通過效果評測模組對AI搜尋開放平台提供的RAG開發鏈路進行效果評測,從使用者提出問題開始,到RAG系統召回內容,再到LLM產生回答的整個流程進行綜合評測。
前提條件
開通AI搜尋開放平台服務,詳情請參見開通服務。
操作步驟
登入AI搜尋開放平台控制台。
選擇上海地區,切換到AI搜尋開放平台,切換到目標空間。
說明目前僅支援在上海、德國(法蘭克福)地區開通AI搜尋開放平台功能。
支援杭州、深圳、北京、張家口、青島地區的使用者,通過VPC地址跨地區調用AI搜尋開放平台的服務。
空間用於隔離和管理資料,首次開通AI搜尋開放平台服務後,系統自動建立一個Default空間,支援建立空間。
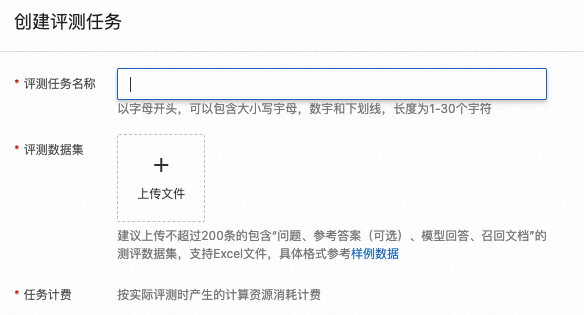
在左側導覽列選擇效果評測,選擇建立評測任務。
在建立評測任務頁面,輸入任務名稱,參照提供的範例資料格式上傳評測資料集。
重要一個測評資料集中,最大有效資料為200條,超出後系統提示報錯。
嚴格按照範例模板上傳測評資料集,參考答案為可選項,同一個資料集中不支援部分問題無參考答案。
測評模板以及關鍵測評指標說明:
參數
說明
question
您的問題
standard_answer
參考答案,該參數值可為空白,對測評報告返回的評測指標有影響。
有參考答案,評測指標如下:
無幻覺率(faithfulness):檢索到的文檔與模型產生答案之間的幻覺率。有幻覺取值為0;無幻覺取值為1。
檢索準確率(context_precision):參考答案與檢索到的文檔之間的準確性。準確取值為1,不準確取值為0。
檢索召回率(context_recall):檢索到的文檔與參考答案之間的完整度,召回完整取值為1,召回不完整取值為0。
滿意度(satisfaction):模型產生的答案與參考答案之間對比:
模型產生的答案無幻覺且準確、完整,滿意度為1。
模型產生的答案無幻覺,但資訊不準確或有遺漏時,滿意度為0.5。
模型產生的答案存在幻覺問題時,滿意度為0。
綜合評分(comprehensive_score):無幻覺率、檢索準確率、檢索召回率、滿意度的綜合評分。
無參考答案,評測指標如下:
檢索相關性(context_relevance):問題與檢索到的文檔的相關性,相關為1,不相關為0。
可信度(credibility):問題與模型產生答案的可信度。
模型產生的答案無幻覺,且根據相關的檢索結果產生答案(若未檢索到相關結果,答案為無法回答)時,可信度為1。
模型產生的答案無幻覺,但根據不相關的檢索結果產生答案,或有相關的檢索結果時答案為無法回答,可信度為0.5。
模型產生的答案有幻覺時,可信度為0。
無幻覺率(faithfulness):檢索到的文檔與模型產生答案之間的幻覺率。有幻覺取值為0;無幻覺取值為1。
綜合評分(comprehensive_score):檢索相關性、無幻覺率、可信度的綜合評分。
recall_docs
檢索到的文檔
model_answer
模型產生的答案
完成上述參數配置後單擊確定建立評測任務。
測評任務狀態:
評測中、評測失敗:支援刪除評測任務。
評測成功:可下載評測報告Excel,包括2個部分:
sheet1-評測任務:測評任務總體情況,根據所有測評成功的問題計算均值指標。
sheet2-任務詳情:針對每個問題的測評詳情資料。
