本文介紹了基於LHM調度遷移工具將DolphinScheduler調度任務流遷移到DataWorks的方案與操作流程,包括三步,DolphinScheduler任務匯出、調度任務轉換、DataWorks任務匯入。
一、匯出DolphinScheduler調度任務流
匯出工具通過調用DolphinScheduler的API擷取專案空間資訊、工作流程定義、資料來源定義、資源檔等資訊,支援DolphinScheduler 1.x、2.x、3.x全版本,操作流程如下。
1 前置條件
準備JDK17運行環境,打通運行環境和DolphinScheduler的網路連接,下載調度遷移工具到本地並解壓縮。
網路連接測試方法:驗證DolphinScheduler的ListProject API能否成功返回資訊,且返回的列表中包含待遷移的專案;token的擷取方式見下一小節。
# DolphinScheduler 1.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/query-project-list
# DolphinScheduler 2.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/list
# DolphinScheduler 3.x
curl -H "token:<YourToken>" -X GET http://<YourIp>:12345/dolphinscheduler/projects/list2 配置串連資訊
在工程目錄的conf檔案夾下建立匯出設定檔(JSON格式),如read.JSON。
使用前請刪除JSON中的注釋。
{
"schedule_datasource": {
"name": "YourDolphin", // 給你的Dolphin資料來源起個名稱!
"type": "DolphinScheduler", // 資料來源類型(DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // 串連地址
"project": "綜合測試Test", // 專案空間名稱
"token": "***********************" // Token
},
"operaterType": "AUTO" // 連線類型(AUTO:通過API自動擷取調度資訊)
},
"conf": {
}
}2.1 Endpoint擷取方式
串連地址為API串連地址,通常與前端頁面所在地址一致,如下圖中“http://120.55.X.XXX:12345”。
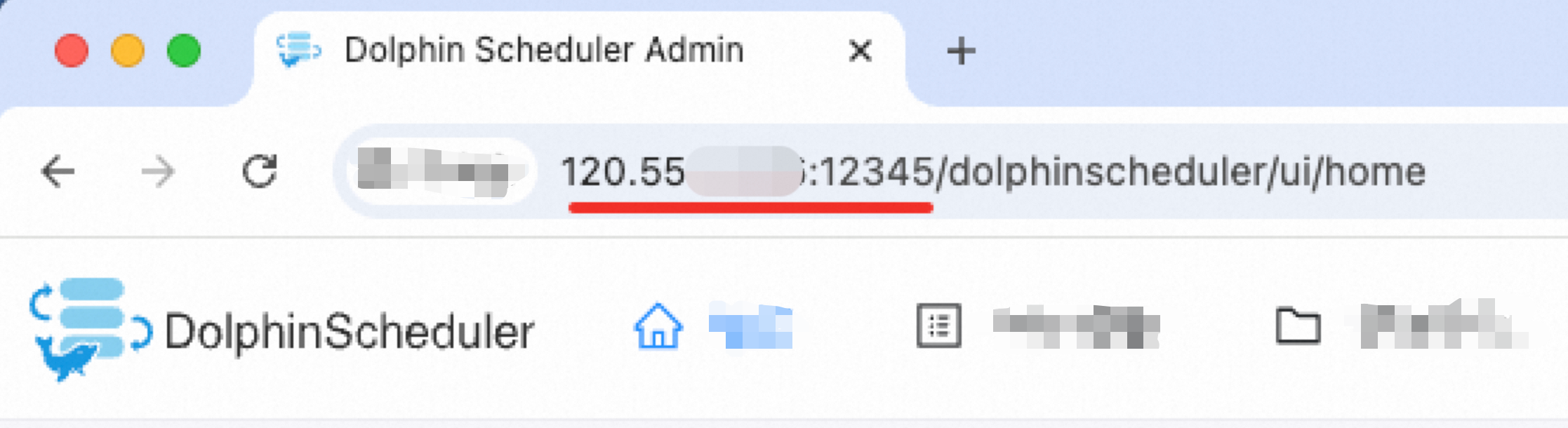
若DolphinScheduler地址為“http://your-company:12345/dolphinscheduler/ui/home”,則endpoint為“http://your-company:12345”。
DolphinScheduler作為一種開源調度引擎,其API模組也可能存在二開,如遇到調用失敗的問題,可以找到其Swagger頁面佐以簡單的測試對API特性進行確認。
2.2 Token擷取方式
在資訊安全中心-令牌管理頁面,建立令牌並設定充足的失效時間。
注意,使用者的token需要具有對待遷移專案的許可權。
2.3 Project擷取方式
開啟專案管理頁面,複製待遷移的專案名稱填寫至Project中。
3 運行調度探查工具
調度探查工具一次運行將產生兩個檔案,分別儲存以下內容:
DolphinScheduler API輸出的原始資訊(簡稱ApiOutput包)。
探查工具解析包,是對原始資訊的資料結構標準化(簡稱ReaderOuput包)。
ReaderOutput是調度匯出的最終結果;ApiOutput是中間結果,僅用於匯出過程中的問題排查。
探查工具通過命令列調用,調用命令如下:
sh ./bin/run.sh read \
-c ./conf/<你的設定檔>.JSON \
-f ./data/0_OriginalPackage/<API原始資訊的儲存包>.zip \
-o ./data/1_ReaderOutput/<源端探查匯出包>.zip \
-t <PluginName>其中-c為設定檔路徑,-f為ApiOutput包儲存路徑,-o為ReaderOutput包儲存路徑,-t為探查外掛程式名稱。
