本文將介紹向量檢索版支援的各類向量模型。
向量檢索介紹
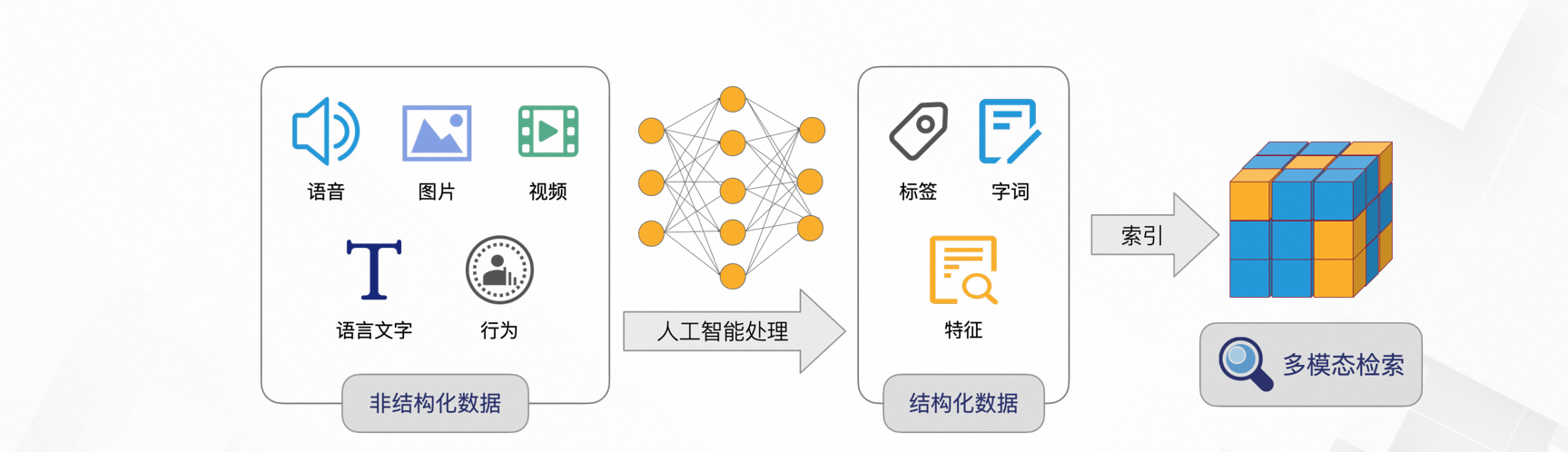
在當前的資訊化時代裡,資訊的模態在文本的基礎上,增加了圖片、視頻、音頻等多模態資訊;多模態能呈現文本無法表達的資訊,如:顏色、形狀、運動動態、聲音、空間關係……

同時各個領域資訊的模態也有大幅度的變化:

資訊在這種多模態的情境下被分為兩大類(結構化和非結構化):
非結構化的資料往往讓電腦難以理解,傳統的文本分詞檢索情境以無法滿足各個領域的搜尋需求,而向量完美地解決了這個難題。
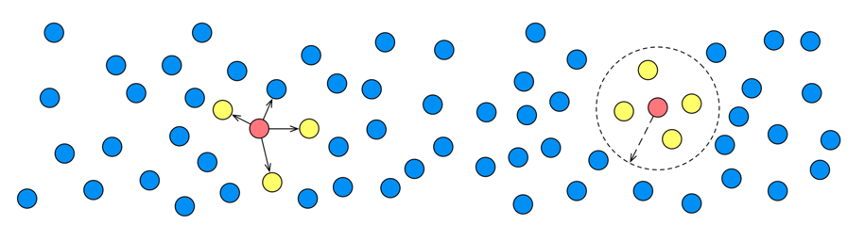
那麼什麼是向量,又如何通過向量檢索呢?
