混合專家模型(MoE)通過“稀疏啟用”機制,在實現萬億級參數規模的同時降低計算成本,但也給傳統推理部署帶來挑戰。專家並行(EP)是一種專為MoE設計的分布式策略,它將不同專家部署在不同GPU上,通過動態路由請求,有效解決顯存瓶頸、提升並行計算效能,並顯著降低部署成本。本文介紹在PAI-EAS上,為MoE模型啟用專家並行(EP)和Prefill-Decode(PD)分離部署,以實現更高的推理吞吐和成本效益。
方案架構
阿里雲人工智慧平台PAI的模型線上服務(EAS) 提供生產級EP的部署支援,將PD分離、大規模EP、計算-通訊協同最佳化、MTP等技術融為一體,形成多維度聯合最佳化的新範式。

方案優勢:
一鍵式部署:提供內建鏡像、可選資源、運行命令等的EP部署模板,將複雜的分布式部署簡化為嚮導式操作,無需關注底層實現。
彙總服務管理:在統一視圖下對Prefill、Decode和智能路由等子服務進行獨立監控、擴縮容和生命週期管理。
部署EP服務
以部署模型DeepSeek-R1-0528-PAI-optimized(PAI最佳化版模型,能夠支援更高的吞吐和更低的時延)為例,操作步驟如下:
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
在推理服務頁簽,單擊部署服務,然後在情境化模型部署地區,單擊LLM大語言模型部署。
模型配置選擇公用模型DeepSeek-R1-0528-PAI-optimized。
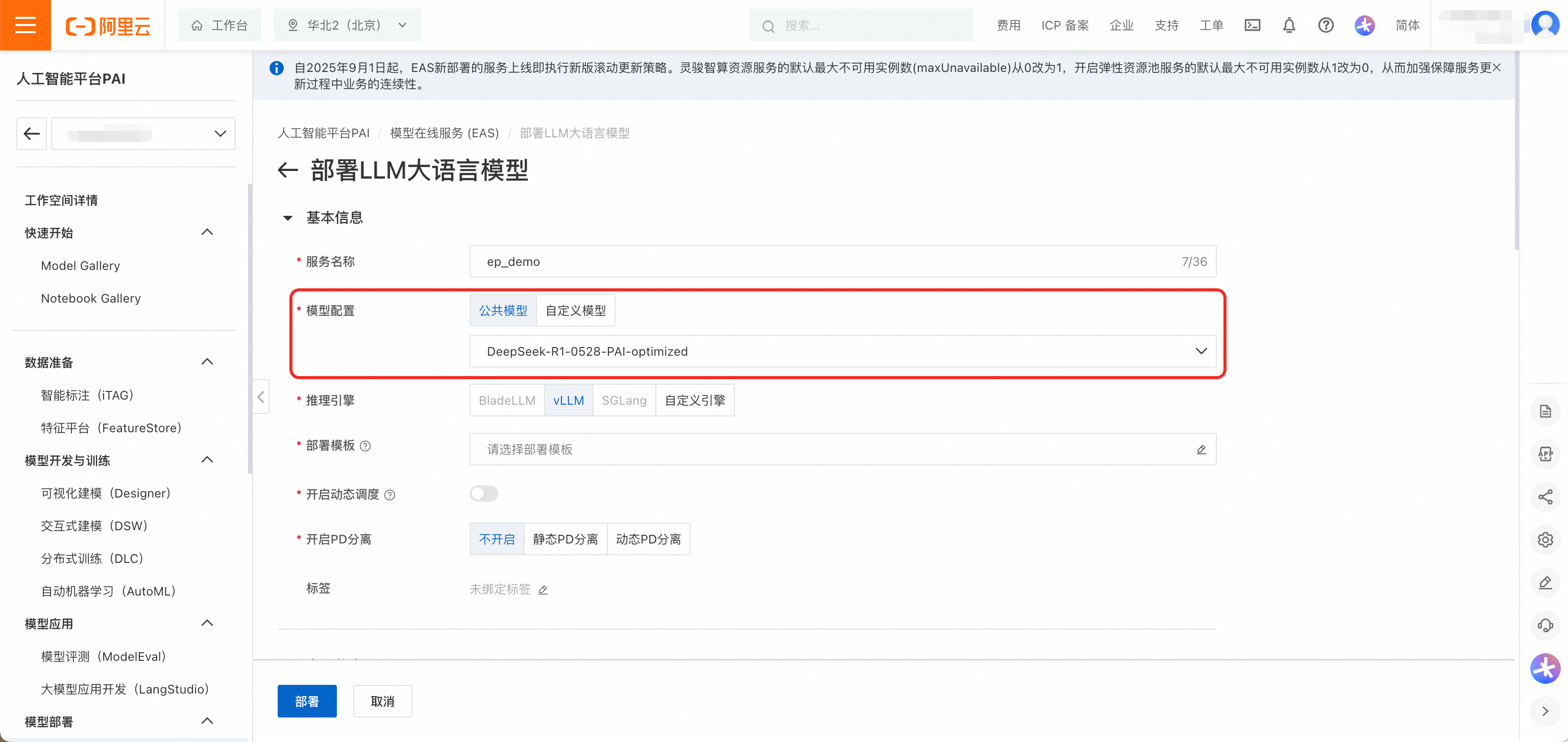
