本文為您介紹在部署和微調大模型時所需顯存與哪些因素相關,以及如何估算大模型所需的顯存大小。
簡易顯存估算器
-
本文根據大模型通用的計算方式,估算大模型部署和微調所需顯存,由於不同模型的網路結構和演算法存在差異,因此,可能與實際顯存佔用有差距。
-
對於MoE模型(混合專家模型),以DeepSeek-R1-671B為例,671B的模型本身參數都需要載入,但在推理時只啟用37B的參數,因此在計算啟用值所佔顯存時,需要按照37B的模型參數量計算。
-
模型微調時通常採用16-bit儲存模型參數、啟用值、梯度,採用Adam/AdamW最佳化器,並用32-bit儲存最佳化器狀態。
Inference
| Scenario | Required GPU Memory (GB) |
|---|---|
| Inference (16-bit) | - |
| Inference (8-bit) | - |
| Inference (4-bit) | - |
Fine-tuning
| Scenario | Required GPU Memory (GB) |
|---|---|
| Full Fine-tuning | - |
| LoRA Fine-tuning | - |
| QLoRA (8-bit) Fine-tuning | - |
| QLoRA (4-bit) Fine-tuning | - |
模型推理所需顯存影響因素
模型推理時所需顯存主要由以下部分組成:
模型本身參數
在模型推理時首先需要儲存模型本身的參數,其佔用的顯存計算公式為:參數量 x 參數精度。常用的參數精度有FP32(4位元組)、FP16(2位元組)、BF16 (2位元組)。對於大語言模型,模型參數通常採用FP16或BF16。因此,以參數精度為FP16,參數量為7B的模型為例,其所需顯存為:
啟用值
在大語言模型推理過程中,需要計算每層神經元的啟用值,其佔用顯存與批量大小、序列長度和模型架構(層數、隱藏層大小)正相關,關係式可以表示為:
其中:
-
b(batch size):單次請求批量大小,在作為線上服務時通常為1,作為批處理介面時不為1。
-
s(sequence length):整個序列長度,包括輸入輸出(token數量)。
-
h(hidden size):模型隱藏層維度。
-
L(Layers):模型Transformer層數。
-
param_bytes:啟用值儲存的精度,一般為2位元組。
結合以上因素和實踐經驗,為簡化顯存估算,且留有一定餘量,以一個7B模型為例,b為1,s為2048,param_bytes為2位元組時,啟用值所佔顯存可以大致按照10%的模型所佔顯存進行估算,即:
KV緩衝
為加速大語言模型的推理效率,通常會緩衝每層Transformer已經計算完成的鍵K(Key)和值V(Value),避免每個時間步重新計算所有歷史token的注意力機制參數。引入KV緩衝後,其計算量從
其中:
-
2:表示需要儲存K(Key)和V(Value)兩個矩陣。
-
b(batch size):單次請求批量大小,在作為線上服務時通常為1,作為批處理介面時不為1。
-
s(sequence length):整個序列長度,包括輸入輸出(token數量)。
-
h(hidden size):模型隱藏層維度。
-
L(Layers):模型Transformer層數。
-
C(Concurrent):服務介面請求的並發度。
-
param_bytes:啟用值儲存的精度,一般為2位元組 。
結合以上因素和實踐經驗,為簡化顯存估算,且留有一定餘量,以一個7B模型為例,當C為1,b為1,s為2048,param_bytes為2位元組時,KV緩衝所佔顯存也大致按照10%的模型所佔顯存進行估算,即:
其他
除了以上影響因素外,當前批次的輸入資料、CUDA核心、PyTorch/TensorFlow深度學習架構本身等也會佔用一些顯存,通常為1~2GB。
根據以上因素分析,對於7B的大模型,通常情況下模型推理部署最低需要的顯存約為:
模型微調所需顯存影響因素
模型微調訓練時所需的顯存主要由以下部分組成:
模型本身參數
在微調訓練時首先需要儲存模型本身的參數,其佔用的顯存計算公式為:參數量 x 參數精度。常用的參數精度有FP32(4位元組)、FP16(2位元組)、BF16 (2位元組),對於大語言模型,在微調時模型參數通常採用FP16或BF16。因此以參數精度為FP16,參數量為7B的模型為例,其所需顯存為:
梯度參數
在模型訓練的反向傳播過程中,需要為模型參數計算梯度,梯度的數量與待訓練的參數數量相同。大語言模型中通常採用2位元組的精度儲存梯度,因此7B的模型根據不同的微調訓練方法,所需的顯存為:
|
微調訓練方法 |
訓練機制 |
適用情境 |
7B模型微調訓練梯度所需顯存(以1%參數計算、2位元組儲存) |
|
全參數微調 |
