您可以將AI搜尋開放平台、ModelScope與定製模型中的模型進行獨立部署,提供更高並發、更低延遲的推理服務。
模型列表
模型類別 | 模型名稱 | 模型來源 |
文本向量化 |
模型調用請參見:文本向量。 | AI搜尋開放平台 |
GTE多語言通用文本向量模型:上下文最大token長度8192,支援70多種語言。 | ModelScope | |
在模型定製中自主訓練的文本向量化模型。 | 模型定製 | |
排序服務 |
模型調用請參見:排序服務。 | AI搜尋開放平台 |
多模態向量化 |
| ModelScope |
計費規則
計費公式為:CU單價*機型消耗的CU數量*購買機器台數
具體計費規則如下表所示:
機型 | CU單價(元/小時) | 單台機器消耗CU數量 | 單台機器單價(元/小時) |
gpu.v100.16g.x1 | 1.07 | 30.14 | 32.25 |
gpu.t4.16g.x1 | 16.07 | 17.195 | |
gpu.a10.24g.x1 | 11.01 | 11.781 |
例如某使用者購買2台gpu.a10.24g.x1部署模型服務,計費為:1.07*11.01*2=23.56元/小時。
部署服務
在AI搜尋開放平台選擇模型服務>服務部署,然後單擊部署服務。
如通過RAM帳號進行服務建立、變更、查看服務詳情等操作時,需要提前授予RAM帳號模型服務-服務部署相關的操作許可權。
在部署服務頁面,佈建服務名稱、部署地區等資訊。
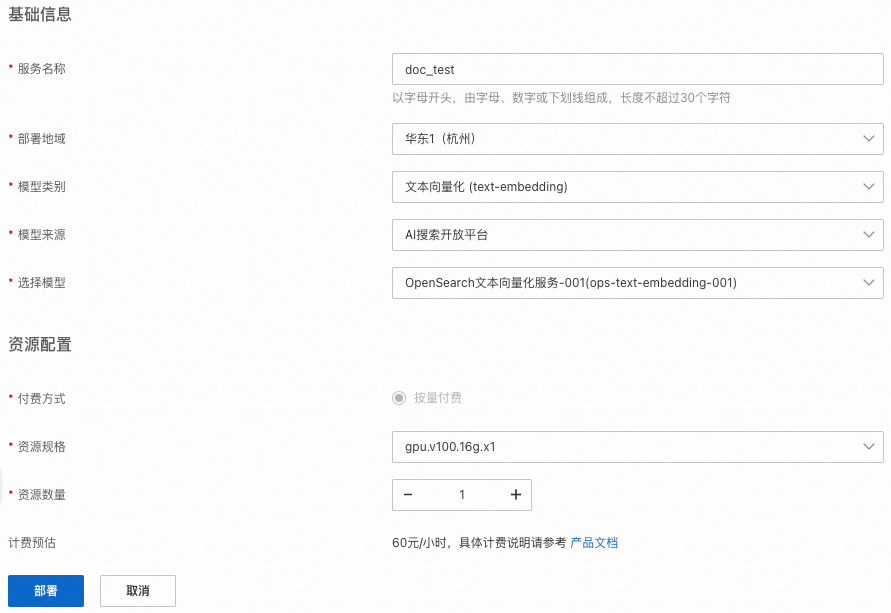
目前支援的部署地區為:華東1(杭州)、華東2(上海)、華南1(深圳)、華北2(北京)、華北3(張家口)。
資源規格:模型部署使用的機型。
計費預估:模型部署消耗的費用。
單擊部署,系統開始部署服務。服務狀態說明:
部署中:系統正在部署服務,服務暫不可用。在服務列表單擊管理查看服務詳情、單擊刪除刪除部署任務。
正常:表示部署成功。在服務列表單擊管理查看服務詳情,在服務詳情頁通過更改配置更改服務的資源配置;在服務列表單擊刪除刪除服務。
部署失敗:可以查看部署詳情、重新部署、刪除部署任務。
查看服務調用資訊
登入AI搜尋開放平台,選擇模型服務>服務部署,在服務列表中單擊管理:
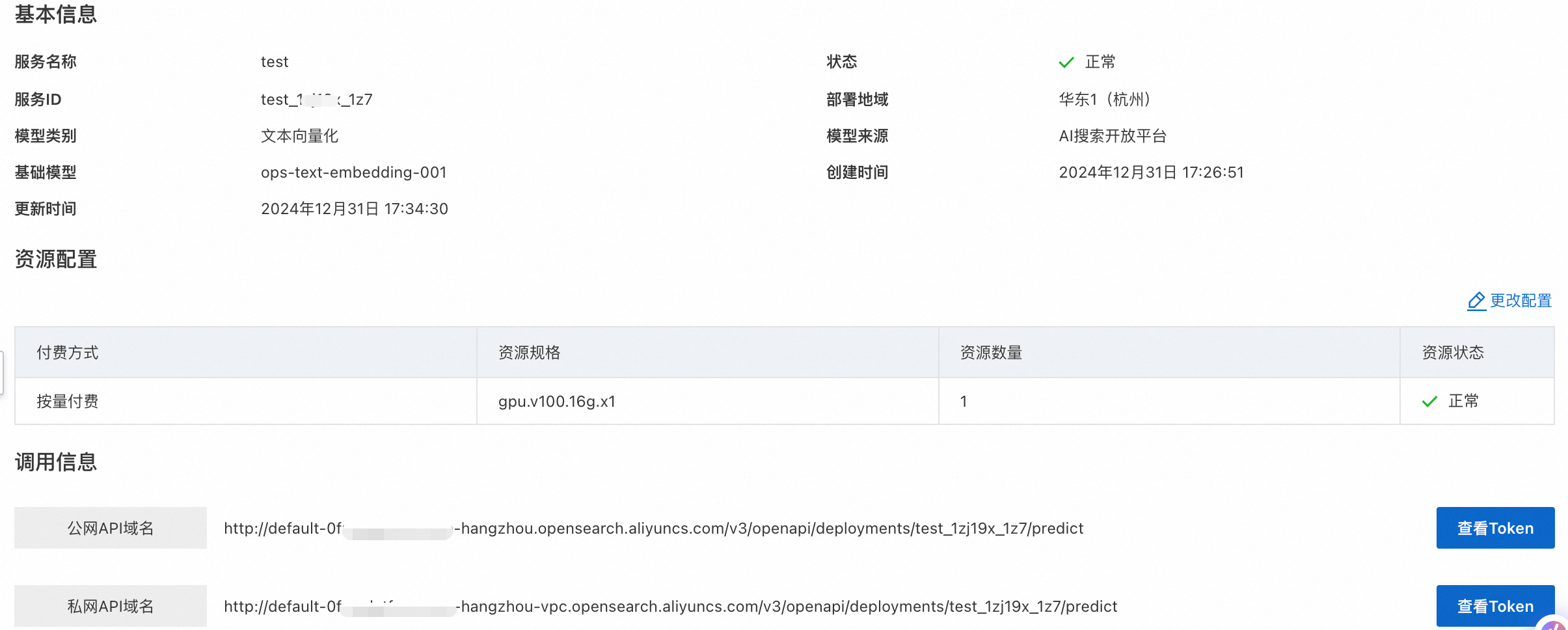
服務ID:通過SDK調用服務時,需要此參數。
公網和私網API網域名稱:可選擇通過公網或者私網地址調用模型服務。
Token:服務調用時的憑證。分為公網Token和私網Token,通過公網或者私網地址調用服務時,需填入對應的Token。
API-KEY:通過API-KEY實現服務調用時的身份認證。

測試服務
通過curl命令測試模型服務時,需要傳入API-KEY、Token資訊。
執行以下代碼調用文本向量化模型對輸入內容“科學技術是第一生產力”和“opensearch產品文檔”進行向量化:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 您的API-KEY" \
-H "Token: NjU0ZDkzYjUwZTQ1NDI1OGRiN2ExMmFmNjQxMDYyN2M5*******==" \
