CosyVoice2提供API介面,用於管理音頻檔案、建立語音合成等功能。本文為您介紹CosyVoice2支援的介面類型及調用方式。
準備工作
部署CosyVoice2 WebUI服務或Frontend/Backend分離式高效能服務,且需要掛載OSS或其他儲存(用來儲存上傳的音頻檔案)。具體操作,請參見快速部署WebUI服務或快速部署Frontend/Backend分離式高效能服務。
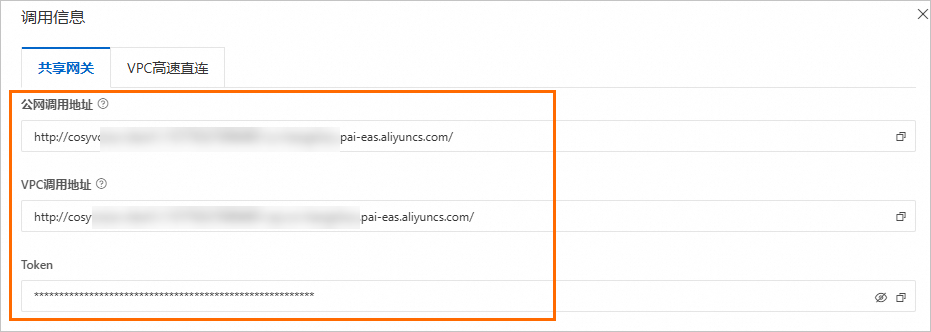
擷取服務訪問地址和Token。
重要對於Frontend/Backend分離式高效能服務,API調用的是Frontend服務。
壓測請使用vpc地址,相比公網可大幅提升處理速度。
單擊CosyVoice2的WebUI服務或Frontend服務名稱,在概覽頁面的基本資料地區,單擊查看調用資訊。
在調用資訊配置面板的共用網關頁簽,擷取服務訪問地址(EAS_SERVICE_URL)和Token(EAS_TOKEN),並將訪問地址末尾的
/刪除。說明使用公網調用地址:調用用戶端需支援訪問公網。
使用VPC調用地址:調用用戶端必須與服務位於同一個專用網路內。
準備音頻檔案。
本方案中使用的參考音頻如下:
參考語音WAV檔案:zero_shot_prompt.wav
參考語音文本:
希望你以後能夠做得比我還好喲
介面列表
上傳參考音頻檔案
調用方式
調用地址
<EAS_SERVICE_URL>/api/v1/audio/reference_audio請求方式
POST
請求HEADERS
Authorization: Bearer <EAS_TOKEN>請求參數
file:必填,表示需要上傳的音頻檔案,支援MP3、WAV和PCM。類型:file,預設值:無。
text:必填,表示音頻檔案對應的文字內容。類型:string。
返回參數
返回一個reference audio object,詳情請參見返回參數列表。
請求樣本
cURL
# <EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。 curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/reference_audio \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --form 'file=@"/home/xxxx/zero_shot_prompt.wav"' \ --form 'text="希望你以後能夠做得比我還好喲"'Python
import requests response = requests.post( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio", # <EAS_SERVICE_URL>需替換為服務訪問地址。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN>需替換為服務Token。 }, files={ "file": open("./zero_shot_prompt.wav", "rb"), }, data={ "text": "希望你以後能夠做得比我還好喲" } ) print(response.text)返回樣本
{ "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "希望你以後能夠做得比我還好喲" }
查看參考音頻檔案清單
調用方式
調用地址
<EAS_SERVICE_URL>/api/v1/audio/reference_audio
請求方式
GET
請求HEADERS
Authorization: Bearer <EAS_TOKEN>請求參數
limit:選填,用於限制返迴文件數。類型:integer,預設值:100。
order:選填,類型:string。按對象的created_at時間戳記排序,取值如下:
asc:升序
desc(預設值):降序
返回參數
返回一個reference audio object的數組,詳情請參見上傳音訊返回參數列表。
請求樣本
cURL
# <EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。 curl -XGET <EAS_SERVICE_URL>/api/v1/audio/reference_audio?limit=10&order=desc \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.get( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio", # <EAS_SERVICE_URL>需替換為服務訪問地址。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN>需替換為服務Token。 } ) print(response.text)返回樣本
[ { "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "希望你以後能夠做得比我還好喲" } ]
查看指定參考音頻檔案
調用方式
調用地址
<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>請求方式
GET
請求HEADERS
Authorization: Bearer <EAS_TOKEN>路徑參數
reference_audio_id:必填,表示參考音頻ID,如何擷取,請參見查看參考音頻檔案清單。類型:String,預設值:無。
返回參數
返回一個reference audio object,詳情請參見返回參數列表。
請求樣本
cURL
# <EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。 # <reference_audio_id>需替換為參考音頻ID。 curl -XGET <EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id> \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.get( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>", # <EAS_SERVICE_URL>需替換為服務訪問地址。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN>需替換為服務Token。 } ) print(response.text)返回樣本
{ "id": "50a5fdb9-c3ad-445a-adbb-3be32750****", "filename": "zero_shot_prompt.wav", "bytes": 111496, "created_at": 1748416005, "text": "希望你以後能夠做得比我還好喲" }
刪除參考音頻檔案
調用方式
調用地址
<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>請求方式
DELETE
請求HEADERS
Authorization: Bearer <EAS_TOKEN>路徑參數
