AI 訓練通常需要重複讀取海量資料,這會產生巨大的網路開銷,影響訓練效率。在靈駿智算情境下,PAI提供了本機快取加速功能,通過將資料緩衝至本地計算節點,減少網路開銷,提高訓練吞吐,大幅提升資料讀取效能,為您的 AI 訓練任務提速。
技術優勢
快取:利用計算節點的記憶體與本地碟構建單機和分布式讀緩衝,加速資料集與 Checkpoint 訪問,顯著減少資料訪問延遲。
水平擴充:緩衝吞吐能力隨計算節點規模線性擴充,支援數百至數千個節點規模。
P2P 模型分發:通過 P2P支援大規模模型的高並發載入與分發,利用 GPU 節點間的高速網路實現熱點資料的並行讀取加速。
Serverless 簡單易用:一鍵開啟和關閉,無需修改代碼,對程式無侵入,無需關注營運。
限制與說明
儲存支援:支援 OSS 、智算 CPFS。
適用資源:目前僅支援靈駿智算資源,注意開啟後會佔用算力節點一定資源(CPU:4核,Mem:14GB)。
容量與策略:最大緩衝容量和靈駿智算規格相關,淘汰策略採用 LRU(最近最少使用)。
加速目標:核心目標是提升資料讀取效能,不支援寫。
資料高可用性:不保證資料高可用。本機快取資料可能存在丟失情況,重要訓練資料請及時備份。
工作機制:在多輪訓練時,第一輪需要從儲存執行個體(例如: OSS、 智算CPFS)讀取資料,效能與直讀儲存執行個體一致。但在後續多輪訓練中,將從本機快取中讀取資料,可以提升讀取速度。
使用方法
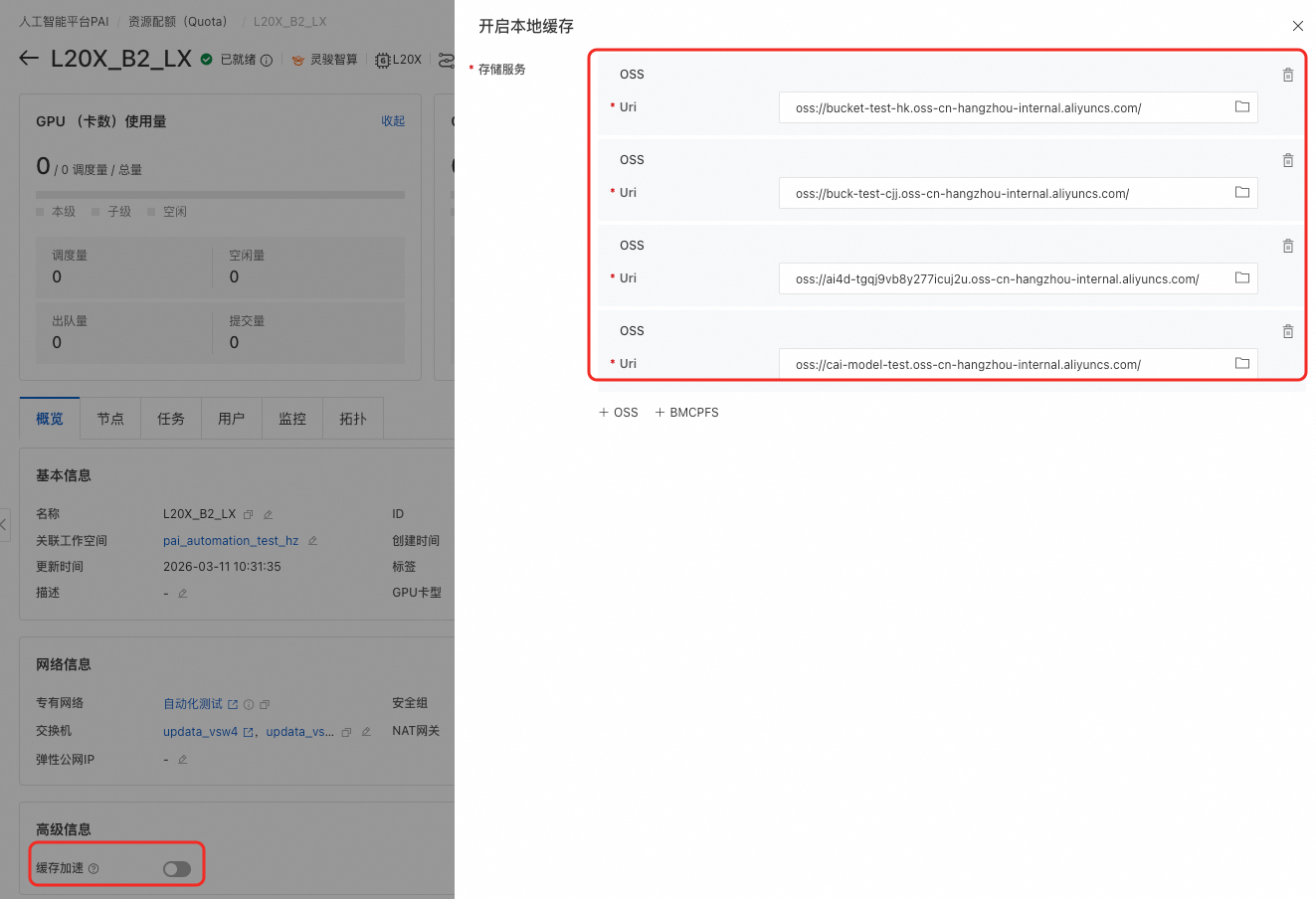
開啟資源配額(Quota)本機快取。在左側導覽列單擊资源配额(Quota)> 灵骏智算资源,找到並單擊目標Quota名稱進入管理頁面。开启本地缓存,並設定需要緩衝的儲存路徑。
