RAG(Retrieval-Augmented Generation,檢索增強產生)技術通過從外部知識庫檢索相關資訊,並將其與使用者輸入合并後傳入大語言模型(LLM),從而增強模型在私人領域知識問答方面的能力。EAS提供情境化部署方式,能快速構建與部署RAG對話系統,並支援靈活選擇大語言模型和向量檢索庫。本文為您介紹如何部署RAG對話系統服務以及如何進行模型推理驗證。
適用範圍
本文適用於RAG版本0.4.x。舊版本請參考PAI-RAG(v0.3.x)。
步驟一:部署RAG服務
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
在推理服务頁簽,單擊部署服务,然後在场景化模型部署地區,單擊大模型RAG对话系统部署。
在部署大模型RAG对话系统頁面,配置如下關鍵參數:
版本选择:選擇LLM分離式部署,僅部署RAG服務。灰度发布
說明LLM一體化部署會將RAG服務與大語言模型部署在同一個EAS服務執行個體中,如部署大模型需要較高的資源規格,建議在使用小模型的情況下選擇。
RAG版本:
pai-rag:0.4.3。资源信息:
资源类型:選擇公用資源。
部署资源:RAG服務本身資源消耗較低。建議選擇至少8核CPU和16 GB記憶體的規格,例如
ecs.c7.2xlarge或ecs.c7.4xlarge。
向量檢索庫設定:
版本类型:選擇FAISS(構建本地向量庫以便快速實踐)。生產環境建議使用其他成熟的向量檢索庫,配置方式請參見使用阿里雲向量資料庫。
OSS地址:選擇當前地區下已建立的OSS儲存目錄,用來儲存上傳的知識庫檔案。如果沒有可選的儲存路徑,您可以參考控制台快速入門進行建立。
