MaxCompute Spark支援使用者使用原生的Spark本地模式,便於使用者進行小批量資料驗證和任務調試。本文以Spark 3.1為例介紹IDEA和Shell兩種使用方式。
使用IDEA調試
步驟一:下載並解壓Spark用戶端
點選連結或在終端輸入如下指令下載並解壓Spark用戶端,樣本為Spark
3.1.1-odps0.47.0版本。wget https://odps-repo.oss-cn-hangzhou.aliyuncs.com/spark/3.1.1-odps0.47.0/spark-3.1.1-odps0.47.0-client.tar.gz tar zxvf spark-3.1.1-odps0.47.0-client.tar.gz確認檔案位置並已正確下載解壓
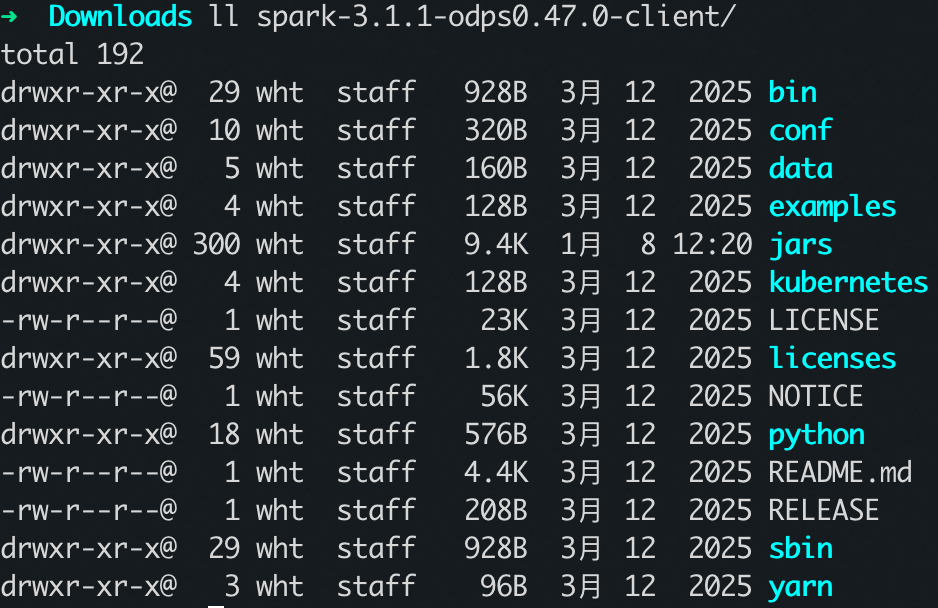
步驟二:建立並修改odps.conf設定檔
在spark-3.1.1-odps0.47.0-client/conf下建立odps.conf檔案:
touch odps.conf
