隨著人工智慧的發展,許多業務和資料分析可以基於大語言模型(LLM)進行廣泛的應用,而資料處理是LLM開發尤為重要的一環,資料品質的好壞直接影響大模型訓練、推理的最終效果。相較於昂貴的GPU資源,MaxCompute的海量彈性CPU資源能夠成為LLM海量資料處理的資源基礎,而MaxFrame分散式運算能力可以協助您更加高效、便捷地完成LLM資料處理工作。
前提條件
已安裝MaxFrame,詳情請參見準備工作。
資料準備
本文以開源專案RedPajama在GitHub中的少量(一萬+)資料為例,為您介紹如何使用MaxFrame對GitHub代碼資料進行清洗和處理。
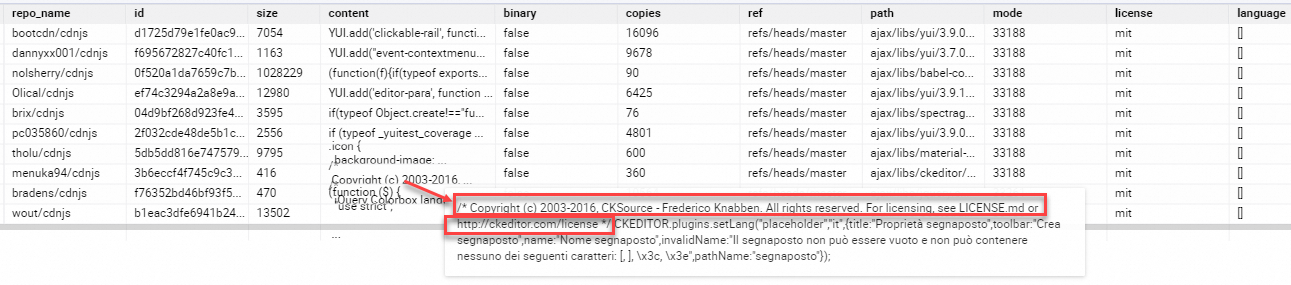
為便於使用,資料已被提前存放在MaxCompute公開專案BIGDATA_PUBLIC_DATASET下的data_science Schema中,您可直接進行使用,表名為llm_redpajama_github_demo_data。部分資料如下:

公開資料集的介紹及使用詳情請參見公開資料集概述。
使用MaxFrame對資料進行“著作權資訊去除”
對未經處理資料進行分析,若其中含有“Copyright”等著作權資訊,需要對該類敏感資訊進行去除。
例如:repo_name值為“menuka94/cdnjs”時,對應的content欄位中含有“Copyright”等著作權資訊。
建立MaxCompute入口類。
import os import time import numpy as np import maxframe.dataframe as md from odps import ODPS from maxframe import new_session # from maxframe.udf import with_resource_libraries from maxframe.config import options from maxframe import config o = ODPS( # 確保 ALIBABA_CLOUD_ACCESS_KEY_ID 環境變數設定為使用者 Access Key ID, # ALIBABA_CLOUD_ACCESS_KEY_SECRET 環境變數設定為使用者 Access Key Secret, # 不建議直接使用AccessKey ID和 AccessKey Secret字串。 os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'), os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'), project='your-default-project', endpoint='your-end-point', )參數說明:
ALIBABA_CLOUD_ACCESS_KEY_ID:需將該環境變數設定為具備目標MaxCompute專案中待操作對象相關MaxCompute許可權的AccessKey ID。您可以進入AccessKey管理頁面擷取AccessKey ID。
ALIBABA_CLOUD_ACCESS_KEY_SECRET:需將該環境變數設定為AccessKey ID對應的AccessKey Secret。
your-default-project:使用的MaxCompute專案名稱。您可以登入MaxCompute控制台,在左側導覽列選擇工作區>專案管理,查看MaxCompute專案名稱。
your-end-point:目標MaxCompute專案所在地區的Endpoint,可根據網路連接方式自行選擇,例如
http://service.cn-chengdu.maxcompute.aliyun.com/api。詳情請參見Endpoint。
引用MaxCompute內建鏡像common,其中包含Python環境及本次資料處理所需的regex等第三方包。
config.options.sql.settings = { "odps.session.image": "common" }通過UDF構建資料處理邏輯。
def clean_copyright(row): import re pat = re.compile('/\\*[^*]*\\*+(?:[^/*][^*]*\\*+)*/') cpat = re.compile('copyright', re.IGNORECASE) text = row['content'] if not text: return row r = pat.search(text) if r: span = r.span() sub = text[span[0]:span[1]] if cpat.search(sub): # cut it text = text[:span[0]] + text[span[1]:] row['content'] = text return row lines = text.split('\n') skip = 0 for k in range(len(lines)): if (lines[k].startswith('//') or lines[k].startswith('#') or lines[k].startswith('--') or not lines[k]): skip = skip + 1 else: break if skip: text = '\n'.join(lines[skip:]) row['content'] = text return row建立MaxFrame Session,提交作業至MaxCompute。
def maxframe_job(): s_time = time.time() table_name = 'bigdata_public_dataset.data_science.llm_redpajama_github_demo_data' session = new_session(o) print('session id: ', session.session_id) df = md.read_odps_table(table_name, index_col='id') df = df.apply( clean_copyright, axis=1, # row output_type="dataframe", ) out_table = 'tmp_mf_clean_copyright' md.to_odps_table(df, out_table).execute() session.destroy() maxframe_job()
資料處理結果
查詢tmp_mf_clean_copyright表,對之前含有“Copyright”等著作權資訊的資料進行查看,已去除敏感資訊。
SELECT * FROM tmp_mf_clean_copyright;部分返回結果如下:
後續操作
MaxCompute已與阿里雲人工智慧平台PAI成功對接,您可基於PAI Desinger進行更多LLM運算元的開發和使用,LLM運算元詳情請參見組件參考:大模型資料處理。