將物理世界產生的非結構化資料,轉化為結構化的多維向量,用這些向量標識實體和實體間的關係。
再計算向量之間距離,通常情況下,距離越近、相似性越高,召回相似性最高的TOP結果,完成檢索。
向量檢索演算法
linear
linear演算法會線性計算所有向量資料。
適用情境:100%召回率
劣勢:巨量資料量下效率較低、資源(CPU、記憶體)消耗較嚴重
聚類演算法
量化聚類(Quantized Clustering)
介紹:
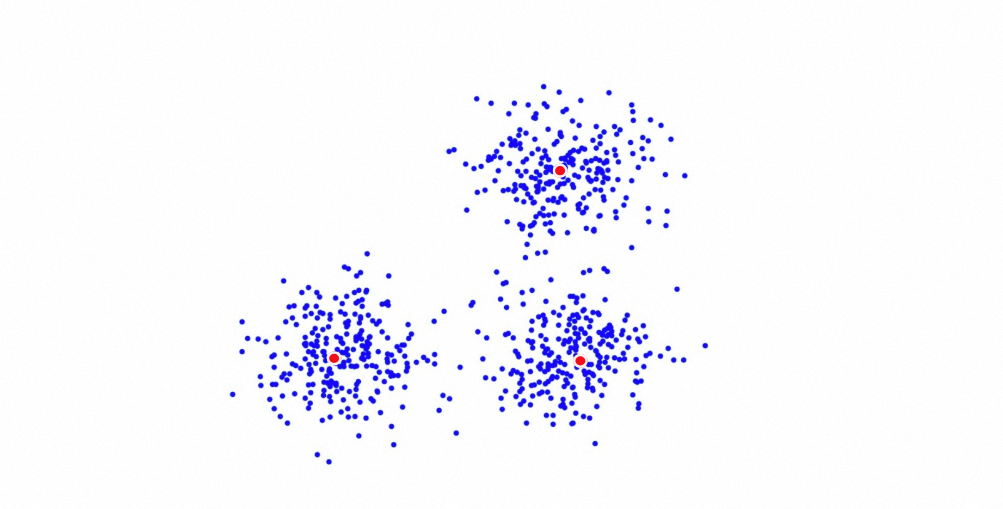
量化聚類(Quantized Clustering)是阿里巴巴開發的基於kmeans聚類的向量檢索演算法。先利用向量文檔聚類n個中心點,並將每個文檔歸屬到離其最近的中心點下,進而構建出n個倒排鏈。n個中心點及其對應的倒排鏈就是QC索引的主要內容。檢索時,請求先和部分中心點進行距離計算,並從中挑選距離最近的多個中心點,接著,請求和中心點對應倒排鏈下的文檔進行距離計算,最終返回距離最近的topk個文檔結果。
特別是,QC支援了數值fp16/int8量化功能,可以減少索引大小、提升檢索效能。但是,對召回效果可能有損。使用者可以根據業務需要,權衡是否需要配置。
QC演算法適用於即時資料情境,或者有GPU資源,且對延遲要求較高的情境。
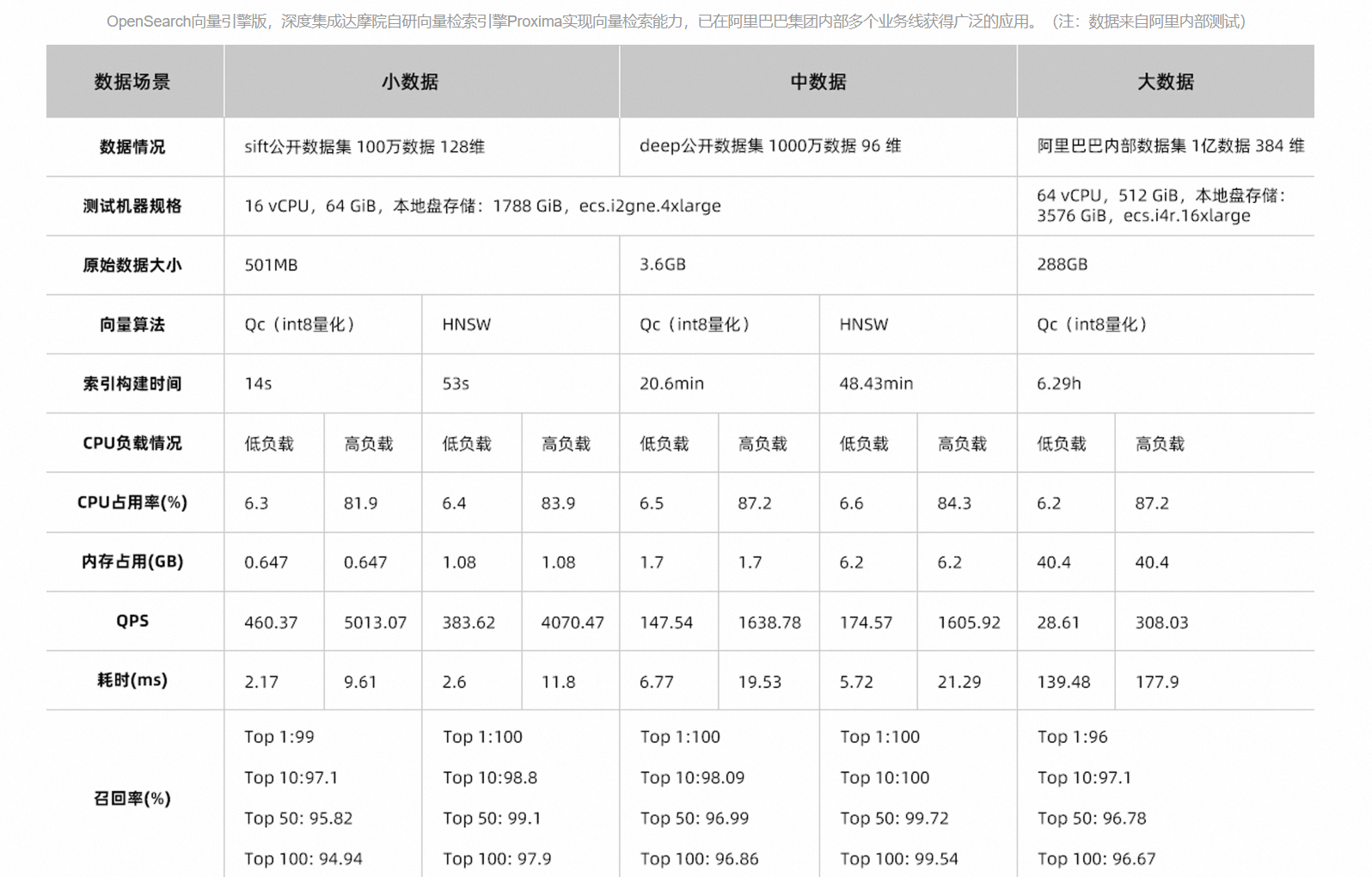
參數調優:
效能對比:
HNSW(Hierarchical Navigable Small World)
介紹:
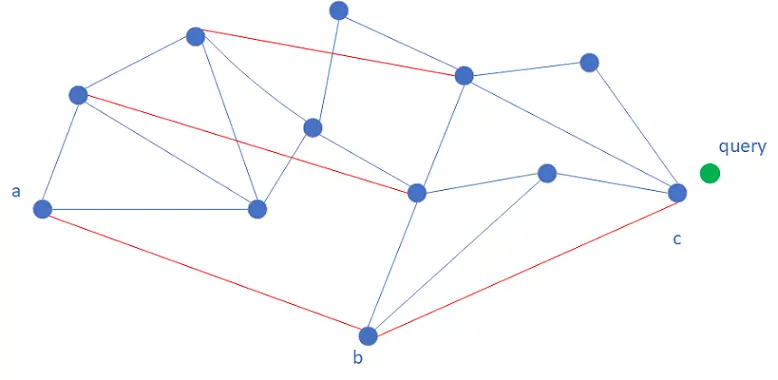
HNSW(Hierarchical Navigable Small World)是基於近鄰圖的向量檢索演算法。先構建一個近鄰圖,距離接近的向量之間建立邊關係。向量以及其近鄰資訊就是HNSW索引的主要內容。檢索時,從入口節點開始遍曆,計算請求和入口節點的所有近鄰距離,選擇距離最近的近鄰,作為下一步的遍曆節點,進而迭代遊走,直至收斂並停止檢索。收斂指的是當前檢索節點的所有近鄰中沒有比已經檢索到的最近節點更接近請求。
為了加速收斂,借鑒跳錶查詢的邏輯,HNSW構建了一個多層近鄰圖結構。檢索從上而下進行。每一層圖的檢索邏輯大致相同(第0層邏輯有些差異),在第k層圖遍曆收斂到一個節點後,會將其作為第k-1層的入口節點並繼續在第k-1層遍曆。相較於第k-1層圖, 第k層圖包含的節點更加稀疏,節點之間的距離更長,這使得第k層圖遊走時的步長更大,迭代更快。