vim odps.conf並在檔案中添加如下配置:
odps.project.name = [替換為實際project]
odps.end.point = [替換為實際endpoint]
odps.access.id = [替換為實際access id]
odps.access.key = [替換為實際access key]步驟三:通過IDEA開啟樣本專案
在 IntelliJ IDEA 的歡迎介面,單擊倉庫複製,輸入倉庫地址
https://github.com/aliyun/MaxCompute-Spark.git。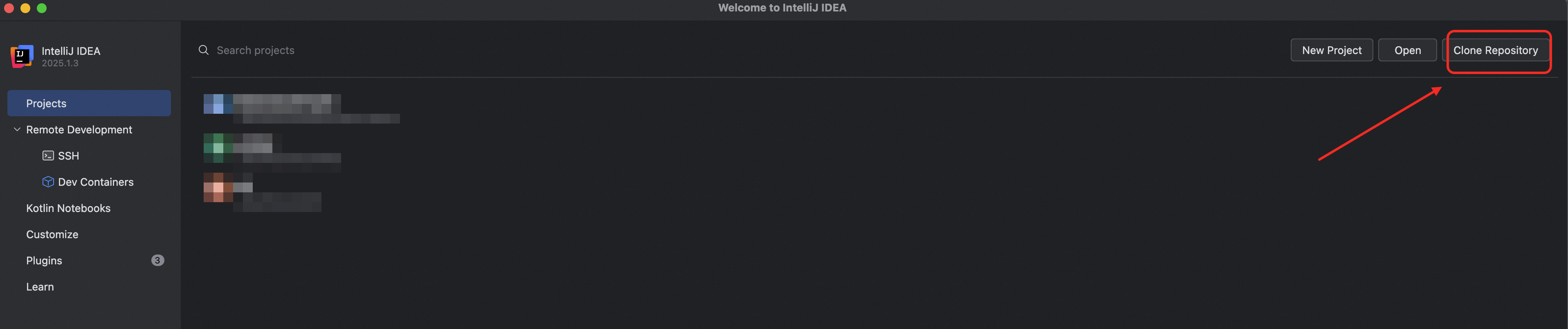
IDEA可能會彈出安全提示,詢問是否信任此專案,點擊信任即可。
複製成功後,IDEA會自動開啟這個專案,但它開啟的是根目錄
MaxCompute-Spark。需要關閉當前專案,然後重新開啟正確的子目錄。關閉當前專案:
點擊 IDEA 功能表列的
File->Close Project。回到 IDEA 歡迎介面。
開啟子目錄專案:
在歡迎介面,點擊
Open。在彈出的檔案瀏覽器中,導航至剛剛複製的檔案夾。
