本文為您介紹使用PyODPS時的常見問題。
問題類別 | 常見問題 |
安裝PyODPS | |
匯入模組 | |
使用PyODPS |
安裝PyODPS時報錯Warning: XXX not installed?
產生此問題的原因為組件缺失,請根據報錯資訊中提示的XXX資訊,明確缺失的組件名稱,使用pip命令安裝此組件。
安裝PyODPS時報錯Project Not Found?
產生此問題的原因為:
Endpoint配置錯誤,需要修改為目標Project的Endpoint。更多Endpoint資訊,請參見Endpoint。
MaxCompute入口對象參數位置填寫錯誤。請檢查此項確保其填寫正確。更多MaxCompute入口對象參數資訊,請參見從DataWorks遷移到本地環境。
安裝PyODPS時報錯Syntax Error?
由於Python版本過低導致報錯。PyODPS不支援Python2.5及以下版本,建議使用PyODPS支援的主流版本,例如Python2.7.6+、Python3.3+以及Python2.6。
在Mac上安裝PyODPS時報錯Permission Denied?
您可以使用sudo pip install pyodps命令安裝PyODPS。
在Mac上安裝PyODPS時報錯Operation Not Permitted?
此報錯是由系統完整性保護導致。您需要重啟裝置,並在重啟時按⌘+R鍵,此後在終端中運行如下命令可以解決此問題。
csrutil disable
reboot 更多資訊,請參見Operation Not Permitted when on root - El Capitan (rootless disabled)。
執行from odps import ODPS時報錯No Module Named ODPS?
此報錯說明無法載入ODPS Package。可能原因如下:
原因一:安裝了多個Python版本。
解決措施:Search Path(通常是目前的目錄)中包含
odps.py或init.py檔案且名為odps的檔案夾。解決方案如下:如果是檔案夾重名,請修改檔案夾名稱。
如果是曾經安裝過一個名為odps的Python包,請使用
sudo pip uninstall odps進行刪除。
原因二:同時安裝了Python2和Python3版本。
解決措施:確保裝置只安裝了Python2或Python3版本。
原因三:當前使用的Python下並未安裝PyODPS。
解決措施:安裝PyODPS,安裝方法請參見安裝PyODPS。
執行from odps import ODPS時報錯Cannot Import Name ODPS?
請檢查當前工作路徑下是否存在名為odps.py的檔案。若存在,請改名後再執行匯入操作。
執行from odps import ODPS時報錯Cannot Import Module odps?
此報錯通常是由於PyODPS遇到了依賴問題。您可以單擊申請連結添加PyODPS支援人員DingTalk群,聯絡釘群管理員定位解決。
在IPython或Jupyter下使用PyODPS時報錯ImportError?
可以在代碼頭部增加from odps import errors。若問題仍存在,可能是缺少IPython依賴,執行sudo pip install -U jupyter解決。
o.gettable('table_name').size中size欄位的含義是什嗎?
SIZE欄位表示表的實體儲存體大小。
如何設定Tunnel Endpoint?
您可以通過options.tunnel.endpoint設定,請參見aliyun-odps-python-sdk。
PyODPS如何使用包含CPython的第三方包?
建議您打包成WHEEL格式後使用,請參見如何製作可以在MaxCompute上使用的crcmod。
PyODPS中的DataFrame最多可以處理多少資料,對錶的大小有限制嗎?
PyODPS對錶的大小沒有限制。本地Pandas建立DataFrame的大小受限於本地記憶體的大小。
在DataFrame中如何使用max_pt?
使用odps.df.func模組來調用MaxCompute內建函數。
from odps.df import func
df = o.get_table('your_table').to_df()
df[df.ds == func.max_pt('your_project.your_table')] # ds是分區欄位。 使用PyODPS向表寫入資料的兩種方式open_writer()和write_table()有什麼區別?
每次調用write_table(),MaxCompute都會在服務端產生一個檔案。這一操作需要較大的時間開銷,同時過多的檔案會降低後續的查詢效率,還可能造成服務端記憶體不足。因此,建議在使用write_table()方法時,一次性寫入多組資料或者傳入一個Generator對象。使用write_table()方法樣本請參見寫入表資料。
open_writer()預設寫入到Block中。
為什麼DataWorks PyODPS節點上查出的資料量要少於本地啟動並執行結果?
DataWorks上預設未開啟Instance Tunnel,即instance.open_reader預設使用Result介面,最多可以擷取一萬條記錄。
開啟Instance Tunnel後,您可以通過reader.count擷取記錄數。如果您需要迭代擷取全部資料,則需要通過設定options.tunnel.limit_instance_tunnel = False關閉Limit限制。
DataFrame如何獲得Count實際數字?
安裝PyODPS後,在Python環境下執行如下命令建立MaxCompute表來初始化DataFrame。
iris = DataFrame(o.get_table('pyodps_iris'))在DataFrame上執行Count擷取DataFrame的總行數。
iris.count()由於DataFrame上的操作並不會立即執行,只有當使用者顯式調用Execute方法或者立即執行的方法時,才會真正執行。此時為了防止Count方法順延強制,可輸入如下命令。
df.count().execute()
使用PyODPS時報錯sourceIP is not in the white list?
PyODPS訪問的MaxCompute專案存在白名單保護,請聯絡專案所有者將裝置添加至IP白名單。更多IP白名單資訊,請參見管理IP白名單。
使用from odps import options options.sql.settings設定MaxCompute運行環境不成功?
問題現象
使用PyODPS運行SQL,在申請MaxCompute執行個體前,通過如下代碼設定MaxCompute運行環境。
from odps import options options.sql.settings = {'odps.sql.mapper.split.size': 32}運行任務後只啟動了6個Mapper,設定未生效。 在用戶端執行
set odps.stage.mapper.split.size=32,一分鐘內運行完畢。產生原因
用戶端和PyODPS裡設定的參數不一致。用戶端的參數是
odps.stage.mapper.split.size,而PyODPS裡的參數是odps.sql.mapper.split.size。解決措施
修改參數為
odps.stage.mapper.split.size。
調用DataFrame的head方法時報錯IndexError:listindexoutofrange?
由於list[index]沒有元素或list[index]超出範圍。
上傳Pandas DataFrame至MaxCompute時報錯ODPSError?
問題現象
上傳Pandas DataFrame至MaxCompute時,返回報錯如下。
ODPSError: ODPS entrance should be provided.產生原因
沒有找到全域的MaxCompute對象入口。
解決措施
使用Room機制
%enter時,會配置全域入口。對MaxCompute對象入口調用
to_global方法。使用參數
DataFrame(pd_df).persist('your_table', odps=odps)。
通過DataFrame寫表時報錯lifecycle is not specified in mandatory mode?
問題現象
通過DataFrame寫表時,返回報錯如下。
table lifecycle is not specified in mandatory mode產生原因
未給表設定生命週期。
解決措施
Project要求對每張表設定生命週期,因此需要在每次執行時設定如下資訊即可。
from odps import options options.lifecycle = 7 # 此處設定lifecycle的值。lifecycle取值為整數,單位為天。
使用PyODPS寫資料時報錯Perhaps the datastream from server is crushed?
該報錯是由髒資料導致,請您檢查資料列數是否和目標表一致。
使用PyODPS讀資料時報錯Project is protected?
Project上的安全性原則禁止讀取表中的資料,如果想使用全部資料,可以使用以下方法:
聯絡Project Owner增加例外規則。
使用DataWorks或其他脫敏工具先對資料進行脫敏,匯出到非保護Project,再進行讀取。
如果只想查看部分資料,可使用如下方法:
改用
o.execute_sql('select * from <table_name>').open_reader()。改用
DataFrame,o.get_table('<table_name>').to_df()。
PyODPS指令碼任務不定時出現串連失敗報錯ConnectionError: timed out try catch exception?
產生此報錯的可能原因如下:
建立連線逾時。PyODPS預設的逾時時間是5s,解決方案如下:
您可以在代碼頭部加上如下代碼,增加逾時時間間隔。
# workaround from odps import options options.connect_timeout=30捕獲異常,進行重試。
由於沙箱限制,會造成部分機器禁止網路訪問。建議您使用獨享調度資源群組執行任務,解決此問題。
使用PyODPS運行get_sql_task_cost函數時報錯is not defined?
