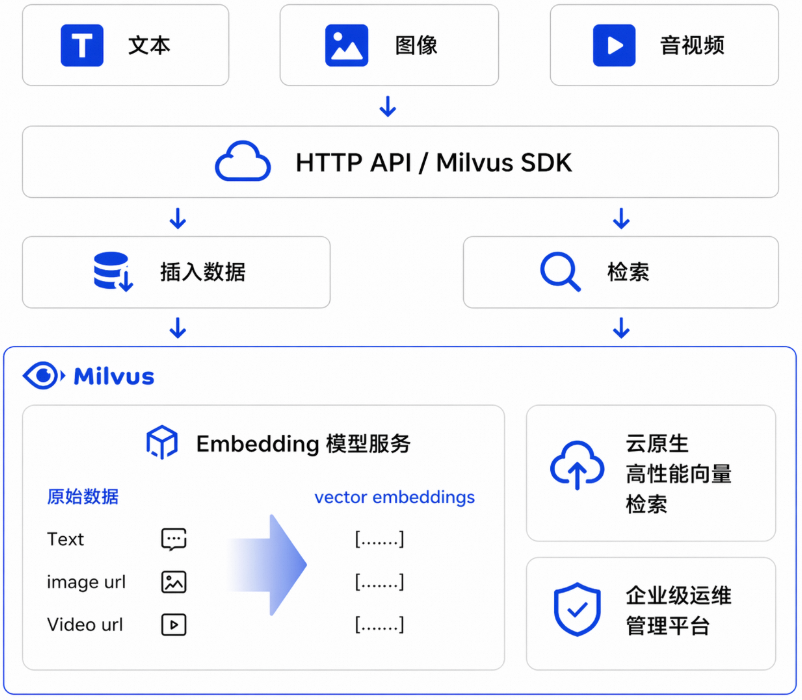
阿里雲 Milvus Embedding 服務是內建於 Milvus 的託管式向量化能力。開通後,在資料寫入和檢索時可直接傳入原始文本或多模態資料(圖片、視頻),由系統自動完成向量產生,無需單獨部署 Embedding 推理服務。
功能概覽
功能 | 說明 |
控制台一站式管理 | 在控制台完成 Embedding 模型服務的開通、配置與執行個體綁定。 |
託管式模型能力 | 平台提供託管式 Embedding 服務,無需自建推理服務。 |
未經處理資料直接寫入和檢索 | 寫入、更新和查詢時直接傳入原始文本或多模態內容,系統自動完成向量化。 |
多模型支援 | 支援多個 Embedding 模型,可根據業務情境選擇和切換。 |
調用量與 Token 統計 | 提供執行個體級的調用量與 Token 用量統計。 |
監控警示 | 支援 QPS、成功率、RT 等指標的監控與警示配置。 |
使用步驟
開啟 Embedding 服務
在 Milvus 控制台左側導航中選擇AI 中心,進入 Embedding 服務頁面,單擊 开通 Embedding 服务 完成開通。
開通後頁面展示可用的模型列表,包括:
text-embedding-v4:基於 Qwen3 的多語言文本向量模型,支援 64~2048 維自訂向量維度。
text-embedding-v3:通用文本向量模型。
text-embedding-v2:通用文本向量模型。
qwen3-vl-embedding:多模態向量模型,支援文本、圖片、視頻輸入。
Embedding 服務按地區獨立開通,切換地區後需在新地區開通。
關聯 Milvus 執行個體
Embedding 能力依賴 Milvus 2.6 版本執行個體,支援以下兩種關聯方式:
建立 2.6 版本叢集時直接開啟 Embedding。
進入 AI 中心對存量 2.6 版本執行個體啟用 Embedding 模型。
在Embedding 服务列表中,單擊目標服务 ID右側的批量启用,在批量启用彈窗中選擇執行個體。
查看調用指標
進入AI 中心在Embedding 服务頁面,單擊模型對應的 查看调用信息,可查看以下指標:
Token Usage Overview:Token 消耗總量趨勢。
QPS:每秒請求數。
Success Rate:請求成功率。
Token Usage/s:每秒 Token 使用量。
Average RT:平均回應時間。
支援按執行個體 ID、時間範圍和採樣間隔進行篩選。
案例一:文搜文語義檢索
情境說明
將一批原始文本寫入 Milvus,無需預先產生向量。查詢時直接輸入自然語言問題,Milvus 自動完成查詢向量化並返回語義最相關的結果。適用於知識庫問答、文檔搜尋、FAQ 檢索等情境。
操作步驟
建立 Collection,定義原始文字欄位
document和向量欄位dense。通過
Function綁定text-embedding-v4模型。插入測試文本資料。
使用自然語言問題發起檢索,返回最相關的文本片段。
範例程式碼
import random
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530",
token='root:xxx',
)
# ========== 建立 Collection ==========
collection_name = 'demo1'
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("document", DataType.VARCHAR, max_length=9000)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1024)
text_embedding_function = Function(
name="dashscope_api_test123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "aliyun_milvus",
"model_name": "text-embedding-v4"
}
)
