據實際情況而定。
參數介紹
①採樣方法(Sampler)
擴散去噪演算法的取樣模式,不同的採樣方法會有不同的效果,根據實際使用方式選擇合適的採樣方法。其中,Euler a(常用)、DPM++ 2S a、DPM++ 2S a Karras整體構圖較為相似;Euler 、DPM++ 2m、DPM++ 2M Karras整體構圖比較相似;DDIM的構圖風格比較不同。

②迭代步數(Steps)
產生圖片的迭代次數是決定AI最佳化效果的關鍵因素,每一次迭代都意味著AI系統將有更多機會對比Prompt與當前產生映像,並據此進行精細化調整。提高迭代步數會消耗更多的時間和計算資源,但並不能保證結果會更好。
在實際應用中,隨著迭代步數的增加,產生的映像通常會呈現出更豐富的細節,與取樣模式息息相關。以Euler a為例,大約在30~40步,產生的圖片細節趨於穩定點,進一步增加迭代步數不會增加新的細節。


③高解析度修複 (Hires. fix)
可以影響圖片的解析度。使用兩個步驟的過程進行產生,以較小的解析度建立映像,然後在不改變構圖的情況下改進其中的細節。勾選後需要設定高分迭代步數、重繪幅度等參數。
高清修複方式,請參見PAI ArtLab高清修複的三種方式。
④寬度&高度:圖片的尺寸和解析度,對顯存的消耗較大,解析度越大細節越多,不建議設定過大,預設512x512即可。
⑤總批次數
不同批次產生的圖片細節不同,數值越大,需要計算的時間越久。
⑥單批數量
每批同時產生的圖片數量,對顯存消耗較大。
⑦提示詞引導係數(CFG Scale)
數值越大,越接近Prompt詞;參數值越小,AI產生的自由創作空間越大。
⑧隨機數種子(Seed)
參數值為-1表示每一次產生都是隨機;若為其他任意數值(可為負數和小數),seed值一致,其他參數一致,模型一致,GPU一致,可以產生相同圖片。
⑨從提示詞或上次產生的圖片中讀取產生參數。
⑩清空提示詞內容。
圖生圖
圖生圖技術可以根據提示詞,將一張圖片轉化為具有新特點的另一張圖片,如將真人照片轉為動漫形象或為線稿上色。該功能支援參數調整和局部重繪,使用者可以在指定地區進行修改或重繪。
產生的圖片可以迴圈創作或局部再編輯,並可用於其他附加功能。系統能根據輸入圖片自動產生關鍵詞,通過CLIP(適用於寫實風格)和DeepBooru(適用於動漫風格)兩種AI模型實現反推。
具體操作步驟如下。
圖生圖(單擊查看詳情)
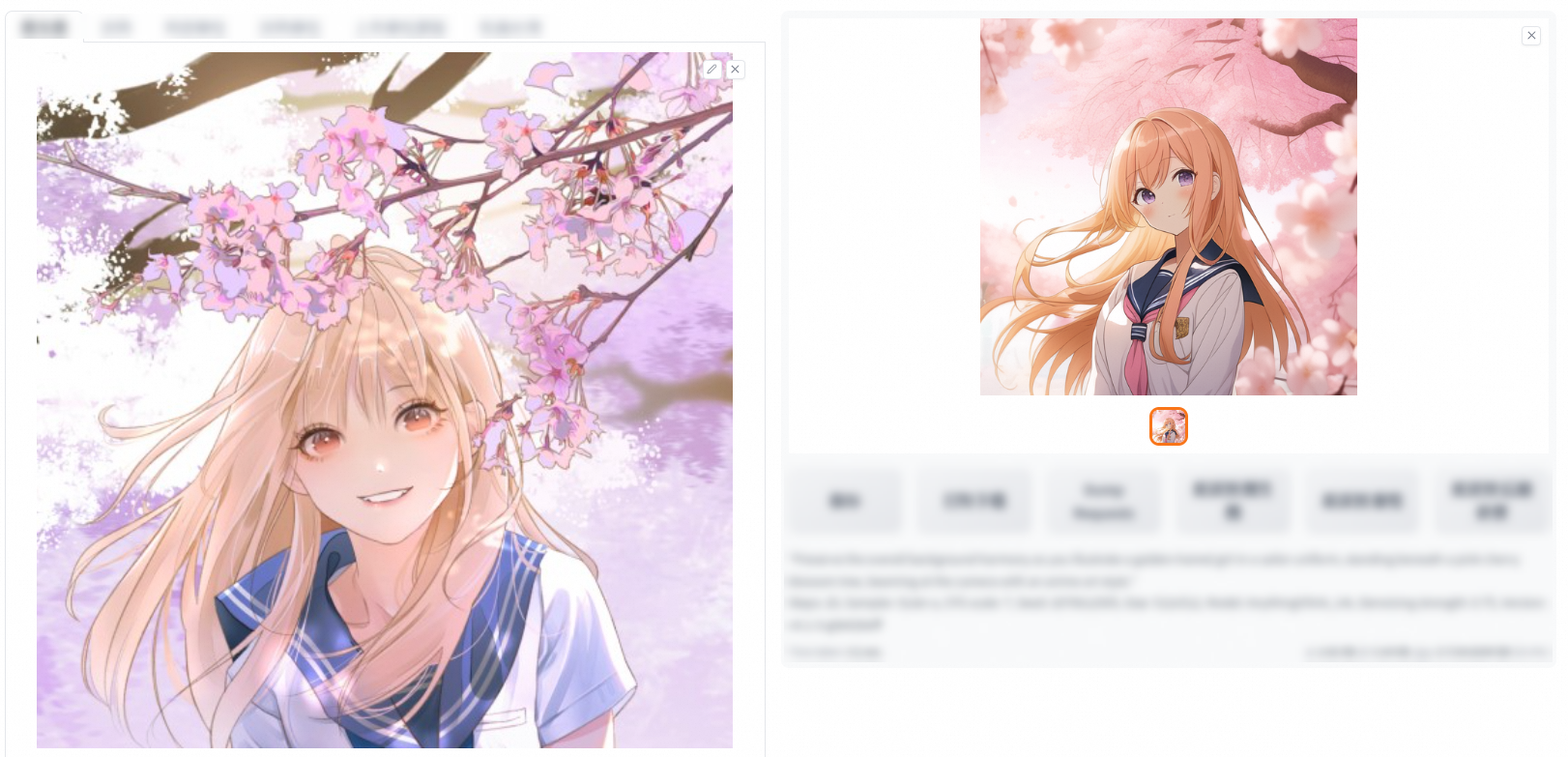
單擊選框上傳圖片,圖片比例需與設定的長寬一致,例如,512*512的圖片需為1:1比例。