DolphinScheduler 1.x、2.x、3.x的匯出外掛程式分別為dolphinv1-reader、dolphinv2-reader、dolphinv3-reader。
例如,當前需要匯出Dolphin Scheduler 3.2.0的專案A:
sh ./bin/run.sh read \
-c ./conf/projectA_read.JSON \
-f ./data/0_OriginalPackage/projectA_ApiOutput.zip \
-o ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-t dolphinv3-reader4 查看匯出結果
開啟./data/1_ReaderOutput/下的產生包ReaderOutput.zip,可預覽匯出結果。
其中,統計報表是對DolphinScheduler中任務流、節點、資源、函數、資料來源基本資料的匯總展示。
而data/project檔案夾下是對DolphinScheduler調度資訊資料結構標準化後的結果。
統計報表:
sheet1“概覽”中展示Reader匯出結果的匯總資訊,取名為“WORKFLOW”、“WORKFLOWNODE”等的sheet中是具體的工作流程、節點、資源、函數、資料來源資訊。
統計報表提供了兩項特殊能力:
1、報表中工作流程、節點的部分屬性被允許更改,允許更改的欄位以藍色字型標識。在下一階段調度轉換中,在初始化階段,工具將擷取表格中的屬性變更並使其生效。
2、報表允許通過刪除工作流程子表中的行,使得在轉換時跳過這些工作流程(工作流程黑名單)。注意!若工作流程存在相互依賴關係,相關聯的工作流程需要同批次轉換,不可通過黑名單進行分割。分割會產生異常!
5 Q&A
5.1 (批量探查)能否一次探查多重專案?
支援,在配置項中project中支援一次填寫多重專案名,以單個英文逗號分隔,不可加入空格(這是由於DolphinScheduler的專案名稱中可以帶空格,因此我們將空格作為名稱的一部分進行匹配)。
使用前請刪除JSON中的注釋。
{
"schedule_datasource": {
"name": "YourDolphin", // 給你的Dolphin資料來源起個名稱!
"type": "DolphinScheduler", // 資料來源類型(DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // 串連地址
"project": "專案1,專案2", // 專案空間名稱
"token": "***********************" // Token
},
"operaterType": "AUTO" // 連線類型(AUTO:通過API自動擷取調度資訊)
},
"conf": {
}
}運行命令中-f和-o入參須填寫一個檔案夾路徑,工具將自動為每個專案分別建立匯出包。
sh ./bin/run.sh read \
-c ./conf/<你的設定檔>.JSON \
-f ./data/0_OriginalPackage/ \
-o ./data/1_ReaderOutput/ \
-t <dolphinv1/2/3-reader>5.2 (手動模式)沒有API怎麼辦?
部分開發人員拿掉了DolphinScheduler的API模組,以API的串連方式無法擷取調度資訊。備用方案是手動在./data/0_OriginalPackage/下構造原始資訊包,並在配置項中將operaterType修改為MANUAL。工具將以手動構造的原始包為輸入,完成DolphinScheduler的探查。
使用前請刪除JSON中的注釋。
{
"schedule_datasource": {
"name": "YourDolphin", // 給你的Dolphin資料來源起個名稱!
"type": "DolphinScheduler", // 資料來源類型(DolphinScheduler)
"properties": {
"endpoint": "http://localhost:12345", // 串連地址
"project": "綜合測試Test", // 專案空間名稱
"token": "***********************" // Token
},
"operaterType": "MANUAL" // 連線類型(MANUAL:離線模式)
},
"conf": {
}
}原始包結構樣本:
.