專用網路:下文將需通過公網訪問阿里雲百鍊的模型服務。請在此處配置VPC,開通公網NAT Gateway並配置SNAT條目,詳情請參見讓EAS服務訪問公網。
參數配置完成後,單擊部署。服務部署時間長度通常約為5分鐘,當服务状态變為运行中時,表示服務部署成功。
步驟二:快速體驗知識庫問答
在推理服務頁簽找到已部署的RAG服務,進入服務詳情頁,單擊右上方的Web应用,進入WebUI頁面。

2.1 配置大語言模型
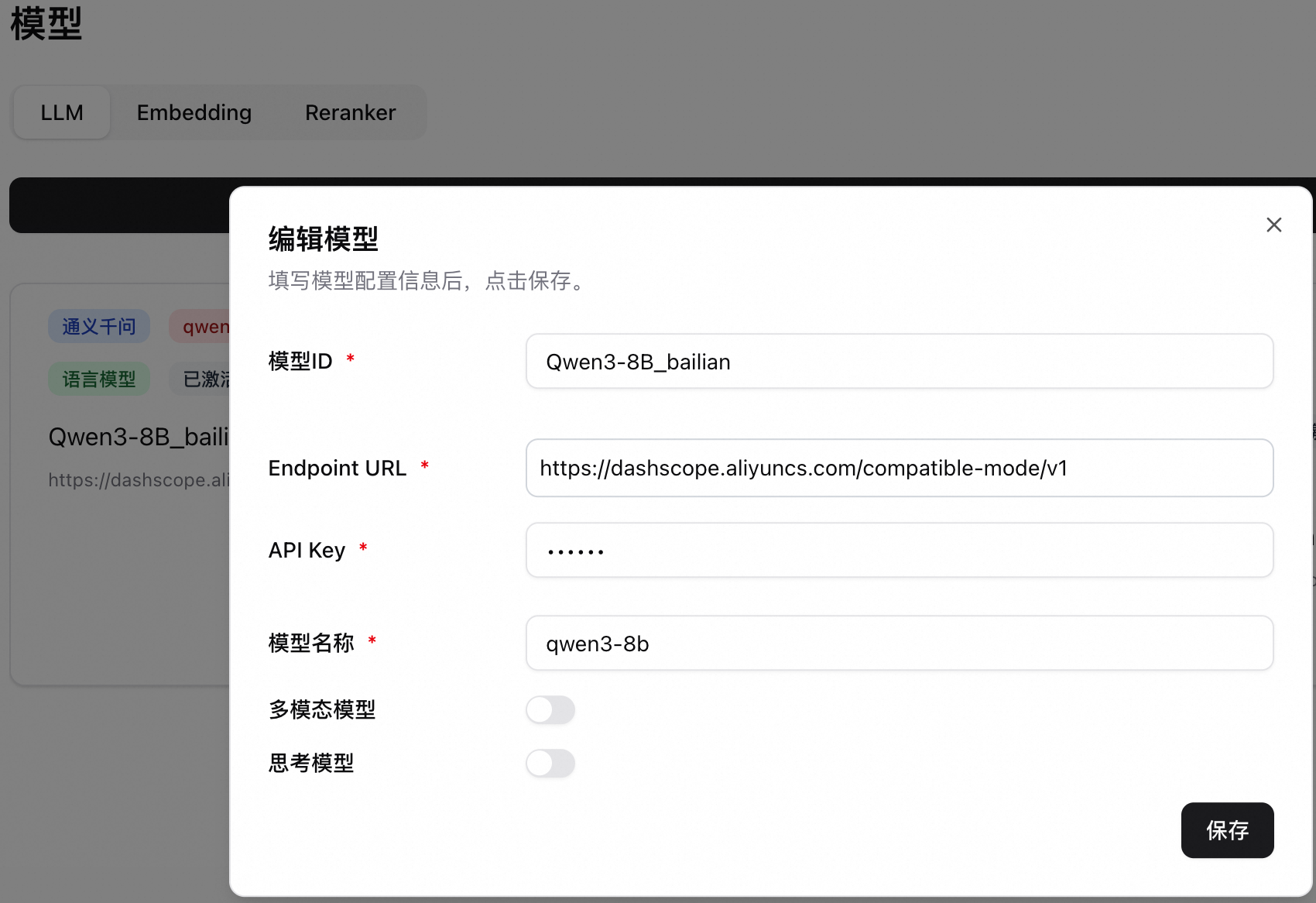
單擊左下角設定 > 模型,進入模型配置。這裡以配置百鍊qwen3-8b模型為例。更多模型配置說明參見配置模型。
阿里雲百鍊模型調用需單獨計費,請參見阿里雲百鍊計費項目說明。
調用百鍊模型需為RAG服務配置有公網訪問能力的專用網路。
模型ID:對話時用於選擇不同的模型。這裡填寫Qwen3-8B_bailian。
Endpoint URL:填寫模型服務地址。阿里雲百鍊北京地區模型服務地址為 https://dashscope.aliyuncs.com/compatible-mode/v1。
重要必須以
/v1、/v2形式結尾,如為EAS服務,請在服務調用地址後添加/v1。API Key:參見擷取API Key。
模型名稱:填寫qwen3-8b。
2.2 添加知識庫
系統已預設配置Embedding模型,可以直接建立知識庫並上傳文檔。
建立知識庫。單擊左側知識庫,進入知識庫頁面,選擇建立知識庫。
 以建立一個iPhone16技術規格介紹的知識庫為例,設定知識庫名稱為iPhone16,其他參數保持預設。