使用反推提示詞CLIP/DeepBooru,或自己填寫補充Prompt和Negative Prompt,單擊產生,即可產生一張基於已上傳圖片的新圖片。
塗鴉(單擊查看詳情)
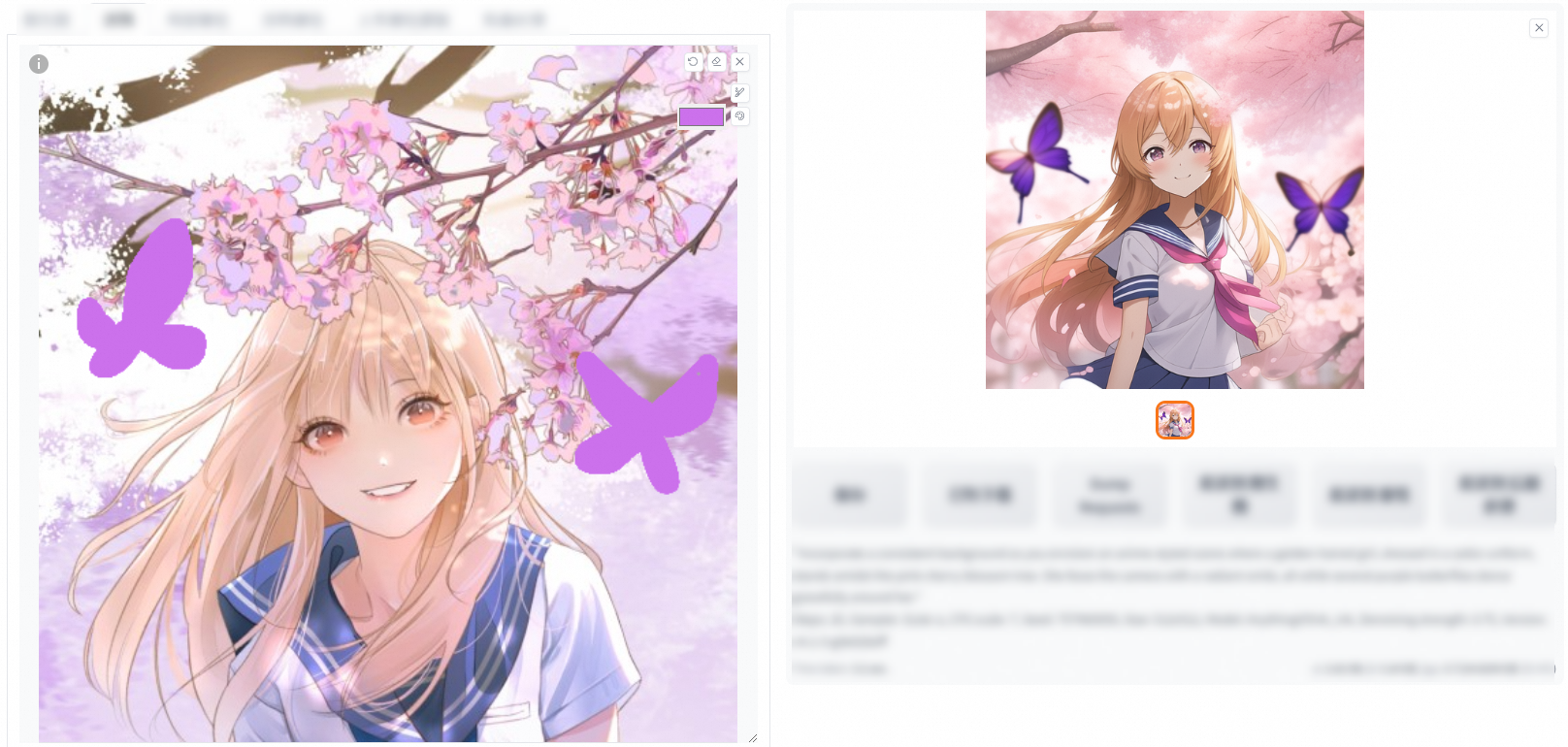
上傳普通圖片
在已上傳的圖片上進行塗鴉,可以配合修改部分Prompt,再次產生的圖片就會包含塗鴉部分。
上傳線稿草稿
自主上色,配合Prompt可以產生不同風格的圖。
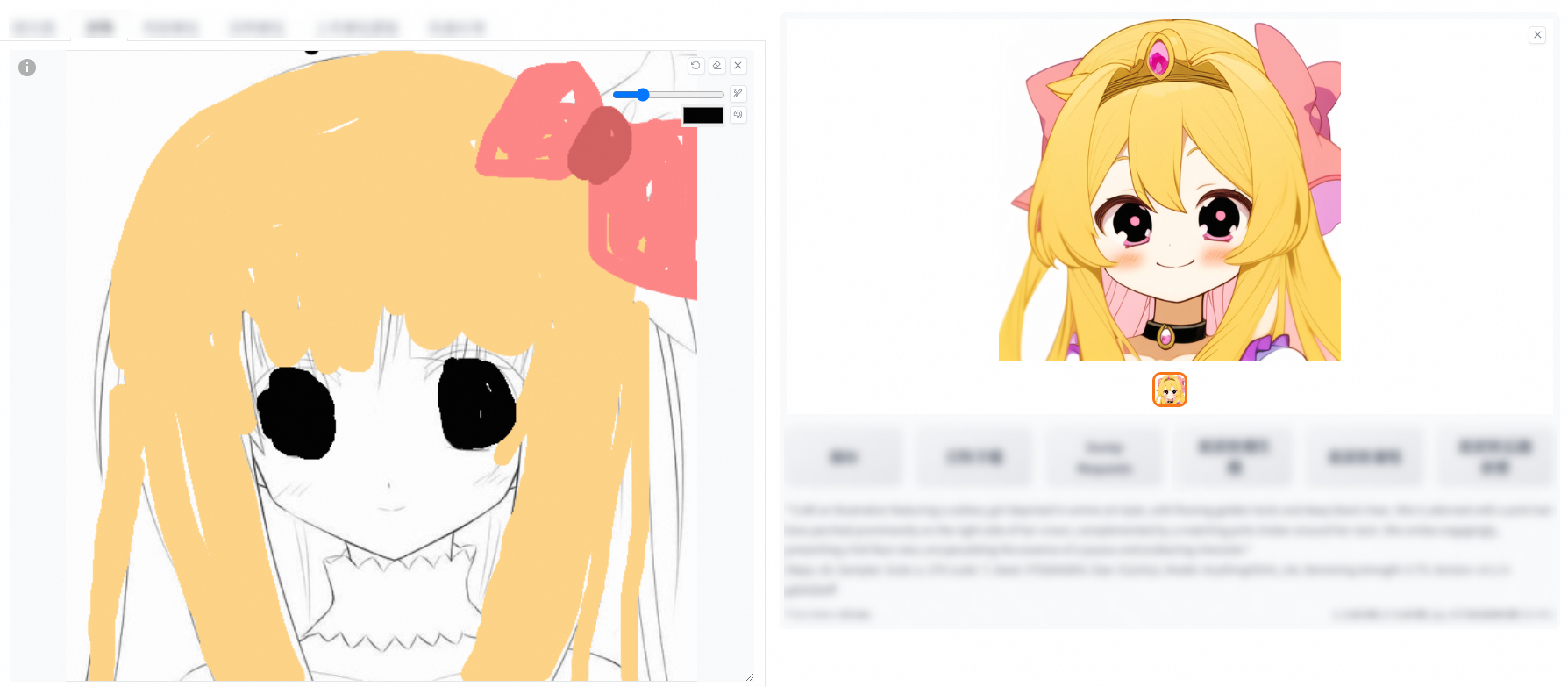
Sketch可以提高我們創作映像的效率和創造力,它使得不具備精湛繪畫技能的使用者也能輕鬆駕馭,只需憑藉自身的想象力,即可將各種創意點子流暢轉化為高品質的視覺映像。
局部重繪(單擊查看詳情)
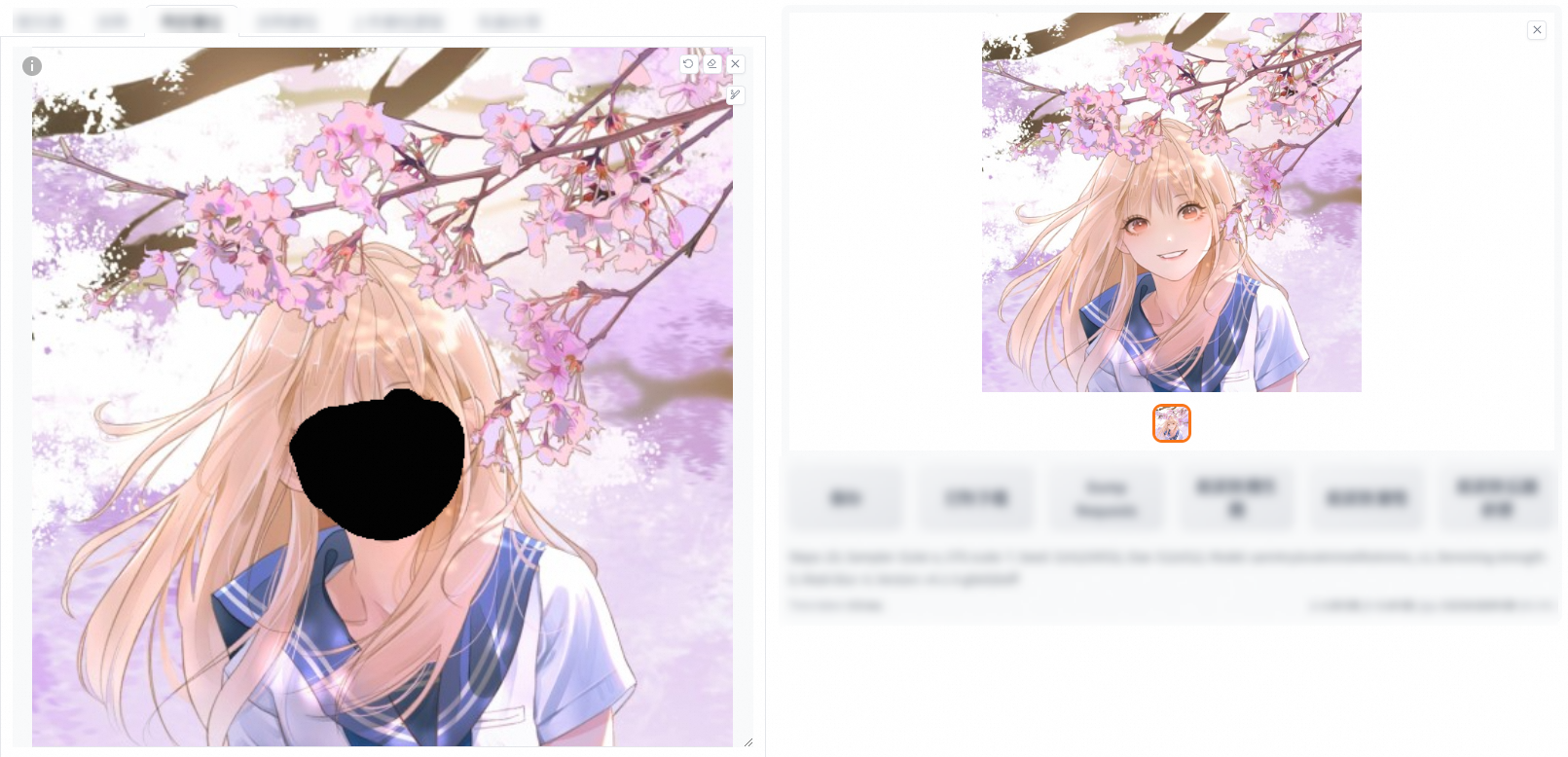
在原圖上添加一個蒙版(將需要修改的部位塗黑),對蒙版或者非蒙版地區進行重繪操作。
重繪蒙版內容
在Prompt中加上想要修改成的內容,單擊產生即可。例如,下圖在原來的Prompt中增加了wears sweater。
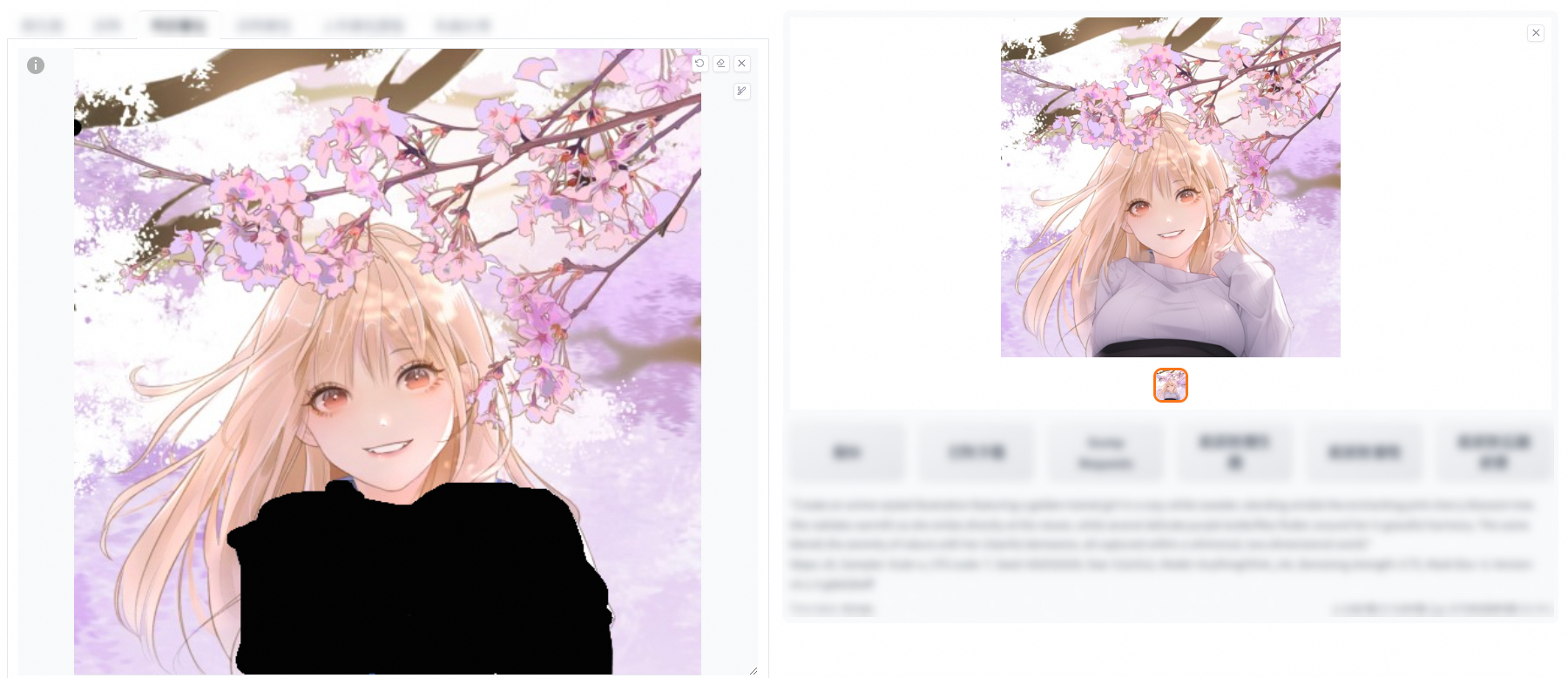
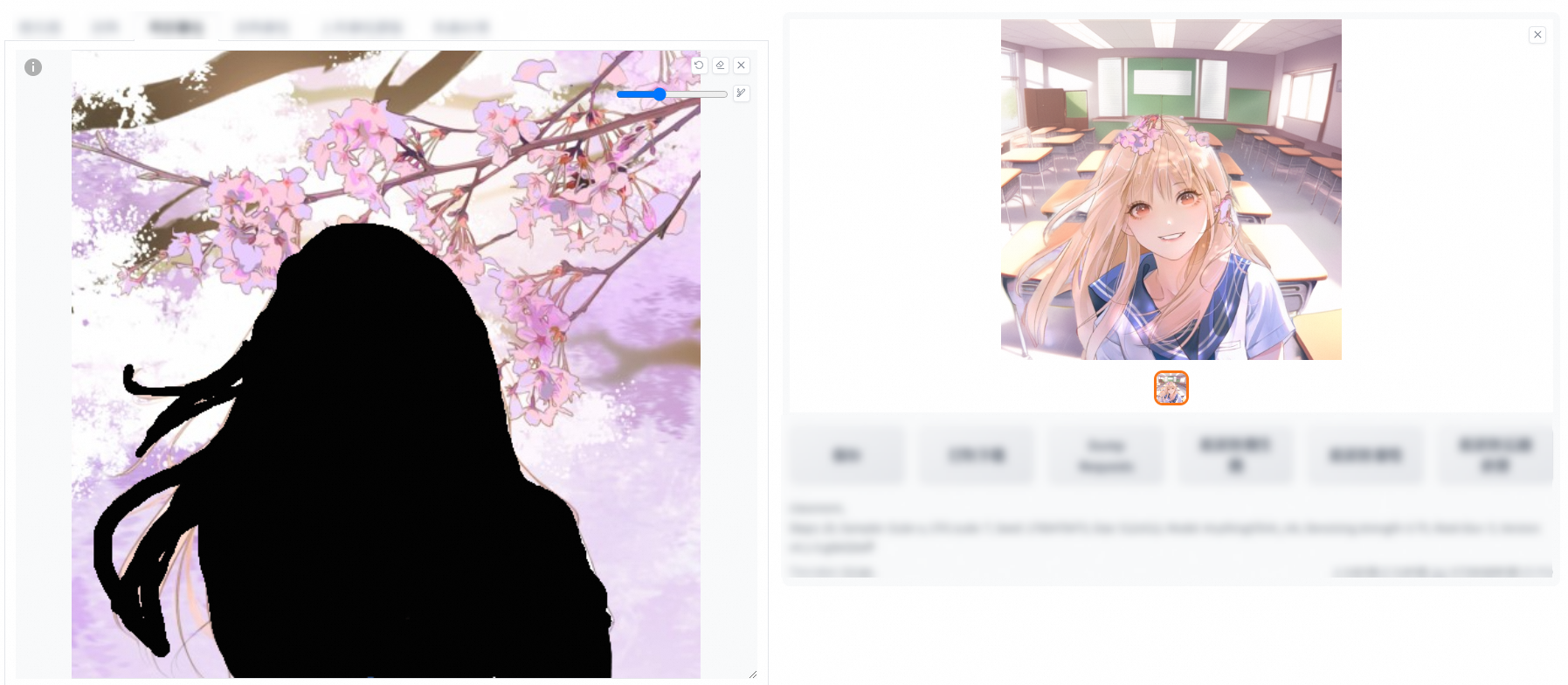
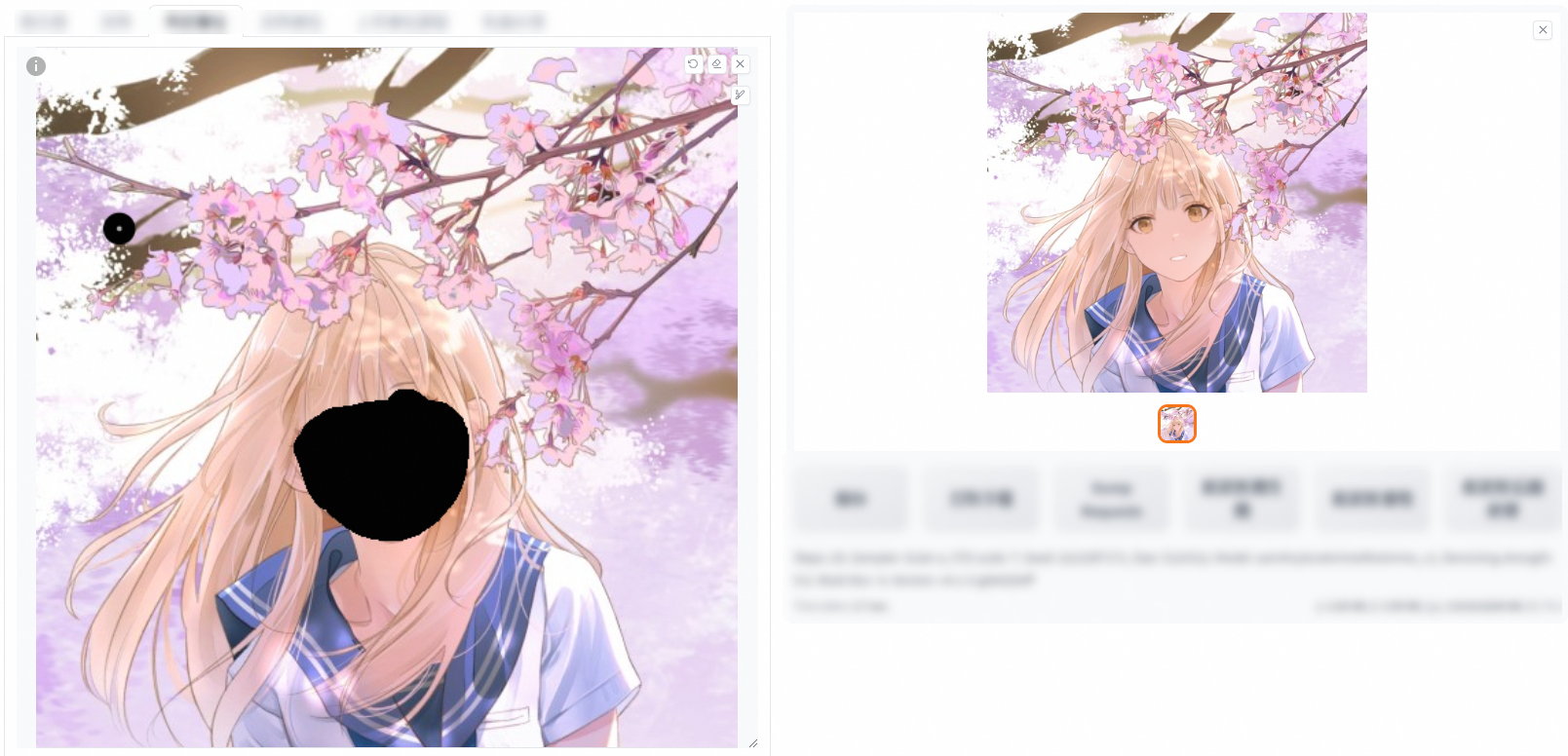
重繪非蒙版內容
在Prompt中加上想要修改成的內容,單擊產生即可完成。例如,下圖在原來的Prompt中增加了classroom。
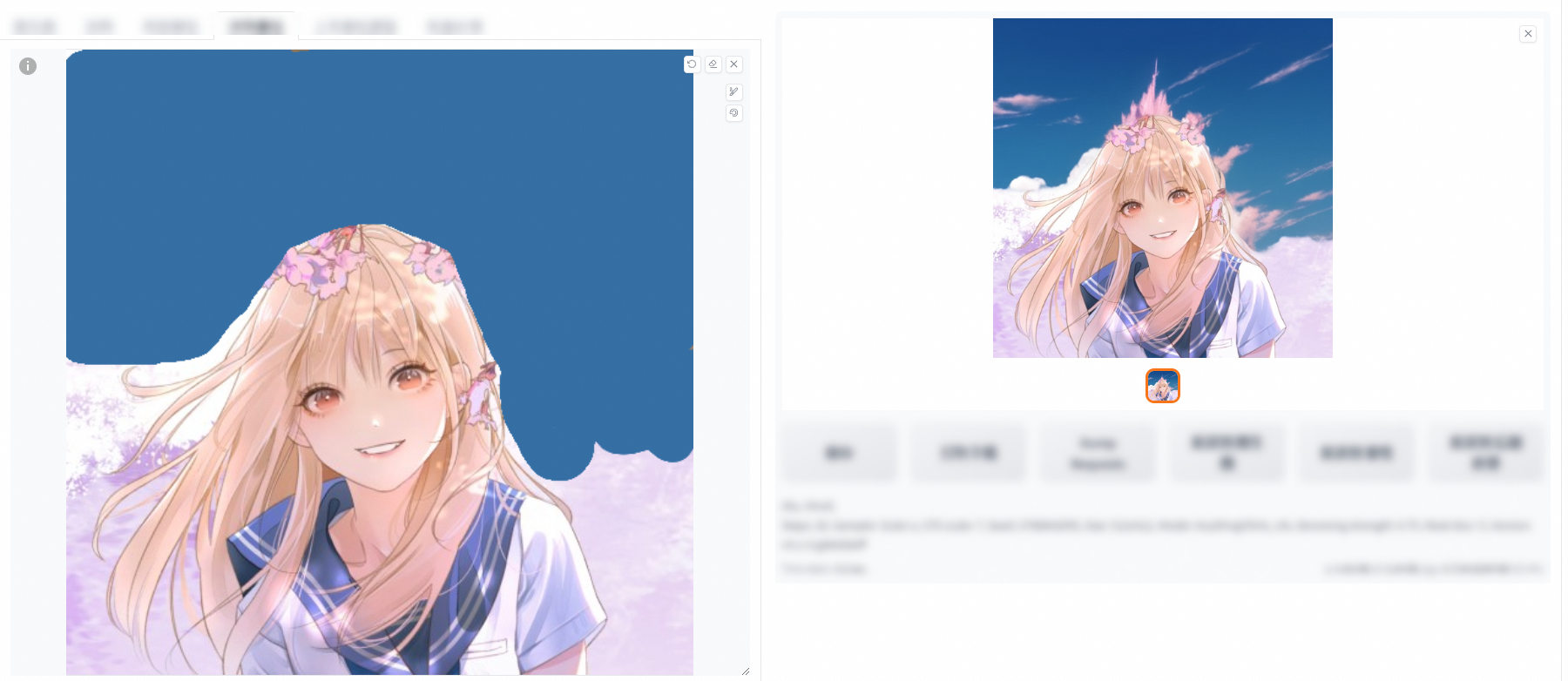
塗鴉重繪(單擊查看詳情)
在局部繪製的基礎上增加了調色盤,讓繪製過程參考蒙版顏色。
上傳重繪蒙版(單擊查看詳情)
批量處理(Batch)(單擊查看詳情)
具體參數說明如下。
圖生圖/塗鴉參數說明(單擊查看詳情)
CLIP反向推導提示詞(Interrogate CLIP)和DeepBooru反向推導提示詞。
根據上傳的圖片反向推導提示詞。
CLIP是自然語言的方式描述,像人類說話一樣。
DeepBooru是以標籤的方式,例如,"beautiful woman, river, afternoon..."。
相比CLIP來說,DeepBooru的表述會更詳細。
縮放模式(Resize mode):根據不同的縮放模式會得到不同的轉換效果。
展開(just resize):簡單的縮放映像大小,轉換後的映像可能會出現展開或壓縮的情況,可能導致部分細節丟失或變形。