reference_audio_id:必填,表示參考音頻ID,如何擷取,請參見查看參考音頻檔案清單。類型:String,預設值:無。
返回參數
返回一個reference audio object。
請求樣本
cURL
# <EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。 # <reference_audio_id>需替換為參考音頻ID。 curl -XDELETE <EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id> \ --header 'Authorization: Bearer <EAS_TOKEN>'Python
import requests response = requests.delete( "<EAS_SERVICE_URL>/api/v1/audio/reference_audio/<reference_audio_id>", # <EAS_SERVICE_URL>需替換為服務訪問地址。 headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN>需替換為服務Token。 } ) print(response.text)返回樣本
{ "code": "OK", "message": "reference audio: c0939ce0-308e-4073-918f-91ac88e3**** deleted.", "data": {} }
建立語音合成
調用方式
調用地址
<EAS_SERVICE_URL>/api/v1/audio/speech請求方式
POST
請求HEADERS
Authorization: Bearer <EAS_TOKEN>Content-Type: application/json
請求參數
model:必填,模型名稱,目前僅支援CosyVoice2-0.5B。類型:string,預設值:無。
input:必填,類型:object,預設值:無。表示輸入內容,取值如下:
mode:必填,類型:string。音頻合成模式,取值如下:
fast_replication:快速複刻
cross_lingual_replication:跨語種複刻
natural_language_replication:自然語言複刻
text:必填,需要合成的文本。類型:string,預設值:無。
reference_audio_id:必填,表示參考音頻ID,如何擷取,請參見查看參考音頻檔案清單。類型:string,預設值:無。
instruct:選填,instruct文本,動態調整語音風格,例如語氣、情感、語速等。僅模式選擇natural_language_replication時生效。類型:string,預設值:無。
sample_rate:選填,音頻採樣率。預設值:24000。
bit_rate: 選填, 位元速率。類型:string,預設值:192k。支援 16k、32k、48k、64k、128k、192k、256k、320k、384k。
volume: 選填,音量。 類型:float,預設值:1.0。例如,3.0就是三倍音量,0.8就是0.8倍音量。
speed:選填,輸出語音的速度,取值範圍:[0.5~2.0]。類型:float,預設值:1.0。
output_format:選填,輸出音頻格式。目前支援的格式:wav、mp3、pcm。預設值:wav。
stream:選填,是否輸出資料流式。類型:boolean,預設值:true。
返回參數
流式返回speech chunk object,詳情請參見返回參數列表。
請求樣本
非流式調用
cURL
<EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。
<reference_audio_id>需替換為參考音頻ID。
# <EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。 # <reference_audio_id>需替換為參考音頻ID。 curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/speech \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", "text": "收到好友從遠方寄來的生日禮物,那份意外的驚喜與深深的祝福讓我心中充滿了甜蜜的快樂,笑容如花兒般綻放。", "speed": 1.0, "output_format": "mp3", "sample_rate": 32000, "bit_rate": "48k", "volume": 2.0, "instruct": "用四川話說" }, "stream": false }'返回base64編碼結果:
{"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"}Python
需要安裝如下依賴:
pip install requests==2.32.3 packaging==24.2import json import base64 import requests from packaging import version required_version = "2.32.3" if version.parse(requests.__version__) < version.parse(required_version): raise RuntimeError(f"requests version must >= {required_version}") with requests.post( "<EAS_SERVICE_URL>/api/v1/audio/speech", # <EAS_SERVICE_URL>需替換為服務訪問地址。 # 樣本: "http://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api/v1/audio/speech" headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN>需替換為服務Token。 "Content-Type": "application/json", }, json={ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", # <reference_audio_id>需替換為參考音頻ID。 "text": "收到好友從遠方寄來的生日禮物,那份意外的驚喜與深深的祝福讓我心中充滿了甜蜜的快樂,笑容如花兒般綻放。", "output_format": "mp3", "sample_rate": 24000, "speed": 1.0, "bit_rate": "48k", "volume": 2.0, "instruct": "用四川話說" }, "stream": False }, timeout=10 ) as response: if response.status_code != 200: print(response.text) exit() data = json.loads(response.content) encode_buffer = data['output']['audio']['data'] decode_buffer = base64.b64decode(encode_buffer) with open('./http_non_stream.mp3', 'wb') as f: f.write(decode_buffer)流式調用