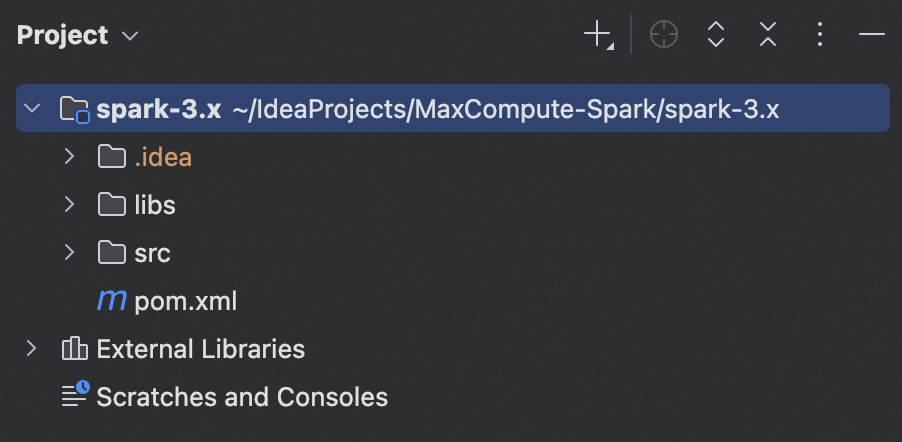
進入這個
MaxCompute-Spark檔案夾,然後選擇裡面的spark-3.x子目錄,點擊Open。
步驟四:添加MaxCompute Spark Jars依賴
如圖所示,進入File > Project Structure
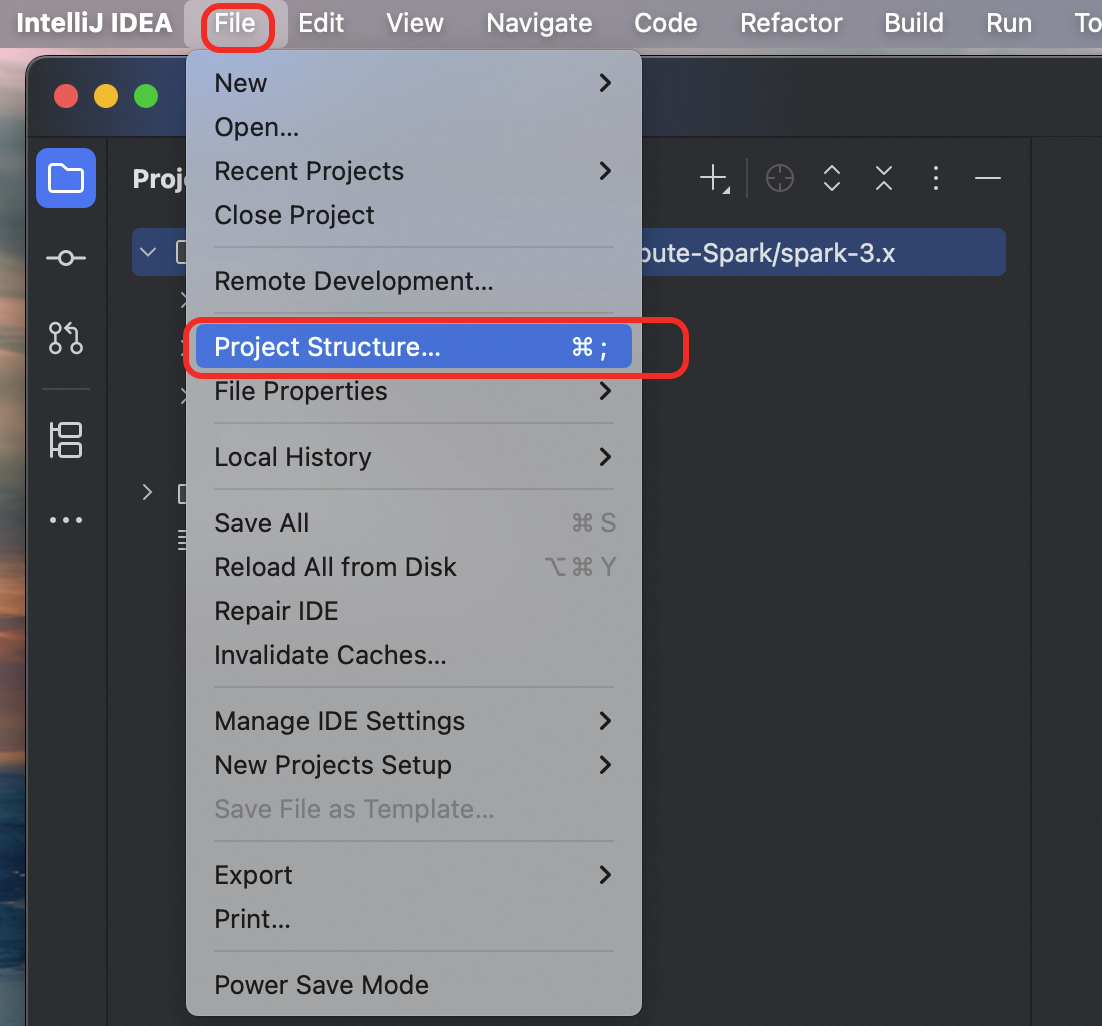
如圖所示,左側選擇
Modules,點擊+,添加JARs or Directories。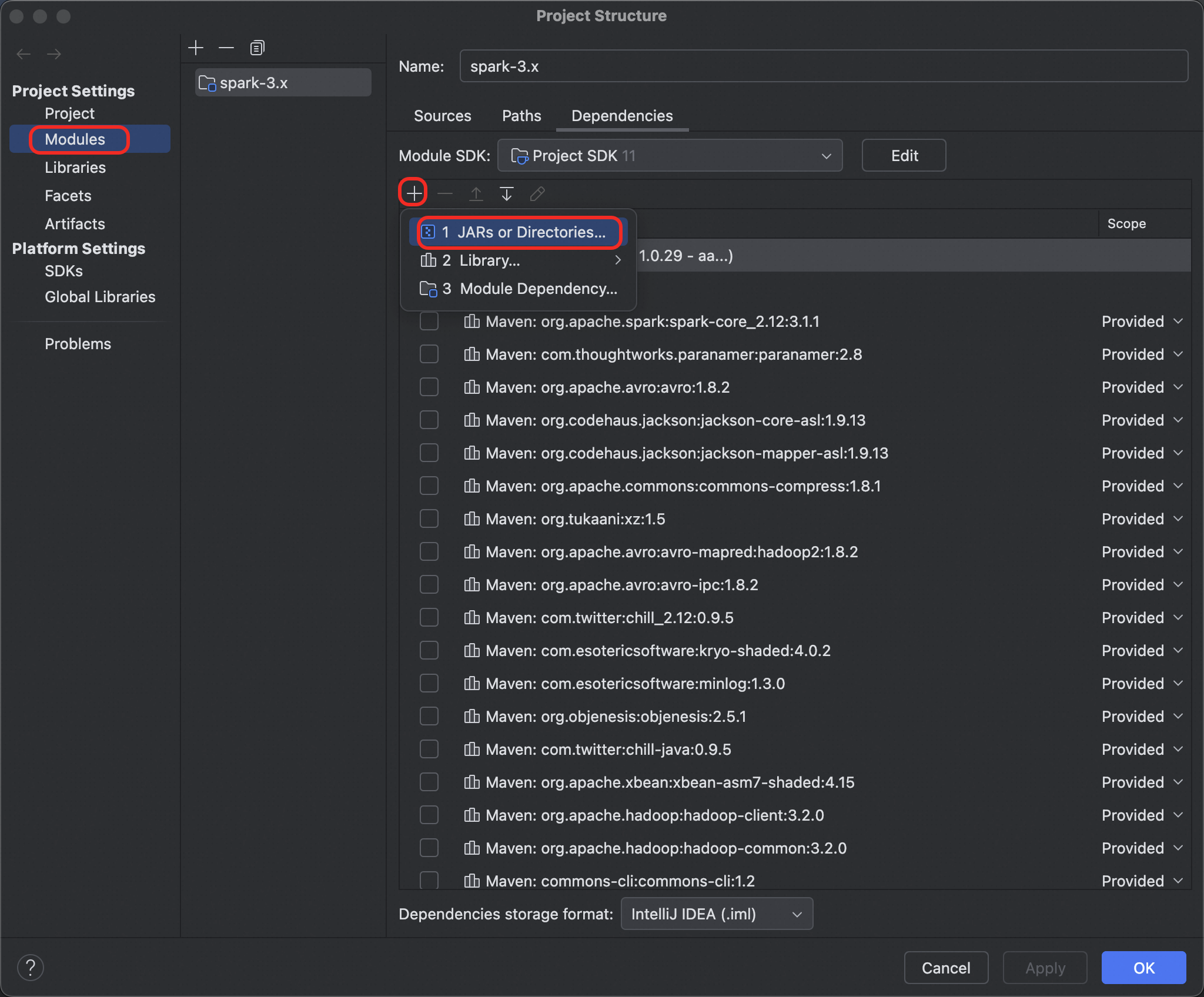
選擇步驟一中解壓的
spark-3.1.1-odps0.47.0-client/jars目錄。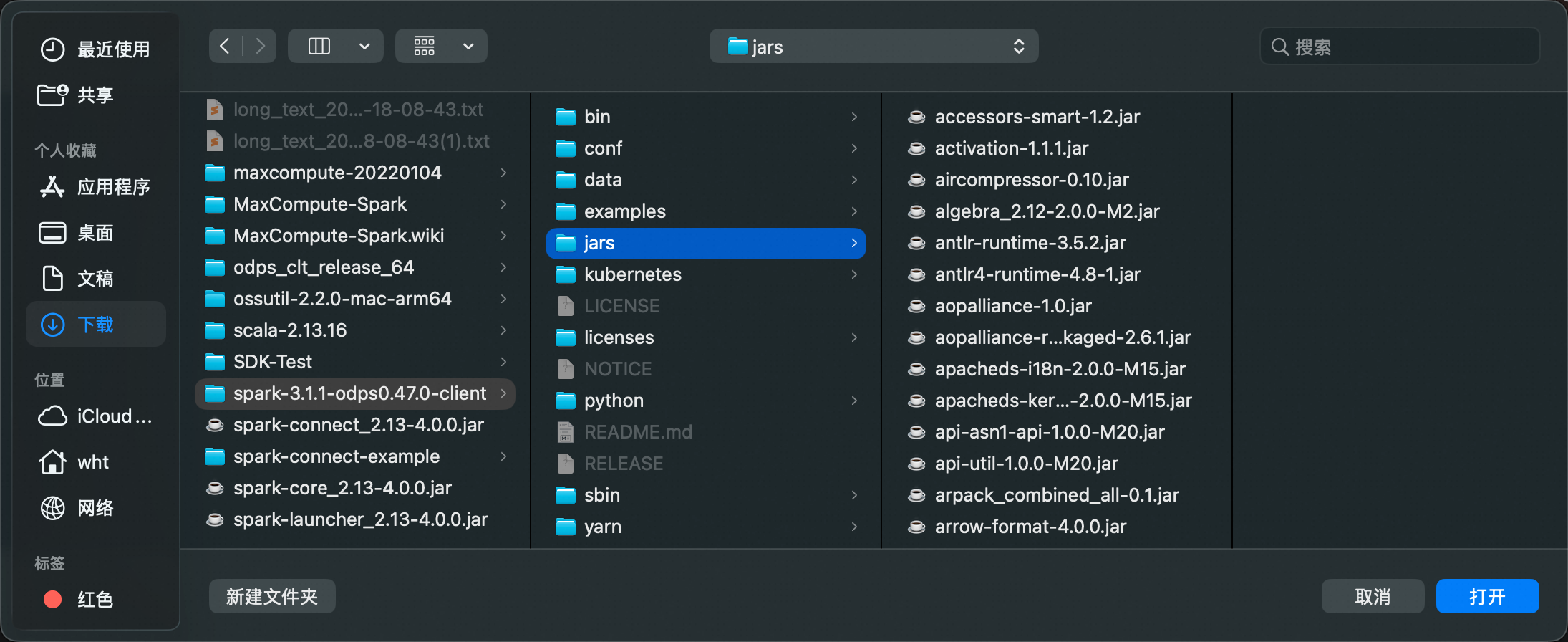
在IDEA單擊OK,確認添加。
步驟五:添加ODPS_CONF_FILE環境變數
單擊IDEA右上方
Edit Configurations
配置環境變數
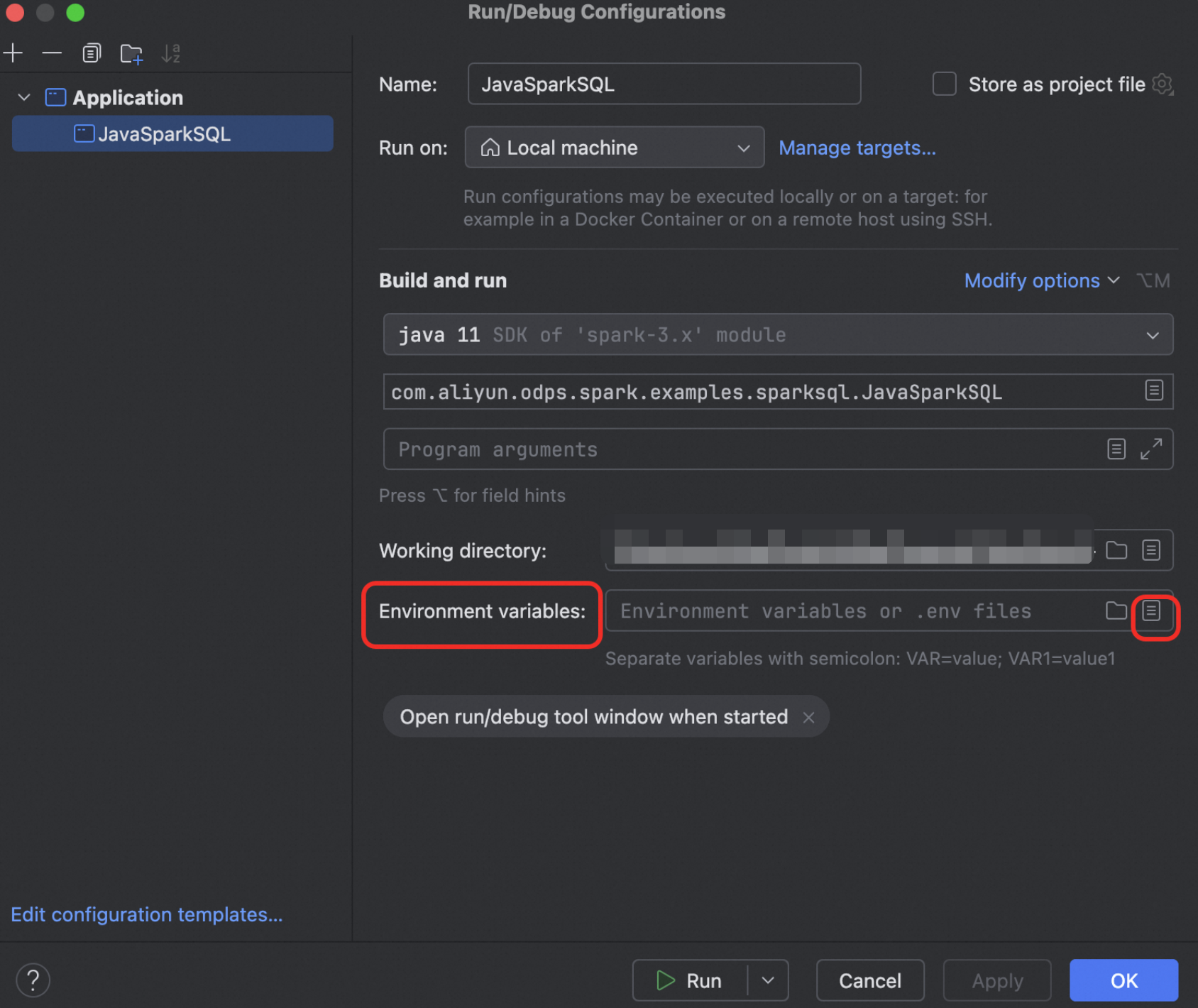
