Cava是OpenSearch引擎團隊基於llvm實現的一門高效的程式設計語言,它的文法和Java類似,效能與C++相當。Cava是一門物件導向的程式設計語言,支援即時編譯(jit),支援各種安全檢查保證程式更加健壯。使用Cava和OpenSearch提供的cava庫,在OpenSearch中可以定製自己的排序外掛程式,相比於OpenSearch支援的運算式,使用Cava實現排序外掛程式具有以下優點:
更強的定製能力:Cava提供了較運算式更加豐富的文法功能,比如for迴圈,函數定義,類定義等,使用者可以實現自己的業務需求
更易於維護:Cava實現的排序外掛程式比運算式更具有可讀性,更易於維護
更易於接受:Cava的文法和Java類似,熟悉Java的同學很容易使用Cava進行開發,學習成本較低
Cava外掛程式僅支援獨享型應用配置
Cava外掛程式目前僅在業務排序中生效
Cava文法可在產品文檔中 開發指南—>排序外掛程式Cava 模組下查看
流程示範
建立策略:在“策略管理”頁點擊“建立”,“應用範圍”選擇“業務排序”,“類型”選擇“cava指令碼”:
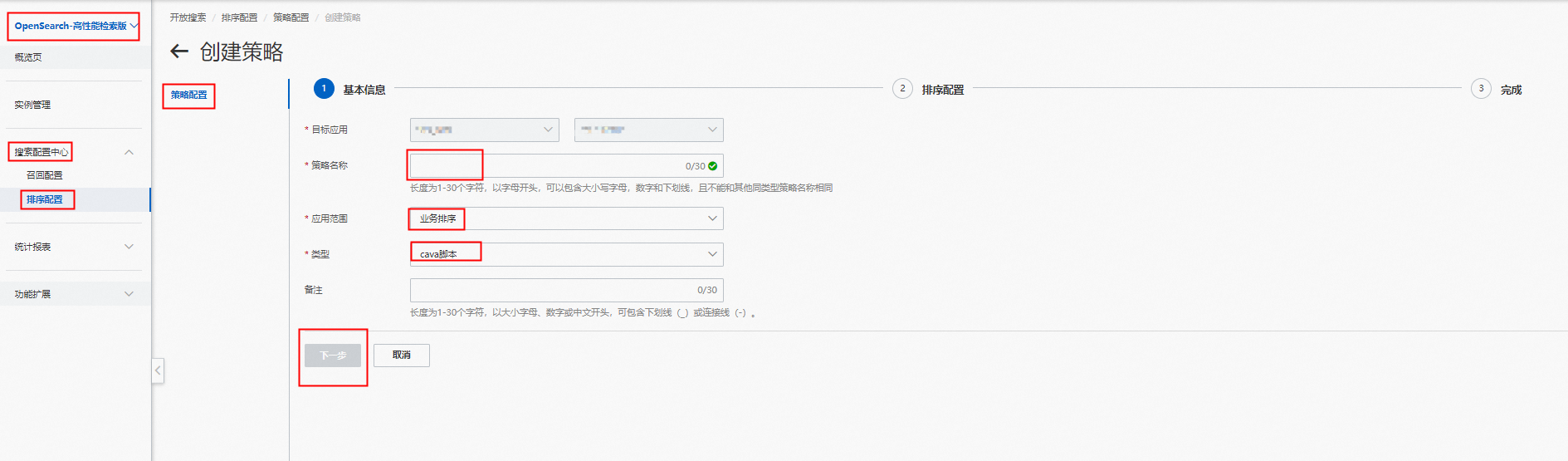
