樸素貝葉斯是一種基於獨立假設的貝葉斯定理的機率分類演算法。使用Designer(原Studio)的樸素貝葉斯組件,您能有效處理多樣的分類問題。本文為您介紹樸素貝葉斯組件的配置方法。
使用限制
支援的計算引擎為MaxCompute。
組件配置
您可以使用以下任意一種方式,配置樸素貝葉斯組件參數。
方式一:可視化方式
在Designer工作流程頁面配置組件參數。
|
頁簽 |
參數 |
描述 |
|
欄位設定 |
特徵列 |
預設為除標籤列外的所有列,支援DOUBLE、STRING及BIGINT資料類型。 |
|
排除列 |
不參與訓練的列,不能與選擇特徵列同時使用。 |
|
|
強制轉換列 |
解析規則如下:
說明
如果需要將BIGINT類型的列解析為CATEGORICAL,則必須使用forceCategorical參數指定類型。 |
|
|
標籤列 |
輸入表的標籤列,只能選擇非特徵列。支援STRING、DOUBLE及BIGINT類型。 |
|
|
輸入資料是否為稀疏格式 |
使用KV格式表示稀疏資料。 |
|
|
當輸入為稀疏時,K:V間的分隔字元 |
預設為半形逗號(,)。 |
|
|
當輸入為稀疏時,key和value的分隔字元 |
預設為半形冒號(:)。 |
|
|
是否產生PMML |
選中該複選框,即可產生PMML模型。如果未設定工作流程資料存放區路徑,您需要單擊點擊前往,設定工作流程資料存放區路徑。 |
|
|
執行調優 |
計算核心數 |
預設為系統自動分配。 |
|
每個核心記憶體數 |
預設為系統自動分配。 |
方式二:PAI命令方式
使用PAI命令方式,配置該組件參數。您可以使用SQL指令碼組件進行PAI命令調用,詳情請參見SQL指令碼。
PAI -name NaiveBayes -project algo_public
-DinputTablePartitions="pt=20150501"
-DmodelName="xlab_m_NaiveBayes_23772"
-DlabelColName="poutcome"
-DfeatureColNames="age,previous,cons_conf_idx,euribor3m"
-DinputTableName="bank_data_partition";|
參數 |
是否必選 |
描述 |
預設值 |
|
inputTableName |
是 |
輸入表的表名。 |
無 |
|
inputTablePartitions |
否 |
輸入表中,參與訓練的分區。 |
所有分區 |
|
modelName |
是 |
輸出的模型名稱。 |
無 |
|
labelColName |
是 |
輸入表中,標籤列的名稱。 |
無 |
|
featureColNames |
否 |
輸入表中,用於訓練的特徵列名。 |
除標籤列外的所有列 |
|
excludedColNames |
否 |
用於反選特徵列,該參數不能與featureColNames同時使用。 |
空 |
|
forceCategorical |
否 |
解析規則如下:
說明
如果需要將BIGINT類型的列解析為CATEGORICAL,則必須使用forceCategorical參數指定類型。 |
INT為連續類型 |
|
coreNum |
否 |
計算的核心數。 |
系統自動分配 |
|
memSizePerCore |
否 |
每個核心的記憶體,取值範圍為1 MB~65536 MB。 |
系統自動分配 |
樣本
-
準備訓練資料和測試資料。
-
使用MaxCompute用戶端建立表train_data和test_data,分別用來存放訓練資料和測試資料。其中欄欄位和資料類型為
id bigint、y bigint、f0 double、f1 double、f2 double、f3 double、f4 double、f5 double、f6 double、f7 double。關於MaxCompute用戶端的安裝及配置請參見使用本地用戶端(odpscmd)串連,如何建立表,請參見建立表。 -
將以下訓練資料和測試資料分別匯入到表train_data和test_data中。如何匯入資料,請參見匯入資料。
-
訓練資料
id
y
f0
f1
f2
f3
f4
f5
f6
f7
1
-1
-0.294118
0.487437
0.180328
-0.292929
-1
0.00149028
-0.53117
-0.0333333
2
+1
-0.882353
-0.145729
0.0819672
-0.414141
-1
-0.207153
-0.766866
-0.666667
3
-1
-0.0588235
0.839196
0.0491803
-1
-1
-0.305514
-0.492741
-0.633333
4
+1
-0.882353
-0.105528
0.0819672
-0.535354
-0.777778
-0.162444
-0.923997
-1
5
-1
-1
0.376884
-0.344262
-0.292929
-0.602837
0.28465
0.887276
-0.6
6
+1
-0.411765
0.165829
0.213115
-1
-1
-0.23696
-0.894962
-0.7
7
-1
-0.647059
-0.21608
-0.180328
-0.353535
-0.791962
-0.0760059
-0.854825
-0.833333
8
+1
0.176471
0.155779
-1
-1
-1
0.052161
-0.952178
-0.733333
9
-1
-0.764706
0.979899
0.147541
-0.0909091
0.283688
-0.0909091
-0.931682
0.0666667
10
-1
-0.0588235
0.256281
0.57377
-1
-1
-1
-0.868488
0.1
-
測試資料
id
y
f0
f1
f2
f3
f4
f5
f6
f7
1
+1
-0.882353
0.0854271
0.442623
-0.616162
-1
-0.19225
-0.725021
-0.9
2
+1
-0.294118
-0.0351759
-1
-1
-1
-0.293592
-0.904355
-0.766667
3
+1
-0.882353
0.246231
0.213115
-0.272727
-1
-0.171386
-0.981213
-0.7
4
-1
-0.176471
0.507538
0.278689
-0.414141
-0.702128
0.0491804
-0.475662
0.1
5
-1
-0.529412
0.839196
-1
-1
-1
-0.153502
-0.885568
-0.5
6
+1
-0.882353
0.246231
-0.0163934
-0.353535
-1
0.0670641
-0.627669
-1
7
-1
-0.882353
0.819095
0.278689
-0.151515
-0.307329
0.19225
0.00768574
-0.966667
8
+1
-0.882353
-0.0753769
0.0163934
-0.494949
-0.903073
-0.418778
-0.654996
-0.866667
9
+1
-1
0.527638
0.344262
-0.212121
-0.356974
0.23696
-0.836038
-0.8
10
+1
-0.882353
0.115578
0.0163934
-0.737374
-0.56974
-0.28465
-0.948762
-0.933333
-
-
-
構建如下工作流程,並運行組件,詳情請參見演算法建模。
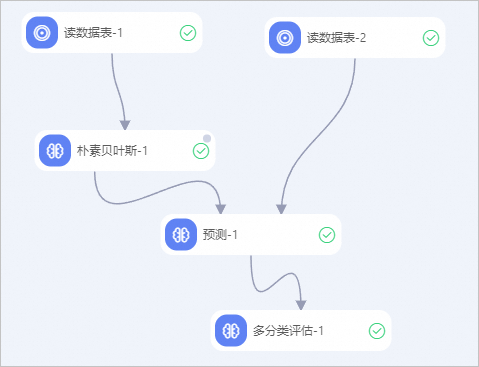
-
在Designer左側組件列表中,分別搜尋讀資料表組件(2個)、樸素貝葉斯組件、預測組件、多分類評估組件,並拖入右側畫布中。
-
通過連線的方式,將各個節點群組織構建成為一個有上下遊關係的工作流程。
-
配置組件參數。
-
在畫布中單擊讀資料表-1組件,在右側表選擇頁簽,配置表名為train_data。
-
在畫布中單擊讀資料表-2組件,在右側表選擇頁簽,配置表名為test_data。
-
在畫布中單擊樸素貝葉斯-1組件,在右側配置如下表中的參數,其餘參數使用預設值。
頁簽
參數
描述
欄位設定
特徵列
在訓練表中,選擇f0、f1、f2、f3、f4、f5、f6及f7列。
標籤列
在訓練表中,選擇y列。
-
在畫布中單擊預測-1組件,在右側欄位設定頁簽,選擇原樣輸出資料行為id和y。其餘參數使用預設值。
-
在畫布中單擊多分類評估-1組件,在右側欄位設定頁簽,選擇原分類結果列為y。其餘參數使用預設值。
-
-
參數配置完成後,單擊運行按鈕
 ,運行工作流程。
,運行工作流程。
-
-
工作流程運行成功後,按右鍵預測-1組件,在捷徑功能表,選擇,查看預測結果。運行完成後,預測結果表包含 id、y(原始標籤)、prediction_result(預測標籤,值為 1 或 -1)、prediction_score(預測信賴度,各樣本得分均接近 1)和 prediction_detail(JSON 格式的各類別機率詳情)列。10 條測試資料的預測結果顯示模型信賴度較高,預測效果良好。
相關文檔
-
運行樸素貝葉斯組件產生PMML類型的模型後,您可以將模型部署為線上服務。具體操作,請參見單模型部署線上服務。
-
關於Designer組件更詳細的內容介紹,請參見Designer概述。
-
Designer預置了多種演算法組件,你可以根據不同的使用情境選擇合適的組件進行資料處理,詳情請參見組件參考:所有組件匯總。