參數調優:
QGraph演算法
介紹:
QGraph(Quantized Graph)是OpenSearch自研的一種基於HNSW的改進演算法,在索引構建過程中會自動對使用者的未經處理資料進行量化,然後再構建成圖索引。與HNSW演算法相比,QGraph演算法可以有效降低索引大小,節省記憶體開銷,最高可以將索引降為原來的1/8。同時,藉助於CPU指令對整數計算的最佳化,QGraph的效能相對於HNSW提升數倍。量化之後向量的區分度降低,QGraph的召回率較HNSW會降低,在真實情境中可通過更多的召回來降低這一影響。
QGraph支援對資料進行int4、int8和int16量化。不同層級的量化對向量索引記憶體佔用、查詢效能和召回率的影響不同。一般隨著整數位元越小,向量索引佔用的記憶體越小,效能越高,召回率越低。其中,int16量化由於底層CPU指令集的問題,效能和召回率與未量化時幾乎相同。
參數調優:
CAGRA演算法
介紹:
CAGRA(CUDA ANN GRAph-based)演算法是一種基於近鄰圖的向量檢索演算法,針對Nvidia GPU進行最佳化,適用於高並發和批量請求的情境。
與HNSW演算法不同,出於並行計算的目的,CAGRA演算法構建的近鄰圖僅為一層。在查詢時,演算法在迭代的同時會維護一個有序的候選集合,每個迭代中,會選取候選集合中最佳的TopK節點作為搜尋起點,嘗試用其近鄰更新候選集合,如此迭代直到候選集合中TopK的所有節點都成為過搜尋起點,此時認為演算法收斂。
CAGRA的演算法實現包含兩種策略,single-CTA與multi-CTA。single-CTA將單個向量的查詢映射到單個線程塊上執行,當batch size較大時效率較高;multi-CTA則使用多個線程塊執行對單個向量的查詢,在batch size較小時能夠更好地利用GPU的並行計算能力,召回率也更高,但當batch size較大時,其輸送量不如single-CTA策略。實際調用時會根據工作負載自動選取最佳的演算法。
參數調優:
DiskANN演算法
介紹:
DiskANN是一種基於磁碟的近似最近鄰搜尋技術,專為處理超大規模資料集而設計。它採用Vamana圖演算法,能夠在有限記憶體條件下有效利用磁碟儲存資料,同時保持高效的向量索引與檢索。
僅資料節點規格類型系列為SSD時支援DiskANN演算法。
參數調優:
CagraHnsw演算法
介紹:
CagraHnsw演算法是OpenSearch自研的向量檢索演算法,結合了CAGRA演算法與HNSW演算法的優勢,適用於需要快速完成海量資料構建的情境。
CagraHnsw演算法在索引構建階段與CAGRA演算法相似,使用GPU進行索引構建,索引檔案會轉換為可供HNSW演算法使用的格式,在檢索階段使用CPU上的HNSW演算法進行搜尋。這種策略結合了CAGRA演算法利用GPU進行高效構建的優勢,同時不要求使用者在檢索階段使用價格更高的GPU機型,相較於CAGRA演算法,在沒有持續高並發查詢情境時性價比更高。
向量距離類型
向量檢索的過程是通過計算向量之間的相似性,最後返回相似性較高的TopK向量集合。在這個過程中,向量之間的相似性是通過計算距離來得到。通常,分數越小表示,向量距離越近;分數越大,表示距離越遠。
在不同向量空間中,定義了不同的距離度量(Distance Metrics)方式來計算這些向量的距離。在向量檢索版中支援的度量方式有:歐式度量、內積度量與Cosine距離。
歐式距離(SquareEuclidean)
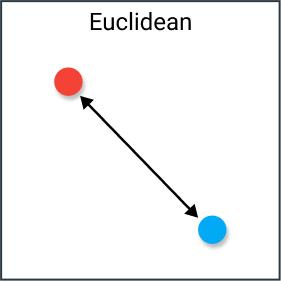
歐式距離是指兩個向量之間的平面距離。作為一種最常用的距離度量方式,歐式距離可以通過計算兩個向量之間的座標差的平方和的平方根來得到。歐式距離越小,表示兩個向量越相似。歐式距離度量的計算公式如下:
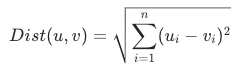
內積距離(InnerProduct)
內積是指兩個向量之間的點積或數量積,內積結果越大,代表越相似。它可以通過計算兩個向量對應位置上的元素相乘,並對乘積結果求和得到。內積度量常見於搜尋推薦情境,通常而言,是否使用內積測量取決於演算法是否使用內積模型。內積度量的計算公式如下:
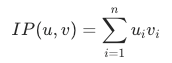
Cosine距離
Cosine距離是指兩個向量夾角的餘弦值。取值範圍為[-1, 1]。為-1時表示兩個向量方向相反,相似性最低;為1時表示兩個向量方向相同,相似性最高;為0時表示兩個向量垂直。值越接近1越相似。常用在文本相似性檢索情境。計算公式如下:
