我的模型頁面用於管理您建立和匯入的模型。通過該頁面,您可以將本地訓練的 LoRA 模型從阿里雲Object Storage Service 匯入到百鍊平台。
使用前提
匯入前,請確保滿足以下條件:
OSS Bucket 準備:已建立 OSS Bucket,並為目標 Bucket 添加標籤。
說明支援的 OSS Bucket 儲存類型不包括歸檔、冷歸檔或深度冷歸檔。支援內容加密的 Bucket。支援私人的Bucket。
不支援訪問OSS Bucket根目錄下的檔案,請您在OSS Bucket下選擇已有的子目錄或建立一個子目錄供阿里雲百鍊訪問。
支援匯入任意大小的模型檔案,匯入後將使用阿里雲百鍊提供的免費儲存空間。
模型檔案準備:模型檔案需符合匯入要求與限制。模型檔案夾需直接放在 OSS Bucket 中,系統會自動識別。
支援匯入的基本模型
當前支援匯入以下基本模型的 LoRA 微調版本:
模型系列 | 模型名稱 |
千問3 | 千問3-32B |
千問3-14B | |
千問3-8B | |
千問3-4B-Instruct-2507 | |
千問3-VL | 千問3-VL-8B-Instruct |
千問2.5 | 千問2.5-72B-Instruct |
千問2.5-32B-Instruct | |
千問2.5-14B-Instruct | |
千問2.5-7B-Instruct | |
千問2.5-VL | 千問2.5-VL-72B-Instruct |
千問2.5-VL-7B-Instruct |
操作步驟
按照以下步驟將 LoRA 模型從 OSS 匯入到百鍊平台:
在我的模型頁面,點擊导入模型按鈕。
在匯入模型頁面中,填寫以下資訊:
模型名稱:輸入模型的顯示名稱,最多50個字元。
基本模型:選擇該 LoRA 模型對應的基本模型。
匯入來源:當前僅支援"從OSS匯入",系統已預設選中。
Bucket:選擇儲存模型檔案的 OSS Bucket。
確認資訊無誤後,點擊确定提交匯入請求。系統將自動驗證模型檔案格式和完整性,驗證通過後開始匯入。匯入完成後,您可以在我的模型頁面查看匯入的模型,並進行部署、增量訓練等操作。
匯入要求與限制
重要:目前的版本僅支援匯入 LoRA(Low-Rank Adaptation)模型,不支援匯入全參微調模型。
匯入 LoRA 模型前,請確保滿足以下要求:
必需檔案:OSS Bucket 中需包含以下檔案:
adapter_model.safetensors:LoRA 適配器的權重檔案,採用 SafeTensors 格式儲存。
adapter_config.json:LoRA 適配器的設定檔,包含 rank、alpha 等關鍵參數資訊。
rank 參數限制:rank 值必須為 8、16、32 或 64 中的一個,且同一模型的所有 LoRA 層必須使用相同的 rank 值。
修改詞彙表的模型:如果訓練過程中添加了新 token 或修改了原始詞彙表(vocab),該模型無法匯入。系統要求使用與基本模型完全一致的詞彙表。
修改對話模板的模型:如果訓練過程中修改了 chat_template 配置,該模型無法匯入。系統僅支援使用與對應開源基本模型預設配置一致的 chat_template。