裁剪(crop and resize):對原圖進行裁剪後再進行縮放,可以減少映像失真的現象,同時能夠保留更多的細節資訊。但由於裁剪操作會刪減部分映像內容,因此在合成後的映像中可能會出現一些細節丟失的情況。


填充(resize and fill):先縮放再填充映像,填充方式多種多樣,可以使用顏色或模式填充。這種方式能保留整個映像的比例和細節,但填充內容可能會影響視覺效果。

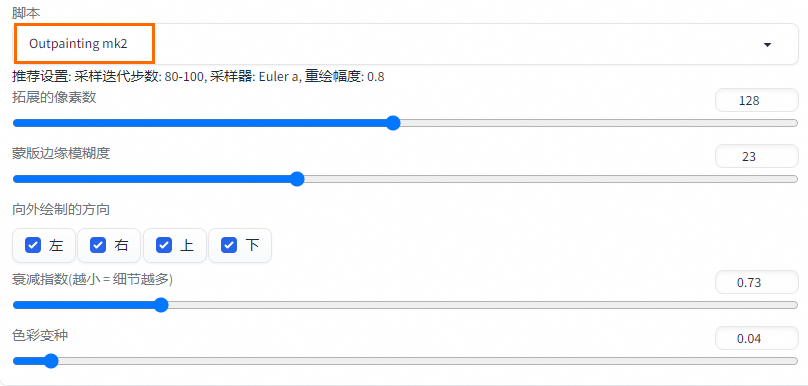
可以使用擴充繪畫【outpainting mk2】的指令碼。(適當調整重繪幅度)

直接縮放(放大潛變數):這種模式只在前向傳播時進行大小變換,因為縮小輸入有優勢,所以速度更快、穩定性更好,但不能準確地恢複原圖的細節。

重繪幅度(Denoising):重繪幅度控製圖像降噪程度。重繪幅度較高時,映像輸出平滑但細節減少,重繪幅度較低時,保留更多原圖細節。需適當調整以獲得理想效果。
下面是根據原圖調整重繪幅度的結果。

局部重繪參數說明(單擊查看詳情)
蒙版邊緣模糊度
Mask blur是一種影像處理技術,用於模糊化缺失地區周圍的像素,以減少邊緣效應,使影像處理更加自然。值越大,邊緣越透明。
以下樣本是蒙版模糊值0、20、40、60的對比圖




蒙版模式(Mask Mode)