schema.add_function(text_embedding_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.drop_collection(collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
insert_data = []
record_id = 1
mock_texts = [
"向量資料庫通過將文本轉換為高維向量來實現語義檢索,能夠理解查詢的真實意圖。",
"深度學習模型可以從大量圖片資料中學習特徵表示,用於映像分類和目標檢測等任務。",
"檢索增強產生通過召回相關文檔為大模型提供外部知識,減少幻覺並提升答案可靠性。",
"在客服情境中,語義搜尋可以快速定位歷史工單,提高首次響應效率和問題解決率。",
"相似性搜尋常用餘弦距離衡量向量方向接近程度,適合文本語義匹配任務。",
"資料清洗是向量化前的重要步驟,去噪和統一格式能顯著提升召回品質。",
"embedding 維度並非越高越好,需要在效果、延遲和儲存成本之間做平衡。",
"通過分塊策略將長文檔切分為小段,可以提高檢索命中率並減少上下文冗餘。",
"為每條知識添加來源欄位有助於結果可解釋性,方便在前端展示引用證據。",
"多語言檢索可藉助統一向量空間實現跨語言匹配,提升國際化系統體驗。",
"索引參數如 ef 和 M 會影響 HNSW 的召回率與查詢效能,需要結合業務調優。",
"在上線前進行離線評測可以量化不同模型和參數組合的檢索品質差異。",
"向量庫中的中繼資料過濾能夠與語義召回結合,實現更精準的範圍限定搜尋。",
"對於高頻問題,可將檢索結果做短時緩衝以降低後端計算壓力和回應時間。",
"語義檢索鏈路應記錄查詢日誌,便於後續分析零結果查詢並持續最佳化知識庫。",
"當知識內容更新頻繁時,增量索引策略可以減少全量重建帶來的資源消耗。",
"在問答系統中加入重排序模型可以提升前幾條結果的相關性和可讀性。",
"為敏感性資料建立存取控制策略是企業級向量檢索系統的基礎安全要求。",
"合理設定 topK 能在覆蓋率與雜訊之間取得平衡,避免返回過多低相關結果。",
"將使用者反饋迴流到訓練與評估流程,可以持續改進檢索與問答整體效果。",
]
for text in mock_texts:
insert_data.append({
"id": record_id,
"document": text,
})
record_id += 1
BATCH_SIZE = 30
print(f"準備插入 {len(insert_data)} 條資料,batch_size={BATCH_SIZE}...")
for batch_start in range(0, len(insert_data), BATCH_SIZE):
batch = insert_data[batch_start:batch_start + BATCH_SIZE]
client.insert(collection_name, batch)
print(f" 已插入 {min(batch_start + BATCH_SIZE, len(insert_data))}/{len(insert_data)} 條")
print("資料插入完成!\n")
# ========== 測試1:文搜文(通過 dense 欄位做純文字語義檢索) ==========
print("=" * 60)
print("測試1:文搜文 - 查詢與向量資料庫相關的內容")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['什麼是語義檢索?向量資料庫如何工作?'],
anns_field='dense',
limit=3,
output_fields=['document'],
)
for hits in results:
for hit in hits:
print(f" id={hit['id']}, distance={hit['distance']:.4f}, document={hit['entity']['document'][:50]}")運行結果
準備插入 20 條資料,batch_size=30...
已插入 20/20 條
資料插入完成!