cURL
<EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。
<reference_audio_id>需替換為參考音頻ID。
# <EAS_SERVICE_URL>和<EAS_TOKEN>需分別替換為服務訪問地址和Token。 # <reference_audio_id>需替換為參考音頻ID。 curl -XPOST <EAS_SERVICE_URL>/api/v1/audio/speech \ --header 'Authorization: Bearer <EAS_TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", "text": "收到好友從遠方寄來的生日禮物,那份意外的驚喜與深深的祝福讓我心中充滿了甜蜜的快樂,笑容如花兒般綻放。", "speed": 1.0, "output_format": "mp3", "sample_rate": 32000, "bit_rate": "48k", "volume": 2.0, "instruct": "用四川話說" }, "stream": true }'返回base64位編碼結果如下:
data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"} data: {"output":{"finish_reason":null,"audio":{"data":"DNgB9djax9su3Ba...."}},"request_id": "f90a65be-f47b-46b5-9ddc-70bae550****"}Python
需要安裝Python SSE用戶端:
pip install requests==2.32.3 packaging==24.2 sseclient-py==1.8.0 -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.comimport io import json import base64 import wave import requests from sseclient import SSEClient # pip install sseclient-py from packaging import version required_version = "2.32.3" if version.parse(requests.__version__) < version.parse(required_version): raise RuntimeError(f"requests version must >= {required_version}") with requests.post( "<EAS_SERVICE_URL>/api/v1/audio/speech", # <EAS_SERVICE_URL>需替換為服務訪問地址。 # 樣本: "http://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api/v1/audio/speech" headers={ "Authorization": "Bearer <EAS_TOKEN>", # <EAS_TOKEN>需替換為服務Token。 "Content-Type": "application/json", }, json={ "model": "CosyVoice2-0.5B", "input": { "mode": "natural_language_replication", "reference_audio_id": "<reference_audio_id>", # <reference_audio_id>需替換為參考音頻ID。 "text": "收到好友從遠方寄來的生日禮物,那份意外的驚喜與深深的祝福讓我心中充滿了甜蜜的快樂,笑容如花兒般綻放。", "output_format": "mp3", "sample_rate": 24000, "speed": 1.0, "bit_rate": "48k", "volume": 2.0, "instruct": "用四川話說", "debug": True }, "stream": True }, stream=True, timeout=10 ) as response: if response.status_code != 200: print(response.text) exit() messages = SSEClient(response) with open('./http_stream.mp3', 'wb') as f: for i, msg in enumerate(messages.events()): print(f"Event: {msg.event}, Data: {msg.data}") data = json.loads(msg.data) if data['error'] is not None: print(data['error']) break metrics = data['metrics'] print(f"{metrics=}") encode_buffer = data['output']['audio']['data'] decode_buffer = base64.b64decode(encode_buffer) f.write(decode_buffer)Websocket API
需要安裝如下依賴:
pip install websocket-client==1.8.0 -i http://mirrors.cloud.aliyuncs.com/pypi/simple --trusted-host mirrors.cloud.aliyuncs.com#!/usr/bin/python # -*- coding: utf-8 -*- import base64 import json import logging import sys import time import uuid import traceback import websocket class TTSClient: def __init__(self, api_key, uri, params, log_level='INFO'): """ 初始化 TTSClient 執行個體 參數: api_key (str): 鑒權用的 API Key uri (str): WebSocket 服務地址 """ self._api_key = api_key # 替換為你的 API Key self._uri = uri # 替換為你的 WebSocket 地址 self._task_id = str(uuid.uuid4()) # 產生唯一任務 ID self._ws = None # WebSocketApp 執行個體 self._task_started = False # 是否收到 task-started self._task_finished = False # 是否收到 task-finished / task-failed self._check_params(params) self._params = params self._chunk_metrics = [] self._metrics = {} self._first_package_time = None self._last_time = None self._init_log(log_level) self.audio_data = b'' def _init_log(self, log_level): self._log = logging.getLogger("ws_client") log_formatter = logging.Formatter('%(asctime)s - Process(%(process)s) - %(levelname)s - %(message)s') stream_handler = logging.StreamHandler(stream=sys.stdout) stream_handler.setFormatter(log_formatter) self._log.addHandler(stream_handler) self._log.setLevel(log_level) def get_metrics(self): """擷取合成結果效能指標""" return self._metrics def _check_params(self, params): assert 'mode' in params and params['mode'] in ['fast_replication', 'cross_lingual_replication', 'natural_language_replication'] assert 'reference_audio_id' in params assert 'output_format' in params and params['output_format'] in ['wav', 'mp3', 'pcm'] if params['mode'] == 'natural_language_replication': assert 'instruct' in params and params['instruct'] else: if 'instruct' in params: del params['instruct'] def on_open(self, ws): """ WebSocket 串連建立時回呼函數 發送 run-task 指令開啟語音合成任務 """ self._log.debug("WebSocket 已串連") # 構造 run-task 指令 run_task_cmd = { "header": { "action": "run-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "task_group": "audio", "task": "tts", "function": "SpeechSynthesizer", "model": "cosyvoice-v2", "parameters": { "mode": self._params['mode'], "reference_audio_id": self._params['reference_audio_id'], "output_format": self._params.get('output_format', 'wav'), "sample_rate": self._params.get('sample_rate', 24000), "bit_rate": self._params.get('bit_rate', '192k'), "volume": self._params.get('volume', 1.0), "instruct": self._params.get('instruct', ''), "speed": self._params.get('speed', 1.0), "debug": True, }, "input": {} } } # 發送 run-task 指令 ws.send(json.dumps(run_task_cmd)) self._log.debug("已發送 run-task 指令") def on_message(self, ws, message): """ 接收到訊息時的回呼函數 區分文本和二進位訊息處理 """ try: msg_json = json.loads(message) # self._log.debug(f"收到 JSON 訊息: {msg_json}") self._log.debug(f"收到 JSON 訊息: {msg_json['header']['event']}") if "header" in msg_json: header = msg_json["header"] if "event" in header: event = header["event"] if event == "task-started": self._log.debug("任務已啟動") self._task_started = True # 發送 continue-task 指令 for text in self._params['texts']: self.send_continue_task(text) # 所有 continue-task 發送完成後發送 finish-task self.send_finish_task() self._last_time = time.time() elif event == "result-generated": metrics = msg_json['payload']['metrics'] cur_time = time.time() metrics['client_cost_time'] = cur_time - self._last_time self._last_time = cur_time encode_data = msg_json["payload"]["output"]["audio"]["data"] decode_data = base64.b64decode(encode_data) self._log.debug(f"收到音頻資料,大小: {len(decode_data)} 位元組") self.audio_data += decode_data metrics['client_rtf'] = metrics['client_cost_time'] / metrics['speech_len'] self._chunk_metrics.append(metrics) elif event == "task-finished": self._metrics = { 'client_first_package_time': self._chunk_metrics[0]['client_cost_time'], "client_rtf": sum([m["client_cost_time"] for m in self._chunk_metrics]) / sum([m["speech_len"] for m in self._chunk_metrics]), 