chat_template 配置通常位於以下位置:
模型的 config.json 檔案中的
chat_template欄位。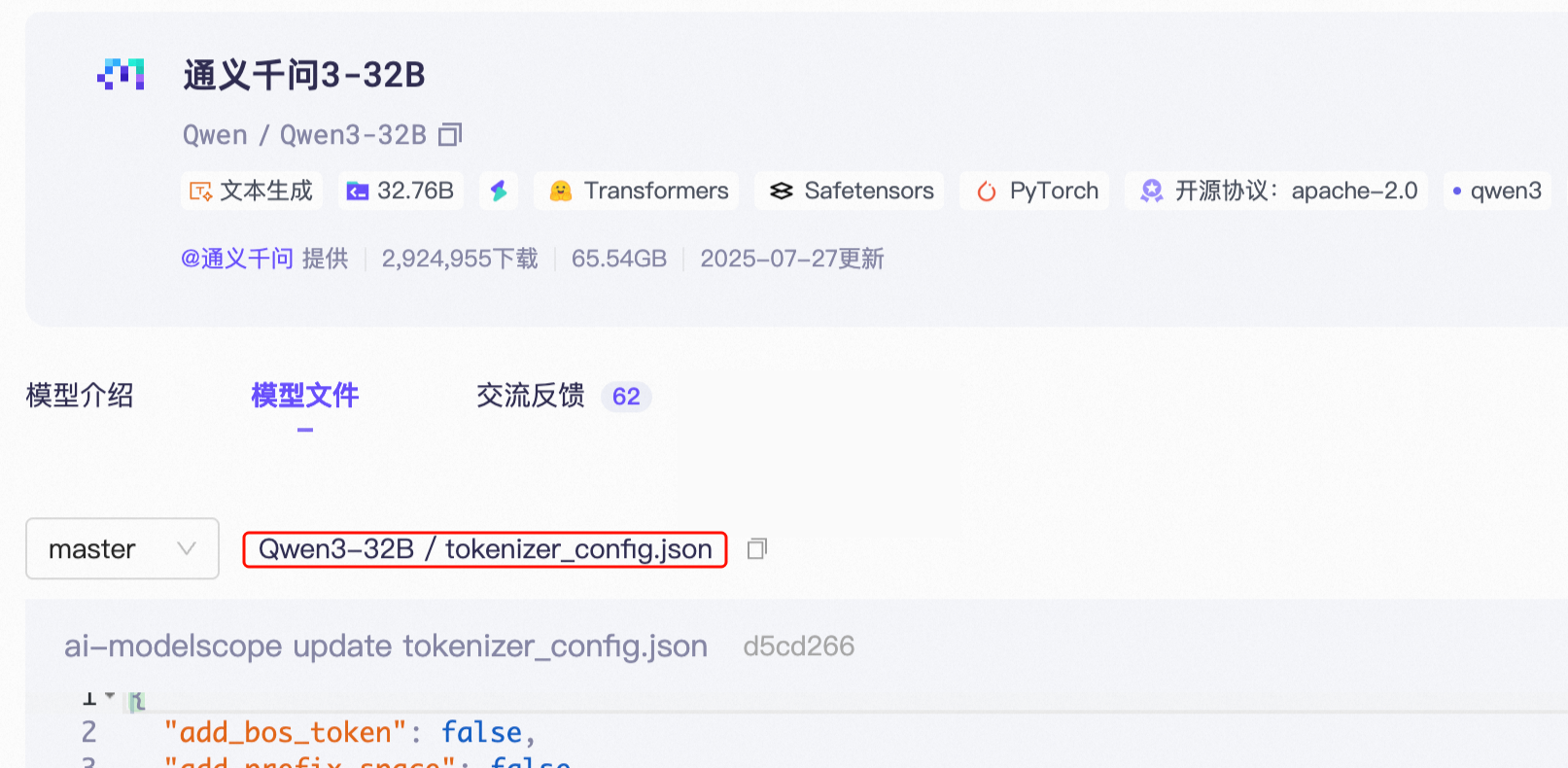
tokenizer_config.json 檔案中的
chat_template欄位。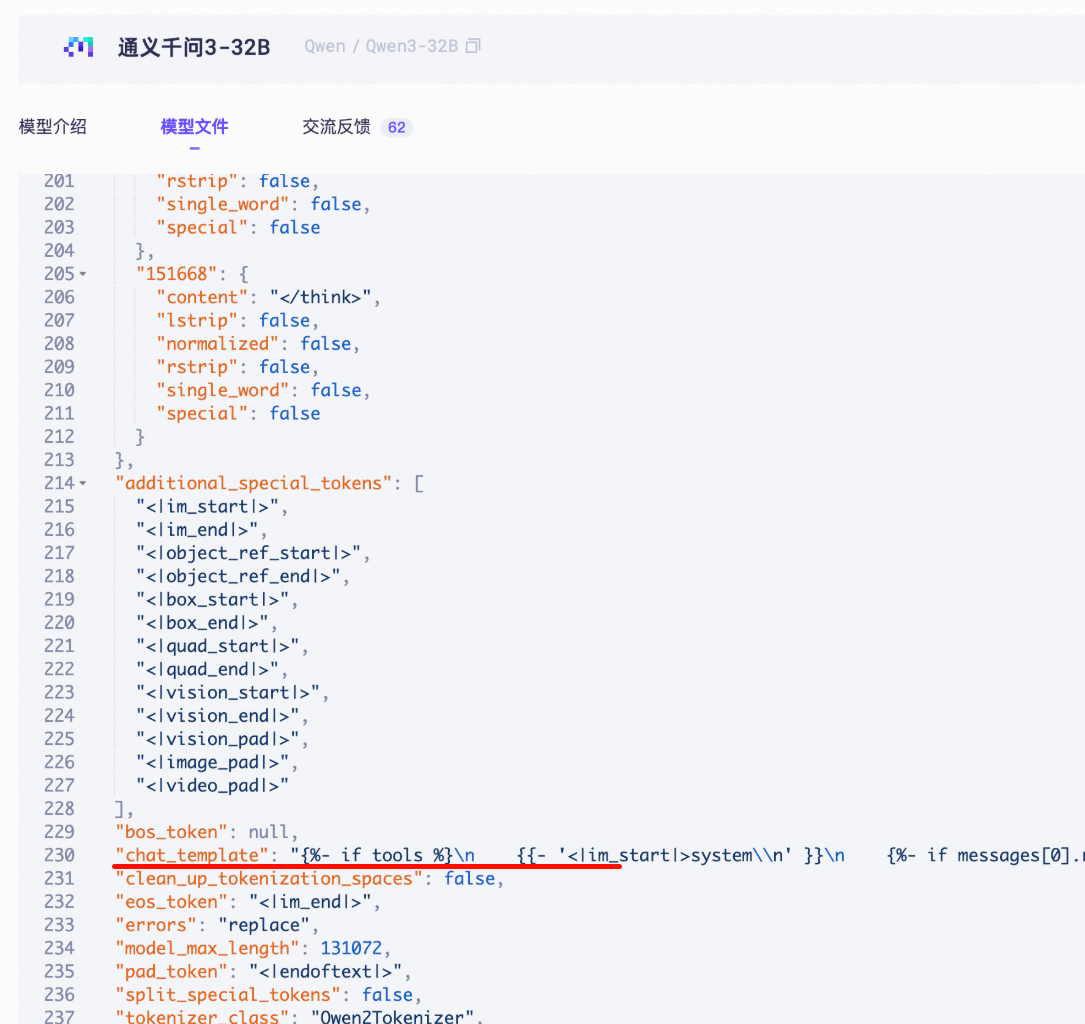
未凍結 VIT 的視覺語言模型:對於 VL(Vision-Language)模型,必須凍結 Vision Transformer(VIT)部分。如果 LoRA adapter 中包含 visual 相關的權重參數(即未凍結 VIT),該模型無法匯入。
可以運行以下代碼判斷。
from safetensors import safe_open import argparse def print_safetensor_structure(file_path): print(f"Loading safetensor file: {file_path}") print("="*80) with safe_open(file_path, framework="pt") as f: keys = f.keys() print(f"Found {len(keys)} tensors in the file:\n") for key in sorted(keys): tensor = f.get_tensor(key) shape = tuple(tensor.shape) dtype = str(tensor.dtype) device = tensor.device if hasattr(tensor, 'device') else 'cpu' lora_tag = " [LoRA]" if "lora_A" in key or "lora_B" in key else "" print(f"[{dtype:>14}] {shape} | {key} {lora_tag}") if __name__ == "__main__": parser = argparse.ArgumentParser(description="Print structure of a .safetensors LoRA adapter.") parser.add_argument("filepath", type=str, help="Path to the .safetensors file") args = parser.parse_args() print_safetensor_structure(args.filepath)判斷方法:檢查 adapt_model.safetensors 檔案中是否包含
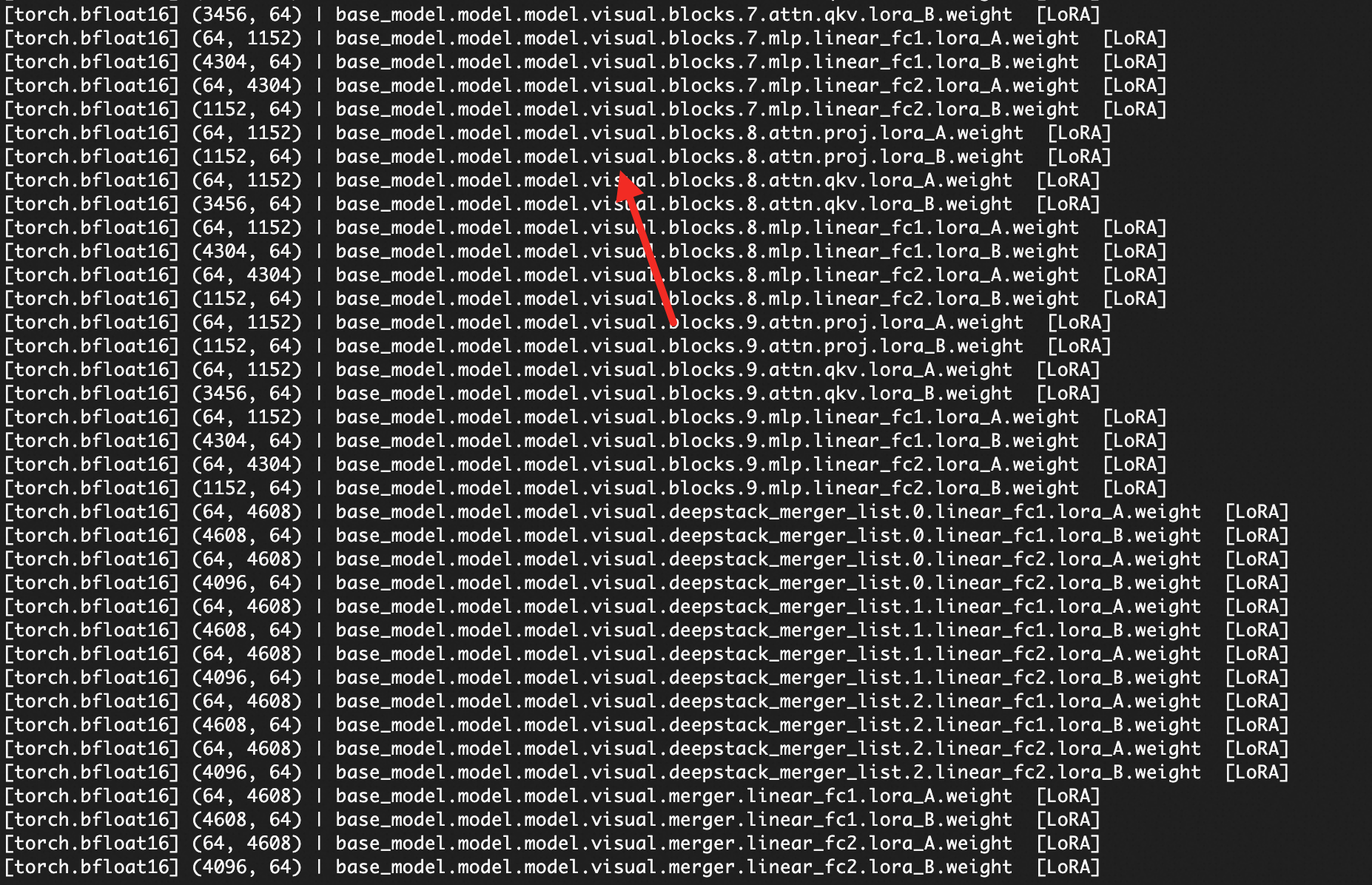
visual相關的權重參數。如果檔案中存在以visual開頭的參數鍵(例如visual.encoder.layer.0...),說明 VIT 部分未被凍結,該模型無法匯入。
常見問題
為什麼匯入的模型與本地使用 vLLM、SGLang 推理的效果不一致?