蒙版地區內容處理
填充:用於填充映像中需要修複的部分,以達到映像修複的目的,常用於刪除映像中的不必要內容。(原圖此處有一些樹榦)
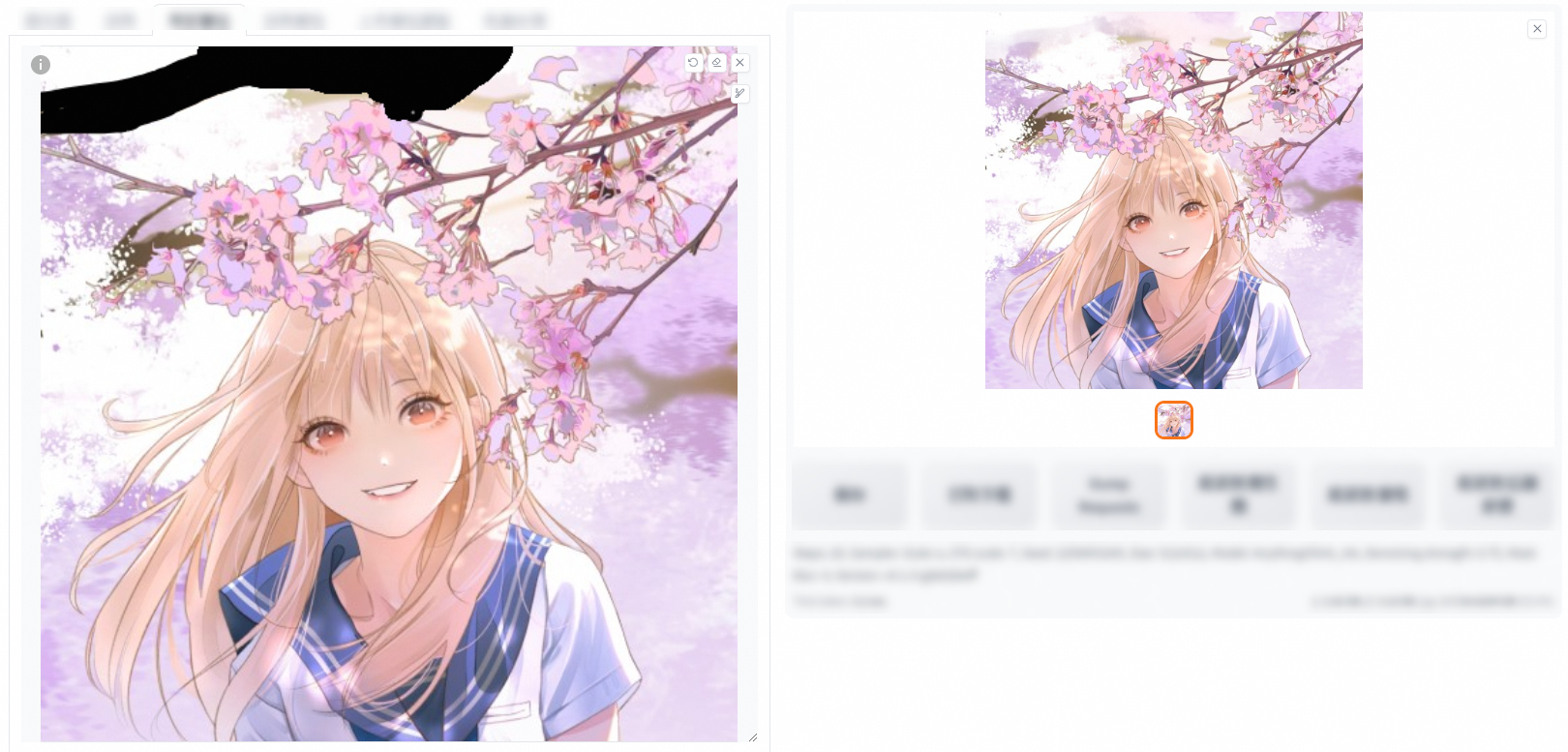
原圖:用於使用原映像的內容來填充需要修複的部分,常用於修複映像中的缺陷,如劃痕、裂縫、汙漬等。(將樹榦換成了花朵)
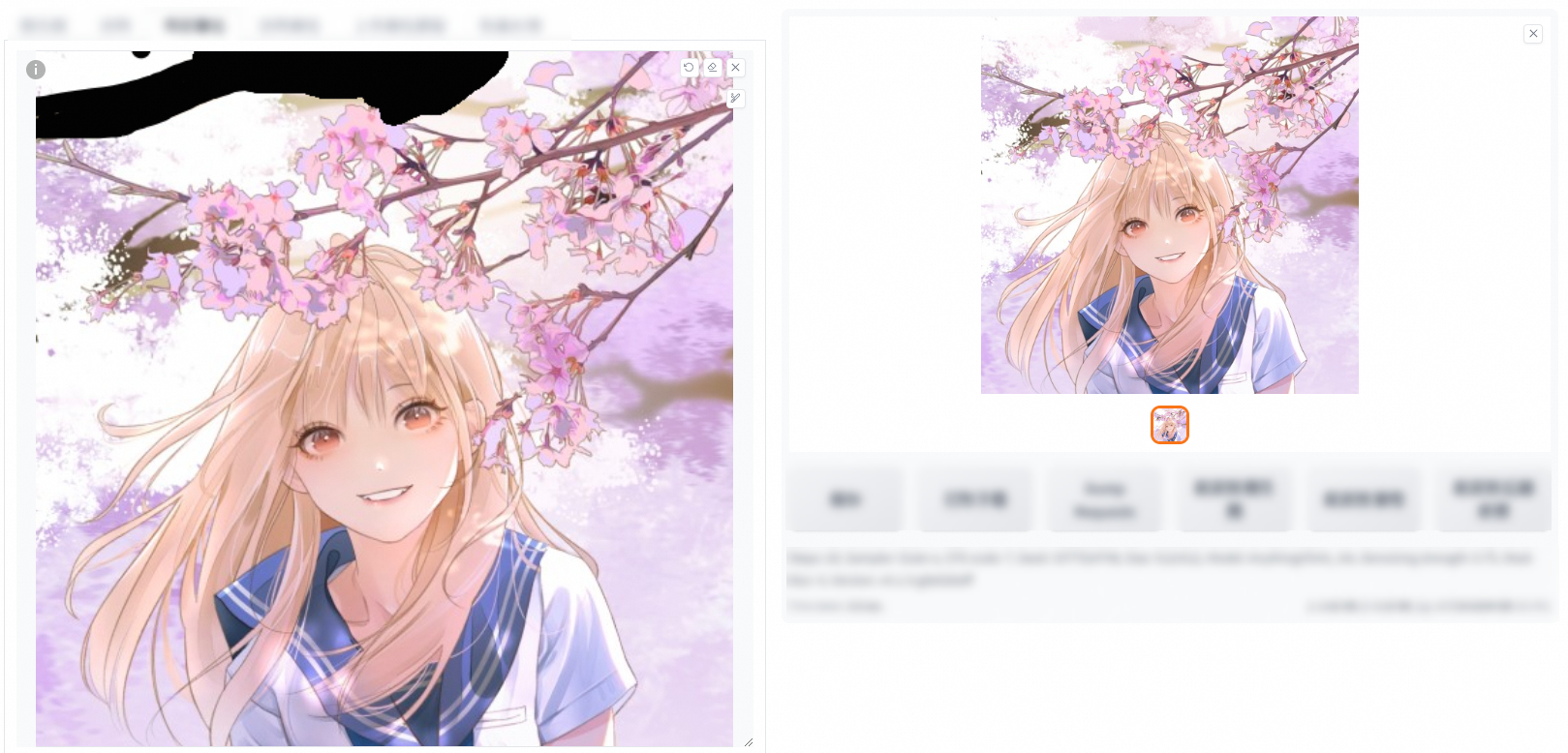
潛空間雜訊:用於在需要填充的部分中添加隨機雜訊,以創造出一種美術效果。它通常用於在映像的特定地區進行藝術處理,以增強映像的審美效果。
