本篇文檔主要介紹定製排序模型的特徵類型配置屬性,不同特徵配置有相應限制,以下是對應規範和限制。
介紹
本篇文檔主要介紹定製排序模型的特徵類型配置屬性,不同特徵配置有相應限制,以下是對應規範和限制。
公用屬性
欄位名 | 是否必選 | 含義 |
feature_name | 是 | feature_name會被當作最終輸出的feature的首碼 |
feature_type | 是 | 即下文中的類型 |
id_feature(離散ID特徵)
id feature是一個sparse feature,是一種最簡單的離散特徵,只是簡單的將某個欄位的值與使用者配置的feature名字拼接。適用字串和整型資料
raw_feature(原始數值特徵)
-raw feature是一種dense的feature,是直接引用原始feature的欄位值作為feature的value。適用於浮點型和整型。
-embedding等輸入可以設定value_dimension,數值用不可見字元ascii(29)分割拼接成字串。
參數名 | 是否必須 | 類型 | 樣本值 | 描述 |
value_dimension | 否 | int | 128 | 輸出的欄位的維度,預設為1 |
combo_feature(組合交叉特徵)
適用於字串和整型特徵的組合,不要嘗試對浮點值特徵作為輸入。
combo feature是多個欄位(或運算式)的組合(即笛卡爾積),id feature可以看成是一種特殊的combo feature,即參與交叉欄位只有一個的combo feature。一般來講,參與交叉的各個欄位來自不同的表(比如user特徵和item特徵進行交叉)。
lookup_feature(匹配尋找特徵)
lookup feature 依賴 map 和 key 兩個欄位,map是一個多值string(MultiString)類型的欄位,其中每一個string的樣子如"k1:v2"。;key可以是一個任意類型的欄位。產生特徵時,先是取出key的值,將其轉換成string類型,然後在map欄位所持有的kv對中進行匹配,擷取最終的特徵。item的多值用多值分隔字元ascii(29)分隔。
參數名 | 是否必須 | 類型 | 樣本值 | 取值範圍 | 描述 |
map | 是 | string | 如系統內建基礎特徵:"system_query_ctr_decay" | 多值string類型的欄位,其中每一個string形如"k1:v2" | |
key | 是 | string | 如系統內建基礎特徵:"system_raw_q_ultra" | 任意類型的欄位,產生特徵時轉換為string,從map中匹配 | |
combiner | 否 | string |
| 存在多個相同key時,通過combiner組合多個查到的值,預設為sum |
overlap_feature(匹配重疊特徵)
用來輸出一些字串字詞匹配資訊的feature
參數名 | 是否必須 | 類型 | 樣本值 | 取值範圍 | 描述 |
query | 是 | string | "user:attr1" | 多值string類型的欄位,分隔字元使用'\u001d'(ascii(29)) | |
title | 是 | string | "item:attr2" | 多值string類型的欄位,分隔字元使用'\u001d'(ascii(29)) | |
method | 是 | string |
|
|
樣本
query為high,high2,fiberglass,abc
title為high,quality,fiberglass,tube,for,golf,bag
method | separator | feature |
common_word | high_fiberglass | |
diff_word | " " | high2 abc |
query_common_ratio | 5 | |
title_common_ratio | 28 | |
is_contain | 0 | |
is_equal | 0 |
特徵產生
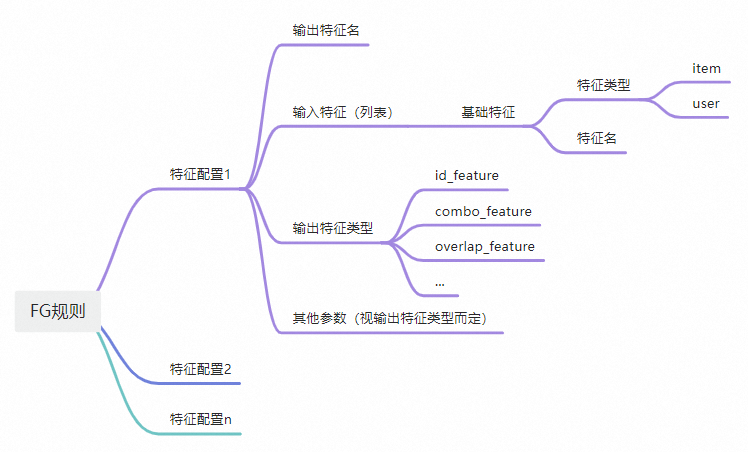
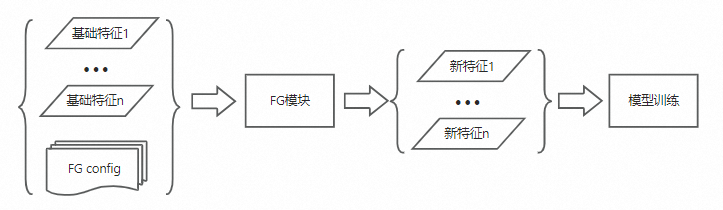
除了基礎特徵,模型訓練實際用的特徵會更加複雜,比如交叉多個基礎特徵產生新的訓練特徵,即特徵產生過程。目前對排序模型而言,按照特徵產生(FeatureGenerate)規則進行配置,即可得到需要的訓練特徵,如圖所示:
FG規則: