推薦系統和搜尋引擎是現代App解決資訊過載的標配系統,如果從零開發推薦系統,不僅需要耗費大量金錢和時間,而且很難滿足快速上線推薦系統及不斷迭代各種演算法的業務要求。本文為您介紹如何使用阿里雲產品建立推薦系統的資料和模型,從而快速搭建自己的推薦系統。
架構
完整的推薦流程包括召回、排序、過濾和重排等模組。召回是指從海量的待推薦候選集中,選取待推薦列表。排序是指對待推薦列表的每個Item與User的關聯程度進行排序。簡要的推薦系統的架構如下:
基於PAI產品實現推薦系統的架構如下(什麼是推薦系統開發平台PAI-Rec):
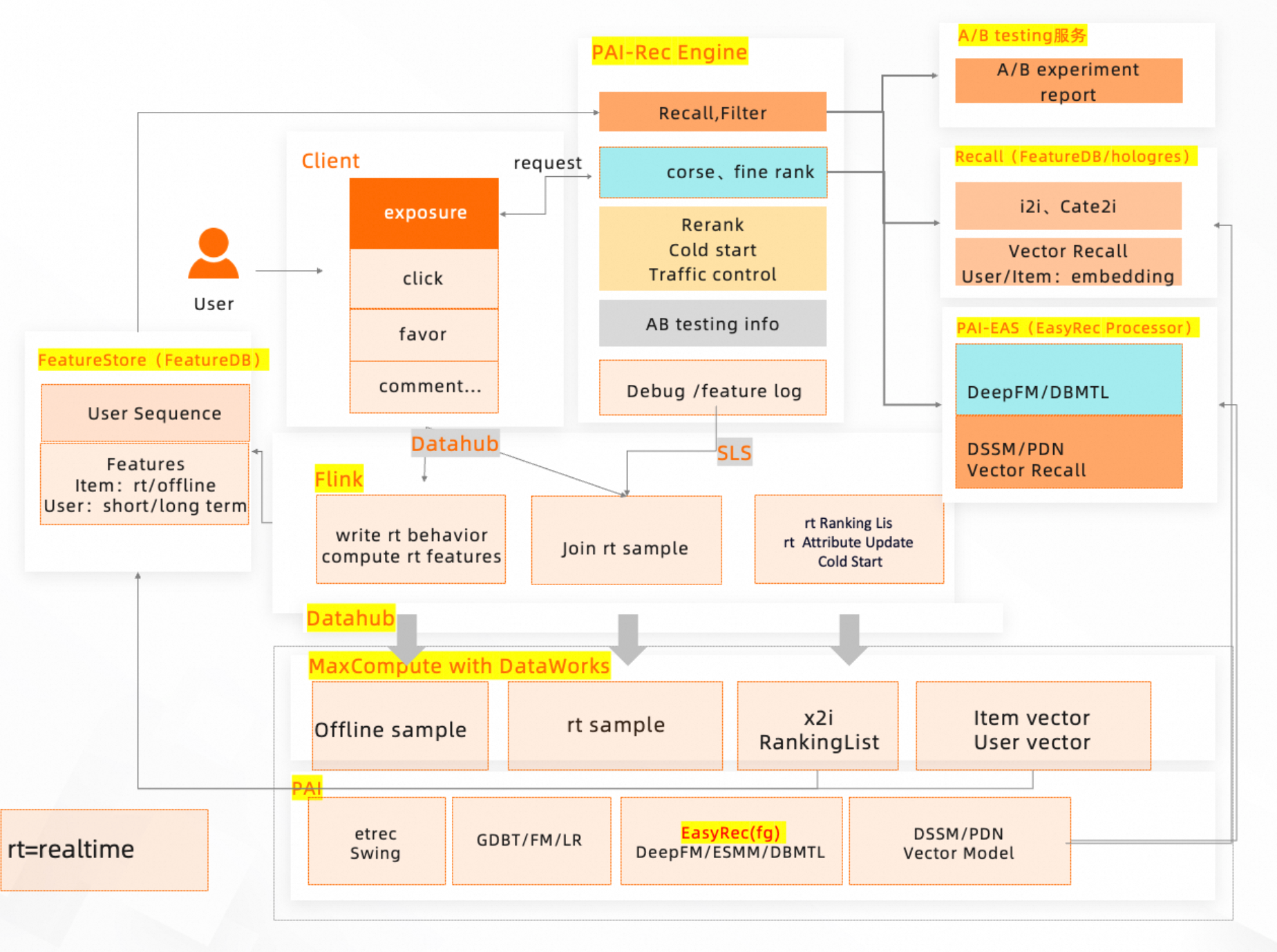
其中:
離線資料包括User、Item屬性工作表,Behavior,均儲存於MaxCompute。具體資料格式可以參考:資料格式說明資料準備。
即時使用者行為,如曝光、點擊、購買行為,寫入到DataHub。參考即時行為日誌表。
使用DataWorks進行資料預先處理和基礎特徵構建。建議使用PAI-Rec(什麼是推薦系統開發平台PAI-Rec)來配置產生推薦演算法流程的代碼,部署到DataWorks平台上,可以快速提高建設推薦系統的效率。
線上特徵通過PAI-FeatureStore的介面,可寫入到FeatureDB(特徵資料庫FeatureDB)
推薦方案定製的排序模組設定粗排和精排演算法:排序配置
通過PAI-Rec的引擎配置單來編排推薦演算法的流程
最終,使用者後端系統調用Recommendation Engine介面得到推薦結果。
推薦系統的相關資料
【強烈推薦】通過視頻,介紹如何快速搭建一套基於協同過濾的簡單推薦系統;從零構建推薦系統。
參考FeatureStore概述,瞭解特徵平台的功能。多個模型共用離線和線上特徵,可以用PAI-FeatureStore的功能。
參考特徵資料庫FeatureDB,瞭解特徵的儲存。
參考召回引擎概覽,瞭解召回引擎的功能和使用。
PyTorch版開源推薦演算法架構:TorchEasyRec。
TensorFlow版開源推薦演算法架構:EasyRec。