============================================================
測試1:文搜文 - 查詢與向量資料庫相關的內容
============================================================
id=1, distance=0.8197, document=向量資料庫通過將文本轉換為高維向量來實現語義檢索,能夠理解查詢的真實意圖。
id=13, distance=0.6906, document=向量庫中的中繼資料過濾能夠與語義召回結合,實現更精準的範圍限定搜尋。
id=18, distance=0.6563, document=為敏感性資料建立存取控制策略是企業級向量檢索系統的基礎安全要求。案例二:多模態檢索
情境說明
在零售、電商和內容平台情境中,檢索對象除文本外還包括圖片和視頻。Milvus Embedding 服務支援將文本與視覺內容納入統一的向量化與檢索流程,實現文搜圖/視頻、圖搜圖/視頻等跨模態檢索能力。
本樣本中使用的圖片,可從此處下載。
操作步驟
將本地測試圖片或視頻上傳到 OSS,產生可訪問的簽名 URL。
建立 Collection,定義文字欄位
document、多媒體地址欄位url、文本向量欄位dense和多模態向量欄位dense_mm。分別為文本和多媒體欄位綁定
text-embedding-v4與qwen3-vl-embedding。插入測試素材及對應文本描述。
執行文搜文、文搜圖/視頻、圖搜圖/視頻等檢索驗證。
範例程式碼
import glob
import os
import random
import oss2
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530",
token='root:xxx',
)
# ========== OSS 配置:上傳多媒體資源並產生簽名 URL ==========
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
OSS_ACCESS_KEY_ID = os.environ['OSS_ACCESS_KEY_ID']
OSS_ACCESS_KEY_SECRET = os.environ['OSS_ACCESS_KEY_SECRET']
OSS_ENDPOINT = 'https://oss-cn-hangzhou.aliyuncs.com'
OSS_BUCKET_NAME = '002test'
auth = oss2.Auth(OSS_ACCESS_KEY_ID, OSS_ACCESS_KEY_SECRET)
bucket = oss2.Bucket(auth, OSS_ENDPOINT, OSS_BUCKET_NAME)
def upload_and_sign(relative_path, oss_key_prefix="milvus-embedding-test"):
"""上傳本地多媒體資源到 OSS 並返回簽名 URL(有效期間 1 小時)"""
full_path = os.path.join(SCRIPT_DIR, relative_path)
oss_key = f"{oss_key_prefix}/{os.path.basename(relative_path)}"
bucket.put_object_from_file(oss_key, full_path)
signed_url = bucket.sign_url('GET', oss_key, 3600)
print(f" 上傳成功: {oss_key} -> {signed_url[:80]}...")
return signed_url
def upload_directory_with_patterns(
directory_relative_path,
patterns,
oss_key_prefix="milvus-embedding-test",
random_pick_count=None,
):
"""上傳目錄下匹配尾碼的多媒體檔案到 OSS,返回 {檔案名稱: 簽名 URL}"""
full_dir = os.path.join(SCRIPT_DIR, directory_relative_path)
matched_files = []
for pattern in patterns:
matched_files.extend(glob.glob(os.path.join(full_dir, pattern)))
matched_files = sorted(set(matched_files))
if random_pick_count is not None and len(matched_files) > random_pick_count:
matched_files = random.sample(matched_files, random_pick_count)
result = {}
for file_path in matched_files:
filename = os.path.basename(file_path)
relative_path = os.path.join(directory_relative_path, filename)
signed_url = upload_and_sign(relative_path, oss_key_prefix)
result[filename] = signed_url
return result
# 上傳 banana 和 orange 目錄下的測試素材到 OSS
print("上傳測試素材到 OSS...")
banana_urls = upload_directory_with_patterns("qwen-vl/train/banana", ["*.JPEG"])
orange_urls = upload_directory_with_patterns("qwen-vl/train/orange", ["*.JPEG"])
print(f"banana 目錄上傳 {len(banana_urls)} 張,orange 目錄上傳 {len(orange_urls)} 張")
print("圖片素材上傳完成!\n")
# 上傳視頻到 OSS(與圖片素材邏輯一致)
print("上傳視頻到 OSS...")
