本文為您介紹如何使用DLC提供的基於AIMaster的容錯監控功能。
背景資訊
深度學習廣泛使用,隨著模型和資料規模增大,常採用分布式方式運行。當任務執行個體增多時,軟體棧和硬體環境可能出現異常,導致任務停止。
為保障大規模分布式深度學習任務穩定運行,DLC提供了基於AIMaster的容錯監控功能。AIMaster是任務層級組件,開啟後會啟動一個AIMaster執行個體與任務其他執行個體一起運行,起到任務監控、容錯判斷和資源控制的作用。
使用限制
目前AIMaster支援以下架構:PyTorch、MPI、TensorFlow、ElasticBatch。
步驟一:配置容錯監控參數
以下是容錯監控功能的全量參數說明,您可以參考常用參數配置樣本,提前規劃任務的容錯監控內容。後續開啟容錯監控功能時,可以根據需求設定到容錯監控的其他配置處。
全量參數說明
配置分類 | 功能介紹 | 配置參數 | 參數說明 | 預設值 |
通用配置 | 任務運行類型 | --job-execution-mode | 配置任務運行類型,取值如下:
不同任務類型容錯行為不同。對於可重試錯誤:
| Sync |
任務重啟設定 | --enable-job-restart | 在滿足容錯條件或檢測到運行時異常時,是否允許任務重啟。取值如下:
| False | |
--max-num-of-job-restart | 配置任務最大重啟次數。超過最大重啟次數後,會將任務標記為失敗。 | 3 | ||
運行時配置 說明 針對沒有執行個體運行失敗的情境。 | 任務Hang(掛起)異常檢測 | --enable-job-hang-detection | 是否開啟任務運行時的Hang異常檢測,只支援同步任務。取值如下:
| False |
--job-hang-interval | 配置任務暫停執行的持續時間長度,正整數,單位為秒。 當任務停止時間長度超過該值時,則將任務標記為異常,並觸發任務重啟。 | 1800 | ||
| 是否開啟C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis)檢測功能,用於快速診斷並定位任務執行過程中出現的慢速節點和導致任務Hang(掛起)的故障節點。 說明 該參數僅在同時開啟 | False | ||
任務退出時Hang(掛起)異常檢測 | --enable-job-exit-hang-detection | 是否開啟任務快要結束退出時的Hang異常檢測,只支援同步任務。取值如下:
| False | |
--job-exit-hang-interval | 配置任務退出時停止執行的持續時間長度,正整數,單位為秒。 當任務退出時間長度超過該值時,則將任務標記為異常,並觸發任務重啟。 | 600 | ||
容錯配置 說明 針對有執行個體運行失敗的情境。 | 容錯策略 | --fault-tolerant-policy | 容錯策略參數取值如下:
| ExitCodeAndErrorMsg |
相同錯誤最大允許出現次數 | --max-num-of-same-error | 配置單個執行個體上同一錯誤允許出現的最大次數。 當錯誤出現次數超過該值時,直接將任務標記為失敗。 | 10 | |
最大容錯率 | --max-tolerated-failure-rate | 設定最大容錯率,當失敗執行個體的比例超過該值時,job直接標記失敗。 預設值-1表示該功能預設不開啟。樣本:設定0.3表示30%以上的worker出現錯誤後,job可以直接標記為失敗。 | -1 |
常用參數配置樣本
針對不同的訓練任務,常用的容錯監控參數配置樣本如下。
同步訓練任務(常見於PyTorch任務)
當執行個體異常且滿足容錯條件時,重啟任務。
--job-execution-mode=Sync --enable-job-restart=True --max-num-of-job-restart=3 --fault-tolerant-policy=ExitCodeAndErrorMsg非同步訓練任務(常見於TensorFlow任務)
對於可重試的錯誤,重啟異常的Worker執行個體。PS或Chief執行個體出錯時,預設不重啟任務,如需重啟可設定--enable-job-restart=True。