'client_cost_time': sum([m["client_cost_time"] for m in self._chunk_metrics]), 'speech_len': sum([m["speech_len"] for m in self._chunk_metrics]), 'server_first_package_time': self._chunk_metrics[0]['server_cost_time'], 'server_rtf': sum([m["server_cost_time"] for m in self._chunk_metrics]) / sum([m["speech_len"] for m in self._chunk_metrics]), 'server_cost_time': sum([m["server_cost_time"] for m in self._chunk_metrics]), "generate_time": sum([m["generate_time"] for m in self._chunk_metrics]) } self._log.debug(f"任務已完成, 請求效能指標: client_first_package_time: {self._metrics['client_first_package_time']:.3f}, client_rtf: {self._metrics['client_rtf']:.3f}, client_cost_time: {self._metrics['client_cost_time']:.3f}, speech_len: {self._metrics['speech_len']:.3f}, server_cost_time: {self._metrics['server_cost_time']:.3f}, generate_time: {self._metrics['generate_time']:.3f}") self._task_finished = True self.close(ws) elif event == "task-failed": self._log.error(f"任務失敗: {msg_json}") self._task_finished = True self.close(ws) except json.JSONDecodeError as e: self._log.error(f"JSON 解析失敗: {str(e)}\t{traceback.format_exc()}") def on_error(self, ws, error): """發生錯誤時的回調""" self._log.error(f"WebSocket 出錯: {error}\t{traceback.format_exc()}") self._metrics = {'error': error} def on_close(self, ws, close_status_code, close_msg): """串連關閉時的回調""" self._log.debug(f"WebSocket 已關閉: {close_msg} ({close_status_code})") def send_continue_task(self, text): """發送 continue-task 指令,附帶要合成的常值內容""" cmd = { "header": { "action": "continue-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "input": { "text": text } } } self._ws.send(json.dumps(cmd)) self._log.debug(f"已發送 continue-task 指令,常值內容: {text}") def send_finish_task(self): """發送 finish-task 指令,結束語音合成任務""" cmd = { "header": { "action": "finish-task", "task_id": self._task_id, "streaming": "duplex" }, "payload": { "input": {} } } self._ws.send(json.dumps(cmd)) self._log.debug("已發送 finish-task 指令") def close(self, ws): """主動關閉串連""" if ws and ws.sock and ws.sock.connected: ws.close() self._log.debug("已主動關閉串連") def run(self): """啟動 WebSocket 用戶端""" # 佈建要求頭部(鑒權) header = { "Authorization": f"Bearer {self._api_key}", } # 建立 WebSocketApp 執行個體 self._ws = websocket.WebSocketApp( self._uri, header=header, on_open=self.on_open, on_message=self.on_message, on_error=self.on_error, on_close=self.on_close ) self._log.debug("正在監聽 WebSocket 訊息...") self._ws.run_forever() # 啟動長串連監聽 # 樣本使用方式 if __name__ == "__main__": API_KEY = "<EAS_TOKEN>" # <EAS_TOKEN>需替換為服務Token SERVER_URI = "ws://<EAS_SERVICE_URL>/api-ws/v1/audio/speech" # <EAS_SERVICE_URL>需替換為服務訪問地址。 # 樣本: "ws://cosyvoice-frontend-test.1534081855183999.cn-hangzhou.pai-eas.aliyuncs.com/api-ws/v1/audio/speech" texts = [ "收到好友從遠方寄來的生日禮物,那份意外的驚喜與深深的祝福讓我心中充滿了甜蜜的快樂,笑容如花兒般綻放。" ] params = { "mode": "natural_language_replication", "texts": texts, "reference_audio_id": "<reference_audio_id>", "speed": 1.0, "output_format": "mp3", "sample_rate": 24000, "bit_rate": "48k", "volume": 2.0, "instruct": "用冷靜的語氣說" } client = TTSClient(API_KEY, SERVER_URI, params, log_level='DEBUG') client.run() with open('./websocket_stream.mp3', 'wb') as wfile: wfile.write(client.audio_data) metrics = client.get_metrics() print(f"{metrics=}")