"http://default-0fm.platform-cn-hangzhou.opensearch.aliyuncs.com/v3/openapi/deployments/******_1zj19x_1yc/predict" \
-d '{
"input": [
"科學技術是第一生產力",
"opensearch產品文檔"
],
"input_type": "query",
"dimension" : 567 # 部署的為定製模型並開啟向量降維時,才會生效,且維度不能大於基本模型的維度
}'
正確返回結果:
{
"embeddings": [
{
"index": 0,
"embedding": [
-0.028656005859375,
0.0218963623046875,
-0.04168701171875,
-0.0440673828125,
0.02142333984375,
0.012345678901234568,
...
0.0009876543210987654
]
}
]
}通過SDK調用服務
測試通過後,接下來您可以參照以下Python SDK調用樣本,在業務系統中整合SDK實現服務調用。
import json
from alibabacloud_tea_openapi.models import Config
from alibabacloud_searchplat20240529.client import Client
from alibabacloud_searchplat20240529.models import GetPredictionRequest
from alibabacloud_searchplat20240529.models import GetPredictionHeaders
from alibabacloud_tea_util import models as util_models
if __name__ == '__main__':
config = Config(bearer_token="API-KEY",
# endpoint配置統一的請求入口,去掉http://或者https://
endpoint="default-xxx.platform-cn-shanghai.opensearch.aliyuncs.com",
# protocol支援HTTPS和HTTP
protocol="http")
client = Client(config=config)
# --------------- 請求體參數 ---------------
request = GetPredictionRequest().from_map({"body":{"input_type": "document", "input": ["搜尋", "測試"]}})
headers = GetPredictionHeaders(token="xxxxxxxxYjIyNjNjMjc2MTU1MTQ3MmI0ZmQ3OGQ0ZjJlMjxxxxxxxx==")
runtime = util_models.RuntimeOptions()
# deploymentId:部署id
response = client.get_prediction_with_options("已部署服務的服務ID" ,request, headers, runtime)
print(response)