多節點並發啟動AI推理服務時,OSS Connector支援模型廣播功能,僅由單個節點從OSS載入模型資料,其餘節點通過鏈式拓撲結構完成模型資料的分發,大幅減少資料回源量,提升模型分發效率。
方案介紹
多節點並發啟動AI推理服務時,若模型檔案儲存體於OSS,各節點同時從OSS源端拉模數型會導致源端出口頻寬成為效能瓶頸,引發服務啟動延遲或失敗。尤其在一些OSS出口頻寬比較低的Region,多節點同時回源將嚴重影響服務部署效率。
OSS Connector模型廣播是AI推理服務大規模部署時的最佳化策略,指在大量啟動同一模型的推理服務時,僅由單個或少量節點從OSS載入模型資料,其餘節點通過預設的鏈式拓撲結構完成模型資料的分發。模型廣播可以利用節點的儲存和網路資源,大幅減少資料回源量,降低源端壓力,提升模型分發效率。
OSS Connector模型廣播採用鏈式傳輸方式。鏈式傳輸通過將模型檔案在節點間串列傳遞,使每個節點僅接收和轉寄一次資料。在模型檔案傳輸的情境下,單個資料流往往就能打滿多數主流機型節點頻寬,鏈式傳輸避免了樹形傳輸中節點向多個下遊節點發送資料而觸達頻寬瓶頸。
OSS Connector通過記憶體緩衝區機制,採用高並發策略將OSS上的模型檔案預先載入至緩衝區,供推理引擎按需載入GPU顯存,完成推理後延時釋放緩衝記憶體。模型廣播功能在此基礎上擴充了緩衝區的共用能力,整合了DADI P2P相關功能,僅需要部署一個Redis或Tair服務用於節點發現和中繼資料管理,實現將緩衝資料分發至其他節點。相較於單機部署方案,該方案僅增加輕量級緩衝區共用邏輯,卻能充分利用模型載入階段閑置的節點出口頻寬,是一種兼具經濟性與高效性的分布式模型載入方案。
OSS Connector模型廣播啟動同一模型在同一時間段僅會有一份資料回源OSS,可以極大減輕大量啟動時OSS源的壓力。但若源的效能仍為瓶頸,則須配合OSS加速器或DADI P2P分布式緩衝版使用。
前提條件
已安裝OSS Connector for AI/ML V1.2.0及以上版本。安裝方法請參見使用OSS Connector for AI/ML提升模型部署效率。
已準備好Redis或Tair資料庫,用於節點發現和中繼資料管理。
設定資料庫
模型廣播功能基於Redis或Tair服務進行節點發現和中繼資料管理,使用前需先設定資料庫。
方案一:購買並配置雲資料庫Tair(推薦)
Tair是阿里雲提供的相容Redis協議的雲資料庫服務,具備高可用性和免營運的優勢。
參考快速入門概覽建立Tair執行個體,版本需 ≥ 6.0,最低規格。
設定白名單,確保推理節點能夠訪問Tair執行個體。
準備好
串連地址、連接埠號碼、帳號和密碼,用於後續配置模型廣播。
方案二:獨立部署Redis服務
如果不使用雲資料庫Tair,你也可以在Kubernetes叢集中自行部署Redis服務。
以下YAML檔案部署了一個包含ACL認證的Redis服務:
建立ACL設定檔並產生Kubernetes Secret。
# 建立 ACL 內容 cat > users.acl << EOF user default off -@all user Username on >Password ~* &* +@all EOF # 建立 Secret kubectl create secret generic redis-acl-secret \ --from-file=users.acl \ --dry-run=client -o yaml | kubectl apply -f -說明請將
Username和Password替換為實際的使用者名稱和密碼。使用以下YAML檔案部署Redis Service和Deployment。
# redis-service.yaml apiVersion: v1 kind: Service metadata: name: redis spec: selector: app: model-redis ports: - protocol: TCP port: 6379 targetPort: 6379 --- # redis-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: model-redis-deployment spec: replicas: 1 selector: matchLabels: app: model-redis template: metadata: labels: app: model-redis spec: containers: - name: redis image: mirrors-ssl.aliyuncs.com/redis:8.4.0 ports: - containerPort: 6379 command: ["redis-server"] args: - "--aclfile" - "/etc/redis/users.acl" - "--maxmemory" - "900mb" - "--maxmemory-policy" - "volatile-lru" - "--save" - "" - "--appendonly" - "no" - "--loglevel" - "notice" resources: requests: memory: "1Gi" cpu: "100m" limits: memory: "1Gi" cpu: "200m" volumeMounts: - name: acl-config mountPath: /etc/redis/users.acl subPath: users.acl volumes: - name: acl-config secret: secretName: redis-acl-secret執行以下命令部署Redis服務。
kubectl apply -f redis-service.yaml
啟用模型廣播功能
在OSS Connector設定檔/etc/oss-connector/config.json中添加模型廣播相關配置。
{
...