├── package_info.JSON
├── projects.JSON
├── projects
│ └── 綜合測試Test
│ └── processDefinition
│ └── process_definitions_page_1.JSON
├── datasource
│ └── datasource_page_1.JSON
├── resource
│ └── resources.JSON
└── udfFunction
└── udf_function_page_1.JSONpackage_info.JSON是包資訊,其中記錄了DolphinScheduler版本。
{
"version": "3.2.0"
}projects.JSON是專案資訊,手動構造時重點填寫id、userId、code和name。
[
{
"id": 2,
"userId": 1,
"code": 16372996967936,
"name": "綜合測試Test",
"description": "",
"createTime": "2025-01-20 11:40:39",
"updateTime": "2025-01-20 11:40:39",
"perm": 0,
"defCount": 0,
"instRunningCount": 0
}
]projects檔案夾儲存了工作流程定義。在手動構造時,其下一級目錄需修改為專案名稱。然後在DolphinScheduler的介面上匯出工作流程定義,依次重新命名為process_definitions_page_*.JSON,並放置於processDefinition下。
datasource、resource、udfFunction分別是資料來源資訊、資源檔資訊、UDF資訊,由於DolphinScheduler介面上缺少匯出能力,這些元素可預設。datasource_page_1.JSON、resources.JSON、udf_function_page_1.JSON中填寫空串[]即可。上述元素的預設對任務流遷移的細節有少量影響,影響涉及Sql節點關聯資料來源的映射、DataX節點(非自訂模板模式)關聯資料來源的映射、節點與資源參考關聯性的遷移等。受影響的節點在DataWorks中會被正常建立,只是節點與資料來源、資源的綁定需要在DataWorks中手動設定。
5.3 Token有效,但匯出任務流部分丟失怎麼辦?
首先檢查Token是否對專案具有許可權。
此外,我們發現DolphinScheduler 1.x部分小版本的API存在匯出丟失的情況。可結合匯出結果中的統計報表對丟失的任務流進行梳理與補全。
二、DolphinScheduler->DataWorks任務流轉換
Dolphin Scheduler作為一種主流開源的調度遷移引擎深受海量使用者喜愛,DataWorks完全覆蓋了Dolphin Scheduler的調度能力。經遷移工具改造,任務流可實現與Dolphin Scheduler上相同的運行效果。
1 前置條件
探查工具運行完成,DolphinScheduler調度資訊被成功匯出,ReaderOutput.zip被成功產生。
(可選,推薦)開啟探查匯出包,查看統計報表,核對待遷移範圍是否被匯出完全。
2 轉換配置項
2.1 轉換配置項目範本
使用前請刪除JSON中的注釋。
{
"conf": {},
"self": {
"if.use.default.convert": false,
"if.use.migrationx.before": false,
"if.use.dataworks.newidea": true,
"owner.map": [ // 責任人映射
{
"src": "1", // DolphinScheduler使用者ID