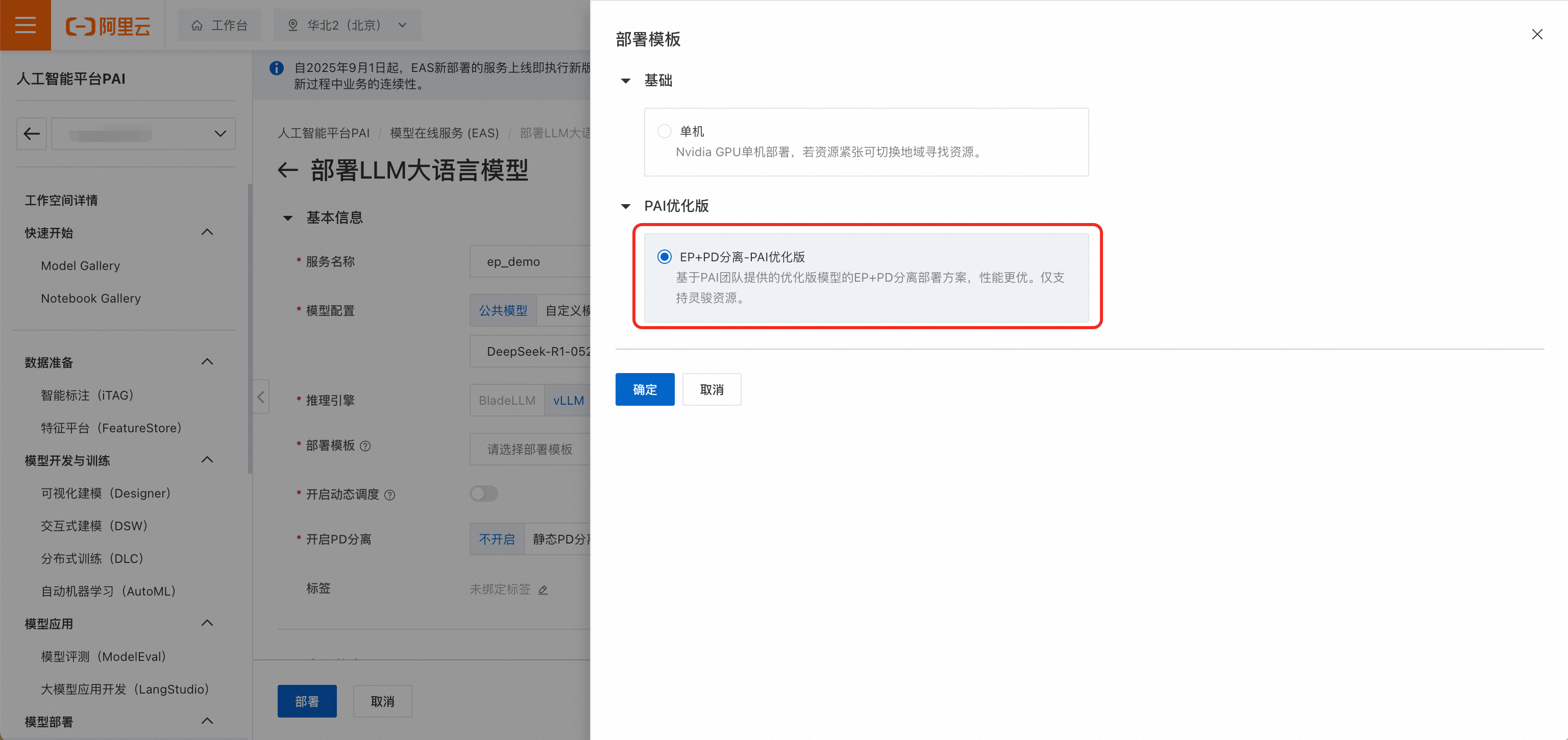
推理引擎選擇vLLM,部署模板選擇EP+PD分離-PAI最佳化版。
為Prefill和Decode服務配置部署資源。可以選擇公用資源或者資源配額。
公用資源:適用於快速體驗和開發測試。可用規格有
ml.gu8tea.8.48xlarge或ml.gu8tef.8.46xlarge。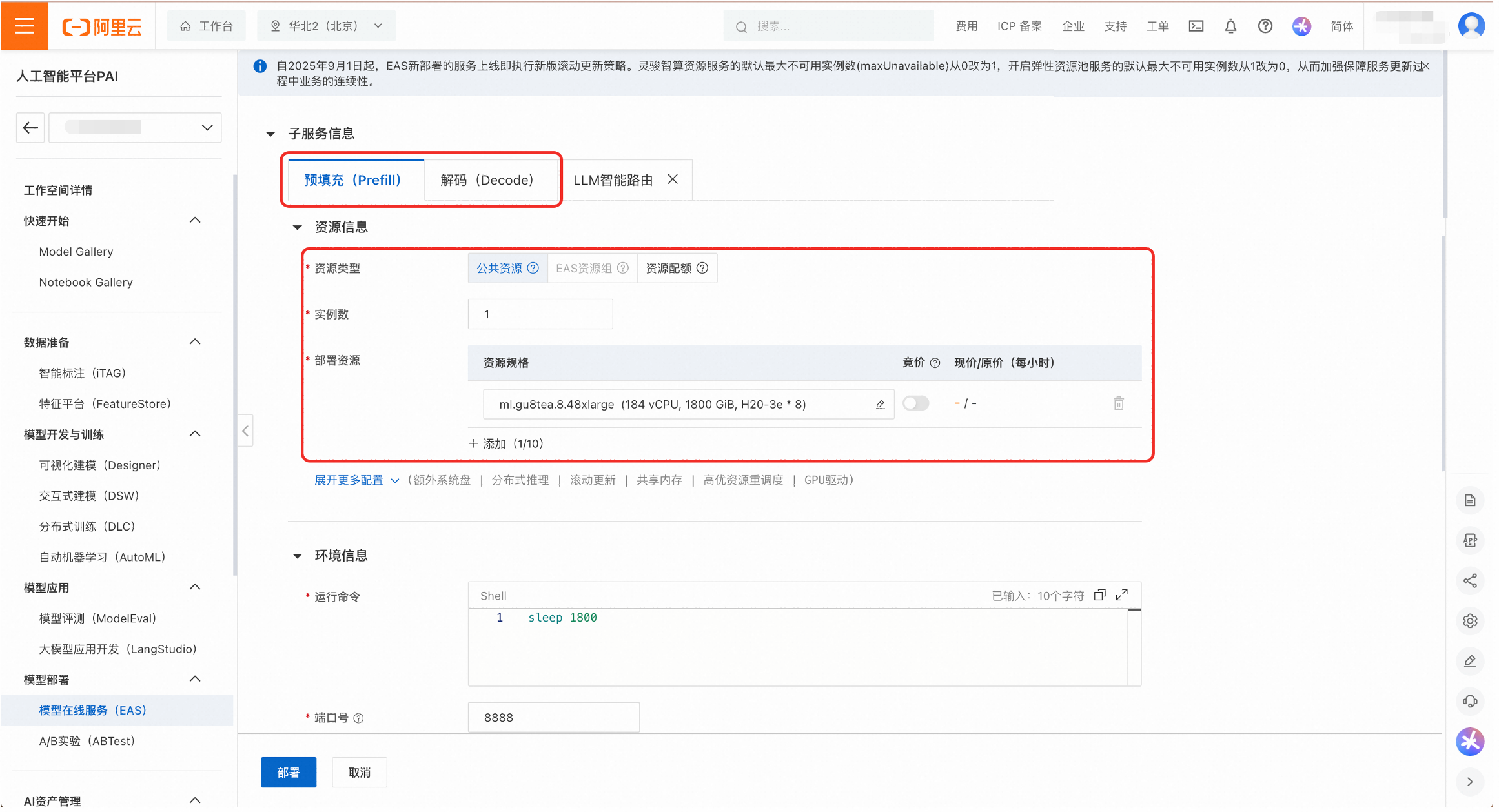
資源配額:推薦用於生產環境,以保證資源穩定性和隔離性。如果沒有可用的資源配置,無法選擇該類型。
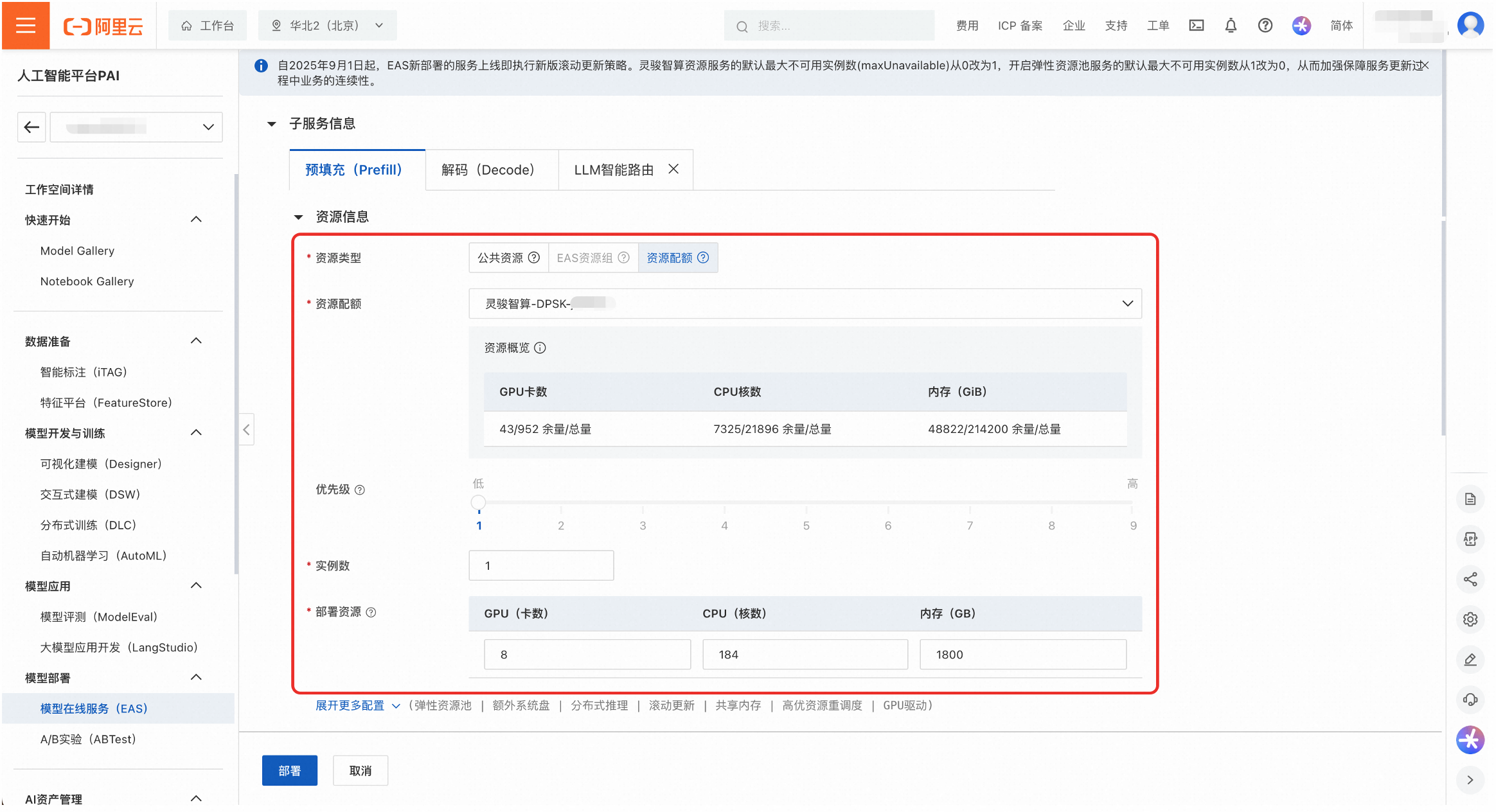
(可選)調整部署參數以最佳化效能。
執行個體數:調整Prefill和Decode的執行個體數量,以改變PD配比。部署模板中執行個體數的預設設定為1。
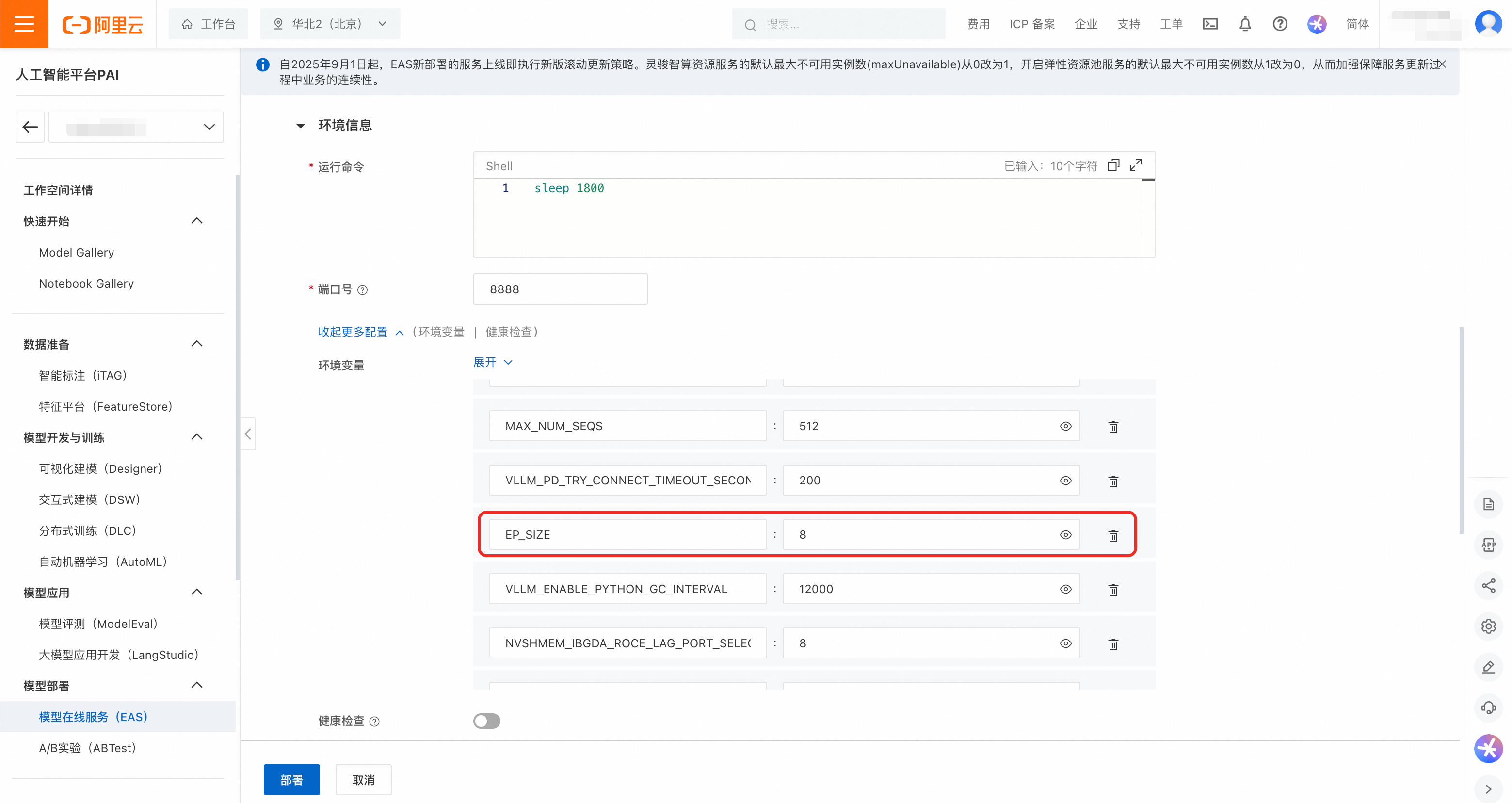
並行參數:在環境變數中調整Prefill和Decode服務的並行策略參數,如
EP_SIZE,DP_SIZE和TP_SIZE。部署模板中的預設值為:Prefill的TP_SIZE為8,Decode的EP_SIZE和DP_SIZE為8。說明為保護DeepSeek-R1-0528-PAI-optimized的模型權重,平台未透出推理引擎的運行命令,使用者可以通過環境變數修改重要參數。
單擊部署,等待服務啟動。此過程約需要40分鐘。
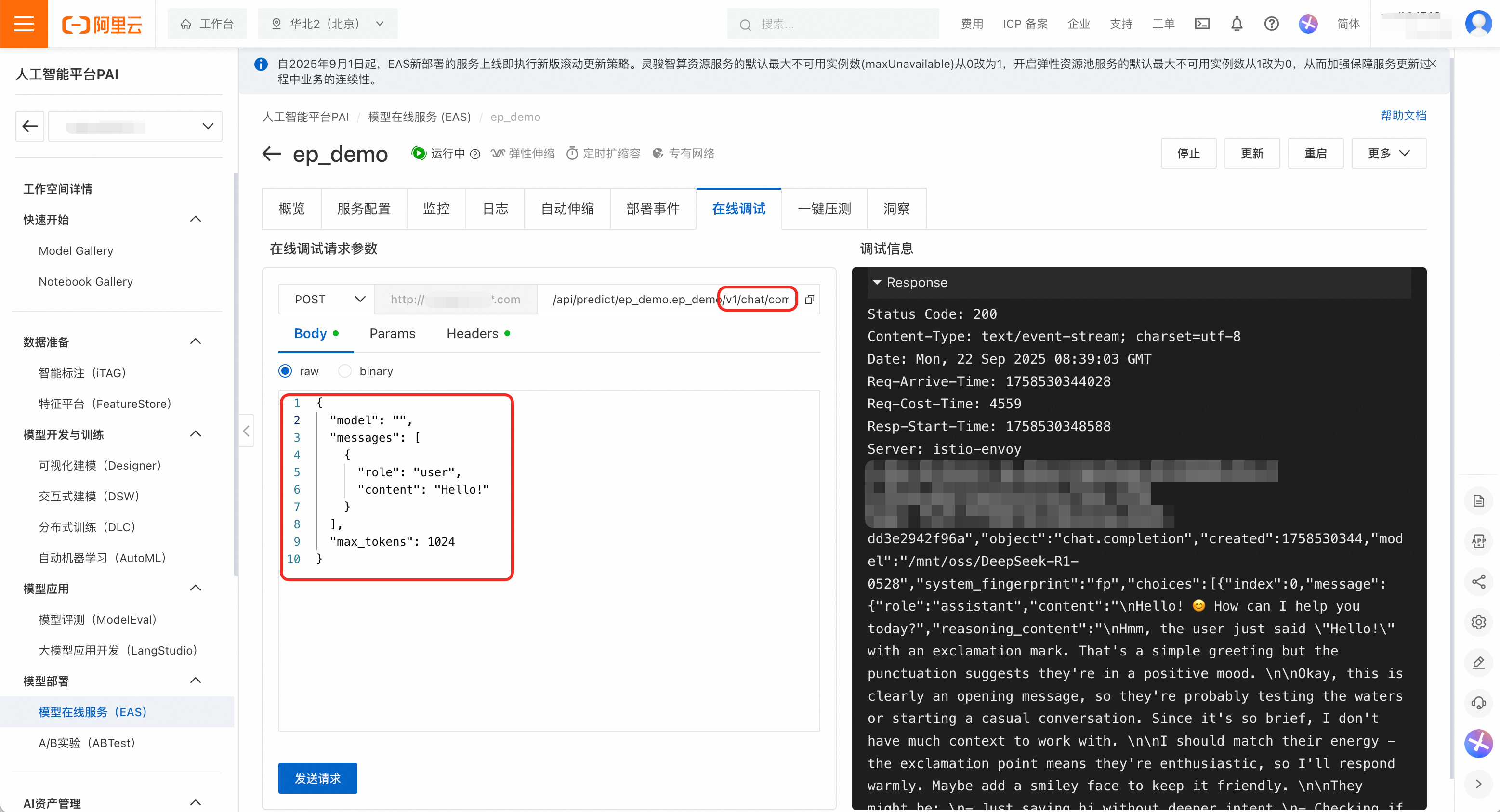