以建立一個iPhone16技術規格介紹的知識庫為例,設定知識庫名稱為iPhone16,其他參數保持預設。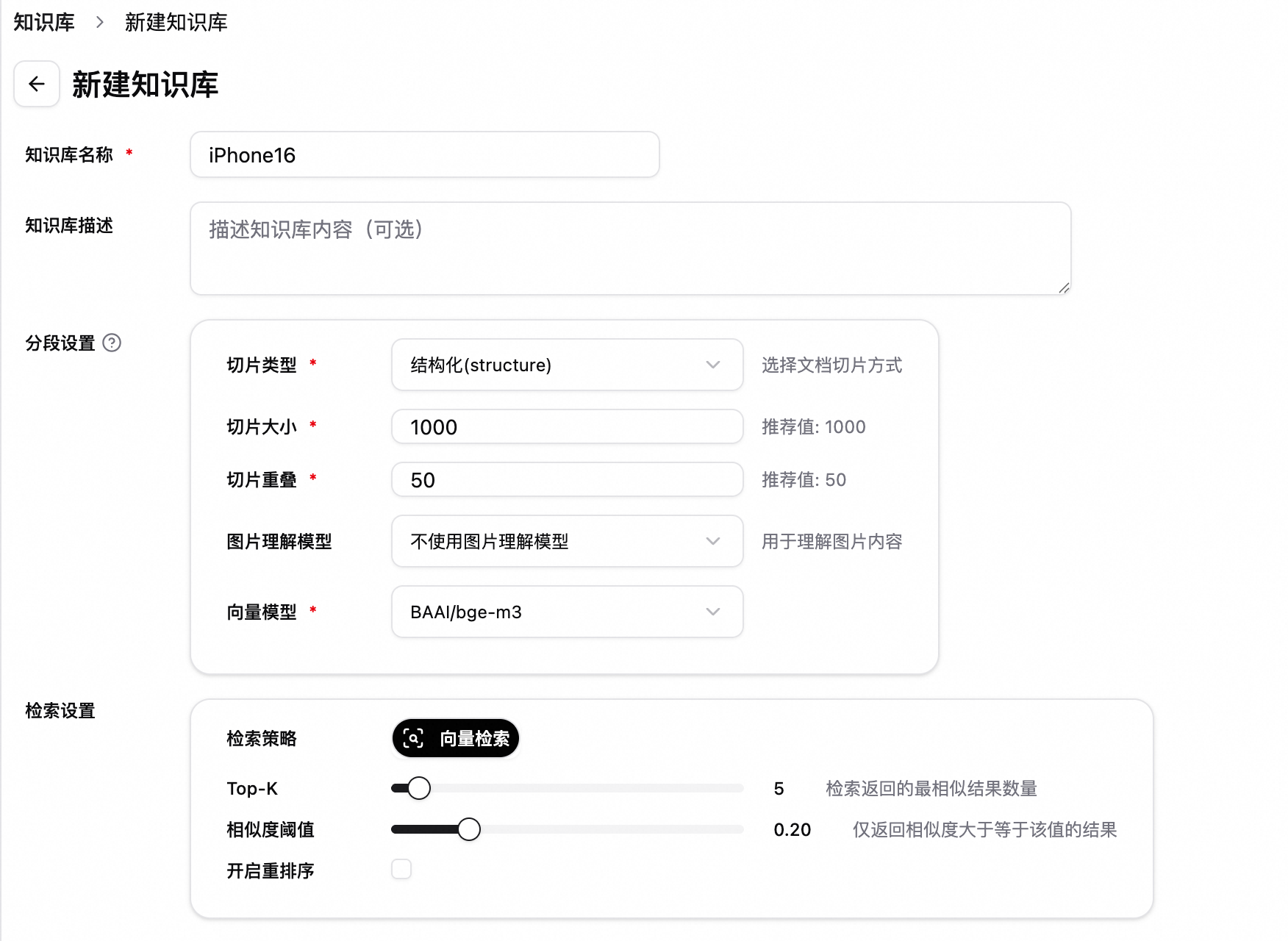
上傳檔案。在檔案管理頁簽,單擊上傳檔案。檔案上傳成功後,單擊開始解析。樣本檔案:iPhone 16 和 iPhone 16 Plus - 技術規格 - Apple (中國大陸).pdf。

查看知識庫檔案。上傳成功後,可單擊檔案名稱,查看文檔切片。
檢索測試。切換到檢索測試頁簽,輸入查詢內容(如
iPhone16),測試知識庫檢索。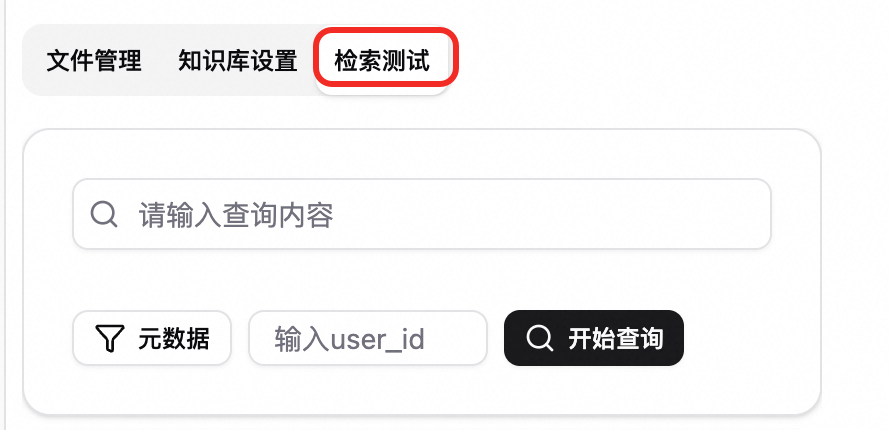
2.3 知識庫問答
單擊左側建立對話,在對話頁面上方選擇模型,下方單擊知識庫,選擇要使用的知識庫(如iphone16介紹)單擊啟用,然後儲存。
說明建議先對話測試模型配置成功,再啟用知識庫。
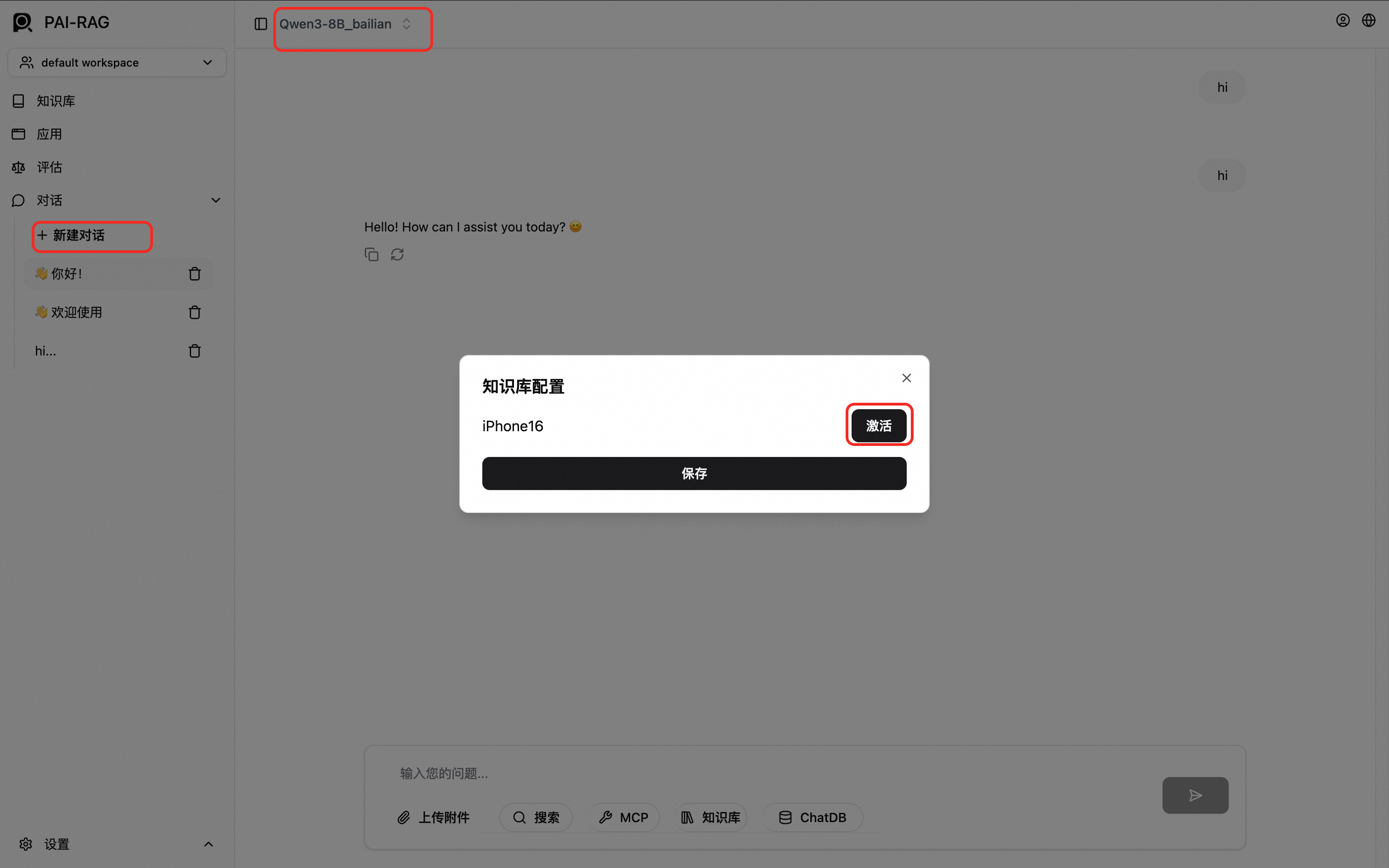
在對話方塊內輸入問題。

步驟三:更多問答模式體驗
多模態問答(圖文對話)
多模態問答需要為RAG服務配置OSS儲存資訊的環境變數用於儲存上傳的檔案和圖片,並使用多模態模型。
為RAG服務配置OSS儲存資訊的環境變數。情境化部署不支援直接設定環境變數,在部署服務頁面右上方選擇切换为自定义部署(已建立的服務可通過更新操作進入部署頁面),在环境信息地區增加如下環境變數:
FILE_STORE_TYPE:設定為oss。
OSS_BUCKET:填寫OSS BUCKET名稱。
說明FILE_STORE_TYPE設定為oss後,OSS_BUCKET下會自動產生