"tgt": "202006995118212119" // DataWorks使用者ID
}
],
"conf": [
{
"nodes": "all", // 規則群組生效範圍
"rule": {
"settings": {
// DolphinScheduler Shell節點轉換為DataWorks Shell節點
"workflow.converter.shellNodeType": "DIDE_SHELL",
// 未知節點預設轉換至DataWorks虛擬節點
"workflow.converter.target.unknownNodeTypeAs": "VIRTUAL",
// DolphinScheduer SQL節點根據資料來源類型轉換為對應DataWorks SQL節點或資料庫節點
"workflow.converter.dolphinscheduler.sqlNodeTypeMapping": {
"CLICKHOUSE": "CLICK_SQL",
"HIVE": "ODPS_SQL",
"STARROCKS": "StarRocks",
"DORIS": "HOLOGRES_SQL",
"MYSQL": "MYSQL",
"REDSHIFT": "Redshift",
"SQLSERVER": "SQLSERVER",
"PRESTO": "EMR_PRESTO",
"POSTGRESQL": "POSTGRESQL",
"ORACLE": "Oracle",
"ATHENA": "MYSQL"
},
// DolphinScheduler資料來源、DataWorks資料來源名稱映射
"workflow.converter.connection.mapping": {
"mysqlDb1": "dataworks_mysqlDb1",
"srDb1": "dataworks_srDb1"
},
// Dataworks上綁定的主要計算引擎(EMR/MaxCompute/Hologres)
"workflow.converter.target.engine.type": "EMR",
// DolphinScheduler Spark節點轉換為DataWorks MaxCompute Spark節點
"workflow.converter.sparkSubmitAs": "ODPS_SPARK",
"workflow.converter.sparkVersion": "3.x",
}
}
}
]
},
"schedule_datasource": {
"name": "DsProject",
"type": "DolphinScheduler"
},
"target_schedule_datasource": {}
}2.2 責任人映射
DolphinScheduler會記錄任務流的所屬使用者,對於團隊開發而言,所屬使用者是非常關鍵的資訊。工具支援通過配置DolphinScheduler使用者與DataWorks使用者的映射,對任務流和節點標記相應的責任人。
DolphinScheduler使用者名稱稱與ID通過使用者管理頁面擷取。
DataWorks工作空間中可以添加使用者作為工作空間的成員,使用者ID可以在右上方擷取。
也可以在資料開發頁面,責任人下拉框中擷取ID。
2.3 節點轉換規則
2.3.1 規則的生效範圍
節點轉換規則的配置規則可設定生效範圍,如所有節點按統一規則轉換,可以配置"nodes": "all"並填寫Settings。通常,使用者只需要配置一個all規則群組即可。
使用前請刪除JSON中的注釋。
{
"conf": {},
"self": {
"conf": [
{
"nodes": "all", // 規則群組生效範圍為ALL,所有節點依據此規則轉換
"rule": {
"settings": {
// Settings
}
}
]
}