如果是多級嵌套的資源配額,需保證第一級資源配額(Quota)已開啟本機快取。

使用目標資源配額的靈駿資源建立DLC任務,並開啟使用缓存。當掛載的儲存地址命中步驟1中填寫的緩衝地址時,預設加速(使用者可選擇關閉)。

安全性群組配置入規則
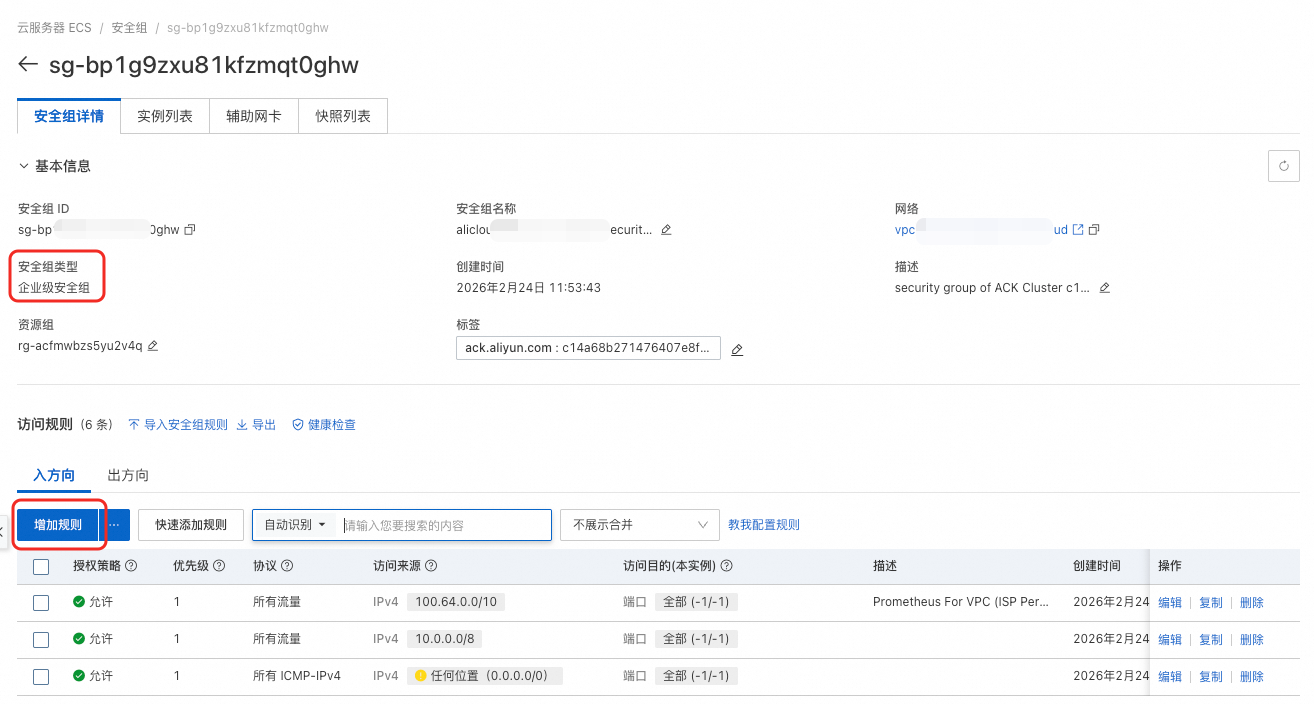
當您使用的安全性群組類型為企業級安全性群組時,需額外配置入規則,實現與Virtual Private Cloud的連通。
在資源配額頁面網路資訊地區查看配置的安全性群組。
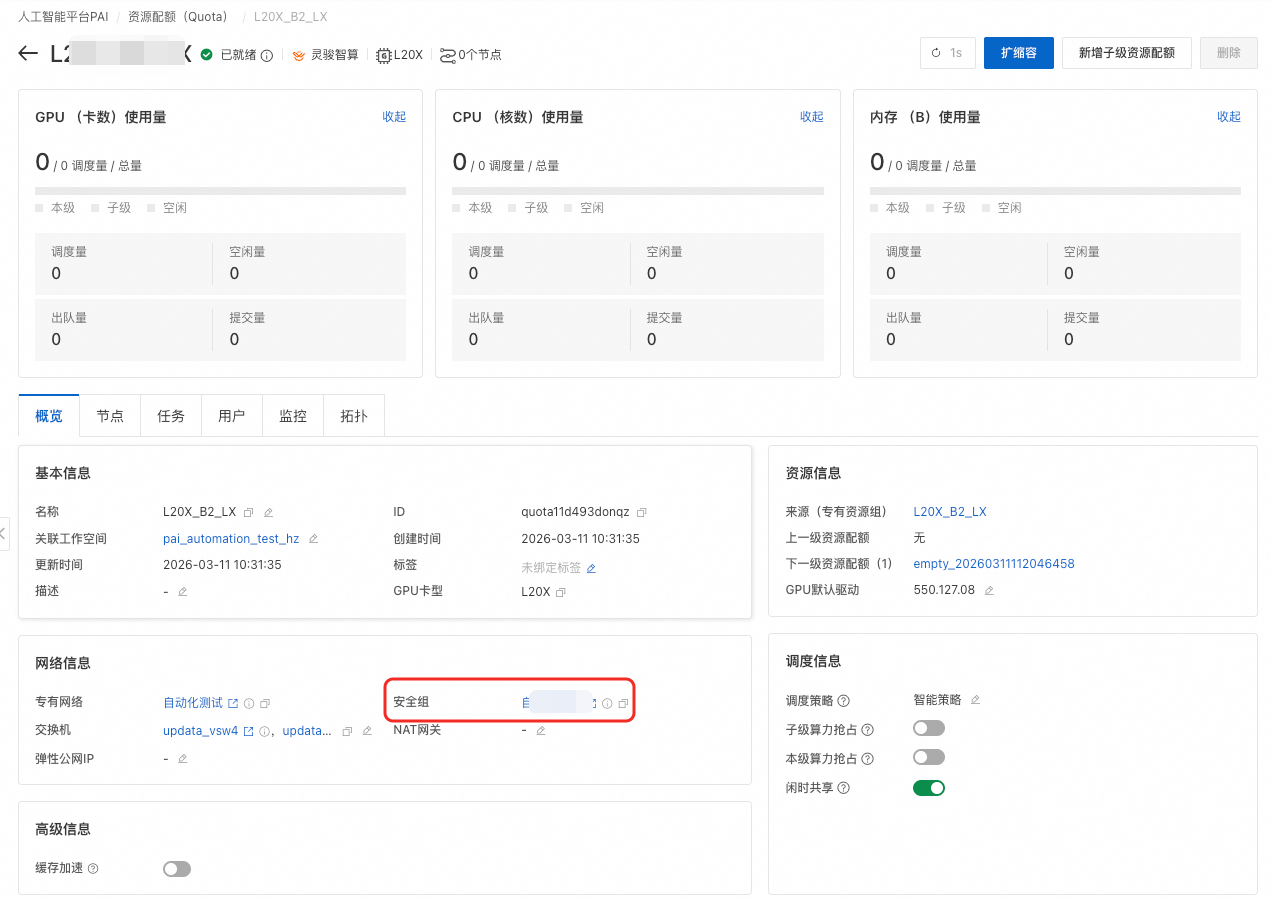
當開通緩衝加速功能時,需要根據設定的儲存服務數量配置對應的入規則連接埠,此處以4個為例。