--job-execution-mode=Async --fault-tolerant-policy=OnFailure離線推理任務(常見於ElasticBatch任務)
執行個體之間無依賴關係,相當於非同步任務。當執行個體運行異常時,只會重啟異常的執行個體。
--job-execution-mode=Async --fault-tolerant-policy=OnFailure
步驟二:開啟容錯監控功能
您可以在提交DLC訓練任務時,通過控制台或SDK的方式開啟容錯監控功能。
通過控制台開啟容錯監控功能
在控制台提交DLC訓練任務時,您可以在容错与诊断地區,開啟自动容错開關,並配置額外參數,詳情請參見建立訓練任務。這樣DLC任務在運行過程中會額外啟動一個AIMaster角色,進行全程監控,並在遇到錯誤時進行容錯處理。

其中:
支援在其他配置文字框中配置額外參數,參數配置說明請參見步驟一:配置容錯監控參數。
啟用任務掛起檢測後,可開啟C4D检测功能。C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis)是阿里雲自研的,專門針對大模型訓練中任務Slow(慢)或任務Hang(掛起)的問題診斷工具,協助定位大模型訓練中的問題。詳情請參見使用C4D。
說明C4D依賴阿里雲自研高效能集合通訊庫ACCL,請確保ACCL已安裝,詳情請參見ACCL:阿里雲高效能集合通訊庫。
目前,DLC任務選擇靈駿智算資源時,可以使用C4D檢測功能。
啟動任務掛起檢測後,可以使用任務函數調用棧分析工具來協助定位任務具體Hang(掛起)在了哪一行代碼,需要針對“任務掛起(Hang)檢測閾值”做專門的配置,詳情請參見“使用函數調用棧快照分析工具”
通過DLC SDK開啟容錯監控功能
使用GO SDK
通過GO SDK提交任務時開啟容錯開關。
createJobRequest := &client.CreateJobRequest{} settings := &client.JobSettings{ EnableErrorMonitoringInAIMaster: tea.Bool(true), ErrorMonitoringArgs: tea.String("--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=3600"), } createJobRequest.SetSettings(settings)其中:
EnableErrorMonitoringInAIMaster:表示是否開啟容錯監控功能。
ErrorMonitoringArgs:表示容錯監控額外參數。
使用Python SDK
通過Python SDK提交任務時開啟容錯開關。
from alibabacloud_pai_dlc20201203.models import CreateJobRequest, JobSettings settings = JobSettings( enable_error_monitoring_in_aimaster = True, error_monitoring_args = "--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=30" ) create_job_req = CreateJobRequest( ... settings = settings, )其中:
enable_error_monitoring_in_aimaster:表示是否開啟容錯監控功能。
error_monitoring_args:表示容錯監控額外參數。
步驟三:配置容錯監控增強功能
您可以根據任務的容錯監控需求情境,選擇使用以下容錯監控增強功能。
配置容錯訊息通知
任務開啟容錯監控後,如果您希望容錯發生時進行通知,可以在工作空间详情,選擇工作空间配置 > 事件通知配置,然後單擊新建事件规则,並選擇事件類型為DLC任务 > 任务自动容错。具體操作,請參見工作空間事件中心。
當任務訓練出現異常時,比如loss出現Nan,可以在代碼中使用AIMaster SDK發送自訂通知訊息:
本功能需要安裝AIMaster whl包,詳情請參見常見問題集。
from aimaster import job_monitor as jm
job_monitor_client = jm.Monitor(config=jm.PyTorchConfig())
...