}如部分節點使用獨立的轉換規則,可以在nodes中填寫任務ID/Name以指定規則的生效範圍,需為一批節點設定時可使用逗號分隔填寫生效範圍。建議使用ID指定,使用Name指定可能導致誤設定。此處也支援使用Regex匹配節點名稱。此外,強烈建議設定一個normal規則群組,為其餘節點設定一個預設轉換規則。
使用前請刪除JSON中的注釋。
{
"conf": {},
"self": {
"conf": [
{
"nodes": "node1Name, node2Id", // 規則群組生效範圍為node1、node2
"rule": {
"settings": {
// Settings 1
}
},
{
"nodes": "node3Name, node4Id", // 規則群組生效範圍為node3、node4
"rule": {
"settings": {
// Settings 2
}
},
{
"nodes": "regexExpression", // 支援用Regex對節點名稱進行篩選
"rule": {
"settings": {
// Settings 3
}
},
{
"nodes": "normal", // 其餘節點的轉換規則
"rule": {
"settings": {
// Settings 4
}
}
]
}
}2.3.2 轉換規則
DolphinScheduler 1.x、2.x、3.x在支援的節點種類上有所差異,因此轉換方案與配置項有所不同,具體如下。
2.3.2.1 DolphinScheduler3.x轉換配置項
工具當前支援轉換的DolphinScheduler 3.x節點包括以下類型:
SHELL、SQL、PYTHON、DATAX、SQOOP、SEATUNNEL、HIVECLI、SPARK(Java, Python, Sql)、MR、PROCEDURE、HTTP、CONDITIONS、SWITCH、DEPENDENT、SUB_PROCESS
其中可配置DataWorks映射規則的包括以下類型:
SHELL(workflow.converter.shellNodeType):
推薦轉換為DIDE_SHELL、EMR_SHELL、VIRTUAL節點等。
SQL(workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
推薦轉換為各類SQL節點、資料庫節點等。
PROCEDURE(workflow.converter.dolphinscheduler.sqlNodeTypeMapping):
推薦轉換為各類SQL節點、資料庫節點等。
PYTHON(workflow.converter.pyNodeType):
推薦轉換為PYTHON, PYODPS, PYODPS3, EMR_SHELL等。
HIVECLI(workflow.converter.dolphinscheduler.sqlNodeTypeMapping/HIVE):
推薦轉換為EMR_HIVE、ODPS_SQL等。
SPARK(workflow.converter.sparkSubmitAs):
SparkJava、SparkPython推薦轉換為ODPS_SPARK, EMR_SPARK;
SparkSql推薦轉換為ODPS_SQL, EMR_SPARK_SQL。
MR(workflow.converter.mrNodeType):
推薦轉換為ODPS_MR, EMR_MR。
DataWorks節點類型可參考此枚舉類:
固定轉換規則的節點類型:
DATAX: 轉換為DI節點,支援自訂模板模式(JSON Script模式)和常規模式(前端填寫入模式)。
支援以下資料來源讀外掛程式配置項轉換:MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb;