selected_video_urls = upload_directory_with_patterns(
"qwen-vl/short_video_10_of_42",
["*.mp4", "*.MP4", "*.mov", "*.MOV"],
random_pick_count=5,
)
print(f"short_video_10_of_42 目錄上傳並選用 {len(selected_video_urls)} 個視頻")
print("視頻上傳完成!\n")
banana_url_list = list(banana_urls.values())
orange_url_list = list(orange_urls.values())
selected_video_url_list = list(selected_video_urls.values())
# ========== 建立 Collection ==========
collection_name = 'demo11'
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("document", DataType.VARCHAR, max_length=9000)
schema.add_field("url", DataType.VARCHAR, max_length=9000)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1024)
schema.add_field("dense_mm", DataType.FLOAT_VECTOR, dim=1024)
text_embedding_function = Function(
name="dashscope_api_test123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "aliyun_milvus",
"model_name": "text-embedding-v4"
}
)
mm_embedding_function = Function(
name="dashscope_api_mm123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["url"],
output_field_names=["dense_mm"],
params={
"provider": "aliyun_milvus",
"model_name": "qwen3-vl-embedding",
"dim": "1024"
}
)
schema.add_function(text_embedding_function)
schema.add_function(mm_embedding_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
index_params.add_index(
field_name="dense_mm",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.drop_collection(collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
# ========== 插入中文測試資料,多媒體資源使用 OSS 簽名 URL ==========
banana_descriptions = [
'一串成熟的黃色香蕉掛在熱帶果園的樹上,陽光透過葉片灑下斑駁的光影。',
'超市水果區擺放著整齊的香蕉,旁邊的價簽標註著今日特價,吸引了不少顧客駐足挑選。',
'廚房桌上放著幾根香蕉和一杯牛奶,這是一份簡單而健康的早餐搭配。',
'剛從樹上摘下來的青皮香蕉整齊地碼放在竹筐裡,等待自然催熟後上市銷售。',
'小朋友手裡拿著一根香蕉,開心地在公園裡邊走邊吃,臉上洋溢著滿足的笑容。',
'烘焙師將熟透的香蕉搗成泥,準備製作一款經典的香蕉蛋糕,廚房裡瀰漫著甜香。',
'熱帶雨林中野生的香蕉樹成片生長,巨大的葉片在微風中輕輕搖曳。',
'早餐桌上切好的香蕉片搭配燕麥和優酪乳,是一份營養均衡的健康早餐。',
'水果攤老闆正在給顧客稱量一大串新鮮香蕉,秤上顯示剛好三斤。',
'幾根香蕉和蘋果、橙子一起擺放在果盤中,色彩鮮豔,賞心悅目。',
]
orange_descriptions = [
'果園裡掛滿枝頭的橙子在陽光下泛著金黃色的光澤,豐收的季節令人喜悅。',
'一杯鮮榨橙汁放在桌上,旁邊擺著切開的橙子,果肉飽滿多汁。',
'媽媽正在廚房裡剝橙子,空氣中瀰漫著清新的柑橘香氣,孩子們圍在旁邊等著吃。',
'超市貨架上整齊排列著臍橙和血橙,不同品種的橙子各有特色。',
'冬日午後,一盤切好的橙子擺在茶几上,是全家人最愛的下午茶水果。',
'橙子皮被巧手的奶奶晒乾後泡茶,據說有理氣健脾的功效。',
'果農小心翼翼地將剛採摘的橙子裝進紙箱,準備發往全國各地的客戶手中。',
'甜品店櫥窗裡展示著精美的橙子慕斯蛋糕,橙色的外觀十分誘人。',
'一顆被切成兩半的橙子露出鮮嫩的果肉,汁水豐富,讓人垂涎欲滴。',
'小區門口的水果店掛出了贛南臍橙到貨的招牌,引來不少居民排隊購買。',
]
video_descriptions = [
"一段水果主題短視頻,展示果園採摘與運輸過程。",
"一段水果門店陳列短視頻,鏡頭近距離展示果實細節。",
"一段飲品製作短視頻,包含切片、壓榨與裝杯過程。",
"一段甜品製作短視頻,展示果肉裝飾和成品呈現。",
]
insert_data = []
record_id = 1
for idx, img_url in enumerate(banana_url_list):
insert_data.append({
'id': record_id,
'document': banana_descriptions[idx],
'url': img_url,
})
record_id += 1
for idx, img_url in enumerate(orange_url_list):
insert_data.append({
'id': record_id,
'document': orange_descriptions[idx],
'url': img_url,
})
record_id += 1
for idx, video_url in enumerate(selected_video_url_list):
insert_data.append({
"id": record_id,
"document": video_descriptions[idx % len(video_descriptions)],
"url": video_url,
})
record_id += 1
# 純文字資料(url 欄位填文本,dense_mm 也會產生對應的文本向量)
insert_data.append({
'id': record_id,
'document': '向量資料庫通過將文本轉換為高維向量來實現語義檢索,能夠理解查詢的真實意圖。',
'url': '向量資料庫通過將文本轉換為高維向量來實現語義檢索,能夠理解查詢的真實意圖。',
})
record_id += 1
insert_data.append({
'id': record_id,
'document': '深度學習模型可以從大量圖片資料中學習特徵表示,用於映像分類和目標檢測等任務。',
'url': '深度學習模型可以從大量圖片資料中學習特徵表示,用於映像分類和目標檢測等任務。',
})
BATCH_SIZE = 20
print(f"準備插入 {len(insert_data)} 條資料,batch_size={BATCH_SIZE}...")