pairag_knowledgebases目錄,儲存上傳的知識庫檔案和對話中上傳的附件。不設定FILE_STORE_TYPE,預設會儲存在掛載的OSS目錄下。OSS_ENDPOINT:OSS訪問地址,請參見OSS地區和Endpoint。如
oss-cn-hangzhou.aliyuncs.com。OSS_ACCESS_KEY_ID、OSS_ACCESS_KEY_SECRET:擁有AliyunOSSFullAccess許可權的AK和SK。
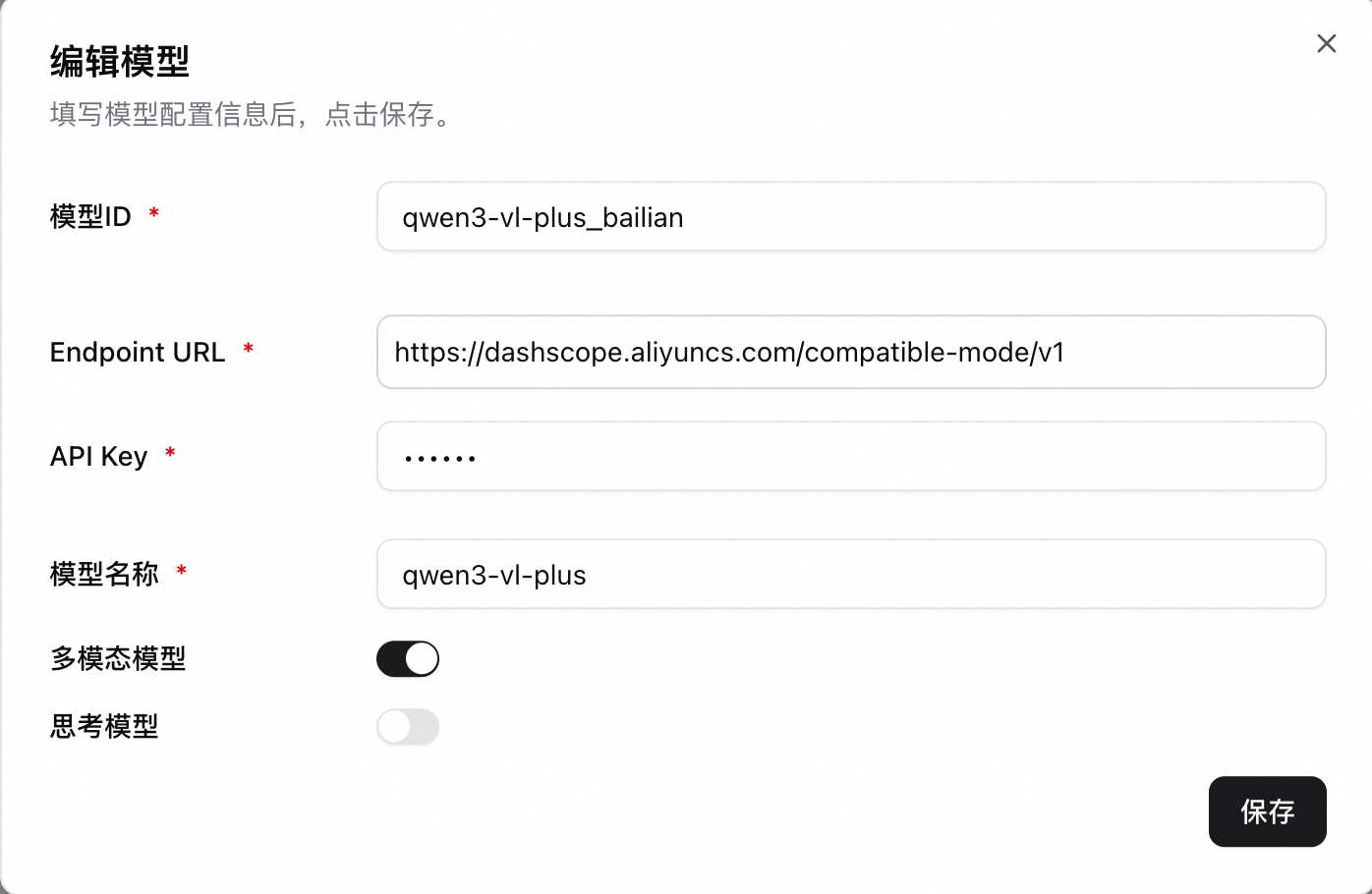
配置多模態大語言模型(如Qwen-VL系列)。以qwen3-vl-plus為例,配置如下,需開啟多模態模型開關。
對話樣本。

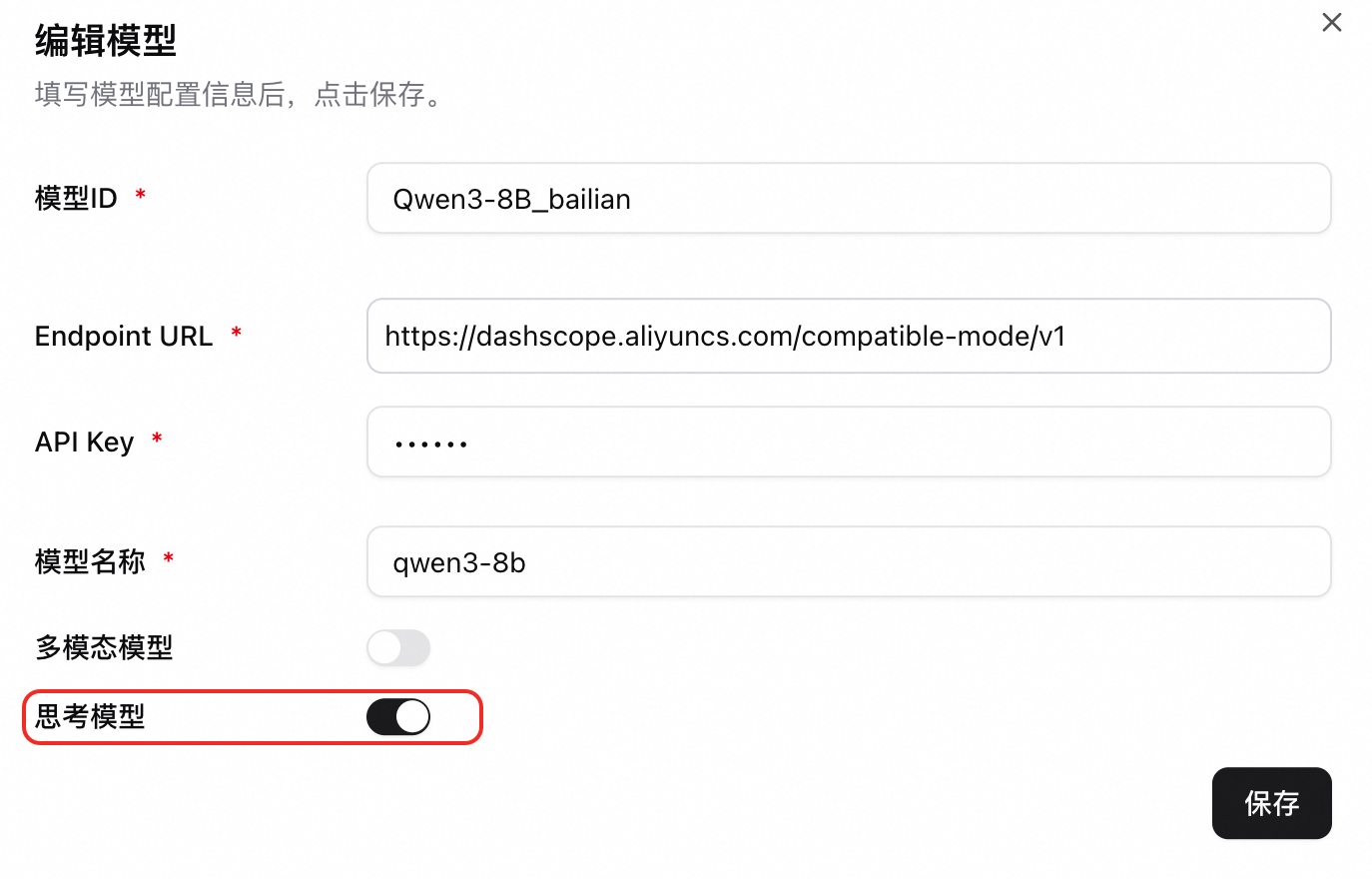
Agentic問答(MCP工具調用)
此模式利用模型思考和調用外部工具(如搜尋、地圖)的能力來回回覆雜問題。
使用樣本如下:

步驟四:評估RAG系統效能
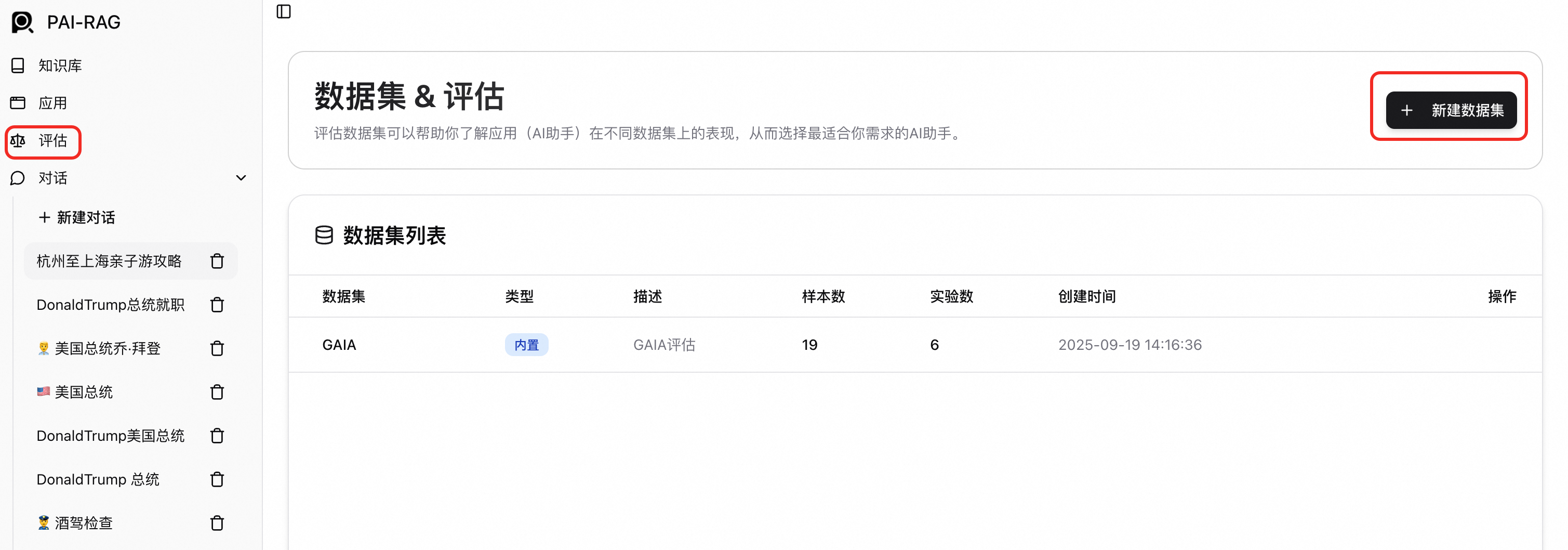
RAG系統內建了評估模組,協助您量化分析不同配置下的問答效果。以下是完整的評估流程:
建立資料集。單擊左側邊欄評估,進入評估頁面,選擇建立資料集。
匯入樣本。單擊建立好的資料集,進入評估任務。在樣本頁簽下,單擊匯入資料。
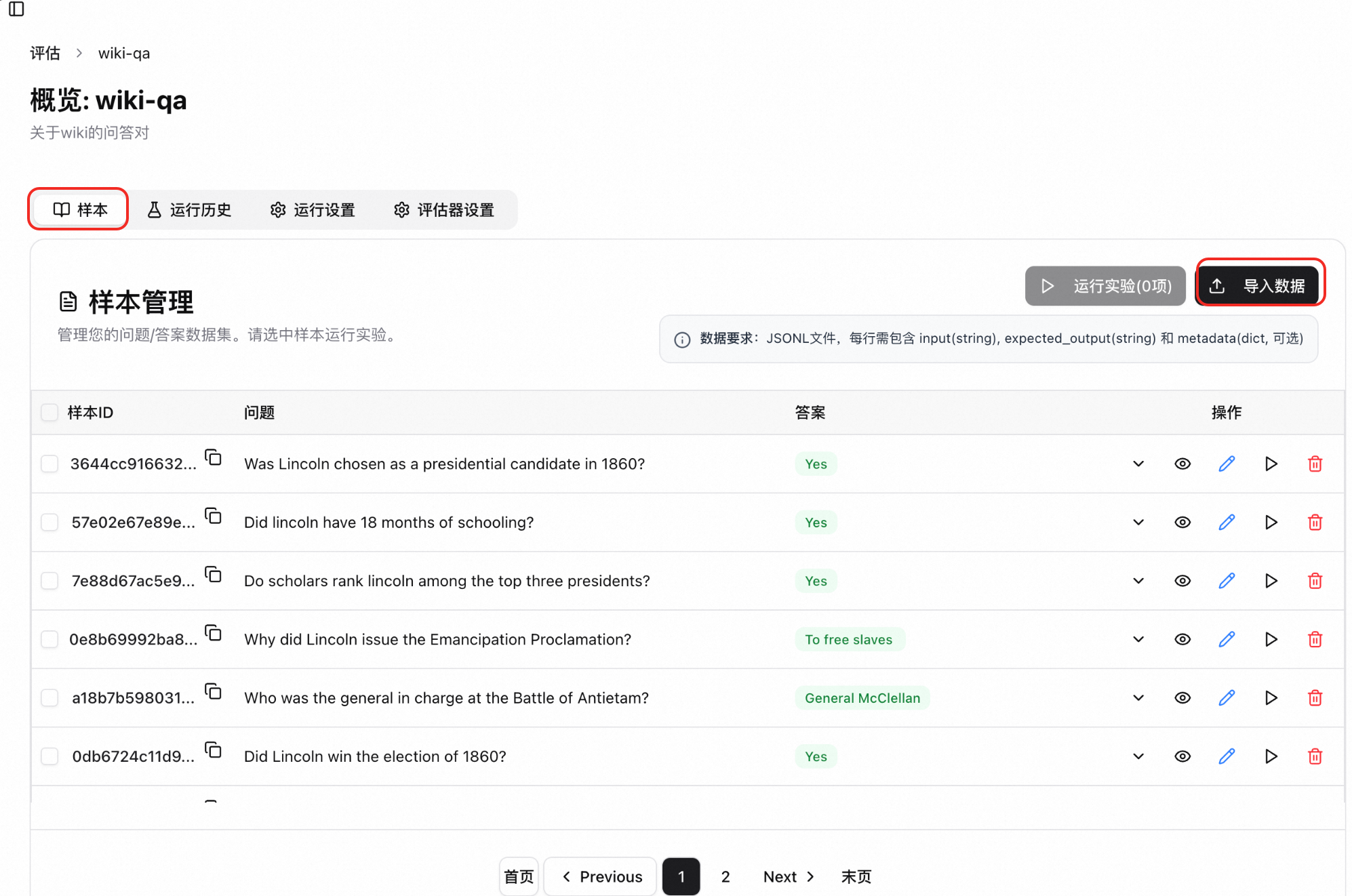
建立回合組態。在回合設定頁簽下,單擊建立配置,按需配置。

建立評估配置。在評估器設定頁簽下單擊建立配置,按需選擇配置和評估器類型。

運行評估實驗。在樣本頁簽,勾選要評估的樣本,單擊運行實驗,填寫實驗名稱,並按需選擇回合組態和評估配置。
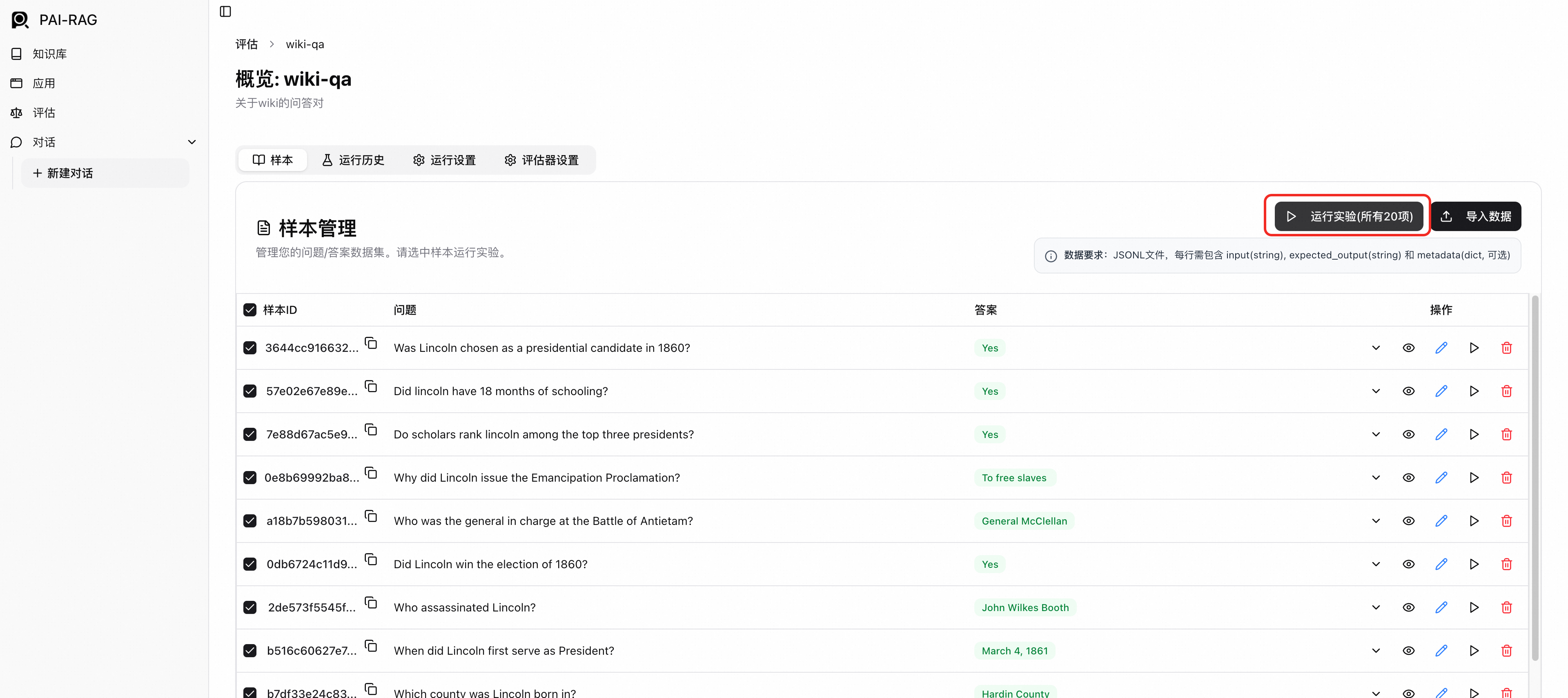