支援以下資料來源寫外掛程式配置項轉換:MYSQL -> mysql, POSTGRESQL -> postgresql, ORACLE -> oracle, SQLSERVER -> sqlserver, ODPS -> odps, OSS -> oss, HIVE -> hdfs, HDFS -> hdfs, CLICKHOUSE -> clickhouse, MONGODB -> mongodb。
SQOOP: 轉換為DI節點。
支援以下資料來源讀外掛程式配置項轉換:Mysql -> mysql, Hive -> hive, HDFS -> hdfs;
支援以下資料來源寫外掛程式配置項轉換:Mysql -> mysql, Hive -> hive, HDFS -> hdfs。
SEATUNNEL: 轉換為DI節點。
暫未支援指令碼轉換,僅轉換節點和調度資訊。
HTTP: 轉換為DIDE_SHELL(通用Shell)節點,遷移工具將請求參數自動拼接為curl命令。
SWITCH: 轉換為CONTROLLER_BRANCH(分支)節點,遷移前後功能一致。
SUB_PROCESS: 轉換為SUB_PROCESS節點,遷移前後功能一致;注意,在匯入DataWorks時,遷移工具將會將被引用的任務流的“可被引用”開關開啟,被引用的任務流只能通過SUB_PROCESS的調用而啟動,無法自行調度啟動。
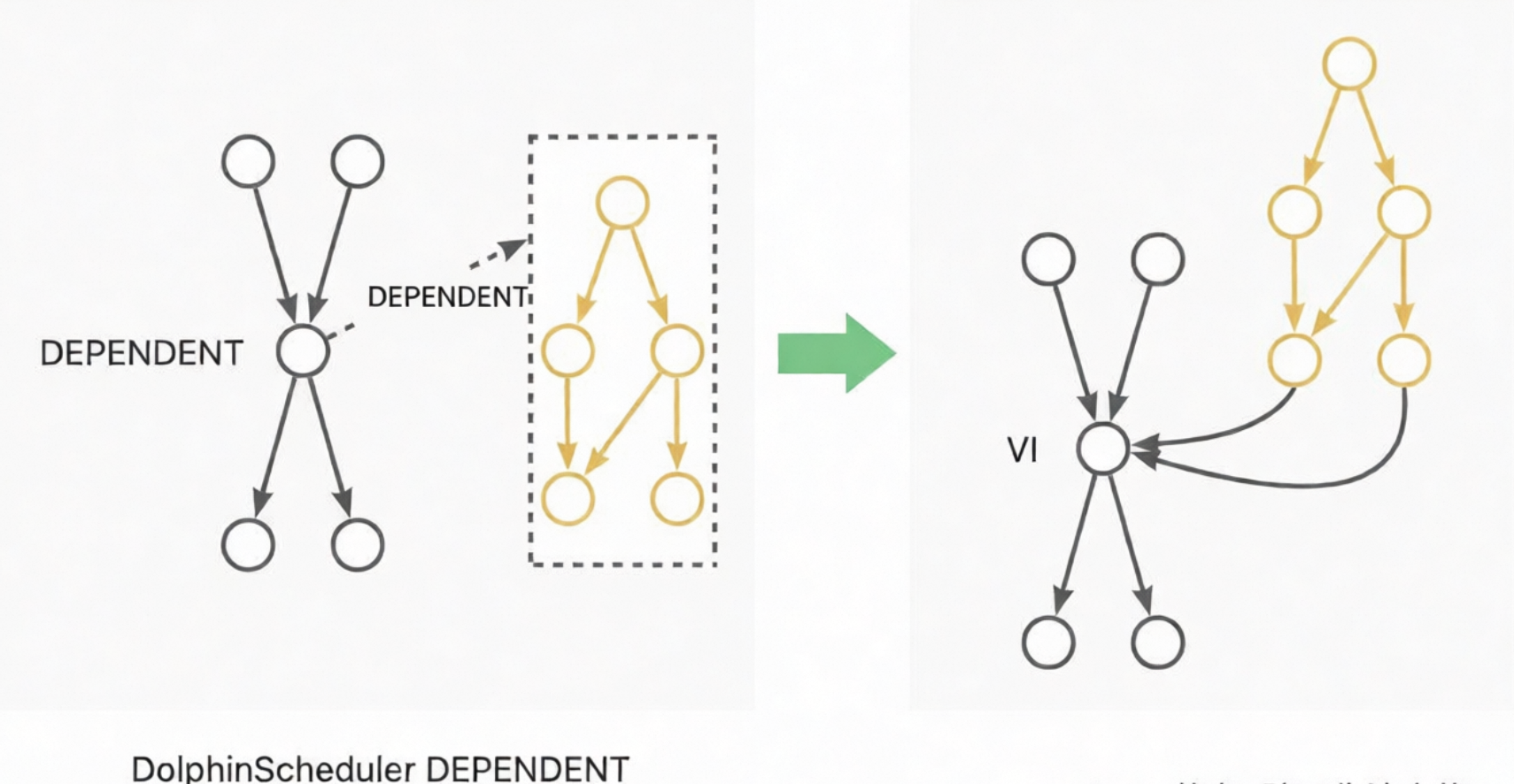
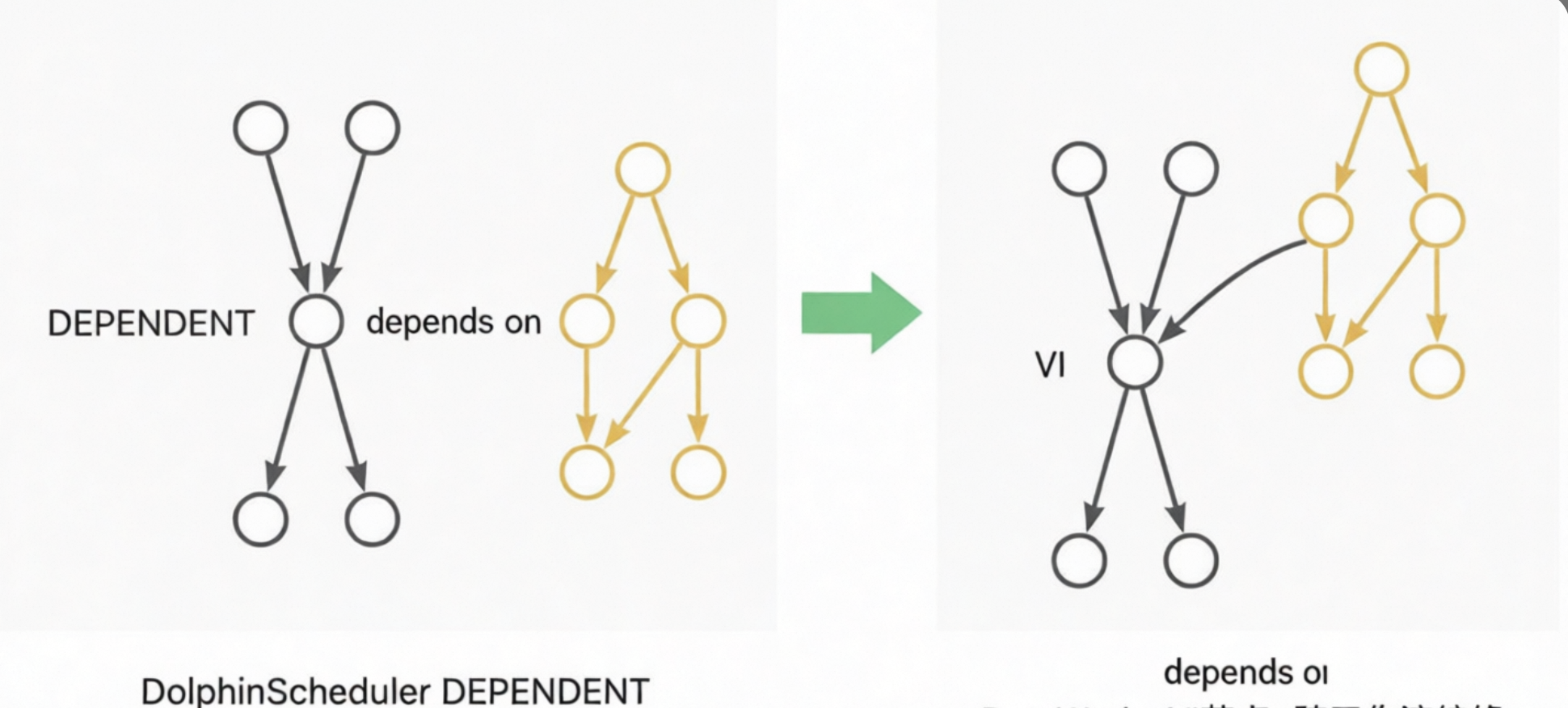
DEPENDENT: 轉換為VITRTUAL節點,依賴關係轉換為節點血緣依賴。如Dependent節點依賴於Workflow A時,依賴關係轉換為Workflow A尾節點到Dependent節點的血緣;如Dependent節點依賴於Node A,自來關係轉換為Node A到Dependent節點的血緣。見下圖示意:
CONDITIONS: 節點中包含兩層邏輯,使用雙層CONTROLLER_JOIN(歸併)節點進行分別實現。CONDITIONS有兩個上遊A和B、兩個下遊C和D,邏輯運算式為((!A&B)|(A&!B)|(!A&!B)),若為真則流轉至C,若為假則流轉至D。上層產生了3個歸併節點分別用來計算!A&B、A&!B、!A&!B的結果,下層產生了2個節點,其中一個在((!A&B)|(A&!B)|(!A&!B))==true時觸發下遊C節點執行,另一個在(!(!A&B)&!(A&!B)&!(!A&!B))==true時觸發下遊D節點執行,以實現CONDITIONS的效果。
2.3.2.2 DolphinScheduler2.x轉換配置項
工具當前支援轉換的DolphinScheduler 2.x節點包括以下類型:
SHELL、SQL、PYTHON、DATAX、SQOOP、HIVECLI、SPARK(Java, Python, Sql)、MR、PROCEDURE、HTTP、CONDITIONS、SWITCH、DEPENDENT、SUB_PROCESS
DolphinScheduler 3.x相比2.x僅多出一種SEATUNNEL節點,其餘節點的轉換方案及配置項同DolphinScheduler 3.x一致,可參考上一小節進行配置。
2.3.2.3 DolphinScheduler1.x轉換配置項
工具當前支援轉換的DolphinScheduler 1.x節點包括以下類型:
SHELL、SQL、PYTHON、DATAX、SQOOP、SPARK(Java, Python, Sql)、MR、CONDITIONS、DEPENDENT、SUB_PROCESS
以上節點轉換方案及配置項同DolphinScheduler 3.x一致,可參考上一小節進行配置。
3 運行調度轉換工具
