本文介紹在使用阿里雲CloudMonitor產品監控OSS資料時遇到的一些常見問題及解決方案。
OSS將資料推送至CloudMonitor,CloudMonitor進行分析處理。OSS控制台上的儲存容量和頻寬流量監控資料來自CloudMonitor。
OSS資料推送到CloudMonitor會延遲2\~3小時,且單次推送間隔不能超過5分鐘,否則CloudMonitor會拒絕接收到期資料,也不支援補推。因此,不建議根據云監控的資料計算您的費用。如需核對費用,建議聯絡支援人員。
案例:警示規則的狀態出現“資料不足”
問題分析:此問題可以查看使用者概況的服務監控總覽內的資料。如果無資料產生,則會出現資料不足的情況。
案例:CloudMonitor上發現上傳下載延遲
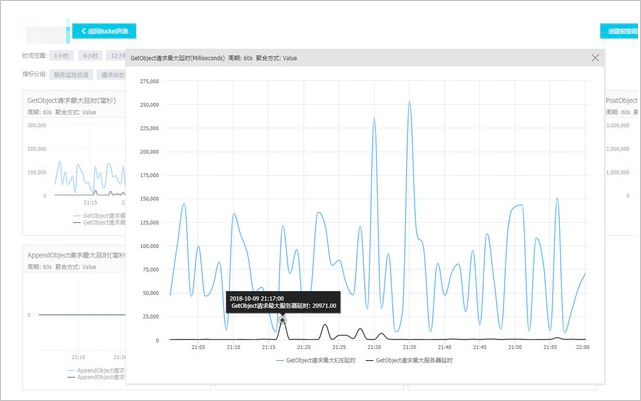
問題分析:CloudMonitor平台上查看到的資料是CloudMonitor產品節點發起探測請求獲得的資料,並不代表真實使用者環境。
解決方案:CloudMonitor平台監控到訪問延遲較大的情況,可通過如下步驟排查:
確認用戶端訪問是否真的有延遲。
若使用者訪問對應的Bucket也出現延遲的情況,需通過抓包擷取訪問資料分析。
您也可以通過日誌分析對應時間內的訪問資料,確認是否有訪問延遲的情況。
案例:某公司自己的監控系統發現OSS請求資料有延遲
 某公司監控系統發現OSS訪問延遲較大,可按以下步驟排查:
某公司監控系統發現OSS訪問延遲較大,可按以下步驟排查:
檢查公司網路,通過ping其他網站測試延遲。
在OSS同地區建立ECS伺服器,測試訪問延遲。
將延遲的OSS requestID發送給支援人員,查看問題。
抓包分析上傳資料,使用以下參數:
tcpdump -i <出口網卡> -s0 ( 本機出口IP and OSS網域名稱 ) -w result.pcap
案例:有效請求率降低
問題現象:CloudMonitor出現“Object Storage Service (<)Bucket=p2xxx,userId=135114002(>),有效請求率(30.51<90% ),期間0分鐘”的報錯。
解決方案:異常請求率是通過2xx+3xx總體數量計算得出,您可以先查看CloudMonitor的 OSS 控制台統計的2xx+3xx及其他異常狀態代碼的佔比,確認是否因異常狀態代碼增加導致有效請求率下降。您也可以開通OSS日誌分析請求行為。
案例:CloudMonitor警示404
問題現象:CloudMonitor出現“Object Storage Service執行個體:Bucket=***-ali,userId=197*****745,資源不存在錯誤請求數於11:45恢複正常,值為30次,期間5分鐘”的報錯。
問題分析:原因是Bucket資源不存在導致的警示,屬於正常的響應,並非是異常狀態。
案例:CloudMonitor出現NoSuchWebSiteConfigration

問題分析:當用戶端請求OSS資料時,因功能配置不存在,導致404錯誤。200狀態代碼表示使用者已在OSS上配置功能模組,不是異常現象。
案例:OSS控制台API統計圖無資料
問題分析:API的監控資料都是隔天顯示,例如10月13日才能查看10月12日產生的完整資料。
案例:通過OSS監控計費核對賬單探索資料不準確
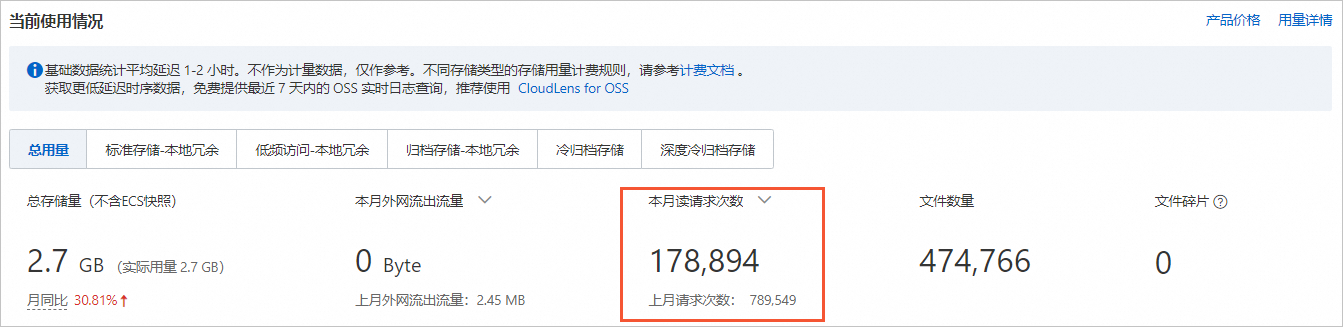
OSS的資料推送到CloudMonitor會延遲1~2小時,且單次推送間隔不能超過5分鐘,否則CloudMonitor會拒絕接收並且不支援補推。因此,不建議使用CloudMonitor資料對賬,因為資料不準確。您可以通過以下方式對賬:
提前開啟OSS日誌,然後將OSS日誌統計情況與賬單核對。
開啟OSS日誌分析功能,匯入日誌後直接查看分析結果。
案例:CloudMonitor顯示某個時間段的有效請求率下降為0,但是OSS的log以及控制台的監控資料都是正常
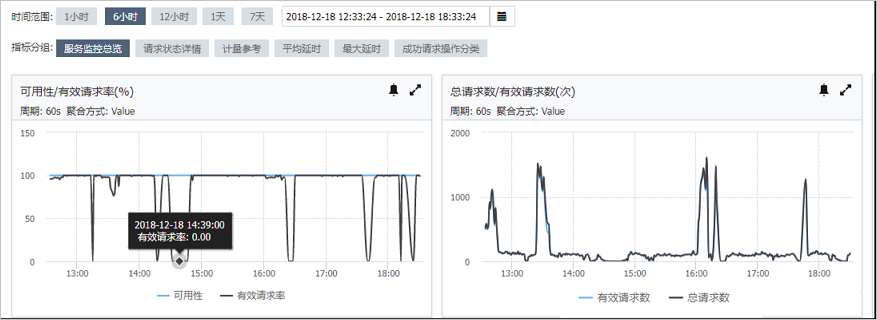
問題分析:CloudMonitor有效請求率的計算公式是:100%-(2xx+3xx)/總請求數量。發現類似情況可查看OSS控制台或OSS log有沒有異常即可。
原因是OSS將整個叢集日誌推送到CloudMonitor時超過了CloudMonitor的接收視窗期,而CloudMonitor不支援補推,所以導致資料為0 。