查看評估結果。建立實驗成功後,會自動跳轉到實驗詳情頁面。也可以直接切換到運行歷史頁簽,選擇目標實驗進入。

生產環境應用
使用阿里雲向量資料庫
PAI-RAG支援通過Elasticsearch、Hologres、OpenSearch或RDS PostgreSQL構建向量檢索庫。
Hologres、Elasticsearch、RDS PostgreSQL支援通過內網或公網訪問,推薦使用內網訪問。
OpenSearch只支援通過公網訪問。
Elasticsearch
準備Elasticsearch執行個體
如無Elasticsearch執行個體,請登入Elasticsearch控制台,參考如下配置建立。詳情請參見建立Elasticsearch執行個體。
地區和可用性區域:選擇與EAS服務相同的地區。
专有网络:選擇與EAS服務一致的VPC,以便通過內網訪問。
執行個體類型:選擇通用商業版。
情境初始化配置:選擇通用情境。
服務配置
務必設定Elasticsearch執行個體允許自動建立索引:在Elasticsearch執行個體的頁面,單擊修改配置,將自動建立索引設定為允許自動建立索引。具體操作,請參見配置YML參數。
版本类型:選擇Elasticsearch。
私网地址/端口:進入Elasticsearch執行個體詳情頁,在基本資料地區可擷取私網地址和連接埠,格式為
http://<私網地址>:<私網連接埠>。索引名称:系統會根據輸入執行不同操作。
輸入一個新名稱:EAS 將在部署時自動建立符合 PAI-RAG 要求的索引。
