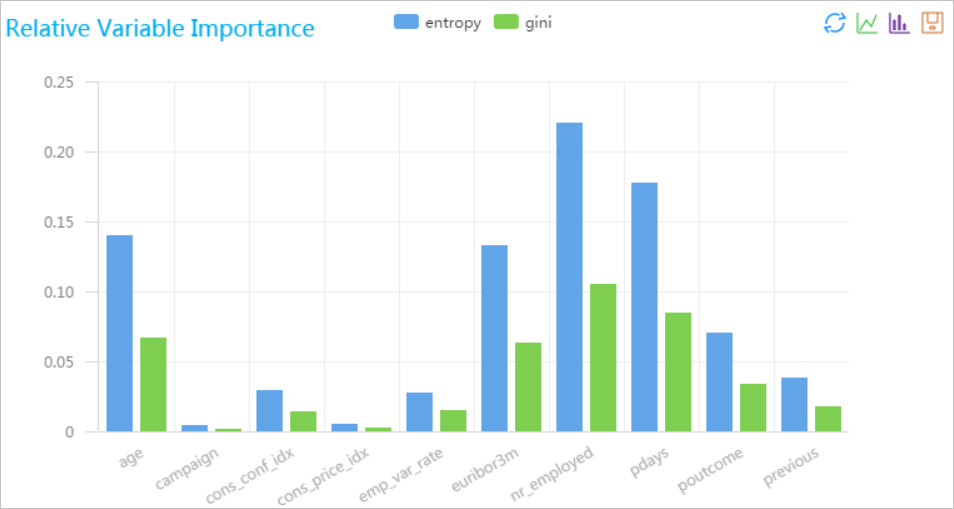
隨機森林特徵重要性評估是一種通過分析隨機森林模型中各個特徵對預測結果貢獻程度的方法。通常通過計算每個特徵在所有決策樹中的平均不純度減少或基於置換重要性的方法來確定特徵的重要性,從而協助識別對模型效能影響最大的特徵。
組件配置
方式一:可視化方式
在Designer工作流程頁面添加隨機森林特徵重要性評估組件,並在介面右側配置相關參數:
參數類型 | 參數 | 描述 |
欄位設定 | 選擇特徵列 | 輸入表中,用於訓練的特徵列。預設選中除Label外的所有列,為可選項。 |
選擇目標列 | 該參數為必選項。 | |
參數設定 | 並行計算核心數 | 並行計算的核心數。 |
每個核記憶體大小 | 每個核的記憶體大小,單位為MB。 |
方式二:PAI命令方式
使用PAI命令配置隨機森林特徵重要性評估組件參數。您可以使用SQL指令碼組件進行PAI命令調用,詳情請參見情境4:在SQL指令碼組件中執行PAI命令。
pai -name feature_importance -project algo_public
-DinputTableName=pai_dense_10_10
-DmodelName=xlab_m_random_forests_1_20318_v0
-DoutputTableName=erkang_test_dev.pai_temp_2252_20319_1
-DlabelColName=y
-DfeatureColNames="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
-Dlifecycle=28 ;參數名稱 | 是否必選 | 預設值 | 描述 |
inputTableName | 是 | 無 | 輸入表的名稱。 |
outputTableName | 是 | 無 | 輸出表的名稱。 |
labelColName | 是 | 無 | 輸入表的標籤列名。 |
modelName | 是 | 無 | 輸入的模型名稱。 |
featureColNames | 否 | 除Label外的所有列 | 輸入表選擇的特徵列。 |
inputTablePartitions | 否 | 選擇全表 | 輸入表選擇的分區名稱。 |
lifecycle | 否 | 不設定 | 輸出表的生命週期。 |
coreNum | 否 | 自動計算 | 核心數。 |
memSizePerCore | 否 | 自動計算 | 記憶體數,單位為MB。 |
使用樣本
使用SQL語句,產生訓練資料。
本文以從bank_data表中選擇指定的列和前10條記錄建立pai_dense_10_10表為例說明,您可根據實際情況建表。
drop table if exists pai_dense_10_10; create table pai_dense_10_10 as select age,campaign,pdays, previous, poutcome, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y from bank_data limit 10;構建如下實驗,詳情請參見自訂工作流程。
y為隨機森林的標籤列,其它列為特徵列。強制轉換列選擇age和campaign,表示將這兩列作為枚舉特徵處理,其它使用預設參數。
運行實驗,查看預測結果。
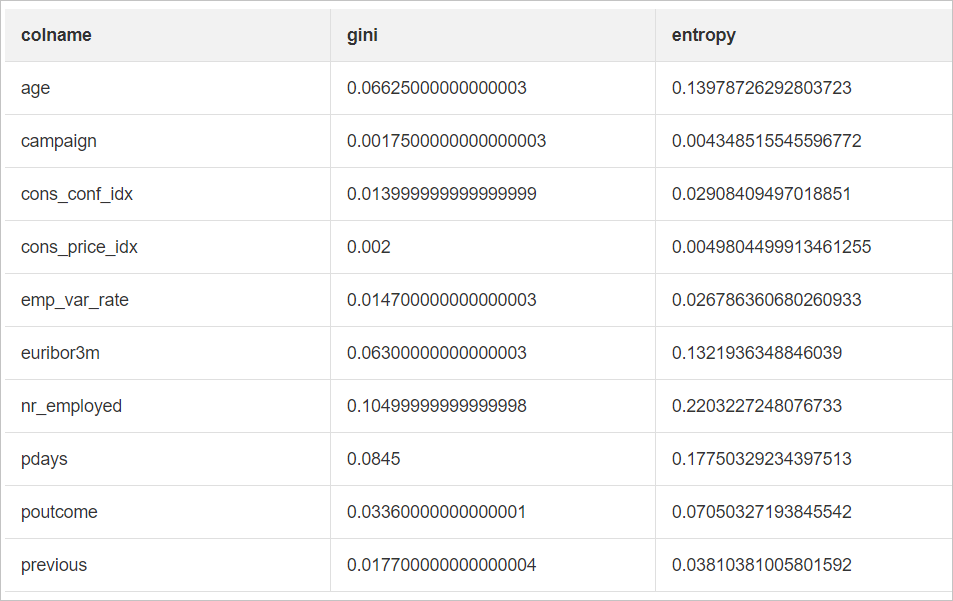
運行完成後,按右鍵隨機森林特徵重要性評估組件,選擇可視化分析,查看結果。