重繪幅度低:
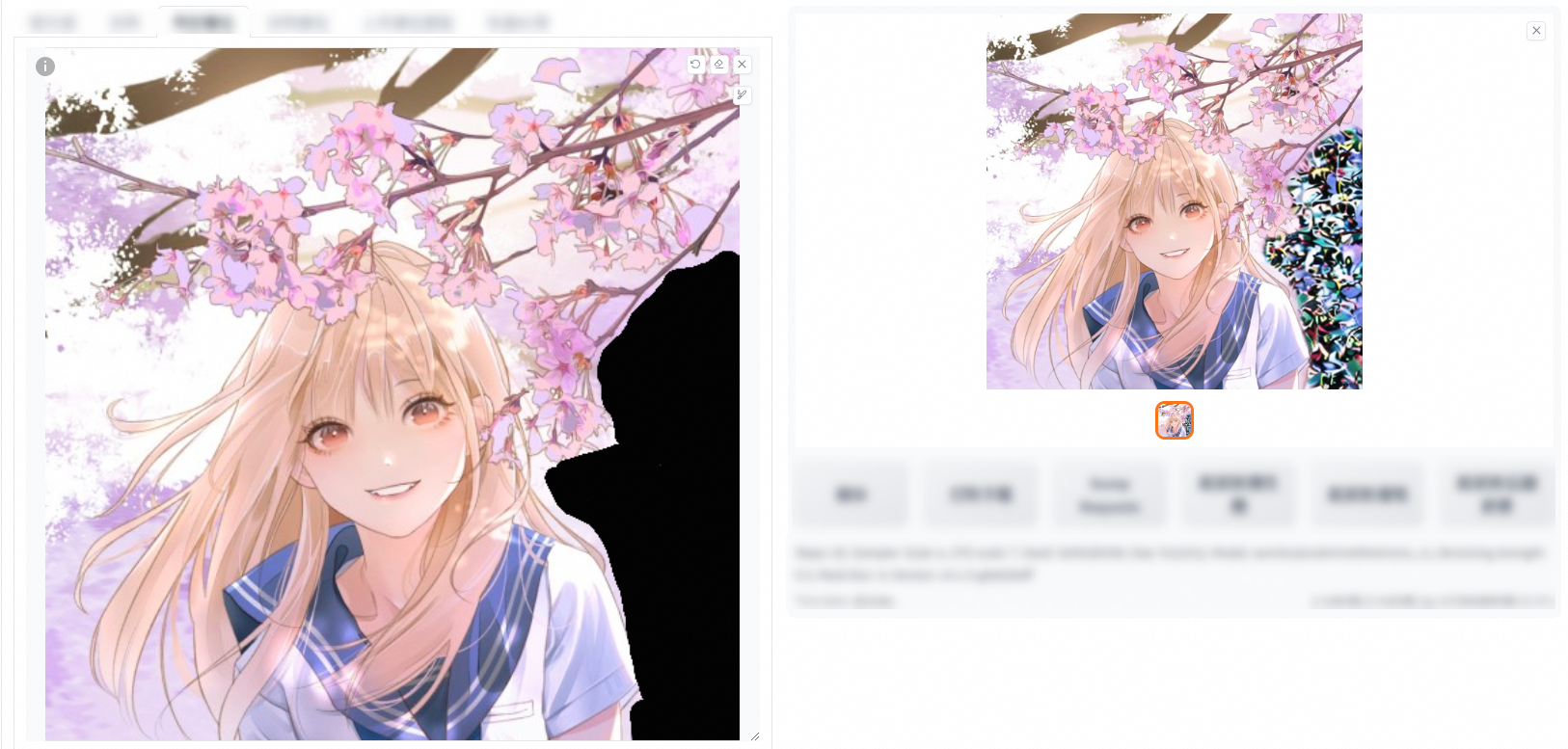
重繪幅度高:
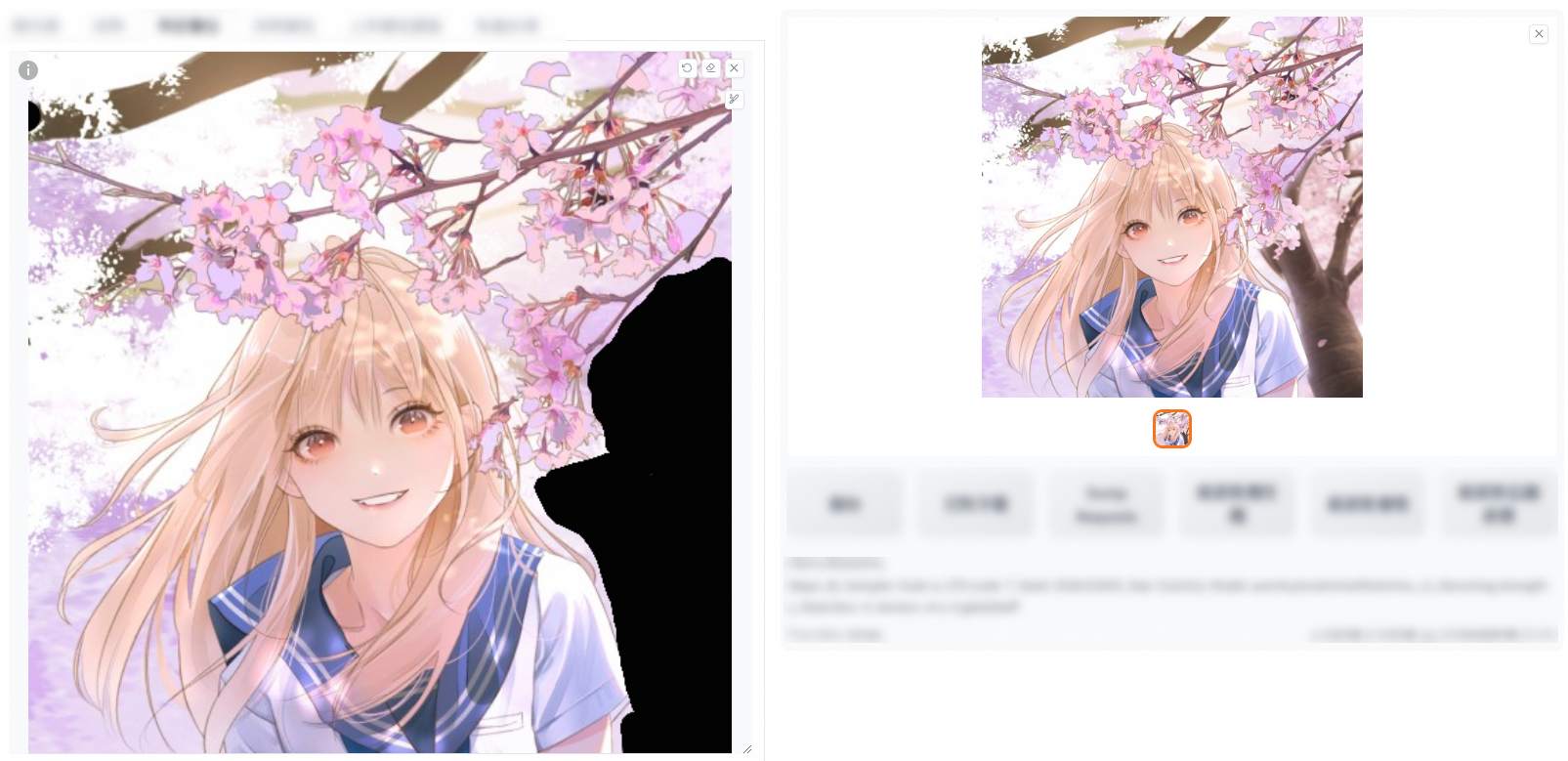
空白潛空間:用於添加空白像素以保持映像的原始外觀,通常用於在映像的特定地區留白或添加邊框,以保持映像的整體美感。
重繪幅度低:
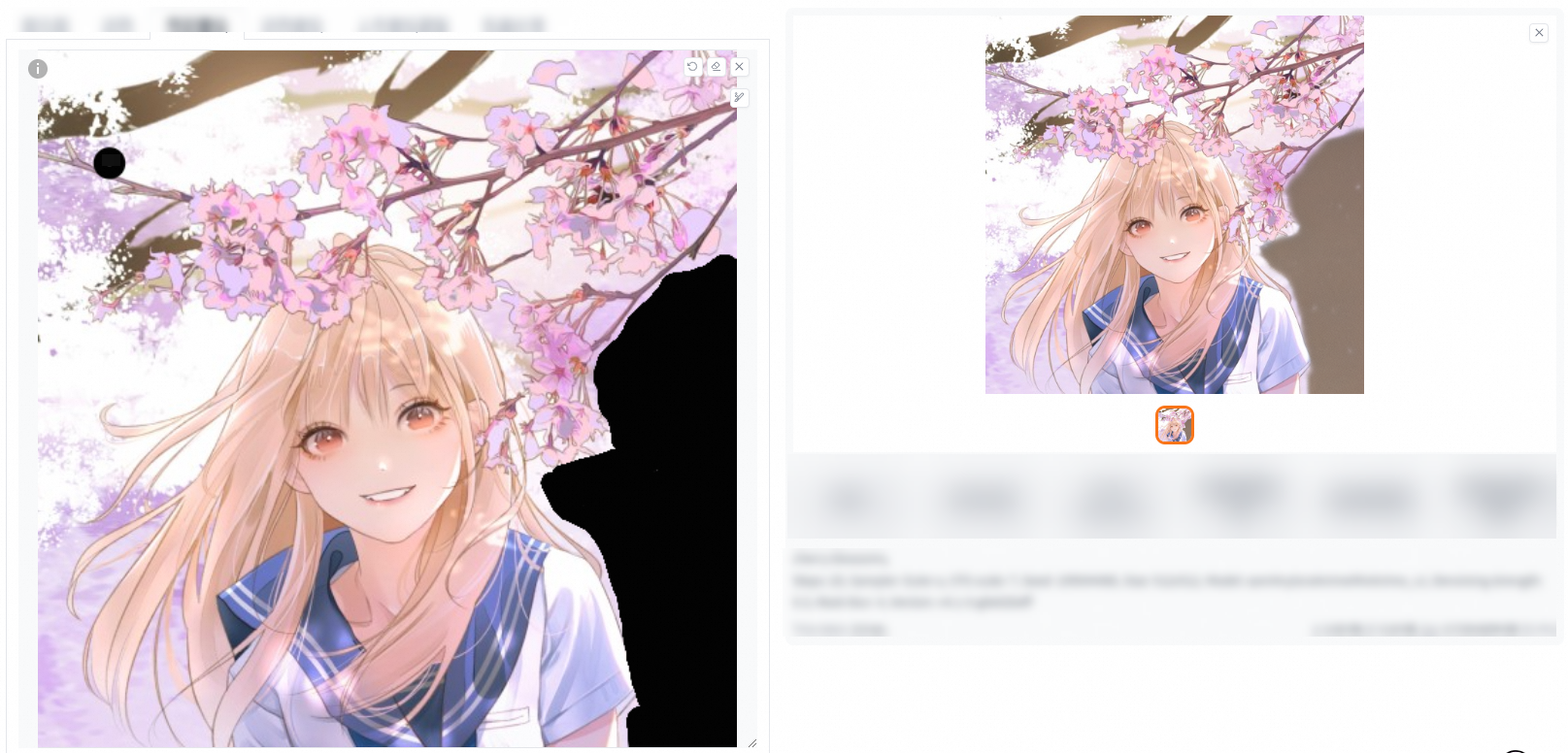
重繪幅度高:
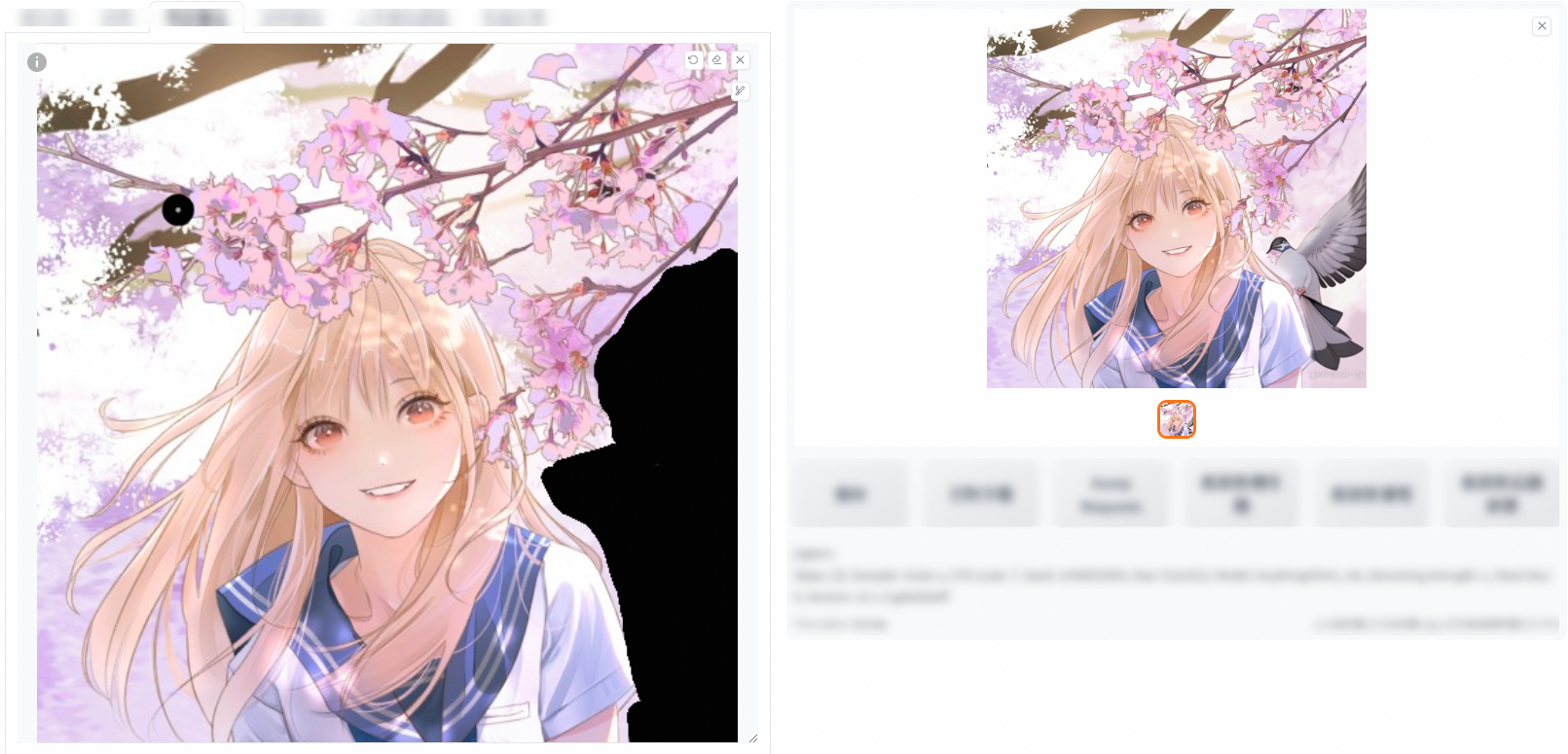
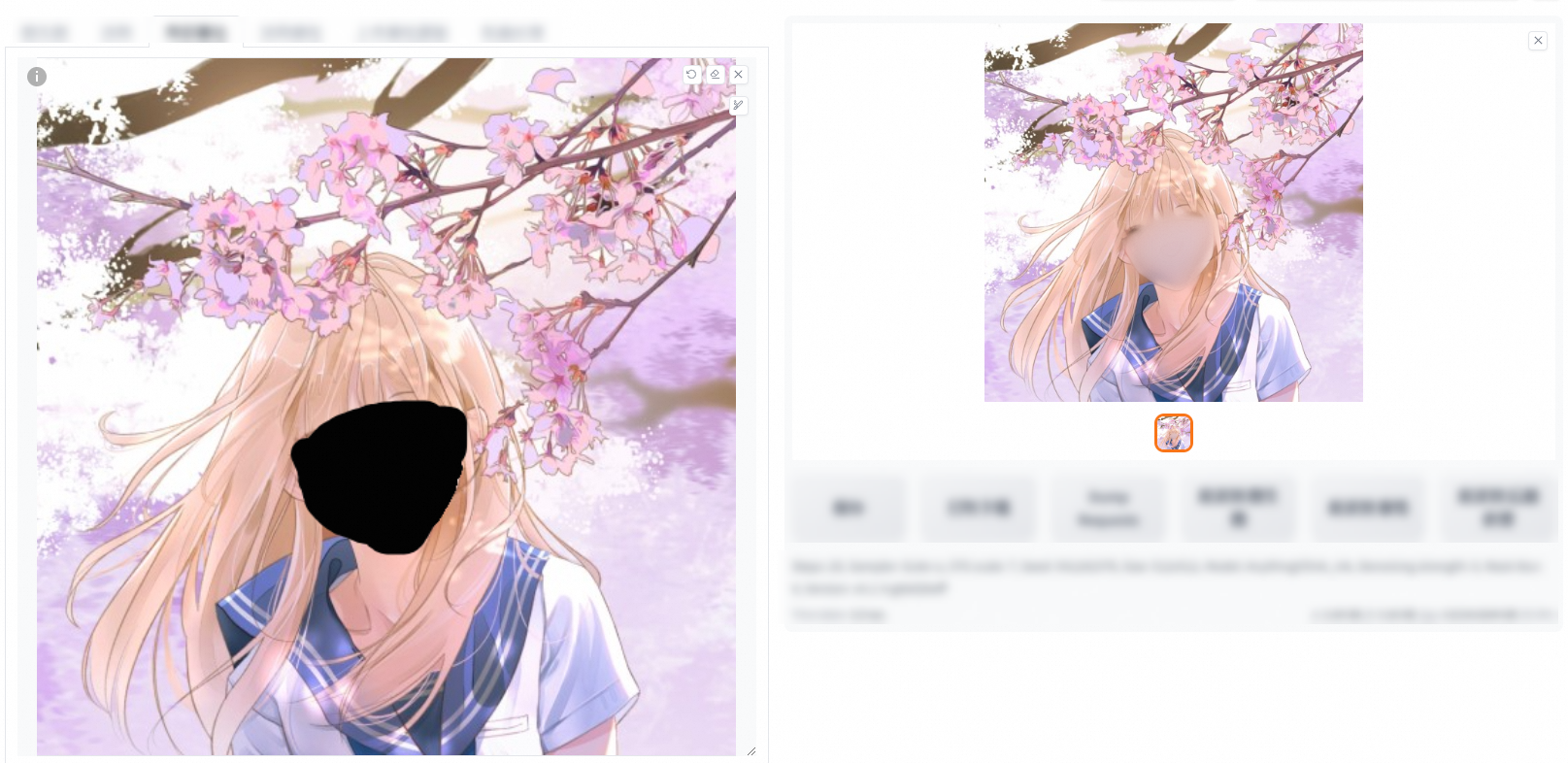
全圖(重繪幅度0、0.6在填充和原圖下的對比)
填充
重繪幅度0
重繪幅度0.6
原圖
重繪幅度0
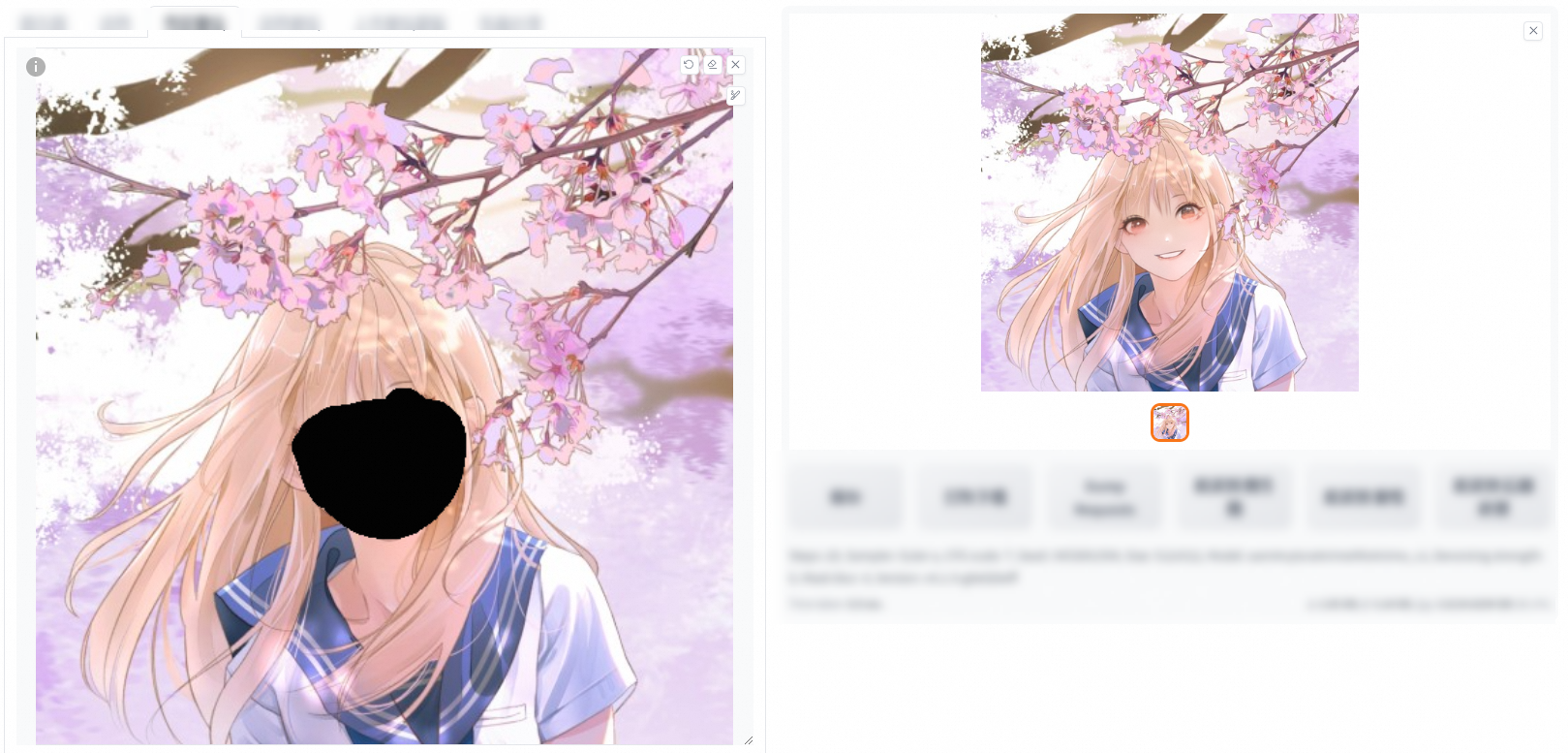
重繪幅度0.6
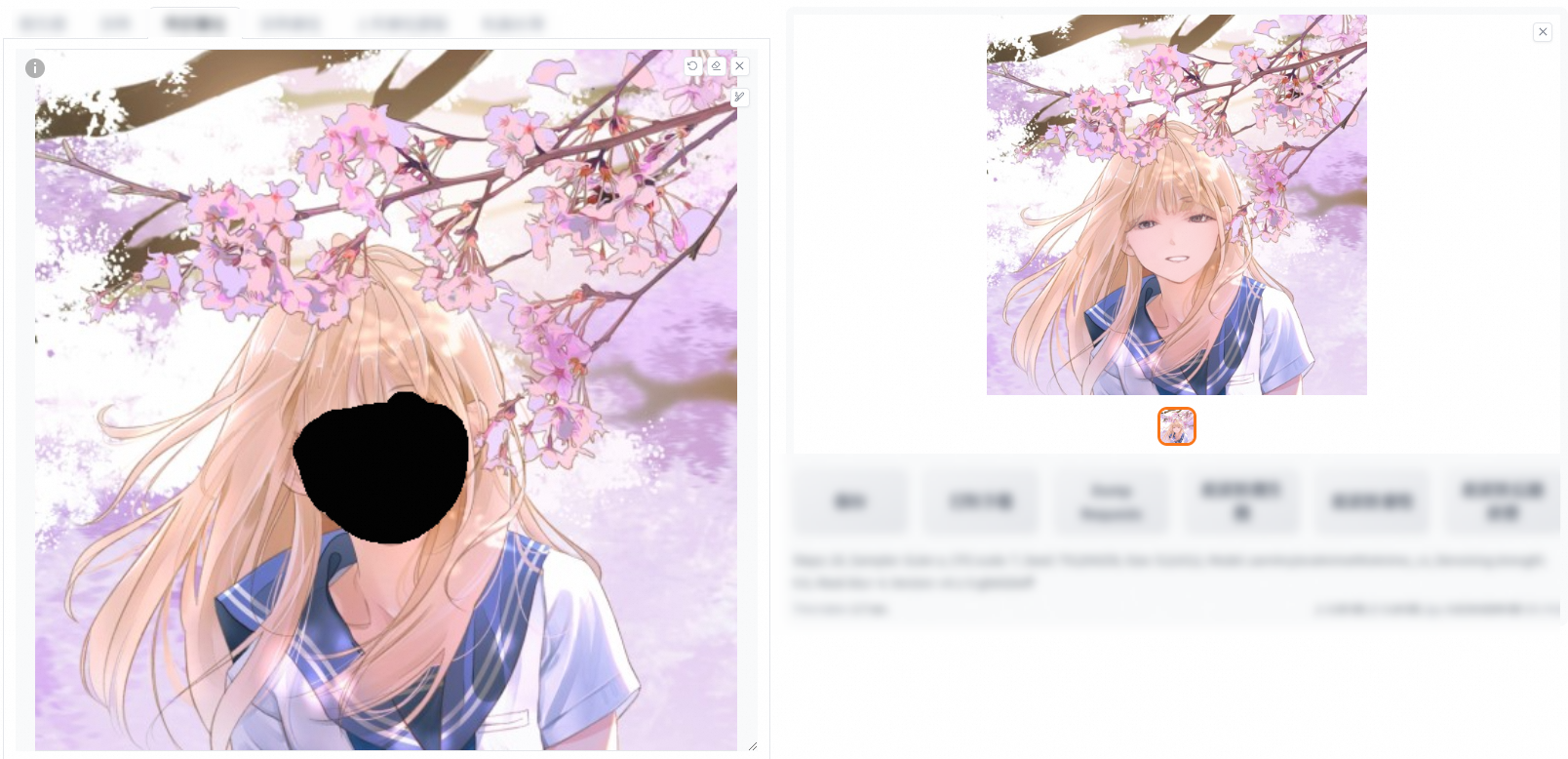