if loss == Nan and rank == 0:
st = job_monitor_client.send_custom_message(content="任務訓練loss出現Nan")
if not st.ok():
print('failed to send message, error %s' % st.to_string())配置自訂容錯關鍵字
容錯監控功能已內建了常見的可重試錯誤的監控模組,如果您希望任務異常執行個體日誌中出現某些關鍵字時也進行容錯,可以在代碼中使用以下方法進行配置。配置完成後,容錯監控模組會掃描失敗的執行個體尾部日誌進行關鍵資訊匹配。
容錯策略需要配置為ExitCodeAndErrorMsg。
PyTorch任務自訂容錯關鍵字配置樣本
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.PyTorchConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])其中:monitor.set_retryable_errors中配置的參數即為自訂容錯關鍵字。
TF任務自訂容錯關鍵字配置樣本
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.TFConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])
分階段自訂任務Hang異常檢測
目前任務Hang異常檢測的配置是針對整個任務的,但是任務狀態是分階段的。例如:在任務初始化階段,各個節點建立通訊可能耗時比較長,但訓練階段日誌更新比較快。為了在訓練過程中能快速發現任務Hang異常的節點,DLC提供了分階段自訂任務Hang異常檢測功能,支援您在不同訓練階段配置不同的任務Hang異常檢測時間長度,具體配置方法如下。
monitor.reset_config(jm_config_params)