問題現象
使用PyODPS運行get_sql_task_cost函數時,返回報錯如下。
NameError: name 'get_task_cost' is not defined.解決措施
函數名稱有誤。
解決措施
使用execute_sql_cost替代get_sql_task_cost。
使用PyODPS列印日誌時,中文自動轉換為編碼顯示,如何顯示成原始中文?
您可以使用類似print ("我叫 %s" % ('abc'))的輸入方式解決。該問題通常僅在Python 2中出現。
設定options.tunnel.use_instance_tunnel = False,為什麼欄位在MaxCompute中定義為DATETIME類型,使用SELECT語句得到的資料為STRING類型?
在調用Open_Reader時,PyODPS會預設調用舊的Result介面。此時從服務端得到的資料是CSV格式的,所以DATETIME都是STRING類型。
開啟Instance Tunnel,即設定options.tunnel.use_instance_tunnel = True,PyODPS會預設調用Instance Tunnel,即可解決此問題。
如何利用Python語言特性來實現豐富的功能?
編寫Python函數。
計算兩點之間的距離有多種計算方法,例如歐氏距離、曼哈頓距離等,您可以定義一系列函數,在計算時根據具體情況調用相應的函數即可。
def euclidean_distance(from_x, from_y, to_x, to_y): return ((from_x - to_x) ** 2 + (from_y - to_y) ** 2).sqrt() def manhattan_distance(from_x, from_y, to_x, to_y): return (from_x - to_x).abs() + (from_y - to_y).abs()調用如下。
In [42]: df from_x from_y to_x to_y 0 0.393094 0.427736 0.463035 0.105007 1 0.629571 0.364047 0.972390 0.081533 2 0.460626 0.530383 0.443177 0.706774 3 0.647776 0.192169 0.244621 0.447979 4 0.846044 0.153819 0.873813 0.257627 5 0.702269 0.363977 0.440960 0.639756 6 0.596976 0.978124 0.669283 0.936233 7 0.376831 0.461660 0.707208 0.216863 8 0.632239 0.519418 0.881574 0.972641 9 0.071466 0.294414 0.012949 0.368514 In [43]: euclidean_distance(df.from_x, df.from_y, df.to_x, df.to_y).rename('distance') distance 0 0.330221 1 0.444229 2 0.177253 3 0.477465 4 0.107458 5 0.379916 6 0.083565 7 0.411187 8 0.517280 9 0.094420 In [44]: manhattan_distance(df.from_x, df.from_y, df.to_x, df.to_y).rename('distance') distance 0 0.392670 1 0.625334 2 0.193841 3 0.658966 4 0.131577 5 0.537088 6 0.114198 7 0.575175 8 0.702558 9 0.132617利用Python語言的條件和迴圈語句。
如果使用者要計算的表儲存在資料庫,需要根據配置來對錶的欄位進行處理,然後對所有表進行UNION或者JOIN操作。這時如果用SQL實現是相當複雜的,但是用DataFrame處理則會非常簡單。
例如,您有30張表需要合成一張表,此時如果使用SQL,則需要對30張表執行UNION ALL操作。如果使用PyODPS,如下代碼就可以完成。
table_names = ['table1', ..., 'tableN'] dfs = [o.get_table(tn).to_df() for tn in table_names] reduce(lambda x, y: x.union(y), dfs) ## reduce語句等價於如下代碼。 df = dfs[0] for other_df in dfs[1:]: df = df.union(other_df)
如何使用Pandas計算後端進行本地Debug?
您可以通過以下兩種方式進行本地Debug,初始化方法不同,但後續代碼一致:
通過Pandas DataFrame建立的PyODPS DataFrame可以使用Pandas執行本地計算。
使用MaxCompute表建立的DataFrame可以在MaxCompute上執行。
範例程式碼如下。
df = o.get_table('movielens_ratings').to_df()
DEBUG = True
if DEBUG:
df = df[:100].to_pandas(wrap=True) 當所有後續代碼都編寫完成,本地的測試速度非常快。當測試結束後,您可以把Debug值改為False,這樣後續就能在MaxCompute上執行全量的計算。
推薦您使用MaxCompute Studio來執行本地PyODPS程式調試。
如何避免嵌套迴圈執行慢的情況?