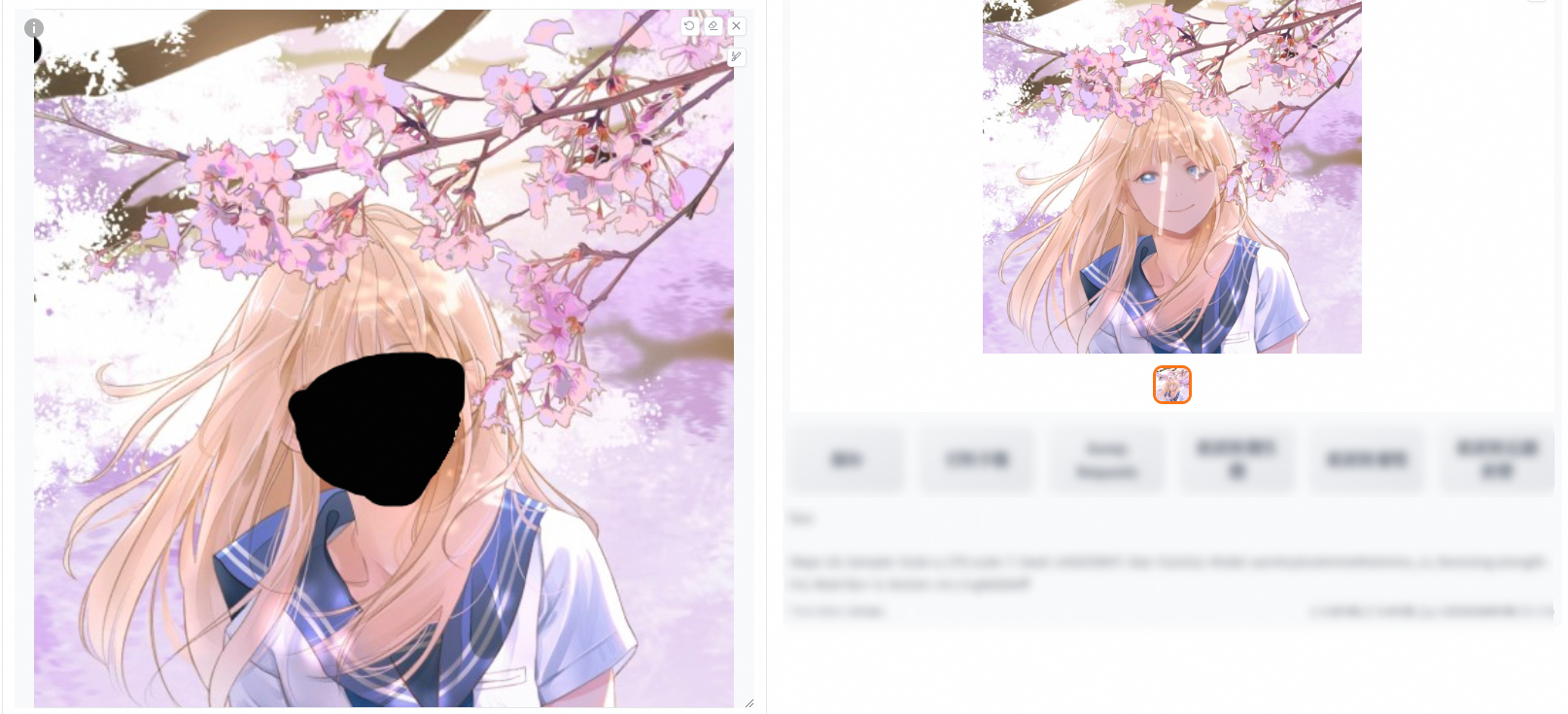
僅蒙版(重繪幅度0、0.6在填充和原圖下的對比)
填充
重繪0
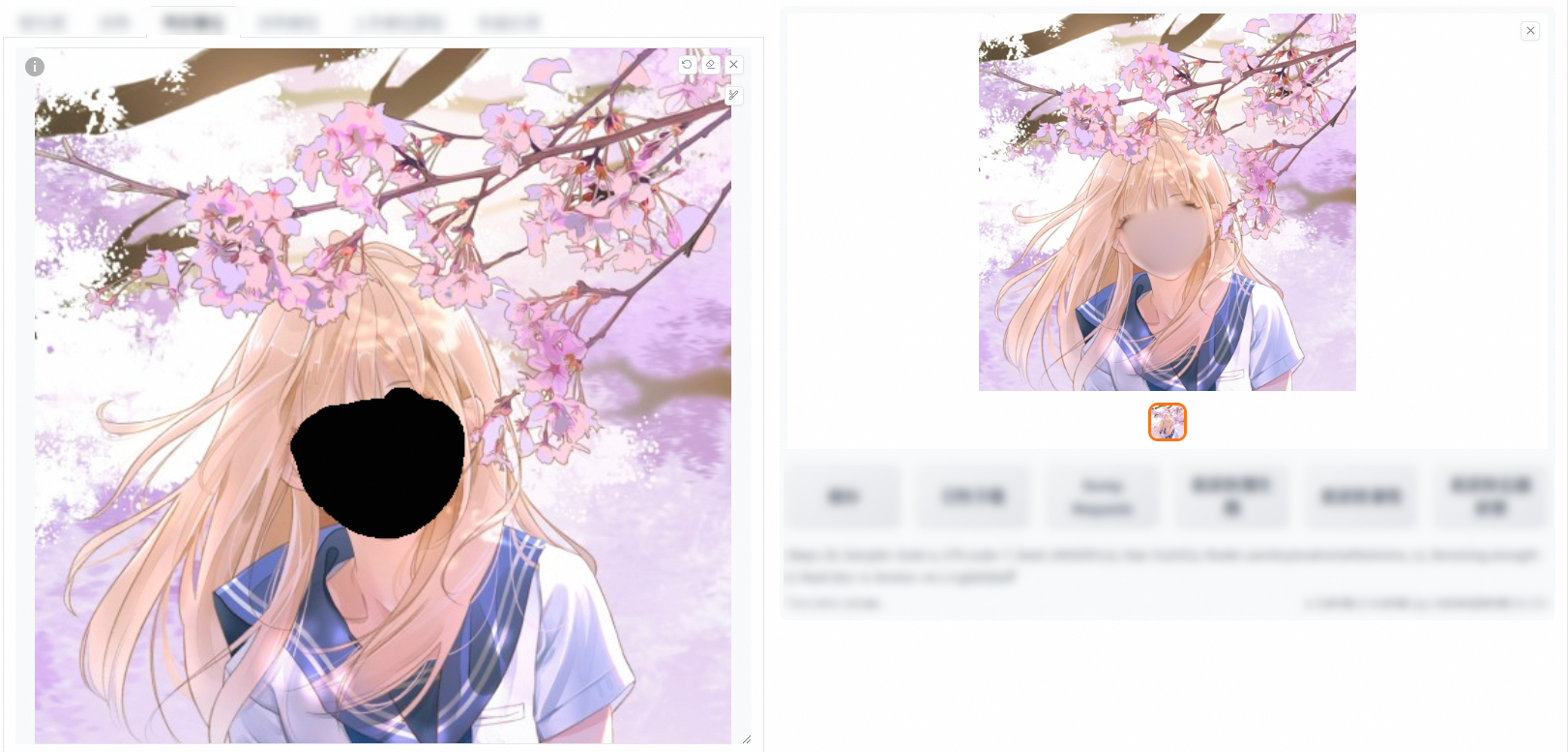
重繪0.6
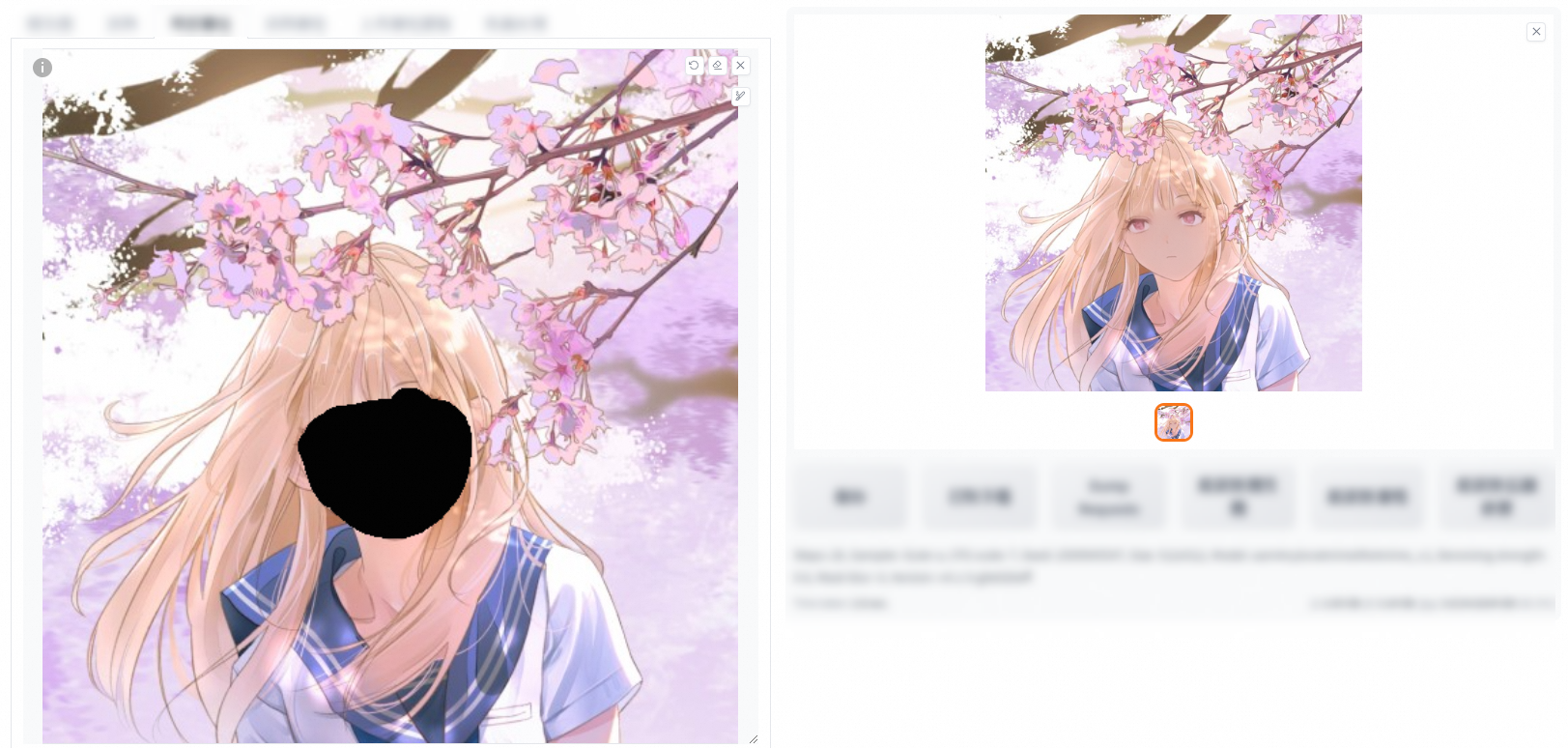
原圖
重繪0
重繪0.6
僅蒙版地區下邊緣預留像素:選擇僅蒙版時才涉及調整的參數。全圖不受影響。在人臉修複時,原圖比較穩定,潛變數雜訊比較有美術效果。
塗鴉重繪參數說明(單擊查看詳情)
蒙版透明度