# Example:
# monitor.reset_config(job_hang_interval=10)
# or
# config_params = {"job_hang_interval": 10, }
# monitor.reset_config(**config_params)PyTorch任務分階段自訂任務Hang異常檢測樣本如下。
import torch
import torch.distributed as dist
from aimaster import job_monitor as jm
jm_config_params = {
"job_hang_interval": 1800 # 全域30min檢測。
}
jm_config = jm.PyTorchConfig(**jm_config_params)
monitor = jm.Monitor(config=jm_config)
dist.init_process_group('nccl')
...
# impl these two funcs in aimaster sdk
# user just need to add annotations to their func
def reset_hang_detect(hang_seconds):
jm_config_params = {
"job_hang_interval": hang_seconds
}
monitor.reset_config(**jm_config_params)
def hang_detect(interval):
reset_hang_detect(interval)
...
@hang_detect(180) # reset hang detect to 3 min, only for func scope
def train():
...
@hang_detect(-1) # disable hang detect temporarily, only for func scope
def test():
...
for epoch in range(0, 100):
train(epoch)
test(epoch)
self.scheduler.step()
使用C4D
C4D(Calibrating Collective Communication over Converged ethernet - Diagnosis),是阿里雲自研的用於大模型訓練中診斷任務Slow(慢)或Hang(掛起)問題的工具。使用C4D需要依賴阿里雲自研的高效能集合通訊庫ACCL,請確保ACCL已安裝並正確配置了環境變數,詳情請參見ACCL:阿里雲高效能集合通訊庫。目前,DLC任務選擇靈駿智算資源時,可以使用C4D檢測功能。
功能介紹
C4D通過匯總任務內所有節點的狀態資訊,分析判斷是否有節點出現通訊或非通訊層面的問題。系統架構如下圖所示:
全量參數說明
開啟C4D檢測功能後,在其他配置文字框中支援配置的參數如下:
參數 | 描述 | 樣本值 |
--c4d-log-level | 設定C4D輸出記錄層級,取值如下:
預設值為Warning,表示會輸出Warning和Error層級的日誌。建議在正常運行情況下使用預設值。若需排查效能問題,則可將其設定為Info層級。 |
|
--c4d-common-envs | 設定C4D執行的環境變數,格式為
|
|
當前針對Error層級的日誌,AIMaster會自動化隔離對應節點並重新拉起任務。各層級Tlog邏輯如下:
錯誤等級 | 錯誤描述 | 處理動作 |
Error | 預設情況下,如果通訊層面Hang(掛起)時間超過三分鐘,則會導致任務失敗。您可以通過配置C4D_HANG_TIMEOUT和C4D_HANG_TIMES兩個參數來修改預設值。 | AIMaster會直接自動化隔離日誌中的節點。 |