"broadcast": {
"enableBroadcast": true,
"tenant": "${P2P_KEY_PREFIX}",
"db": {
"host": "${P2P_REDIS_HOST}",
"port": 6379,
"username": "${P2P_REDIS_USERNAME}",
"password": "${P2P_REDIS_PASSWD}"
}
},
"bindPort": 19898
...
}配置參數說明如下表所示。
參數名 | 說明 |
broadcast.enableBroadcast | 是否啟用模型廣播功能。設定為 |
broadcast.tenant | 租戶名。相同租戶名的節點間可以進行模型廣播,建議每個服務配置一個租戶。 |
broadcast.db.host | Redis或Tair服務的串連地址。 |
broadcast.db.port | Redis或Tair服務的連接埠號碼。預設為6379。 |
broadcast.db.username | Redis或Tair服務的帳號。 |
broadcast.db.password | Redis或Tair服務的密碼。 |
bindPort | 對外提供資料的連接埠。預設值為19898。 |
在Kubernetes叢集中部署模型廣播服務的完整樣本,請參見部署多執行個體模型廣播服務。
限制緩衝大小
模型廣播過程中,節點需要在記憶體中緩衝模型資料以供其他節點擷取。你可以通過以下方式限制緩衝佔用的記憶體大小。
方式一:通過環境變數設定
export CONNECTOR_MAX_CACHE_ADVISE_GB=100方式二:通過設定檔設定
在
/etc/oss-connector/config.json中設定prefetch.maxCacheAdviseGB:{ ... "prefetch": { "vcpus": 16, "workers": 24, "maxCacheAdviseGB": 100 }, ... }
記憶體限制為軟式節流。
環境變數優先順序高於設定檔。
效能報告