以下樣本是蒙版透明度0、30、60、90的對比圖。範圍0~100,值越大,蒙版對保留的輪廓更明顯,也會影響重繪強度。




圖片資訊
上傳由Stable Difussion產生的圖片,可以查看到產生圖片的prompt和參數。
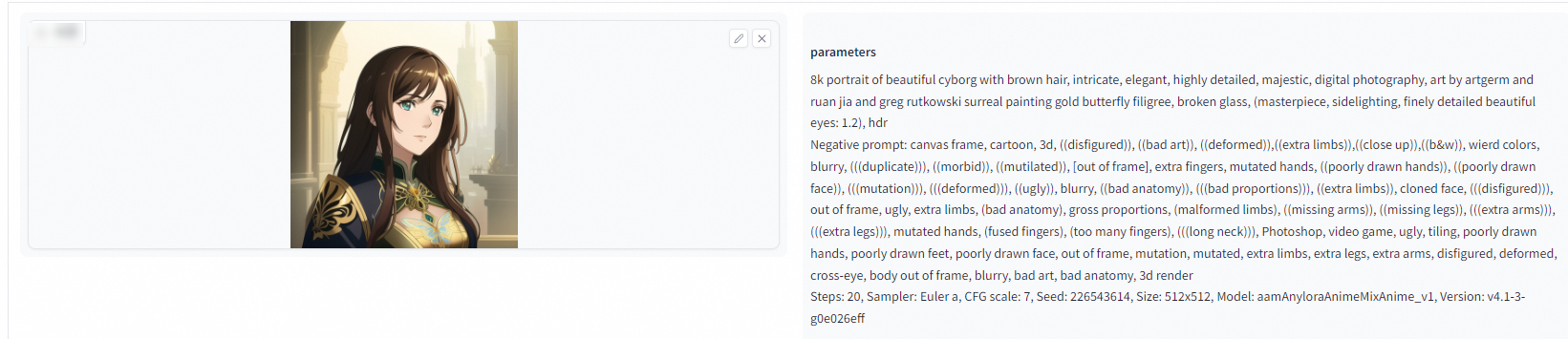
經測試,將原圖截圖或使用其他APP轉寄後儲存的圖片,無法識別圖片資訊。

ControlNet外掛程式
本產品不同版本Stable Diffusion WebUI及ComfyUI,上架了TheMisto.ai開發的MistoLine-SDXL-ControlNet。
參數介紹
參數 | 說明 |
啟用 | 勾選後啟用ControlNet。 |
低顯存最佳化 | 4 GB顯存以下可勾選。 |
前置處理器 | 不同選項具有不同的預先處理效果,每一個前置處理器有對應的模型,二者搭配使用。 |
模型 | 與前置處理器中的模型搭配使用。需要手動下載並上傳至對應OSS目錄中。 |
控制權重 | 表示產生圖片時,受ControlNet產生圖片影響的權重佔比。在圖生圖的過程中,低重繪強度配高權重,可以鎖定圖片的細節,更改濾鏡和畫風;高重繪強度配低權重,可以修改圖片的細節。 |
引導介入時機 | 數值為0~1,意為百分比,表示ControlNet在第幾步介入繪畫。0表示從第一步就開始介入,1表示從最後一步開始介入。數值越大,ControlNet對產生圖片的影響就越小。 例如:設定採樣迭代步數為20,引導介入時機為0.3,表示從第6(20*0.3)步開始介入。 |
引導終止時機 | 數值為0~1,意為百分比,表示ControlNet在第幾步退出繪畫。 |
控制類型 |
|
ControlNet生圖效果展示
推薦模型:Checkpoint、LoRA
Prompt設定
正向Prompt:JinxLol,mature female,1girl, solo,looking at viewer, navel, gloves, fingerless gloves, character name, midriff, bare shoulders, looking at viewer, gun, crop top, belt,outdoors
負向Prompt:(low quality, worst quality:1.3), (lowres), blurry,text,watermark,signature,artist name,letterboxed, female pubic hair,realism
參數設定
採樣方法(Sampler)選擇DPM++2M Karras,其他參數使用預設值或根據實際需求進行微調。
ControlNet參數設定
上傳一張不同視角的線稿,控制類型選擇Canny(硬邊緣),其他參數使用預設值或根據實際需求進行微調。
效果圖展示


推薦模型::Checkpoint、LoRA
Prompt設定
正向Prompt:XSWB,architecture,autumn,bench, blue_sky, building,cloudy_sky, day, fence,forest, garden, grass, house, mountain, nature, no_humans, outdoors, palm_tree, path, pavement, plant, road, scenery, sky,tree, water,wooden_fence,triangular top,masterpiece,ultra-fine painting,sharp focus,HDR,UHD,8K,4K <lora:xsarchitectural3aerial_xsarchitectural3:0.9>
負向Prompt:soft line,Distorted, fuzzy
參數設定
採樣方法(Sampler)選擇Euler a,其他參數使用預設值或根據實際需求進行微調。
ControlNet參數
上傳一張建築物線稿,控制類型選擇MLSD(直線),其他參數使用預設值或根據實際需求進行微調。
效果圖展示

推薦模型:
基本模型v1-5-pruned-emaonly.safetensors、LoRA
Prompt設定
正向Prompt:Interior advanced Design<lora:xsarchitectural9advanced_xsarchitectural:1>
參數設定
採樣方法(Sampler)選擇Euler a,其他參數使用預設值或根據實際需求進行微調。
ControlNet參數
上傳一張室內毛坯房圖片,控制類型選擇MLSD(直線),單批數量為4,一次出4張圖,其他參數使用預設值或根據實際需求進行微調。
效果圖展示

推薦模型:Checkpoint、LoRA
Prompt設定
正向Prompt:best quality, masterpiece, (realistic:1.2), 1 girl, brown hair, brown eyes,Front, detailed face, beautiful eyes <lora:hanfu_v29 Lora:1>
負向Prompt:(low quality, worst quality:1.4),nsfw
參數設定
採樣方法(Sampler)選擇Euler a,其他參數使用預設值或根據實際需求進行微調。
ControlNet參數
上傳一張人臉映像,控制類型選擇Canny(硬邊緣),其他參數使用預設值或根據實際需求進行微調。
效果圖展示:


推薦模型:C站
Prompt設定
正向Prompt:close up of a european woman, ginger hair, winter forest, natural skin texture, 24mm, 4k textures, soft cinematic light, RAW photo, photorealism, photorealistic, intricate, elegant, highly detailed, sharp focus, ((((cinematic look)))), soothing tones, insane details, intricate details, hyperdetailed, low contrast, soft cinematic light, dim colors, exposure blend, hdr, faded
負向Prompt:(deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation,nsfw
參數設定
採樣方法(Sampler)選擇Euler a,其他參數使用預設值或根據實際需求進行微調。
ControlNet參數
上傳一張人物圖,控制類型選擇OpenPose(姿態),其他參數使用預設值或根據實際需求進行微調。
效果圖展示:


Prompt設定
可增加以下標籤:black hair
參數設定
通過圖生圖局部重繪功能更改圖片發色,手動繪製蒙版,重繪幅度設定為0.6,其他參數保持預設。
效果圖展示:


Prompt設定
可增加以下標籤,並通過括弧來增加權重:green trees,((beach)),((sea)),((blue sky)),black hair
參數設定
手繪蒙版,根據蒙版範圍修改蒙版模式、重繪幅度等參數。
效果圖展示