添加
ODPS_CONF_FILE,Name為ODPS_CONF_FILE,Value為步驟二建立的odps.conf檔案的位置。
單擊OK配置完成。
步驟六:運行任務JavaSparkSQL.java
在第48行添加如下代碼,配置為本地模式
.config("spark.master","local[*]")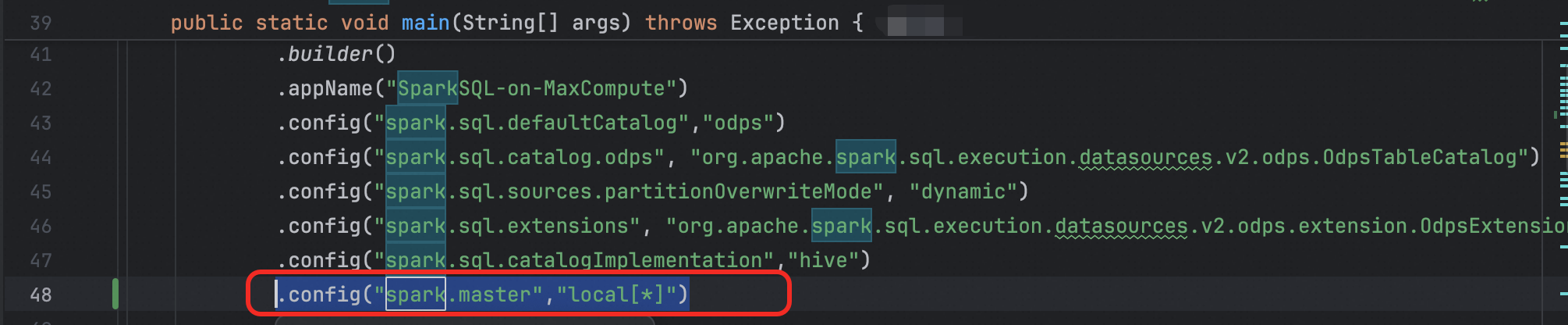
在第113行添加如下代碼,手動添加分區。
spark.sql("ALTER TABLE " + ptTableName + " ADD IF NOT EXISTS PARTITION (pt1='2018', pt2='0601')");
注釋第118行代碼,本地模式暫不支援動態分區覆蓋。
ptDf.write().mode("overwrite").insertInto(ptTableName);
單擊運行,返回結果如下:
使用Shell調試
步驟一:下載並解壓Spark用戶端
點選連結或在終端輸入如下指令下載並解壓Spark用戶端,樣本為Spark
