Qwen3是阿里雲千問團隊於2025年4月29日發布的最新大型語言模型系列,包含2個MoE模型和6個Dense模型。其基於廣泛的訓練,在推理、指令跟隨、Agent 能力和多語言支援方面取得了突破性的進展。PAI-Model Gallery已接入全部8個尺寸模型,以及其對應的Base模型、FP8模型,總計22個模型。本文為您介紹如何在Model Gallery部署評測該系列模型。
模型部署與調用
模型部署
以SGLang部署Qwen3-235B-A22B模型為例。
進入Model Gallery頁面。
登入PAI控制台,在頂部左上方根據實際情況選擇地區(可以切換地區來擷取合適的計算資產庫存)。
在左側導覽列選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間。
在左側導覽列選擇快速開始 > Model Gallery。
在Model Gallery頁面右側的模型列表中,單擊Qwen3-235B-A22B模型卡片,進入模型詳情頁面。
單擊右上方部署,如下配置參數,其他保持預設,即可將模型部署到EAS推理服務平台。
部署方式:推理引擎選擇SGLang。部署模板選擇單機。
资源信息:资源类型選擇公用資源,系統會給出推薦規格。模型所需最低配置參見部署所需算力&支援Token數。
重要如無可選資源規格,說明該地區公用資產庫存不足,可以考慮如下方案:
切換地區。如華北6(烏蘭察布)地區有較多靈駿競價資源(ml.gu7ef.8xlarge-gu100、ml.gu7xf.8xlarge-gu108、ml.gu8xf.8xlarge-gu108、ml.gu8tf.8.40xlarge),競價資源可能被搶佔,注意出價。
使用EAS資源群組。請前往EAS專屬機器預付費購買EAS專屬資源。
線上調試
在服務詳情頁最底端單擊線上調試,樣本如下。

API調用
擷取服務的訪問地址和Token。
在Model Gallery > 任務管理 > 部署任務中單擊已部署的服務名稱,進入服務詳情頁。
單擊查看調用資訊擷取公網調用地址和Token。

對話介面
/v1/chat/completions調用樣本(SGLang部署)。curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: <EAS_TOKEN>" \ -d '{ "model": "<模型名,通過'/v1/models' API擷取>", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "hello!" } ] }' \ <EAS_ENDPOINT>/v1/chat/completionsfrom openai import OpenAI ##### API 配置 ##### # <EAS_ENDPOINT>需替換為部署服務的訪問地址,<EAS_TOKEN>需替換為部署服務的Token。 openai_api_key = "<EAS_TOKEN>" openai_api_base = "<EAS_ENDPOINT>/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) models = client.models.list() model = models.data[0].id print(model) stream = True chat_completion = client.chat.completions.create( messages=[ {"role": "user", "content": "你好,請介紹一下你自己。"} ], model=model, max_completion_tokens=2048, stream=stream, ) if stream: for chunk in chat_completion: print(chunk.choices[0].delta.content, end="") else: result = chat_completion.choices[0].message.content print(result)其中:<EAS_ENDPOINT>需替換為部署服務的訪問地址,<EAS_TOKEN>需替換為部署服務的Token。
部署方式不同,對應的調用方法也不同。更多調用請參見LLM大語言模型部署-API調用。
整合第三方應用
進階配置
通過修改服務的 JSON 配置,可以實現調整 Token 上限、啟用工具調用 (Function Calling) 等進階功能。
操作路徑:在部署頁面的服務配置地區,編輯JSON。如果是已部署的服務,通過更新服務進入部署頁面。

修改 Token 上限
Qwen3模型原生支援 token 長度為 32768,可通過 RoPE 縮放支援人員最大 131072 長度的 token(但可能損失部分效能)。如下修改服務配置JSON檔案中的containers.script欄位:
vLLM:
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072SGLang:
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
解析工具調用
vLLM/SGlang 支援將模型產生的工具調用內容解析為結構化訊息,如下修改服務配置JSON檔案中的containers.script欄位:
vLLM:
vllm serve ... --enable-auto-tool-choice --tool-call-parser hermesSGLang:
python -m sglang.launch_server ... --tool-call-parser qwen25
控制思考模式
Qwen3 預設使用思考模式,可以通過硬開關(完全禁用思考)或軟開關(模型遵循使用者關於是否應該思考的指令)來控制。
使用軟開關/no_think
請求體樣本如下:
{
"model": "<MODEL_NAME>",
"messages": [
{
"role": "user",
"content": "/no_think Hello!"