重要Elasticsearch預設不允許自動建立索引。在Elasticsearch執行個體的頁面,單擊修改配置,更新YML檔案配置,將自動建立索引設定為允許自動建立索引。具體操作,請參見配置YML參數。
輸入已存在的名稱:EAS 將直接使用該索引。請確保該索引由PAI-RAG服務建立,以保證結構相容。
账号、密码:配置建立Elasticsearch執行個體時配置的登入名稱和密碼。登入名稱預設為elastic。密碼如忘記,可重設執行個體訪問密碼。
OSS地址:請選擇當前地區下已建立的OSS儲存目錄。通過掛載OSS路徑實現知識庫管理員。
通過Kibana管理索引
Elasticsearch提供了索引管理功能,詳情請參見通過Kibana串連叢集。
Hologres
請確認已購買Hologres執行個體。
版本类型:選擇Hologres。
调用信息:配置為指定VPC的host資訊。進入Hologres管理主控台的執行個體詳情頁,在网络信息地區單擊指定VPC後的複製,擷取網域名稱
:80前的host資訊。数据库名称:配置為Hologres執行個體的資料庫名稱。如無,請參見建立資料庫。
账号:配置為已建立的自訂使用者帳號。具體操作,請參見建立自訂使用者,其中選擇成員角色選擇執行個體超級管理員(SuperUser)。
密码:配置為已建立的自訂使用者的密碼。
表名称:系統會根據輸入執行不同操作。
輸入一個新名稱:EAS 將在部署時會自動建立符合 PAI-RAG 要求的表。
輸入已存在的名稱:EAS 將直接使用該表。請確保該表由PAI-RAG服務建立,以保證結構相容。
OSS地址:請選擇當前地區下已建立的OSS儲存目錄。通過掛載OSS路徑實現知識庫管理員。
OpenSearch
準備OpenSearch向量檢索版執行個體