3.1.1-odps0.47.0版本。wget https://odps-repo.oss-cn-hangzhou.aliyuncs.com/spark/3.1.1-odps0.47.0/spark-3.1.1-odps0.47.0-client.tar.gz tar zxvf spark-3.1.1-odps0.47.0-client.tar.gz確認檔案位置並已正確下載解壓
步驟二:建立並修改odps.conf設定檔
在spark-3.1.1-odps0.47.0-client/conf下建立odps.conf檔案:
touch odps.conf
vim odps.conf並在檔案中添加如下配置:
odps.project.name = [替換為實際project]
odps.end.point = [替換為實際endpoint]
odps.access.id = [替換為實際access id]
odps.access.key = [替換為實際access key]步驟三:修改spark-defaults.conf設定檔
在spark-3.1.1-odps0.47.0-client/conf下找到spark-defaults.conf檔案:
cd spark-3.1.1-odps0.47.0-client/conf
vim spark-defaults.conf
注釋掉以下配置
#spark.master = yarn
#spark.submit.deployMode = cluster
#spark.eventLog.enabled = true
添加配置
spark.master = local[*]步驟四:添加HADOOP_CONF_DIR環境變數
export HADOOP_CONF_DIR=/PATH/TO/spark-3.1.1-odps0.47.0-client/conf步驟五:開啟pyspark shell
cd spark-3.1.1-odps0.47.0-client
./bin/pyspark執行成功示意圖如下:
步驟六:執行Spark SQL
查詢設定檔中填寫的MaxCompute專案記憶體在的表。
spark.sql("SELECT * FROM xxxx").show();