需要訓練的參數與模型本身參數相同 |
算力充足的高精度需求 |
14GB |
|
LoRA(低秩適配器) |
LoRA微調將凍結原始模型參數,僅訓練低秩矩陣,其待訓練的參數取決於模型結構和低秩矩陣的大小,通常約佔模型總參數量的0.1%~1% |
低資源適配特定任務 |
0.14GB |
|
QLoRA(量化 + LoRA) |
將預訓練模型壓縮為4-bit或8-bit,使用LoRA微調模型,並引入雙重量化與分頁最佳化器,進一步減少顯存佔用,待訓練參數通常約佔模型總參數量的0.1%~1% |
超大規模模型微調 |
0.14GB |
最佳化器狀態
在訓練過程中還需儲存最佳化器的狀態,狀態值的數量與待訓練參數數量相關,此外,模型通常會採用混合參數精度訓練,即模型參數、梯度採用2位元組儲存,最佳化器狀態採用4位元組儲存,此做法是為了確保在參數更新過程中保持高精度,避免因FP16/BF16的有限動態範圍導致數值不穩定或溢出。同時,如果採用4位元組儲存狀態時,所需的顯存將翻倍。常用的最佳化器情況如下:
|
最佳化器類型 |
參數更新機制 |
額外儲存需求 (每個待訓練參數) |
適用情境 |
7B模型微調訓練最佳化器狀態所需顯存(4位元組儲存) |
||
|
全參數微調 |
LoRA微調(以1%參數計算) |
QLoRA微調(以1%參數計算) |
||||
|
SGD |
只用當前梯度 |
0(無額外狀態) |
小模型或實驗 |
0 |
0 |
0 |
|
SGD + Momentum |
帶動量項 |
1個浮點數(動量) |
穩定性更好 |
28GB |
0.28GB |
0.28GB |
|
RMSProp |
適應性學習率 |
1個浮點數(二階矩) |
非凸最佳化 |
28GB |
0.28GB |
0.28GB |
|
Adam/AdamW |
動量 + 適應性學習率 |
2個浮點數(一階+二階矩) |
大模型常用 |
56GB |
0.56GB |
0.56GB |
啟用值
訓練時還需儲存前向傳播過程中產生的中間啟用值,以便在反向傳播時計算梯度。這部分顯存消耗與批量大小 (batch size)、序列長度 (sequence length) 和模型架構(層數、隱藏層大小)正相關,關係式可以表示為:
其中:
-
b(batch size):批量大小。
-
s(sequence length):整個序列長度,包括輸入輸出(token數量)。
-
h(hidden size):模型隱藏層維度。
-
L(Layers):模型Transformer層數。
-
param_bytes:啟用值儲存的精度一般為2位元組。
結合以上因素和實踐經驗,為簡化顯存估算,且留有一定餘量,以一個7B模型為例,當b為1,s為2048,param_bytes為2位元組時,啟用值所佔顯存可以大致按照10%的模型所佔顯存進行估算,即:
其他
除了以上影響因素外,當前批次的輸入資料、CUDA核心、PyTorch/TensorFlow深度學習架構本身等也會佔用一些顯存,通常為1~2GB。
根據以上因素分析,對於7B的大模型,通常情況下微調訓練大約需要的顯存為:
|
微調訓練方式 |
模型本身所需顯存 |
梯度所需顯存 |
Adam最佳化器狀態 |
啟用值 |
其他 |
總計 |
|
全參數微調 |
14GB |
14GB |
56GB |
1.4GB |
2GB |
87.4GB |
|
LoRA(低秩適配器) |
14GB |
0.14GB |
0.56GB |
1.4GB |
2GB |
18.1GB |
|
QLoRA(8-bit量化 + LoRA) |
7GB |
0.14GB |
0.56GB |
1.4GB |
2GB |
11.1GB |
|
QLoRA(4-bit量化 + LoRA) |
3.5GB |
0.14GB |
0.56GB |
1.4GB |
2GB |
7.6GB |
-
大模型通常採用Adam/AdamW最佳化器。
-
表中除了QLoRA模型本身採用4-bit或8-bit儲存,最佳化器狀態採用32-bit(4位元組)儲存外,其餘參數都採用16-bit(2位元組)儲存。
常見問題
Q:如何查看大模型參數量?
對於開源大模型,其參數量通常會標註在模型名稱上,如:Qwen-7B,其參數量為
Q:如何查看大模型的參數的精度?
如果未加特別說明,大模型通常採用16-bit(2位元組)儲存。對於量化的模型,其可能採用8-bit/4-bit儲存,詳細情況您可以查看其說明文檔,例如,如果您使用PAI Model Gallery中的模型,其詳情頁通常會介紹參數的精度:
千問2.5-7B-Instruct訓練說明:

Q:如何查看大模型微調訓練使用的最佳化器及狀態精度?
大模型訓練通常採用Adam/AdamW最佳化器,參數精度為32-bit(4位元組),更詳細的配置需要查看啟動命令或者代碼。
Q:如何查看顯存佔用?