如無OpenSearch執行個體,請登入OpenSearch控制台,參考如下配置建立。詳情請參見購買OpenSearch向量檢索版執行個體。
商品版本:選擇向量檢索版。
地區和可用性區域、專用網路:OpenSearch只支援通過公網訪問,無需與EAS服務一致。
服務配置
版本类型:選擇OpenSearch。
访问地址:配置為OpenSearch向量檢索版執行個體的公網訪問地址。
說明需為OpenSearch向量檢索版執行個體開通公網訪問功能,並將EAS公網IP地址添加為白名單。
实例id:在OpenSearch向量檢索版執行個體列表中擷取執行個體ID。
用户名、密码:配置為建立OpenSearch向量檢索版執行個體時,輸入的使用者名稱和密碼。
表名称:需先建立滿足要求的索引表。參見配置執行個體建立,關鍵參數如下:
情境模板選擇通用模板,欄位配置匯入如下設定檔。
索引結構中,向量維度要與知識庫向量模型使用的向量維度保持一致,距離類型建議選擇InnerProduct。
管理索引表與資料
登入阿里雲OpenSearch向量檢索版控制台,單擊已建立的執行個體ID,進入執行個體詳情頁面。
進入表管理頁面,對索引表進行管理操作。詳情請參見表管理。
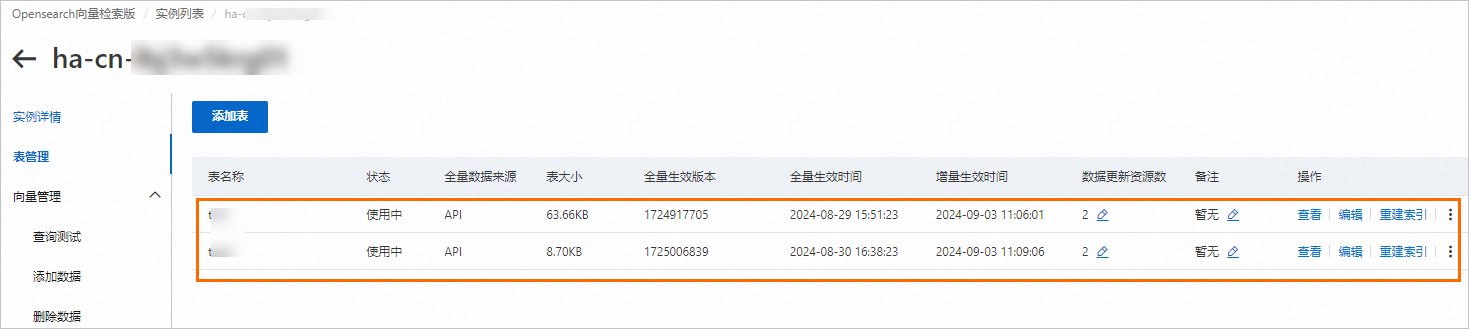
進入向量管理頁面,進行查詢測試、添加或刪除資料。詳情請參見向量管理。
RDS PostgreSQL
準備RDS PostgreSQL執行個體
如無RDS PostgreSQL執行個體,點此開啟RDS執行個體建立頁面,配置如下關鍵參數後,按照控制台操作指引完成支付和開通操作。詳情請參見建立RDS PostgreSQL執行個體。
引擎:選擇PostgreSQL。