以下為Qwen2.5-72B模型(135.437 GB)在不同Region使用模型廣播功能的效能測試結果。
北京Region測試
測試環境
測試項 | 配置 |
OSS | 北京,內網下載頻寬250 Gbps |
節點配置 | ecs.g9i.24xlarge,網路32/最高48 Gb/s,96 vCPU 384 GiB |
模型 | Qwen2.5-72B,135.437 GB |
測試單位 | CPU版vllm api server啟動到服務就緒時間、OSS和P2P流量 |
不限制緩衝大小
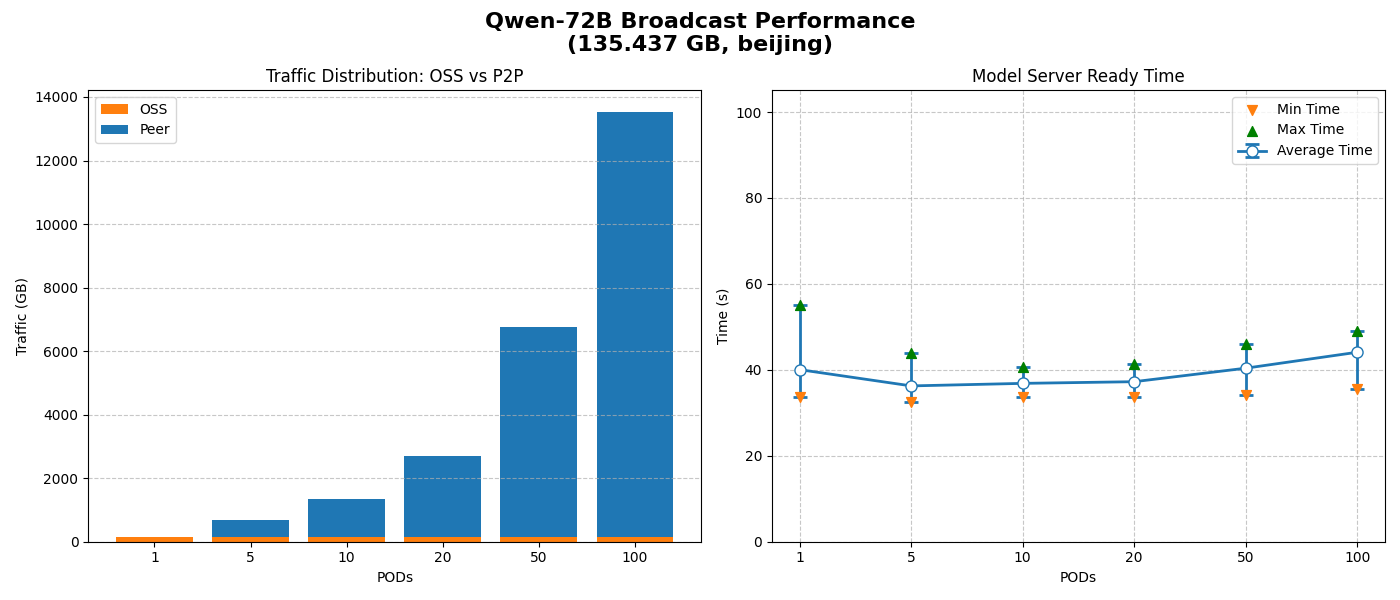
僅一份資料回源,其他均通過P2P傳輸,將OSS頻寬壓力降至最低。
平均模型就緒時間接近O(1)時間,不隨節點數線性增加,具有良好的水平擴充能力。
限制緩衝大小
分別測試不限制緩衝大小、限制緩衝大小到100/60/40/20/0 GB時,1/10/50/100節點同時啟動的模型就緒時間。
