簡介
計算查詢詞在指定欄位上的匹配度。欄位上命中的查詢詞越多,權重越高,匹配分數也越高。FieldMatchWeighted的分數由兩部分組成,baseScore和bonusScore,計算公式可以簡單表示為:(A*baseScore + bonusScore) / (A + 1)。通過A來調節baseScore所佔的比重。baseScore的計算邏輯可以表示為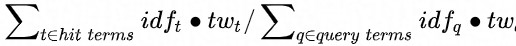 。tw表示term的權重,由查詢分析產出,預設為1。bonusScore為加權分數,只有當查詢詞和欄位精確匹配、查詢詞是欄位的一個片段時才進行加權。可以通過FieldMatchWeighted提供的介面函數對paramA與加權分數進行調整。
。tw表示term的權重,由查詢分析產出,預設為1。bonusScore為加權分數,只有當查詢詞和欄位精確匹配、查詢詞是欄位的一個片段時才進行加權。可以通過FieldMatchWeighted提供的介面函數對paramA與加權分數進行調整。
函數列表
函數原型 | 函數簡介 |
FieldMatchWeighted create(OpsScorerInitParams params, CString indexName, CString fieldName) | 建立FieldMatchWeighted對象 |
void setGroupScoreMergeOp(CString opName) | 設定多個query group結果的merge方式,可以是sum和max,預設為sum |
void setParamA(double paramA) | 設定參數A |
void setExactMatchBonus(double exactMatchBonus) | 設定exact match bonus |
void setNgramMatchBonus(double ngramMatchBonus) | 設定ngram match bonus |
double evaluate(OpsScoreParams params) | 計算查詢詞在指定欄位上的匹配度 |
函數詳情
FieldMatchWeighted create(OpsScorerInitParams params, CString indexName, CString fieldName)
建立FieldMatchWeighted對象,需要指定待匹配的索引名稱和欄位名稱。參數列表:params — 初始化輸入參數,詳情請參考OpsScorerInitParams手冊。indexName — 指定的索引名,必須為常量。fieldName — 索引下的欄位名,該欄位需要為TEXT或者SHORT_TEXT,並且分詞類型為中文基礎分詞、自訂分詞、單字分詞、英文分詞、模糊分詞,必須是常量。
void setGroupScoreMergeOp(CString opName)
設定多個查詢分組之間分數組合規則,目前僅支援max、sum,如果沒有設定預設多個group分數進行sum。該函數必須在算分外掛程式初始化階段調用。查詢分組是指經過查詢分析處理之後對原始查詢詞進行的擴充,預設只有一個查詢分組。參數列表:opName — 多個查詢分組分數組合規則,目前支援max與sum。
void setParamA(double paramA)
設定參數A的值,該參數用於控制baseScore在整體分數中的權重。該函數必須在算分外掛程式初始化階段調用。參數列表:paramA — A的值,預設為0.5。
void setExactMatchBonus(double exactMatchBonus)
設定查詢詞與欄位精確匹配時的加權分數,精確匹配表示查詢詞語欄位內容完全相同。該函數必須在算分外掛程式初始化階段調用。參數列表:exactMatchBonus — 加權分數,預設為1.0。
void setNgramMatchBonus(double ngramMatchBonus)
設定查詢詞是欄位的一個片段時的加權分數,該函數必須在算分外掛程式初始化階段調用。參數列表:ngramMatchBonus — 加權分數,預設為0.6。
double evaluate(OpsScoreParams params)
計算查詢詞在指定索引的指定欄位上的匹配分數。參數列表:params — 算分輸入參數,詳情請參考OpsScoreParams手冊。傳回值:返回查詢詞在欄位上的文本相關性,取值範圍為[0, 1]。程式碼範例:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.features.similarity.fieldmatch.FieldMatchWeighted;
class BasicSimilarityScorer {
FieldMatchWeighted _f1;
boolean init(OpsScorerInitParams params) {
_f1 = FieldMatchWeighted.create(params, "title_index", "title");
_f1.setGroupScoreMergeOp("max");
_f1.setParamA(1);
_f1.setExactMatchBonus(0.5);
_f1.setNgramMatchBonus(0.3);
return true;
}
double score(OpsScoreParams params) {
return _f1.evaluate(params);
}
}