VPC:選擇與EAS服務一致的VPC,以便通過內網訪問。
高許可權帳號:在更多配置地區,配置高許可權帳號。選擇立即設定,並設定資料庫帳號和密碼。
建立資料庫。
單擊已建立的執行個體名稱,在左側導覽列單擊資料庫管理,並單擊建立資料庫。
在建立資料庫配置面板中,配置資料庫(DB)名稱,授權帳號選擇已建立的高許可權帳號,其他參數配置說明,請參見建立帳號和資料庫。
參數配置完成後,單擊创建。
服務配置
請確認已建立RDS PostgreSQL執行個體。
版本类型:選擇RDS PostgreSQL。
主机地址:配置為RDS PostgreSQL執行個體的內網地址,您可以前往雲資料庫RDS PostgreSQL控制台頁面,在RDS PostgreSQL執行個體的資料庫連接頁面進行查看。
端口:預設為5432,請根據實際情況填寫。
数据库:資料庫的授權帳號需為高許可權帳號,操作請參見建立帳號和資料庫。同時需為資料庫安裝外掛程式vector和jieba。
表名称:自訂設定資料庫表名稱。
账号、密码:配置為建立資料庫時的授權帳號和密碼。如何建立高許可權帳號,請參見建立帳號和資料庫,其中帳號類型選擇高許可權帳號。
OSS地址:請選擇當前地區下已建立的OSS儲存目錄。通過掛載OSS路徑實現知識庫管理員。
RDS PostgreSQL資料庫管理
訪問RDS執行個體列表,切換到執行個體所在地區,然後單擊執行個體名稱,進入執行個體詳情頁面。
在左側導覽列選擇資料庫管理,然後單擊目標資料庫操作列下的SQL查詢。
輸入資料庫帳號和資料庫密碼,即您在建立RDS PostgreSQL時設定的高許可權帳號和密碼,然後單擊登录。
登入成功後,在已登入資料庫執行個體中查詢匯入的知識庫列表。