建議您通過Dict資料結構記錄下迴圈的執行結果,最後在迴圈外統一匯入到DataFrame對象中。如果您將DataFrame對象代碼df=XXX放置在外層迴圈中,會導致每次迴圈計算都產生一個DataFrame對象,從而降低嵌套迴圈整體的執行速度。
如何避免將資料下載到本地?
什麼情況下可以下載PyODPS資料到本地處理?
在如下兩種情況下,可以下載PyODPS資料到本地:
資料量很小的情況。
需要對單行資料應用Python函數,或執行一行變多行的操作,這時使用PyODPS DataFrame就可以輕鬆完成,並且可以完全發揮MaxCompute的並行計算能力。
例如有一份JSON串資料,需要把JSON串按Key-Value對展開成一行,代碼如下所示。
In [12]: df json 0 {"a": 1, "b": 2} 1 {"c": 4, "b": 3} In [14]: from odps.df import output In [16]: @output(['k', 'v'], ['string', 'int']) ...: def h(row): ...: import json ...: for k, v in json.loads(row.json).items(): ...: yield k, v ...: In [21]: df.apply(h, axis=1) k v 0 a 1 1 b 2 2 c 4 3 b 3
通過open_reader最多隻能取到1萬條記錄,如何擷取多於1萬條的記錄?
使用create table as select ...將SQL的結果儲存成表,再使用table.open_reader讀取。
為什麼盡量使用內建運算元,而不是自訂函數?
計算過程中使用自訂函數比使用內建運算元速度慢很多,因此建議使用內建運算元。
對於百萬行的資料,當一行應用了自訂函數後,執行時間從7秒延長到了27秒。如果有更大的資料集、更複雜的操作,時間的差距可能會更大。
為什麼通過DataFrame().schema.partitions獲得分區表的分區值為空白?
這是因為DataFrame不區分分區欄位和普通欄位,所以擷取分區表的分區欄位作為普通欄位處理。您可以通過如下方式過濾掉分區欄位。
df = o.get_table().to_df()
print(df[df.ds == ''].execute())建議您參照表來設定分區或讀取分區資訊。
如何使用PyODPS DataFrame執行笛卡爾積?
如何使用PyODPS實現結巴中文分詞?
請參見PyODPS節點實現結巴中文分詞。
如何使用PyODPS下載全量資料?
PyODPS預設不限制從Instance讀取的資料規模。但是對於受保護的MaxCompute專案,通過Tunnel下載資料將受到限制。此時,如果未設定options.tunnel.limit_instance_tunnel,則資料量限制會被自動開啟,可下載的資料條數受到MaxCompute配置限制,通常該限制為10000條。如果您需要迭代擷取全部資料,則需要關閉limit限制。您可以通過下列語句在全域範圍內開啟Instance Tunnel並關閉limit限制。
options.tunnel.use_instance_tunnel = True
options.tunnel.limit_instance_tunnel = False # 關閉limit限制,讀取全部資料。
with instance.open_reader() as reader:
# 通過Instance Tunnel可讀取全部資料。使用PyODPS統計表中某個欄位的空值率時,是用execute_sql還是DataFrame?
DataFrame彙總效能更高一些,推薦使用DataFrame來執行彙總操作。
PyODPS資料類型如何設定?
如果您使用PyODPS,可以通過下列方法開啟新資料類型開關:
如果通過
execute_sql方式開啟新資料類型,可以執行o.execute_sql('set odps.sql.type.system.odps2=true;query_sql', hints={"odps.sql.submit.mode" : "script"})。如果通過DataFrame開啟新資料類型,例如persist、execute、to_pandas等方法,可通過hints參數設定。圖示設定方法僅針對單個作業生效。
from odps.df import DataFrame users = DataFrame(o.get_table('odps2_test')) users.persist('copy_test',hints={'odps.sql.type.system.odps2':'true'})如果通過DataFrame調用,且需要全域生效,應當設定Option參數
options.sql.use_odps2_extension = True。
在PyODPS中使用Decimal類型時報錯ValueError?
您可以通過以下兩種方式進行解決:
升級SDK版本至V0.8.4或以上版本。
SQL中添加如下語句:
from odps.types import Decimal Decimal._max_precision=38
如何排查PyODPS執行SQL很慢?