}
],
"max_tokens": 1024
}使用硬開關
通過 API 參數控制(適用於vLLM和SGLang):在API調用中增加參數
chat_template_kwargs,樣本如下:curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: <EAS_TOKEN>" \ -d '{ "model": "<MODEL_NAME>", "messages": [ { "role": "user", "content": "Give me a short introduction to large language models." } ], "temperature": 0.7, "top_p": 0.8, "max_tokens": 8192, "presence_penalty": 1.5, "chat_template_kwargs": {"enable_thinking": false} }' \ <EAS_ENDPOINT>/v1/chat/completionsfrom openai import OpenAI # # <EAS_ENDPOINT>需替換為部署服務的訪問地址,<EAS_TOKEN>需替換為部署服務的Token。 openai_api_key = "<<EAS_TOKEN>" openai_api_base = "<EAS_ENDPOINT>/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) chat_response = client.chat.completions.create( model="<MODEL_NAME>", messages=[ {"role": "user", "content": "Give me a short introduction to large language models."}, ], temperature=0.7, top_p=0.8, presence_penalty=1.5, extra_body={"chat_template_kwargs": {"enable_thinking": False}}, ) print("Chat response:", chat_response)其中:<EAS_ENDPOINT>需替換為部署服務的訪問地址,<EAS_TOKEN>需替換為部署服務的Token。<MODEL_NAME>需替換為實際的模型名,通過
/v1/modelsAPI擷取。通過修改服務配置關閉(適用於BladeLLM):啟動模型時使用阻止模型產生思考內容的聊天模板。
在Model Gallery的模型介紹頁,查看是否提供了BLadeLLM關閉思考模式的方式。如Qwen3-8B,可如下修改服務配置JSON檔案中的
containers.script欄位關閉思考模式:blade_llm_server ... --chat_template /model_dir/no_thinking.jinja自行編寫聊天模板如
no_thinking.jinja,通過OSS掛載讀取,並修改服務配置JSON檔案中的containers.script欄位。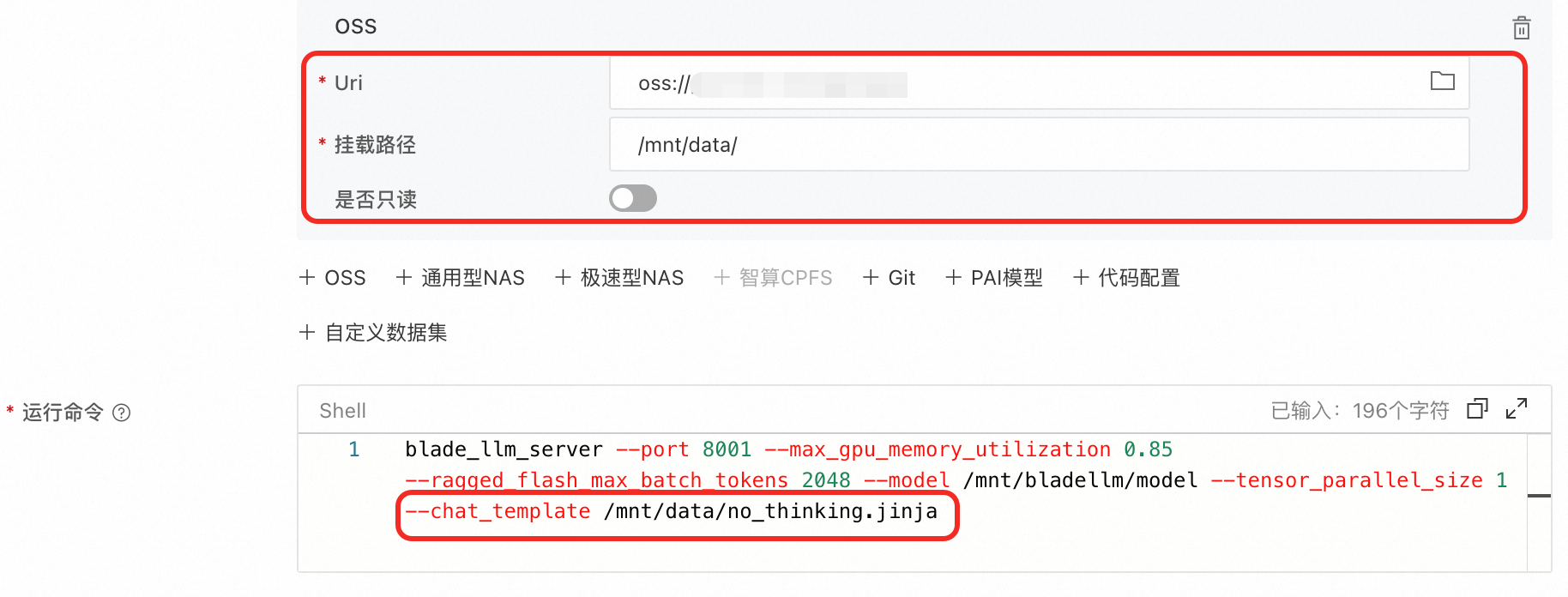