轉換工具通過命令列調用,調用命令如下:
sh ./bin/run.sh convert \
-c ./conf/<你的設定檔>.JSON \
-f ./data/1_ReaderOutput/<源端探查匯出包>.zip \
-o ./data/2_ConverterOutput/<轉換結果輸出包>.zip \
-t <PluginName>其中-c為設定檔路徑;-f為ReaderOutput包儲存路徑;-o為ConverterOutput包儲存路徑;-t為轉換外掛程式名稱,DolphinScheduler 1.x、2.x、3.x的轉換外掛程式分別為dolphinv1-dw-converter、dolphinv2-dw-converter、dolphinv3-dw-converter。
例如,當前需要轉換的DolphinScheduler 3.x專案A:
sh ./bin/run.sh convert \
-c ./conf/projectA_convert.JSON \
-f ./data/1_ReaderOutput/projectA_ReaderOutput.zip \
-o ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-t dolphinv3-dw-converter轉換工具運行中將列印過程資訊,請關注運行過程中是否有報錯。轉換完成後將在命令列中列印轉換成功與失敗的統計資訊。注意,部分節點的轉換失敗不會影響整體轉換流程,如遇少量節點轉換失敗,可在遷移至DataWorks後進行手動修改。
4 查看轉換結果
開啟./data/2_ConverterOutput/下的產生包ConverterOutput.zip,可預覽匯出結果。
其中,統計報表是對轉換結果任務流、節點、資源、函數、資料來源基本資料的匯總展示。
而data/project檔案夾是轉換完成的調度遷移包本體。
統計報表提供了兩項特殊能力:
1、報表中工作流程、節點的部分屬性被允許更改,允許更改的欄位以藍色字型標識。在下一階段匯入DataWorks時,工具將擷取表格中的屬性變更並使其生效。
2、報表允許通過刪除工作流程子表中的行,使得在匯入DataWorks時跳過這些工作流程(工作流程黑名單)。注意!若工作流程存在相互依賴關係,相關聯的工作流程需要同批次匯入,不可通過黑名單進行分割。分割會產生異常!
三、匯入DataWorks
LHM遷移工具異構轉換已將遷移源端的調度元素轉換為DataWorks調度格式,工具得以針對不同的遷移情境提供了統一的上傳入口,實現任務流匯入DataWorks。
匯入工具支援多輪刷寫,會自動選擇建立/更新任務流(OverWrite模式)。
1 前置條件
1.1 轉換成功
轉換工具運行完成,源端調度資訊被成功轉換為DataWorks調度資訊,ConverterOutput.zip被成功產生。
(可選,推薦)開啟轉換輸出包,查看統計報表,核對待遷移範圍是否被轉換成功。
1.2 DataWorks側配置
DataWorks側需進行以下動作:
1、建立工作空間。
2、建立AK、SK且保證AK、SK對工作空間具有管理員權限。(強烈建議建立與帳號有綁定關係的AK、SK,以便在寫入遇到問題時進行排查)
3、在工作空間中建立資料來源、綁定計算資源、建立資源群組。
4、在工作空間中上傳檔案資源、建立UDF。
1.3 網路連通性檢查
驗證能否連通DataWorks Endpoint。
服務存取點列表:
ping dataworks.aliyuncs.com2 匯入配置項
在工程目錄的conf檔案夾下建立匯出設定檔(JSON格式),如writer.JSON。
使用前請刪除JSON中的注釋。
{
"schedule_datasource": {
"name": "YourDataWorks", //給你的DataWorks資料來源起個名字!