PyODPS提交SQL任務前,並沒有進行重度操作。因此多數情況下,SQL任務執行變慢與PyODPS無關。您可以根據以下步驟排查具體原因:
檢查網路及服務端延遲
確認提交任務經過的Proxy 伺服器或者網路鏈路是否存在延遲。
檢查服務端是否存在任務排隊延遲等情況。
評估資料讀取效率
如果您的SQL執行過程中涉及大量資料讀取,請檢查是否因為資料量過大或資料分區過多而導致讀取速度變慢。具體操作如下:
您可先嘗試將提交執行與讀取資料進行拆分,即使用run_sql提交任務,使用instance.wait_for_success等待任務結束,再通過instance.open_reader讀取資料,最後確認各語句造成的延遲。拆分樣本如下:
拆分前:
with o.execute_sql('select * from your_table').open_reader() as reader: for row in reader: print(row)拆分後:
inst = o.run_sql('select * from your_table') inst.wait_for_success() with inst.open_reader() as reader: for row in reader: print(row)
驗證DataWorks作業狀態(如果適用)
對於在DataWorks中提交的作業,請確認是否存在提交正常,但未產生Logview的SQL任務,尤其是當PyODPS版本低於0.11.6時。這些任務通常是通過execute_sql或run_sql方法提交的。
本地環境因素分析
若要進一步確定問題是否與本地環境相關,建議啟用調試日誌功能。PyODPS會將所有請求和返回結果列印出來,您可根據請求和返回結果的日誌確定延遲發生的位置。
樣本如下:
import datetime import logging from odps import ODPS logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') o = ODPS(...) # 此處填入帳號,如果環境已提供 MaxCompute Entry 則忽略 # 列印本地時間以確定本地操作發起的時間 print("Check time:", datetime.datetime.now()) # 提交任務 inst = o.run_sql("select * from your_table")此時,您的標準輸出內容應與如下結果類似:
Check time: 2025-01-24 15:34:21.531330 2025-01-24 15:34:21,532 - odps.rest - DEBUG - Start request. 2025-01-24 15:34:21,532 - odps.rest - DEBUG - POST: http://service.<region>.maxcompute.aliyun.com/api/projects/<project>/instances 2025-01-24 15:34:21,532 - odps.rest - DEBUG - data: b'<?xml version="1.0" encoding="utf-8"?>\n<Instance>\n <Job>\n <Priority>9</Priority>\n <Tasks>\n <SQL>\n .... 2025-01-24 15:34:21,532 - odps.rest - DEBUG - headers: {'Content-Type': 'application/xml'} 2025-01-24 15:34:21,533 - odps.rest - DEBUG - request url + params /api/projects/<project>/instances?curr_project=<project> 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers before signing: {'Content-Type': 'application/xml', 'User-Agent': 'pyodps/0.12.2 CPython/3.7.12', 'Content-Length': '736'} 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers to sign: OrderedDict([('content-md5', ''), ('content-type', 'application/xml'), ('date', 'Fri, 24 Jan 2025 07:34:21 GMT')]) 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - canonical string: POST application/xml Fri, 24 Jan 2025 07:34:21 GMT /projects/maxframe_ci_cd/instances?curr_project=maxframe_ci_cd 2025-01-24 15:34:21,533 - odps.accounts - DEBUG - headers after signing: {'Content-Type': 'application/xml', 'User-Agent': 'pyodps/0.12.2 CPython/3.7.12', 'Content-Length': '736', .... 2025-01-24 15:34:21,533 - urllib3.connectionpool - DEBUG - Resetting dropped connection: service.<region>.maxcompute.aliyun.com 2025-01-24 15:34:22,027 - urllib3.connectionpool - DEBUG - http://service.