Warn | 預設情況下,如果通訊層面Hang(掛起)時間超過10秒,雖然影響效能,但不會導致任務失敗。您可以通過配置C4D_HANG_TIMEOUT參數來修改預設值。 | 暫時不會自動化隔離日誌中的節點,需要人工二次確認。 |
非通訊層面Hang(掛起)時間超過10秒,有可能會導致任務失敗。 | 暫時不會自動化隔離日誌中的節點,需要人工二次確認。 | |
Info | 通訊層面慢和非通訊層面慢。 | 這部分診斷記錄主要是針對效能問題,需要人工二次確認。 |
在DLC任務運行過程中,如果發現任務Slow(慢)或Hang(掛起)的情況,您可以在DLC工作清單中,單擊任務名稱,進入任務概覽頁面。在下方的執行個體地區,查看任務的AIMaster節點日誌,即可看到C4D的診斷結果。關於診斷結果詳情,請參見診斷結果範例。
診斷結果範例
RankCommHang:表示有節點出現了通訊層面Hang(掛起)的問題。

RankNonCommHang:表示有節點出現了非通訊層面Hang(掛起)的問題,例如計算部分出現了Hang(掛起)。

RankCommSlow:表示有節點出現了通訊層面慢的問題。
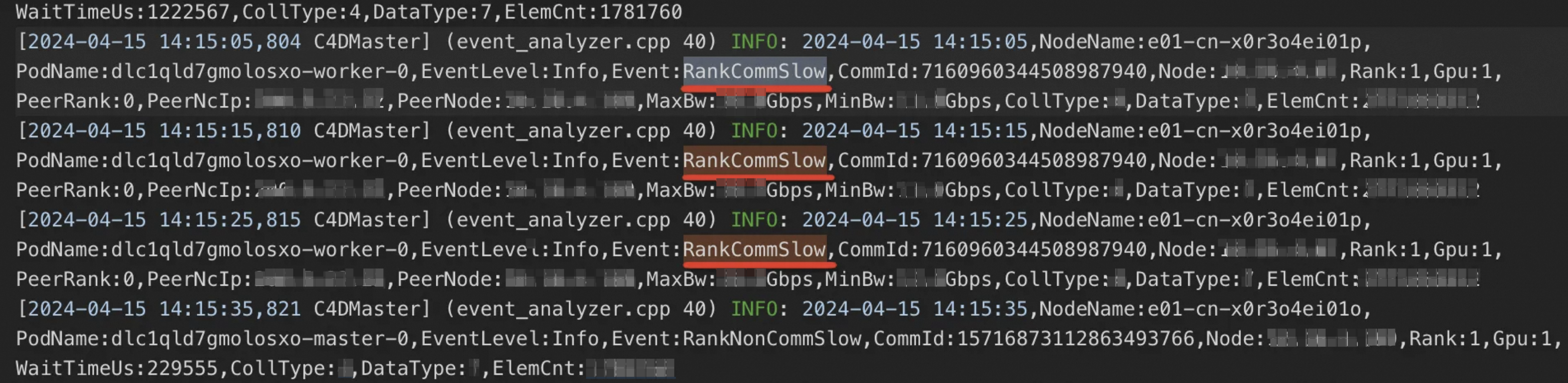
RankNonCommSlow:表示有節點出現了非通訊層面慢的問題。

使用函數調用棧快照分析工具
大模型訓練任務常見的故障類型之一就是任務有時會Hang(掛起),其中很常見的一種類型是NCCL Hang,此時任務失敗的時候會列印“Watchdog caught collective operation timeout”這類日誌,針對這類常見的問題,我們開發了模型任務函數調用棧快照分析工具,來協助使用者快速定位任務Hang的根因,具體使用步驟如下:
步驟一:安裝pystack或者py-spy
使用者需要先確認自己使用的容器鏡像中是否已安裝pystack或者py-spy工具,如果沒有則需要事先安裝下,下面是安裝pystack工具的命令範例:
pip install pystack -i https://mirrors.cloud.aliyuncs.com/pypi/simple/ --trusted-host mirrors.cloud.aliyuncs.com步驟二:開啟自動容錯功能中的Hang檢測開關
開啟方法請參見通過控制台開啟容錯監控功能,開啟“任務掛起(Hang)檢測”開關之後,還需要對“任務掛起(Hang)檢測閾值”部分的時間配置一個合適的值,才能正常使用函數調用棧快照分析工具,需要先確認下自己模型任務的逾時時間是多少,這個逾時時間一般可以在任務Hang(掛起)之後報錯的日誌中看到,下面是一個範例:
Watchdog caught collective operation timeout: WorkNCCL(SeqNum=2143, OpType=ALLREDUCE, NumelIn=659, NumelOut=659, Timeout(ms)=600000) ran for 600535 milliseconds before timing out從這條報錯日誌的Timeout欄位,可以看出這個模型任務的逾時時間是600秒,也就是10分鐘,在這種情況下我們一般建議將“任務掛起(Hang)檢測閾值”配置為450秒,如果任務報錯日誌中的Timeout欄位是1800秒,則建議將“任務掛起(Hang)檢測閾值”配置為1500秒,原則就是盡量讓“任務掛起(Hang)檢測閾值”的取值比Timeout欄位的值小150~200秒左右。
按照前面說的步驟正確配置了Hang(掛起)檢測功能之後,在任務發生了Hang(掛起)之後,AIMaster就會自動觸發針對模型任務進程的函數調用棧的採集和分析,分析結果可以在AIMaster節點的日誌中看到, 下面是一個任務Hang(掛起)住之後工具輸出的函數調用棧分析結果範例:
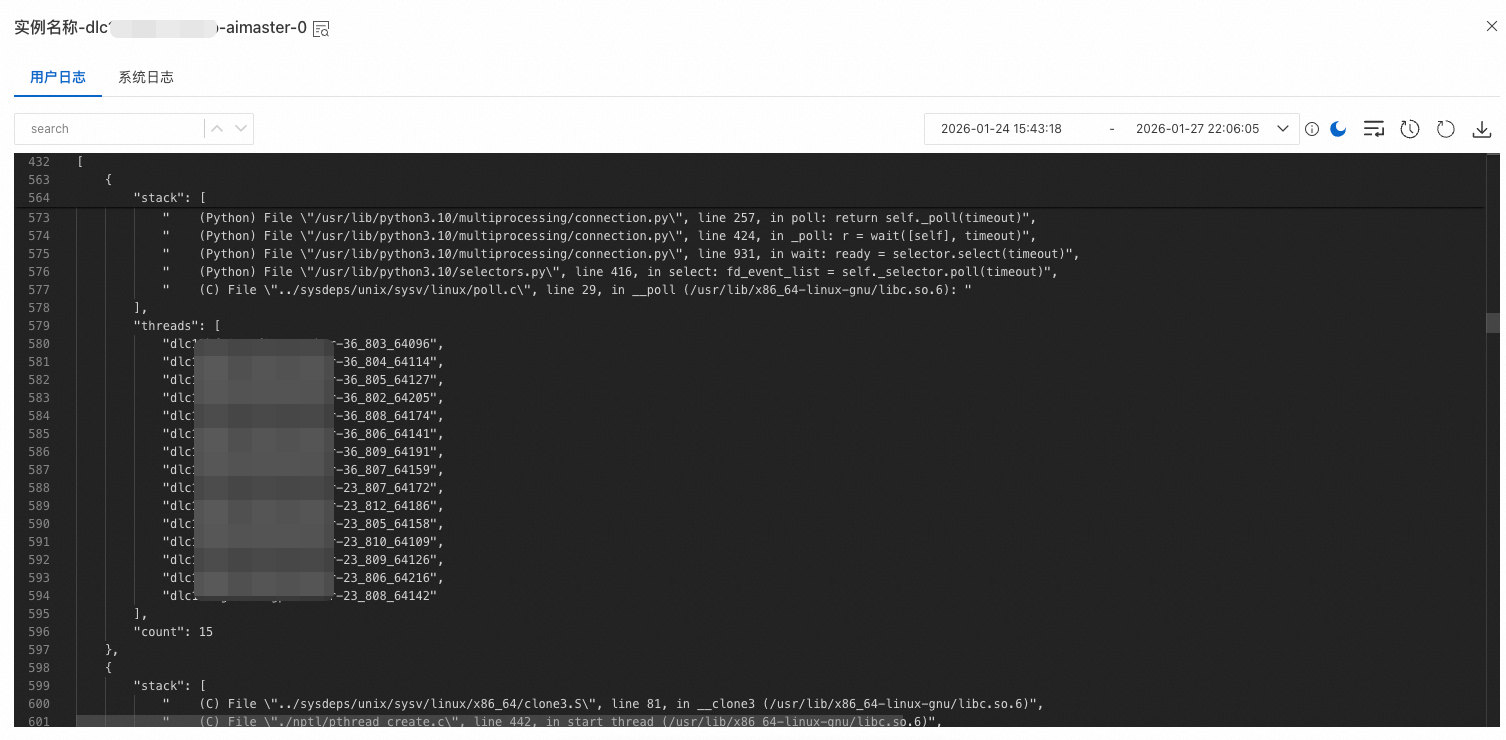
函數調用棧分析結果中的stack欄位代表具體的函數調用棧,threads欄位代表出現這些函數調用棧的線程是哪些,count欄位代表出現這個函數調用棧的線程數量,對於count為1的這些棧需要重點懷疑是其導致了任務出現了Hang(掛起)。
步驟四:查看重啟原因
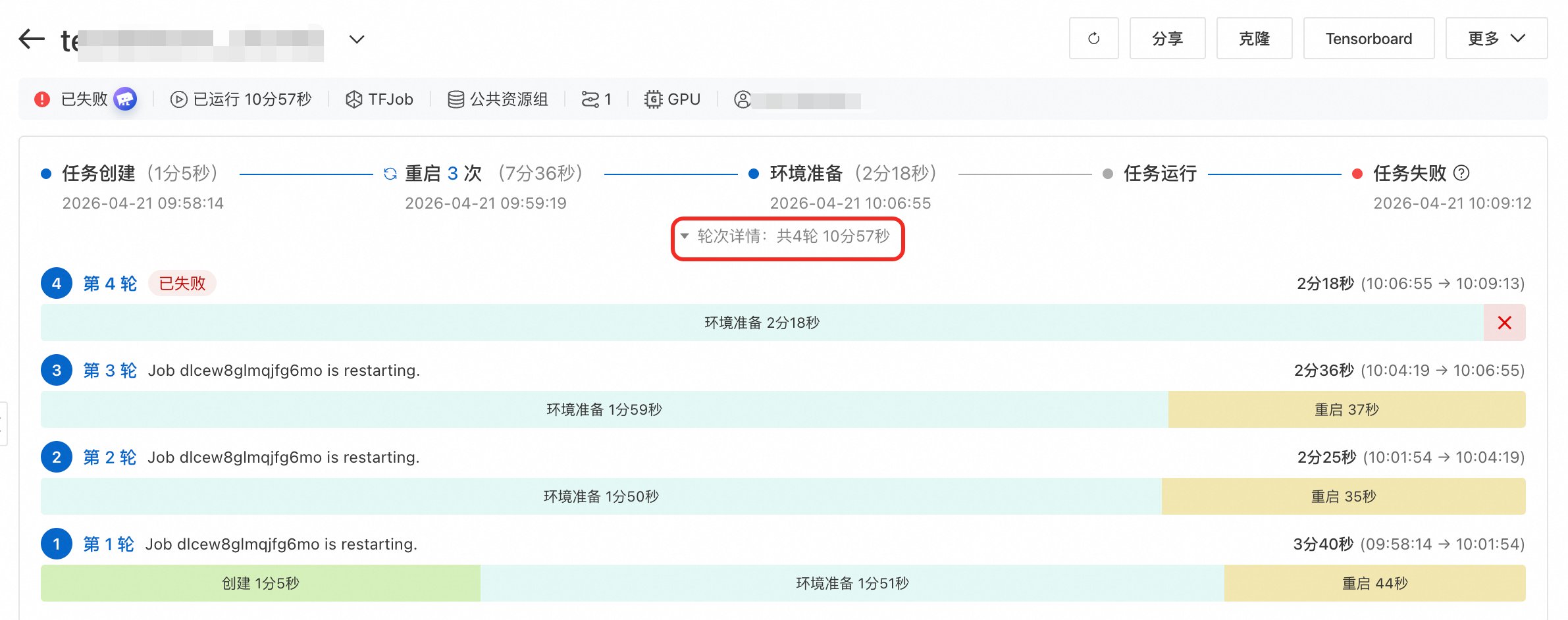
查看重啟輪次:任務重啟資訊按輪次進行劃分,您可以在任務詳情頁通過單擊展開輪次詳情,查看任務在各個階段耗費的時間長度等資訊,從而更精準地瞭解任務健全狀態。
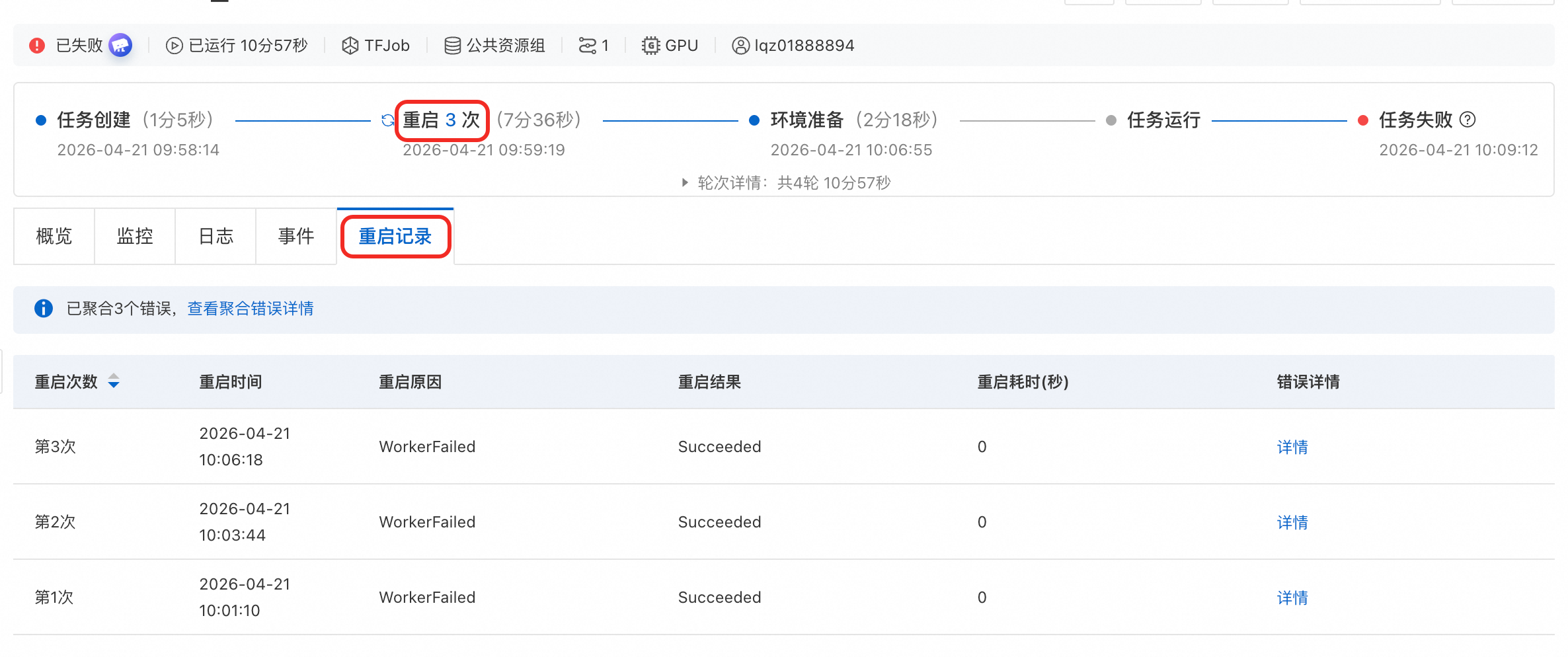
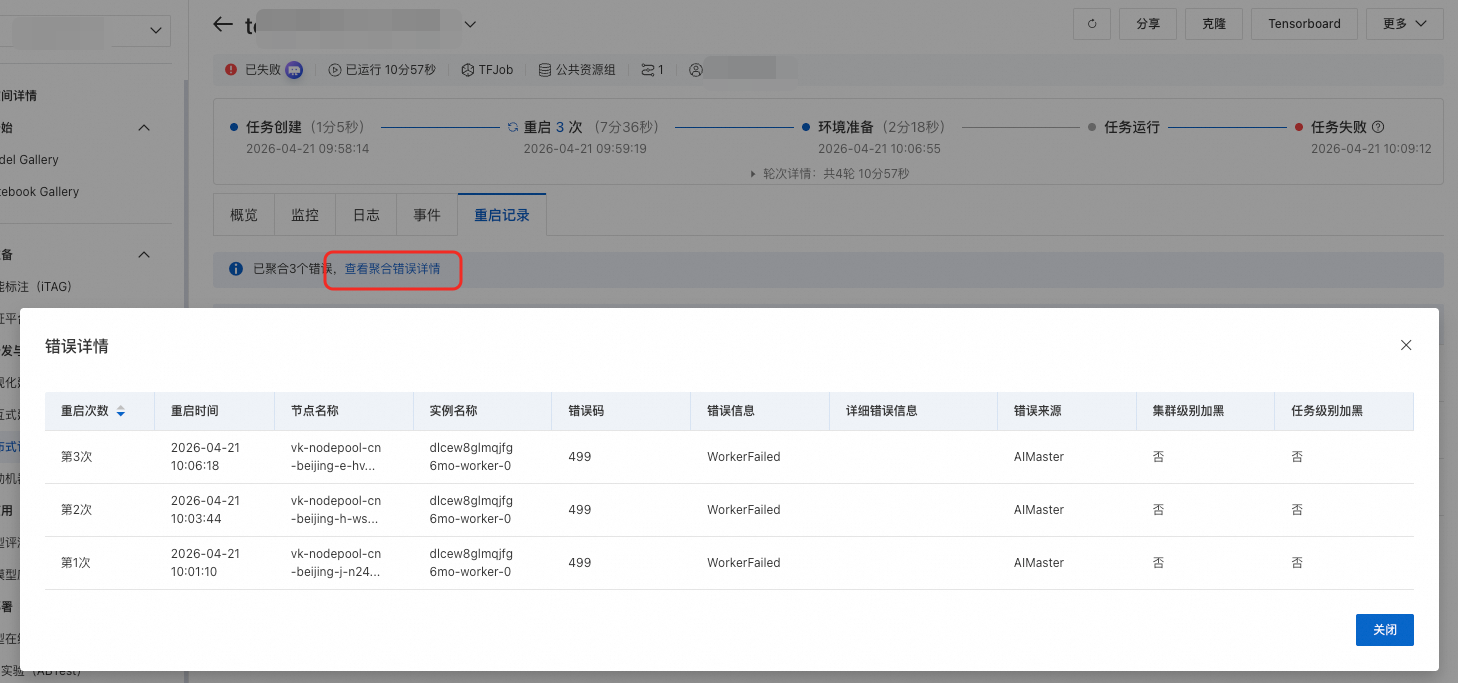
查看重啟記錄:您可以單擊重啟次數或直接單擊重启记录頁簽,查看相關重啟資訊,包括重啟原因、重啟結果、重啟耗時等。
具體操作如下:
在重启记录列表中,單擊详情可查看該次重啟的詳細資料,包含重启次数、重启时间、节点名称、实例名称、错误码、错误信息、错误来源等資訊。
單擊查看聚合错误详情可展開全部重啟記錄的詳情列表。
常見問題集
Q:如何安裝AIMaster SDK ?
根據您的Python版本,使用以下命令安裝對應的whl包。
# Python 3.6
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp36-cp36m-linux_x86_64.whl
# Python 3.8
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp38-cp38-linux_x86_64.whl
# Python 3.10
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp310-cp310-linux_x86_64.whl