"type": "DataWorks",
"properties": {
"endpoint": "dataworks.cn-hangzhou.aliyuncs.com", // 服務存取點
"project_id": "YourProjectId", // 工作空間ID
"project_name": "YourProject", // 工作空間名稱
"ak": "************", // AK
"sk": "************", // SK
},
"operaterType": "MANUAL"
},
"conf": {
"di.resource.group.identifier": "Serverless_res_group_***_***", // 調度資源群組
"resource.group.identifier": "Serverless_res_group_***_***", // Data Integration資源群組
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls", // DataWorks節點類型表的路徑
"qps.limit": 5 // 向DataWorks發送API請求的QPS上限
}
}2.1 服務存取點
根據DataWorks所在Region選擇服務存取點,參考文檔:
2.2 工作空間ID與名稱
開啟DataWorks控制台,開啟工作空間詳情頁,從右側基本資料中擷取工作空間ID與名稱。
2.3 建立AK、SK並授權
在使用者頁建立AK、SK,要求對目標DataWorks工作空間擁有管理員讀寫權限。
許可權管理組件括兩處,如果帳號是RAM帳號,則需先對RAM帳號進行DataWorks操作授權。
權限原則頁面:https://ram.console.alibabacloud.com/policies
然後在DataWorks工作空間中,將工作空間許可權賦給帳號。
注意!AccessKey可設定網路訪問限制策略,請務必保證遷移工具所在機器的IP被允許訪問。
2.4 資源群組
由DataWorks工作空間詳情頁左側功能表列進入資源群組頁面,綁定資源群組,並擷取資源群組ID。
通用資源群組可用於節點調度,也可用於Data Integration。配置項中調度資源群組resource.group.identifier和Data Integration資源群組di.resource.group.identifier可以配置為同一通用資源群組。
2.5 QPS設定
工具通過調用DataWorks的API進行匯入操作。不同DataWorks版本中的讀、寫OpenAPI分別有相應的QPS限制和每日調用次數限制,詳見連結:使用限制。
DataWorks基礎版、標準版、專業版建議填寫"qps.limit": 5,企業版建議填寫"qps.limit": 20。
注意,請儘可能避免多個匯入工具同時運行。
2.6 DataWorks節點類型ID設定
在DataWorks中,部分節點類型在不同Region中被分配了不同的TypeId。具體TypeID以DataWorks資料開發實際介面為準。存在此特性的節點類型以資料庫節點為主:資料庫節點。
如:MySQL節點在杭州Region的NodeTypeId為1000039、在深圳Region的NodeTypeId為1000041。
為適應上述DataWorks不同Region的差異特性,工具提供了一種可配置的方式,允許使用者組態工具所使用的節點TypeId表。
表格通過匯入工具的配置項引入:
"conf": {
"dataworks.node.type.xls": "/Software/bwm-client/conf/CodeProgramType.xls" // DataWorks節點類型表的路徑
}從DataWorks資料開發介面上擷取節點類型Id的方法:在介面上建立一個工作流程,並在工作流程中建立一個節點,在點擊儲存後查看工作流程的Spec。
若節點類型配置錯誤,在任務流發布時將提示以下錯誤。
3 運行DataWorks匯入工具
轉換工具通過命令列調用,調用命令如下:
sh ./bin/run.sh write \
-c ./conf/<你的設定檔>.JSON \
-f ./data/2_ConverterOutput/<轉換結果輸出包>.zip \
-o ./data/4_WriterOutput/<匯入結果儲存包>.zip \
-t dw-newide-writer其中-c為設定檔路徑,-f為ConverterOutput包儲存路徑,-o為WriterOutput包儲存路徑,-t為提交外掛程式名稱。
例如,當前需要匯入DataWorks的專案A:
sh ./bin/run.sh write \
-c ./conf/projectA_write.JSON \
-f ./data/2_ConverterOutput/projectA_ConverterOutput.zip \
-o ./data/4_WriterOutput/projectA_WriterOutput.zip \
-t dw-newide-writer匯入工具運行中將列印過程資訊,請關注運行過程中是否有報錯。匯入完成後將在命令列中列印匯入成功與失敗的統計資訊。注意,部分節點的匯入失敗不會影響整體匯入流程,如遇少量節點匯入失敗,可在DataWorks中進行手動修改。
4 查看匯入結果
匯入完成後,可在DataWorks中查看匯入結果。匯入處理程序中亦可查看工作流程逐個匯入的過程,如發現問題需要終止匯入,可運行jps命令找到BwmClientApp,並使用kill -9終止匯入。
5 Q&A
5.1 源端持續在進行開發,這些增量與變更如何提交到DataWorks?
遷移工具為OverWrite模式,重新運行匯出、轉換、匯入可實現將源端增量提交到DataWorks的能力。請注意,工具將根據全路徑匹配任務流以選擇建立任務流/更新任務流。如需進行變更遷移,請勿移動任務流。
5.2 源端持續在進行開發,同時進行DataWorks上任務流改造與治理,增量遷移時是否會覆蓋DataWorks上的變更?
是的,遷移工具為OverWrite模式,建議您在完成遷移後再在DataWorks上進行後續改造。或者採用分批遷移的方式,已遷移等任務流再確認不再刷寫後開始DataWorks改造,不同批次之間互相不會影響。
5.3 整個包匯入耗時太長,能否只匯入一部分
可以,可手動裁剪待匯入包來實現部分匯入:將data/project/workflow檔案夾下需要匯入的任務流保留、其他任務流刪除,重新壓縮回壓縮包,再運行匯入工具。注意,存在相互依賴的任務流需要捆綁匯入,否則任務流間的節點血緣將會丟失。