您可以通過PAI-DSW、PAI-EAS、PAI-DLC的圖形監控頁面查看顯存佔用情況:
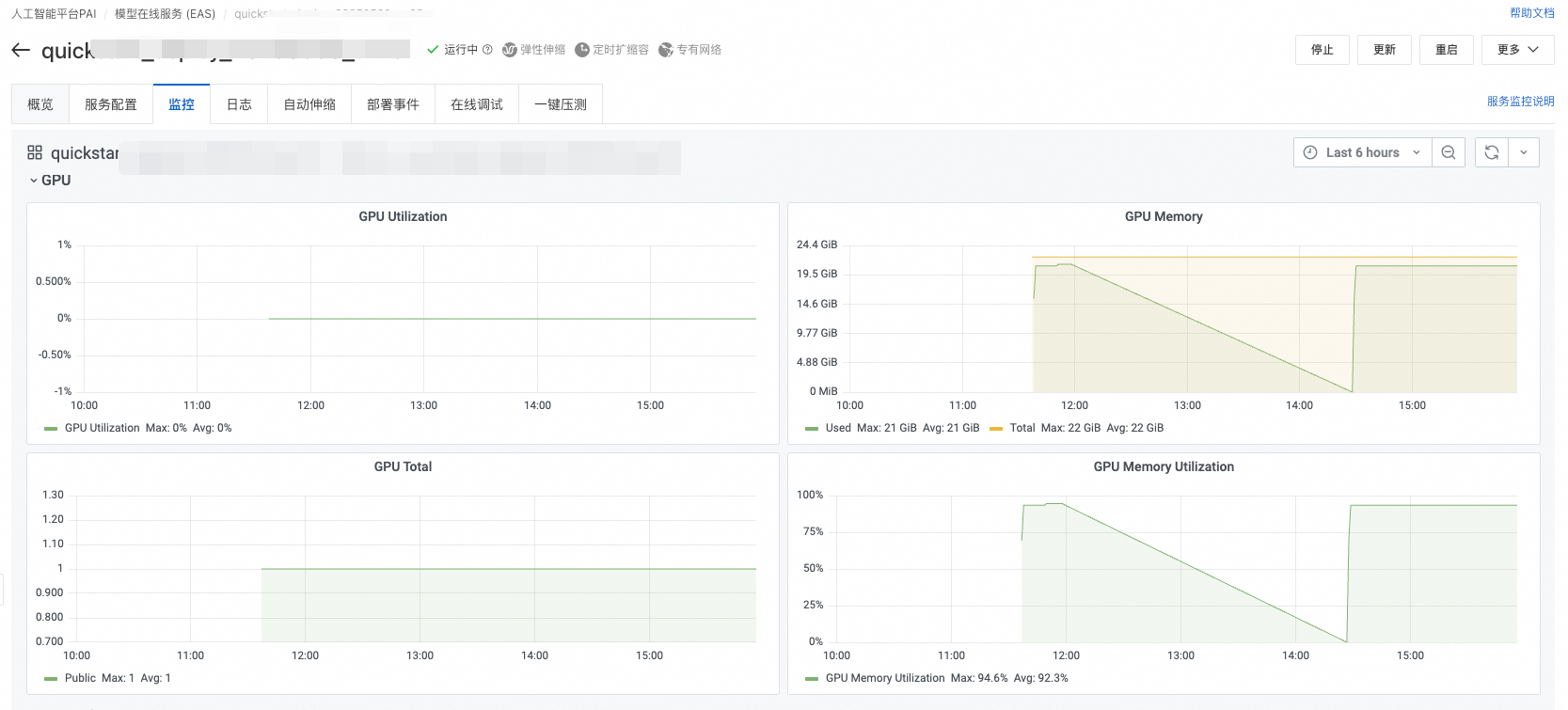
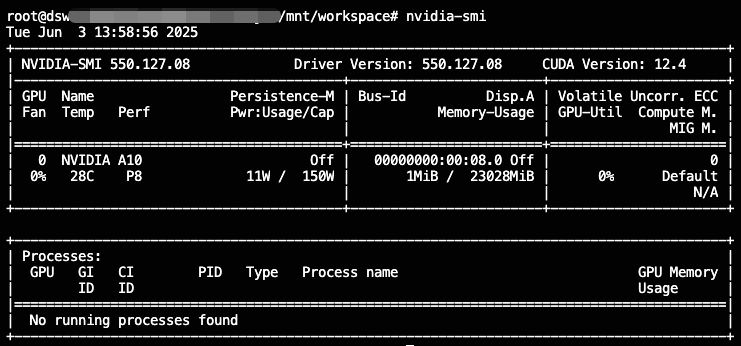
或者在容器的終端中執行nvidia-smi查看GPU使用方式:
Q:顯存不足的常見報錯有哪些?
使用NVIDIA GPU顯存不足時會報CUDA out of memory. Tried to allocate X GB的錯誤,此時您需要增大顯存,或者縮小批量大小(batch size)、序列長度等。