<region>.maxcompute.aliyun.com:80 "POST /api/projects/<project>/instances?curr_project=<project> HTTP/1.1" 201 0 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.status_code 201 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.headers: {'Server': '<Server>', 'Date': 'Fri, 24 Jan 2025 07:34:22 GMT', 'Content-Type': 'text/plain;charset=utf-8', 'Content-Length': '0', 'Connection': 'close', 'Location': .... 2025-01-24 15:34:22,027 - odps.rest - DEBUG - response.content: b''由此可知代碼啟動任務的時間(2025-01-24 15:34:21.531)、請求發起時間(2025-01-24 15:34:21.533)以及服務端返回的時間(2025-01-24 15:34:22.027),從而獲知各個階段的時間開銷。
如何使用PyODPS擷取MaxCompute表的檔案數量和最後修改時間
問題描述
通過MaxCompute本地用戶端
odpscmd或DataWorks 中的MaxCompute SQL節點,執行DESC EXTENDED table_name或DESC EXTENDED table_name PARTITION (xxx='xxx')可以查看錶的詳細資料。包括檔案數量(file_num)、物理大小和最後修改時間等中繼資料。但是,若直接使用PyODPS的
run_sql()或execute_sql()執行DESC EXTENDED語句,返回結果中並不包含完整的擴充資訊(如file_num等欄位),無法結構化提取關鍵計量。如圖所示:
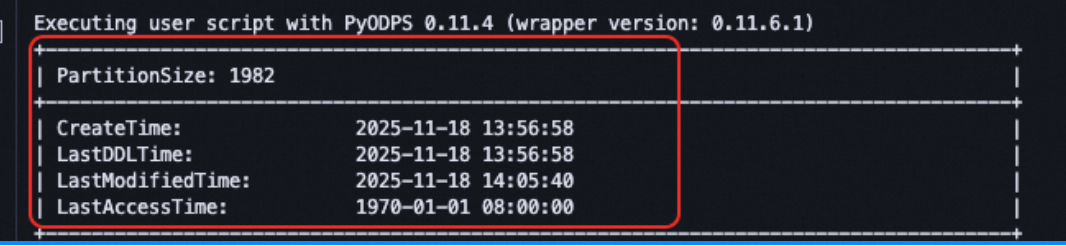
解決方案
用 PyODPS 的 SDK 原生介面(如
table.reload_extend_info()或partition.reload())準確擷取這些統計資訊。單擊連結參考源碼。完整的擷取分區檔案數資訊樣本如下:
from odps.models import Partition # 替換為使用者真實的表名 table_name = 'your_real_table_name' # ========== 1. 擷取表對象 ========== try: # 假設 o 是一個已初始化的 ODPS 對象 # 在 DataWorks PyODPS 節點中,可以取消下面這行的注釋 # o = odps table = o.get_table(table_name) print(f"成功擷取表對象: {table_name}") except Exception as e: print(f"錯誤:無法擷取表 '{table_name}'。原因: {str(e)}") raise # 拋出異常,中斷執行 # ========== 2. 檢查是否為分區表 ========== if not table.table_schema.partitions: print(f"資訊:表 '{table_name}' 不是分區表,無法查詢分區資訊。") else: print(f"資訊:表 '{table_name}' 是分區表,開始遍曆所有分區...") print("=" * 60) # ========== 3. 使用 table.partitions 遍曆分區 ========== partition_count = 0 try: # 直接遍曆所有分區,這將返回一系列 Partition 對象 for partition in table.partitions: try: # 擷取分區的字串表示(例如:'pt=20230101') part_spec = partition.spec if not part_spec: part_spec = '未知分區' # partition.reload() 方法會載入分區的詳細中繼資料 # 這會觸發一次或多次對 MaxCompute Metastore 的 API 呼叫 partition.reload() print(f"分區資訊 (Partition Spec): {part_spec}") print(f" - 建立時間 (Creation Time) : {partition.creation_time}") print(f" - 資料最後修改時間 (Modified Time): {partition.last_data_modified_time}") print(f" - 物理大小 (Physical Size) : {partition.physical_size} 位元組") print(f" - 檔案數量 (File Count) : {partition.file_num}") print(f" - 是否歸檔 (Is Archived) : {partition.is_archived}") print("-" * 60) partition_count += 1 except Exception as e_inner: # 捕獲處理單個分區時可能發生的錯誤,並繼續處理下一個 print(f"警告:載入分區 {partition.spec or ''} 的詳細資料失敗。原因: {str(e_inner)}") print("-" * 60) continue print(f"遍曆完成:共成功處理了 {partition_count} 個分區。") except Exception as e_outer: print(f"致命錯誤:在遍曆分區的過程中發生嚴重錯誤。原因: {str(e_outer)}")