解析思考內容
需要將 think 部分區分輸出時,可以如下修改服務配置JSON檔案中的containers.script欄位:
vLLM:
vllm serve ... --enable-reasoning --reasoning-parser qwen3SGLang:
python -m sglang.launch_server ... --reasoning-parser deepseek-r1
模型微調
Qwen3-32B/14B/8B/4B/1.7B/0.6B 模型已支援SFT(全參/LoRA/QLoRA微調)和GRPO訓練。
支援一鍵提交訓練任務,訓練企業業務情境專屬模型。


模型評測
附錄:部署所需算力&支援Token數
下表提供了Qwen3部署所需的最低配置,以及使用不同機型部署時在不同推理架構上支援的最大 Token 數。
FP8模型裡只有Qwen3-235B-A22B模型的算力需求比原模型減少,其他所需算力與非FP8無區別,故未列在表中。比如Qwen3-30B-A3B-FP8所需算力,請參考Qwen3-30B-A3B。
模型 | 支援的最大 Token 數(輸入+輸出) | 最低配置 | |
SGLang 加速部署 | vLLM 加速部署 | ||
Qwen3-235B-A22B | 32768(加 RoPE 縮放:131072) | 32768(加 RoPE 縮放:131072) | 8 卡 GPU H / GU120 (8 * 96 GB 顯存) |
Qwen3-235B-A22B-FP8 | 32768(加 RoPE 縮放:131072) | 32768(加 RoPE 縮放:131072) | 4 卡 GPU H / GU120 (4 * 96 GB 顯存) |
Qwen3-30B-A3B Qwen3-30B-A3B-Base Qwen3-32B | 32768(加 RoPE 縮放:131072) | 32768(加 RoPE 縮放:131072) | 1 卡 GPU H / GU120 (96 GB 顯存) |
Qwen3-14B Qwen3-14B-Base | 32768(加 RoPE 縮放:131072) | 32768(加 RoPE 縮放:131072) | 1 卡 GPU L / GU60 (48 GB 顯存) |
Qwen3-8B Qwen3-4B Qwen3-1.7B Qwen3-0.6B Qwen3-8B-Base Qwen3-4B-Base Qwen3-1.7B-Base Qwen3-0.6B-Base | 32768(加 RoPE 縮放:131072) | 32768(加 RoPE 縮放:131072) | 1 卡 A10 / GU30 (24 GB 顯存) 重要 8B模型加RoPE縮放時,需要 48GB顯存 |
常見問題
Q: PAI部署的模型服務是否支援session/會話功能(多次請求之間能保持上下文資訊)?
不支援。PAI部署的模型服務API是無狀態的,每個調用完全獨立,伺服器不會在多個請求之間保留任何上下文或工作階段狀態。
如果要實現多輪對話,需要用戶端儲存歷史對話,再添加到模型調用的請求中,請求樣本見如何?多輪對話?