添加指令檔:添加指令檔,編輯cava指令碼;也可本地上傳指令檔,支援JSON格式檔案:

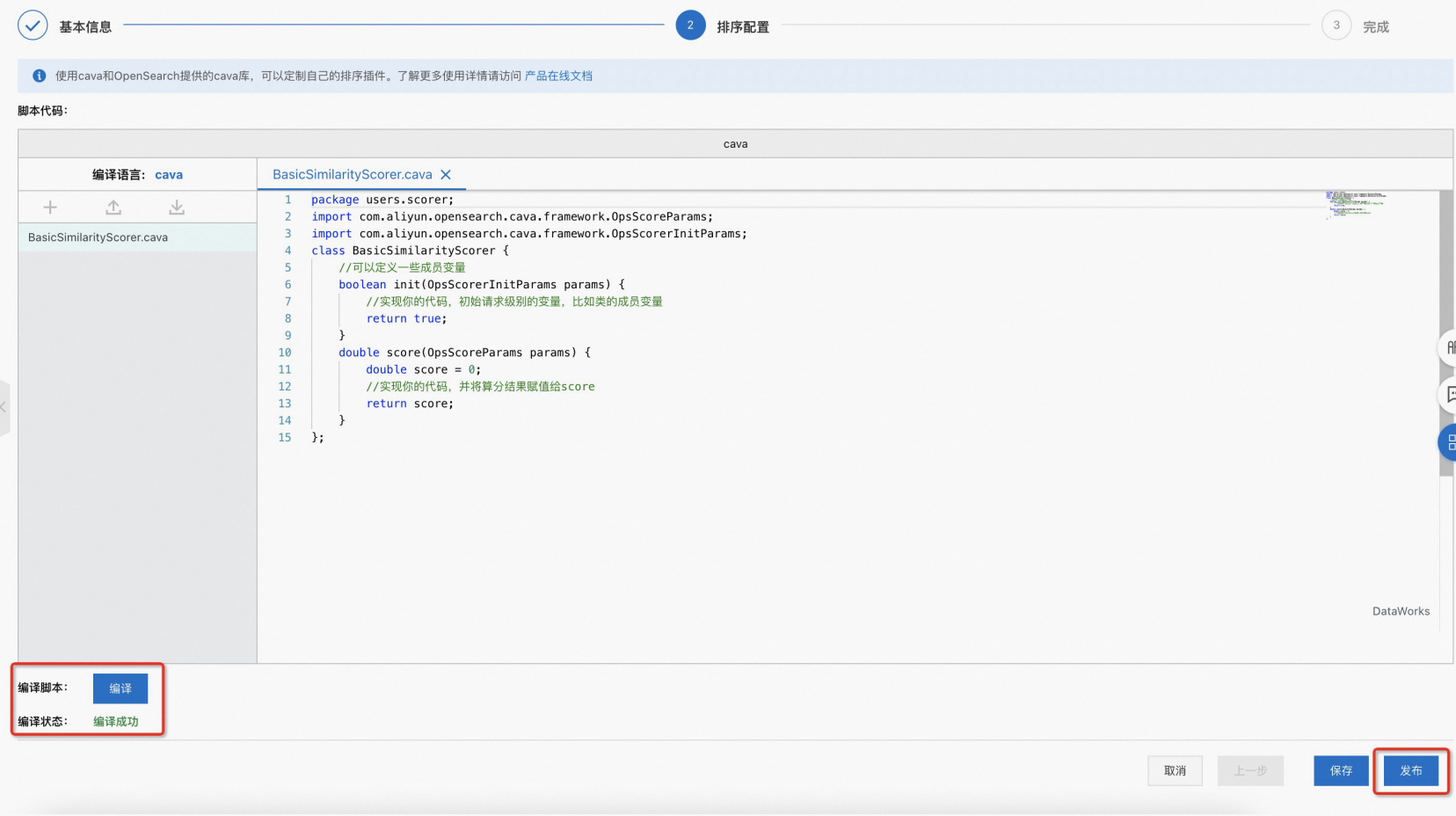
編譯並發布指令碼:指令檔編輯完成後,點擊“編譯”可對所有指令檔進行編譯,並在下方展示編譯狀態;編譯通過後,點擊發布即可發布當前指令碼;指令碼發布後不可重新編輯
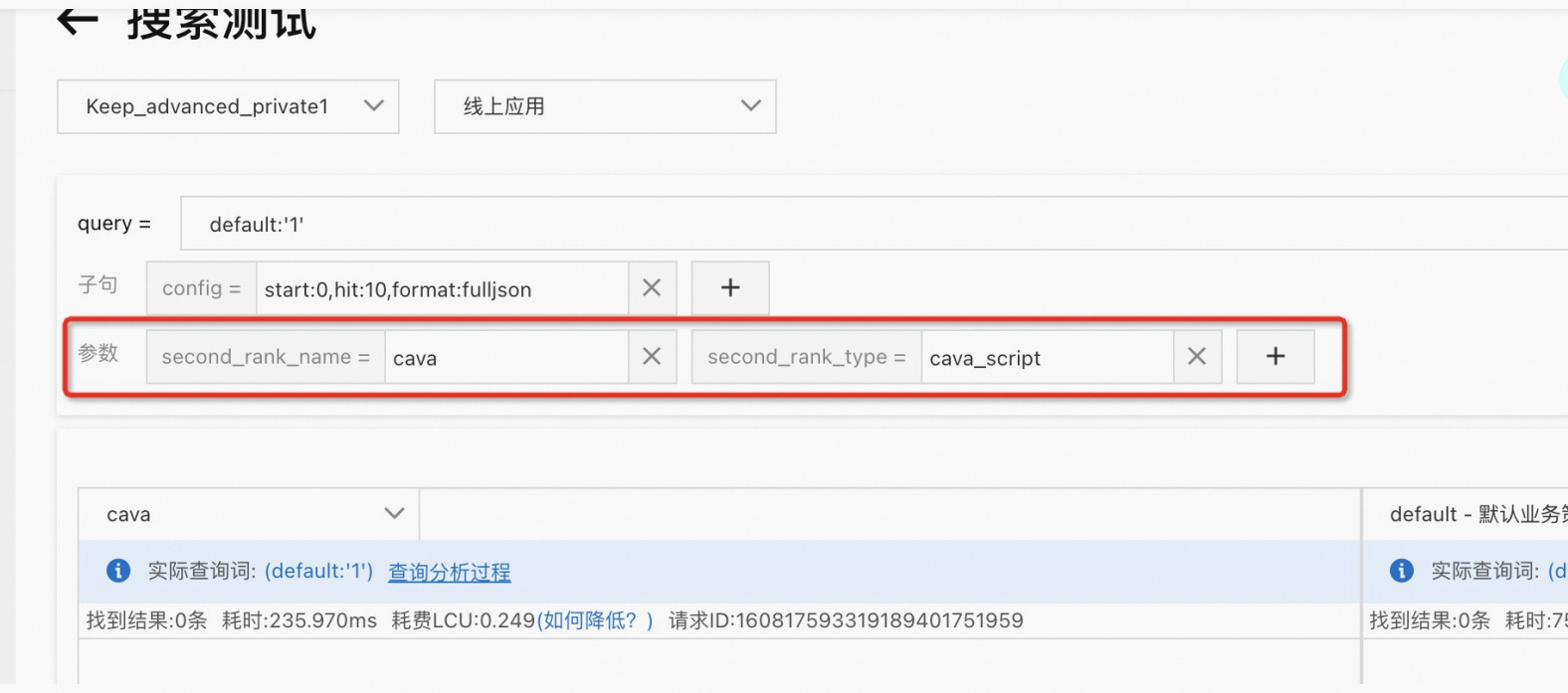
查看排序效果:在搜尋測試中輸入設定參數
second_rank_name=“策略名稱稱”,second_rank_type=cava_script
代碼中參數配置如下:(以Java為例):
...
// 建立參數對象
SearchParams searchParams = new SearchParams(config);
...
//建立rank對象
Rank rank=new Rank();
//設定調用的CAVA指令碼
rank.setSecondRankName("cava指令碼名稱");
//設定排序類型 - CAVA 指令碼
rank.setSecondRankType(RankType.CAVA_SCRIPT);
//將排序策略加入到參數對象中
searchParams.setRank(rank);常見參數擷取
擷取向量分:
import com.aliyun.opensearch.cava.features.similarity.ProximaScore;
ProximaScore _proximaScoreVector;
_proximaScoreVector = ProximaScore.create(params, "{{indexes.vector_index}}"); //對應的向量索引名稱
float proximaScoreVector = _proximaScoreVector.evaluate(params);注意事項
Cava外掛程式目前僅支援獨享型應用配置;
Cava指令碼單檔案大小限制為10K,單個Cava排序策略最多可以建立5個指令檔,單個應用執行個體最多支援50個Cava排序策略;
Cava指令碼發布後不可編輯,如需修改可在策略管理頁複製建立Cava指令碼類排序策略;
SDK中配置的Cava指令碼必須是發行的,未發布的Cava指令碼僅支援在搜尋測試中測試。