到對應安全性群組的頁面,如果安全性群組類型為企業級,需要增加一項入方向的規則。
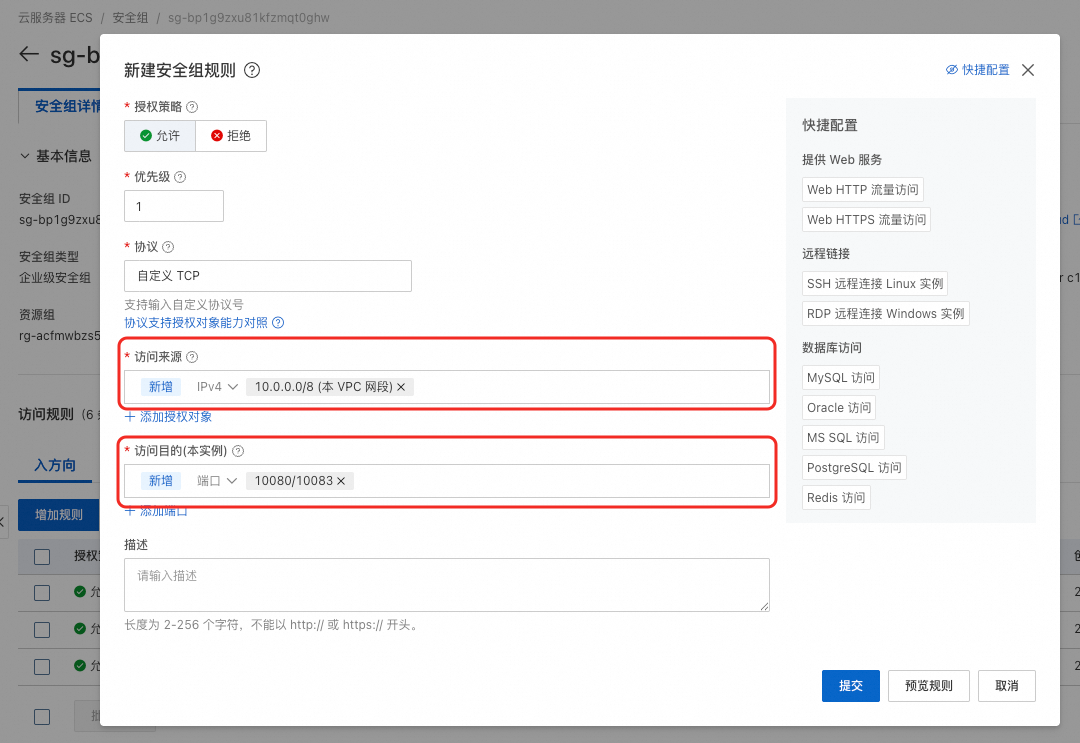 訪問來源配置為的資源配額使用的交換器對應的網段。訪問目的需要配置連接埠,連接埠數需要與緩衝配置的儲存服務數相同。如果儲存服務數為n,則連接埠需配置為10080/10080+n-1,其中n<=10。(表示連接埠範圍為
訪問來源配置為的資源配額使用的交換器對應的網段。訪問目的需要配置連接埠,連接埠數需要與緩衝配置的儲存服務數相同。如果儲存服務數為n,則連接埠需配置為10080/10080+n-1,其中n<=10。(表示連接埠範圍為10080-10080+n-1)。本樣本配置了4個,因此為10080/10083。