驗證服務狀態。部署完成後,在服務詳情頁的線上調試頁簽中測試服務是否正常運行。
說明API調用及第三方應用整合,可參見調用LLM服務。
構造一個符合OpenAI格式的請求,在URL路徑後附加
/v1/chat/completions,請求體為:{ "model": "", "messages": [ { "role": "user", "content": "Hello!" } ], "max_tokens": 1024 }單擊發送請求,可以看到響應結果為200,模型成功輸出回答,表示服務正常運行。
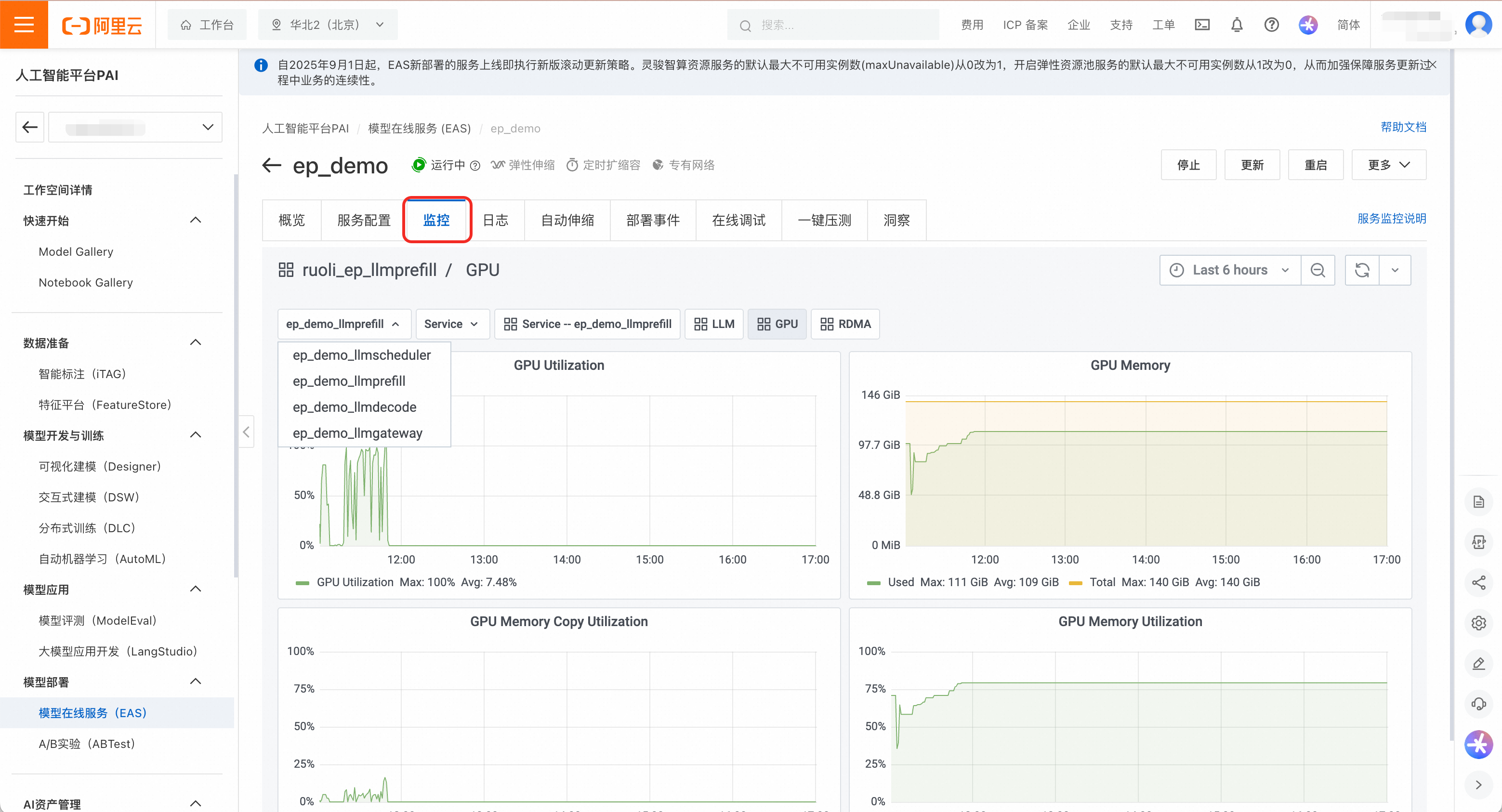
管理EP服務
在服務列表頁,點擊服務名稱進入詳情頁,可以對服務進行精細化管理。查看維度既包含整體服務(即彙總服務),也包含Prefill、Decode和LLM智能路由等子服務。
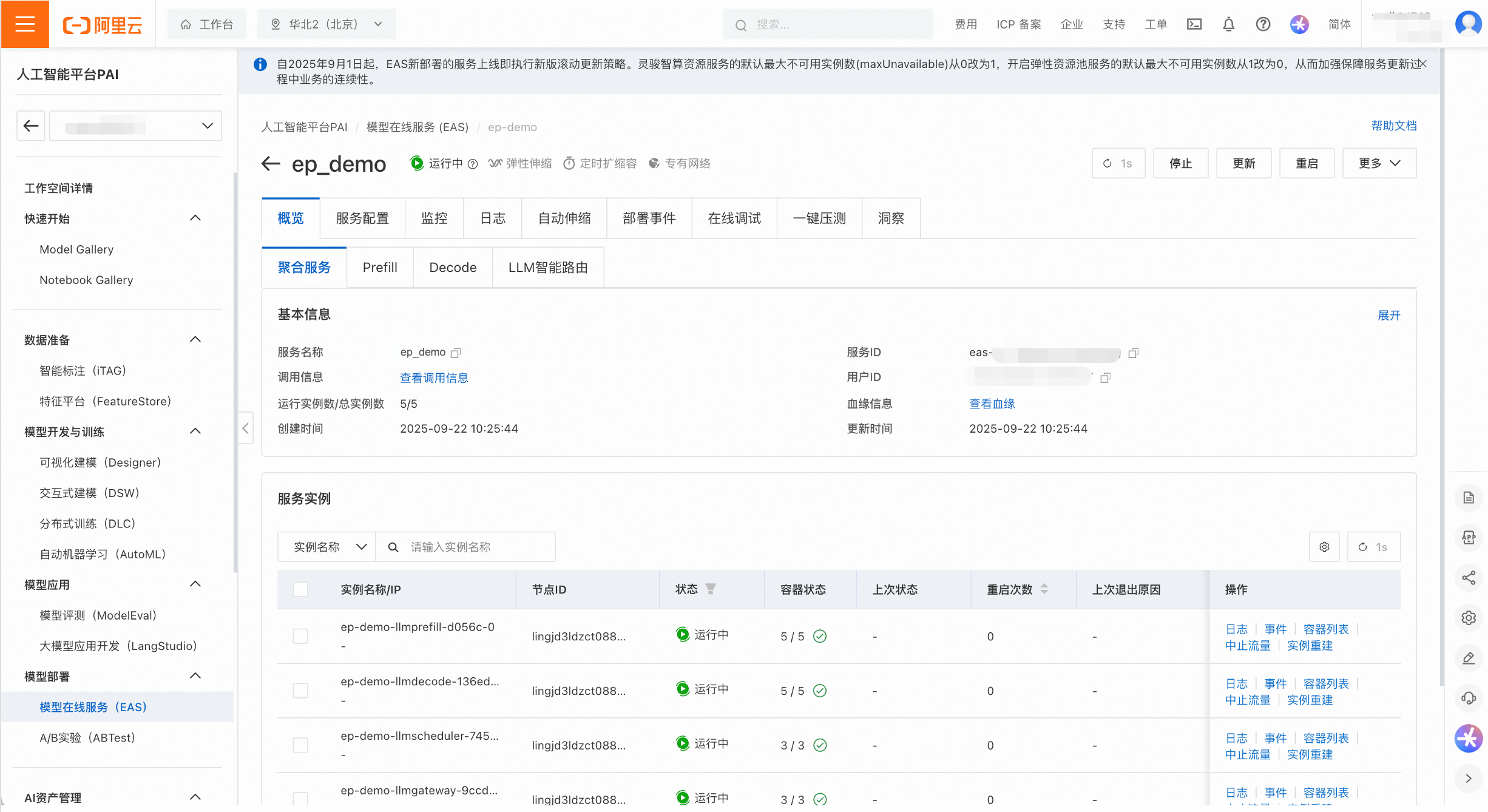
使用者可以查看服務的監控和日誌,以及配置自動調整策略。