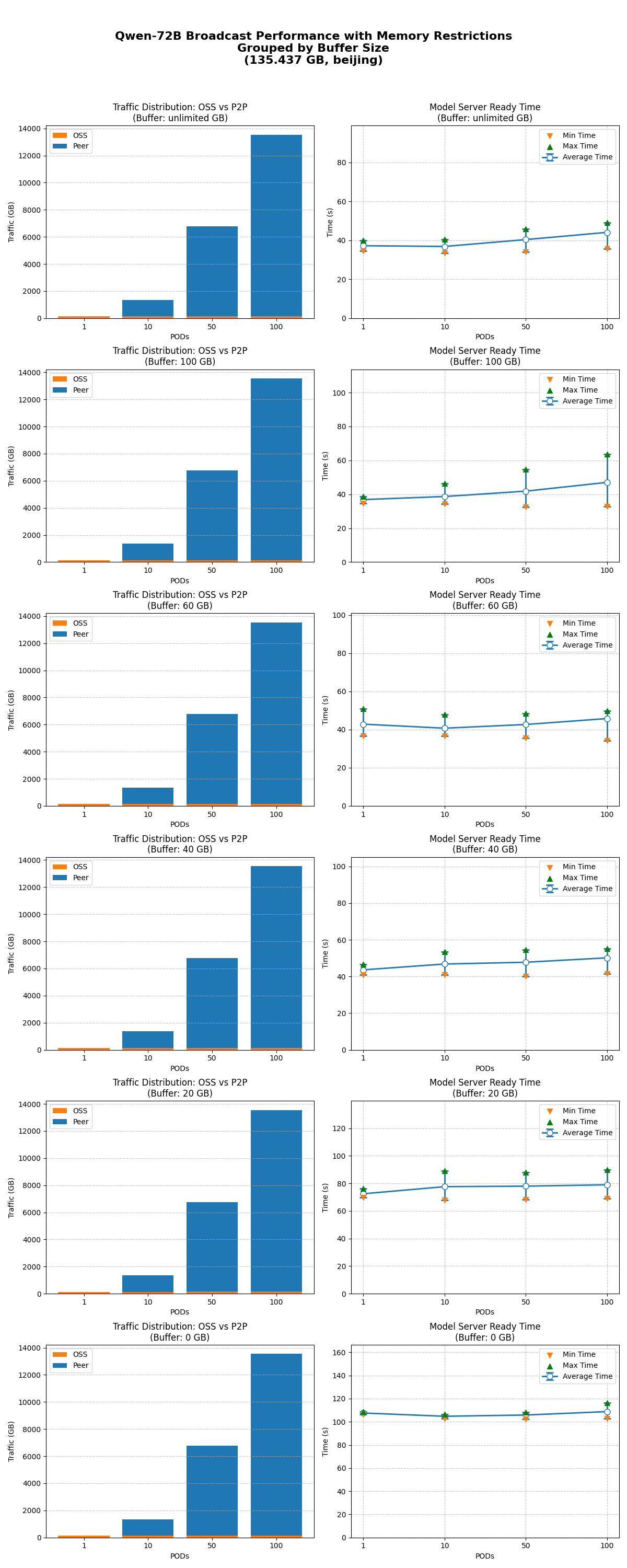
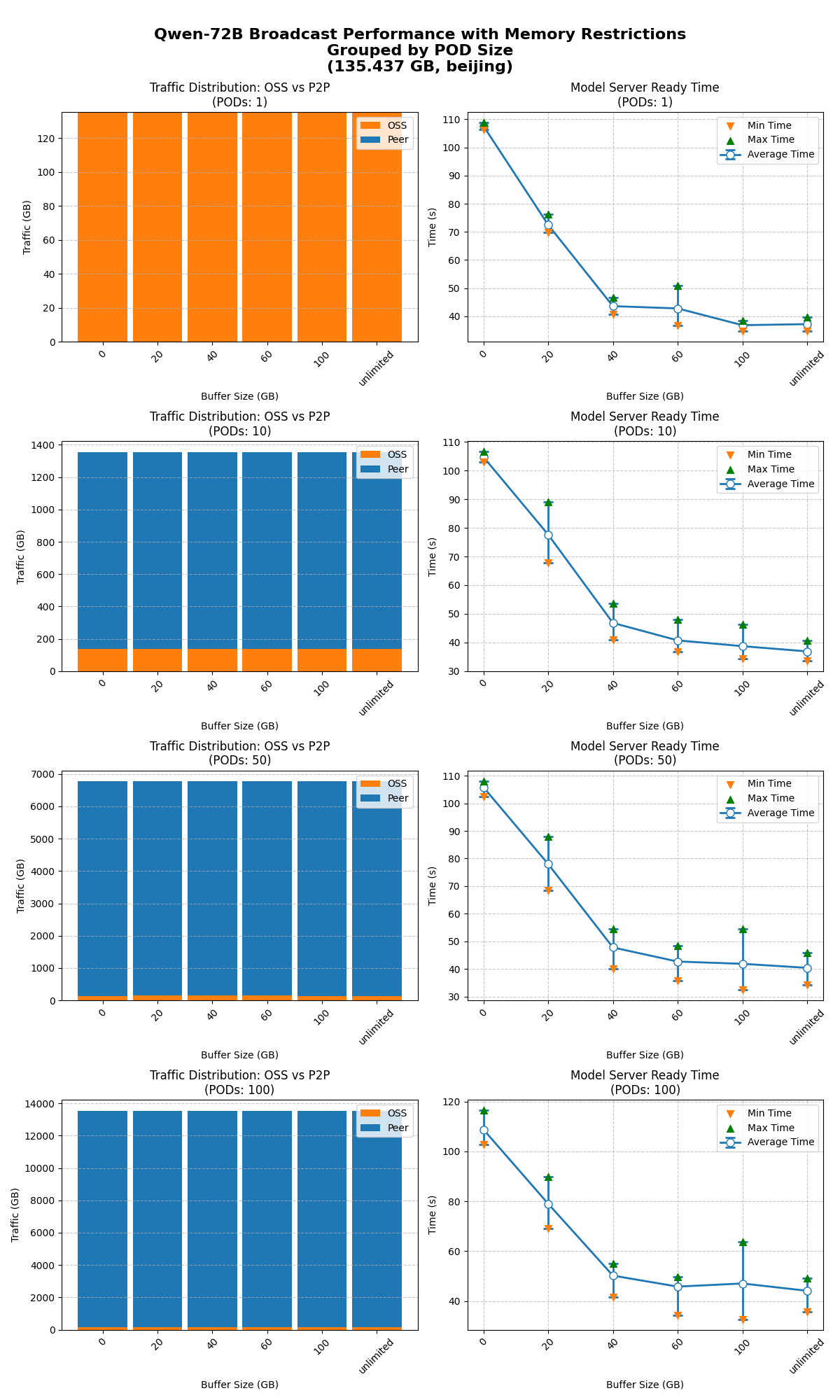
在不同緩衝限制下,模型廣播能正常工作,達到預期效果。
在不同並發下,限制緩衝對效能的影響基本一致。當緩衝 ≥ 40 GB時,限制緩衝對模型就緒時間影響不顯著;當緩衝 ≤ 20 GB時,效能開始明顯下降。
烏蘭察布Region測試
測試環境
測試項 | 配置 |
OSS | 烏蘭察布,內網下載頻寬10 Gbps |
節點配置 | ecs.g9i.24xlarge,網路32/最高48 Gb/s,96 vCPU 384 GiB |
模型 | Qwen2.5-72B,135.437 GB |
分別測試不限制緩衝大小、限制緩衝大小到60/0 GB時,1/10/50/100節點同時啟動的模型就緒時間。
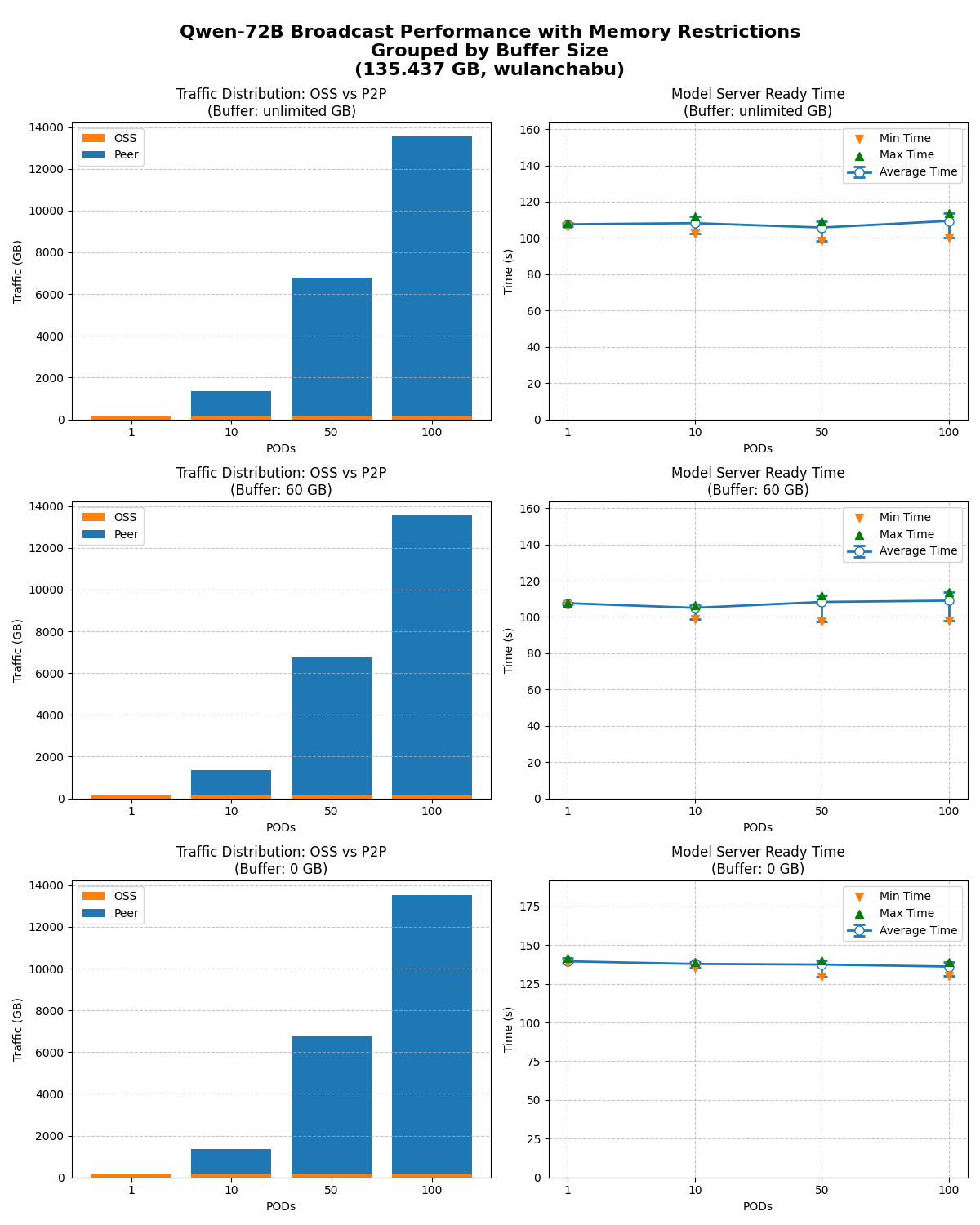
從測試結果看,當OSS下載頻寬受限時,模型廣播仍具備良好的水平擴充能力,將OSS頻寬壓力降至最低。