百鍊平台的推理引擎參數設定可能與您本地使用的推理架構預設值不同。為確保效果一致,建議在調用 API 時調整以下參數:
參數名稱 | 推薦值(對應 vLLM 預設值) |
temperature | 取值範圍:[0, 2)。設定為 1.0 等同於 vLLM 引擎預設值。 |
top_p | 取值範圍:(0, 1.0]。設定為 1.0 等同於 vLLM 引擎預設值。 |
top_k | 取值為 None 或大於 100 時,表示不啟用 top_k 策略,此時僅有 top_p 策略生效。設定為 99 不支援全採樣,該值接近 vLLM 預設值 0(全採樣)。 |
presence_penalty | 取值範圍:[-2.0, 2.0]。設定為 0 等同於 vLLM 引擎預設值。 |
repetition_penalty(DashScope 協議) | 提高 repetition_penalty 可以降低模型產生的重複度,1.0 表示不做懲罰。取值範圍:大於 0。設定為 1.0 等同於 vLLM 引擎預設值。 |
說明:以上參數值基於 vLLM 引擎的預設配置。如果您的本地環境使用 SGLang 或其他推理架構,請參考對應架構的文檔調整參數。
如果您是首次從 OSS 向阿里雲百鍊匯入檔案,請先按照介面提示完成授權,並為目標 OSS Bucket 添加bailian-datahub-access標籤,然後再進行匯入。
如果您尚不清楚主帳號和子帳號的概念和區別,請先閱讀許可權管理。
使用主帳號
單擊前往授權。
在 匯入方式 中選擇 從OSS匯入 後,頁面會顯示"您還未授權OSS"的提示資訊,在提示欄右側找到 前往授權 連結。
在彈出的對話方塊中,單擊確認授權,系統將為您自動開通OSS服務關聯角色(必要條件)。
通常秒級生效,服務高峰期可能會稍有延遲。
為目標 OSS Bucket 添加
bailian-datahub-access標籤。該標籤用於標記阿里雲百鍊可訪問的 Bucket,未標記的 Bucket 阿里雲百鍊無法訪問。
訪問OSS管理主控台,單擊左側導覽列中的Bucket 列表,即可查看您已建立的Bucket。
在待添加標籤的Bucket标签列,懸停滑鼠於
 表徵圖上,然後單擊前往編輯。
表徵圖上,然後單擊前往編輯。單擊建立標籤。
單擊標籤,添加標籤名為
bailian-datahub-access,標籤值為read的標籤,然後單擊儲存。
返回匯入模型介面,重新選擇目標 Bucket 再嘗試匯入。
請注意,阿里雲百鍊不支援訪問儲存在 Bucket 根目錄下的檔案。請您選擇 Bucket 下的現有檔案夾或建立一個檔案夾供阿里雲百鍊訪問。
使用子帳號
單擊前往授權。
在彈出的對話方塊中,單擊確認授權。介面會提示授權失敗、目前使用者沒有建立服務關聯角色的許可權(因為當前子帳號沒有建立服務關聯角色的許可權。接下來需要先授予子帳號建立服務關聯角色的許可權,再授予子帳號通過阿里雲百鍊訪問OSS的許可權)。
對話方塊中顯示 Service Name 為
datahub.sfm.aliyuncs.com,服務關聯角色名稱為AliyunServiceRoleForSFMDataHubOSSImport,執行該操作所需的使用者權限為ram:CreateServiceLinkedRole。授予子帳號建立服務關聯角色的許可權。
需主帳號登入RAM控制台,在左側導覽列,選擇,然後單擊介面上的建立權限原則。
在指令碼編輯的
Effect、Action、Resource、Condition中分別輸入以下指令碼中的對應內容後,單擊確定。{ "Action": [ "ram:CreateServiceLinkedRole" ], "Resource": "*", "Effect": "Allow", "Condition": { "StringEquals": { "ram:ServiceName": "datahub.sfm.aliyuncs.com" } } }輸入權限原則名稱後,單擊確定。
本樣本中,權限原則名稱為
服務關聯角色。在左側導覽列,選擇。在頁面列表中找到待授權的子帳號,然後單擊子帳號操作列的添加許可權。
在權限原則中選擇剛才建立的權限原則(自訂策略),單擊確認新增授權。至此,子帳號擁有了建立服務關聯角色的許可權。
授權子帳號通過阿里雲百鍊訪問OSS。
返回匯入模型介面,單擊前往授權。
匯入方式選擇OSS後,介面提示您還未授權OSS。
在彈出的對話方塊中,單擊确认授权,系統將為您自動開通OSS服務關聯角色(必要條件)。
通常秒級生效,服務高峰期可能會稍有延遲。
為目標 OSS Bucket 添加
bailian-datahub-access標籤。該標籤用於標記阿里雲百鍊可訪問的 Bucket,未標記的 Bucket 阿里雲百鍊無法訪問。
訪問OSS管理主控台,單擊左側導覽列中的Bucket 列表,即可查看您已建立的Bucket。
在待添加標籤的Bucket标签列,懸停滑鼠於
表徵圖上,然後單擊前往編輯。單擊建立標籤。
單擊標籤,添加標籤名為
bailian-datahub-access,標籤值為read的標籤,然後單擊儲存。
返回匯入模型介面,重新選擇目標 Bucket 再嘗試匯入。
請注意,阿里雲百鍊不支援訪問儲存在 Bucket 根目錄下的檔案。請您選擇 Bucket 下的現有檔案夾或建立一個檔案夾供阿里雲百鍊訪問。