for batch_start in range(0, len(insert_data), BATCH_SIZE):
batch = insert_data[batch_start:batch_start + BATCH_SIZE]
client.insert(collection_name, batch)
print(f" 已插入 {min(batch_start + BATCH_SIZE, len(insert_data))}/{len(insert_data)} 條")
print("資料插入完成!\n")
# ========== 測試1:文搜文(通過 dense 欄位做純文字語義檢索) ==========
print("=" * 60)
print("測試1:文搜文 - 查詢與向量資料庫相關的內容")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['什麼是語義檢索?向量資料庫如何工作?'],
anns_field='dense',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
print(f" id={hit['id']}, distance={hit['distance']:.4f}, document={hit['entity']['document'][:50]}")
# ========== 測試2:文搜圖 / 視頻(通過 dense_mm 欄位,用文字查詢匹配多媒體內容) ==========
print("\n" + "=" * 60)
print("測試2:文搜圖 / 視頻 - 用文本描述搜尋香蕉相關的圖片和視頻素材")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['黃色香蕉'],
anns_field='dense_mm',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
has_image = "有圖" if hit['entity'].get('url') else "無圖"
print(f" id={hit['id']}, distance={hit['distance']:.4f}, [{has_image}] document={hit['entity']['document'][:50]}")
# ========== 測試3:圖搜圖 / 視頻(通過 dense_mm 欄位,用視覺素材查詢匹配多媒體內容) ==========
print("\n" + "=" * 60)
print("測試3:圖搜圖 / 視頻 - 用 orange 目錄中的視覺素材搜尋相似圖片和視頻")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=[orange_url_list[0]],
anns_field='dense_mm',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
has_media = "有媒體" if hit['entity'].get('url') else "無媒體"
print(f" id={hit['id']}, distance={hit['distance']:.4f}, [{has_media}] document={hit['entity']['document'][:50]}")運行結果
準備插入 27 條資料,batch_size=20...
已插入 20/27 條
已插入 27/27 條
資料插入完成!
============================================================
測試1:文搜文 - 查詢與向量資料庫相關的內容
============================================================
id=26, distance=0.8197, document=向量資料庫通過將文本轉換為高維向量來實現語義檢索,能夠理解查詢的真實意圖。
id=27, distance=0.3091, document=深度學習模型可以從大量圖片資料中學習特徵表示,用於映像分類和目標檢測等任務。
id=22, distance=0.2337, document=一段水果門店陳列短視頻,鏡頭近距離展示果實細節。
============================================================
測試2:文搜圖 / 視頻 - 用文本描述搜尋香蕉相關的圖片和視頻素材
============================================================
id=9, distance=0.4862, [有圖] document=水果攤老闆正在給顧客稱量一大串新鮮香蕉,秤上顯示剛好三斤。
id=1, distance=0.4834, [有圖] document=一串成熟的黃色香蕉掛在熱帶果園的樹上,陽光透過葉片灑下斑駁的光影。
id=7, distance=0.4797, [有圖] document=熱帶雨林中野生的香蕉樹成片生長,巨大的葉片在微風中輕輕搖曳。
============================================================
測試3:圖搜圖 / 視頻 - 用 orange 目錄中的視覺素材搜尋相似圖片和視頻
============================================================
id=11, distance=1.0000, [有媒體] document=果園裡掛滿枝頭的橙子在陽光下泛著金黃色的光澤,豐收的季節令人喜悅。
id=12, distance=0.9898, [有媒體] document=一杯鮮榨橙汁放在桌上,旁邊擺著切開的橙子,果肉飽滿多汁。
id=13, distance=0.9858, [有媒體] document=媽媽正在廚房裡剝橙子,空氣中瀰漫著清新的柑橘香氣,孩子們圍在旁邊等著吃。