本文為您整合了使用Proxima CE過程中的常見問題。
Proxima CE用的是哪裡的資源?
使用者所在MaxCompute Project下的資源。
輸入表中的vector可以直接使用MaxCompute的Binary類型嗎?
,:- 如果-binary_to_int值為false,使用者的輸入類似於
1,1,1,1,1,1,….。 - 如果-binary_to_int值為true,使用者的輸入類似於
12345,13423,13325,….。
0/1值轉換為了N/32個整數,能對產生的索引起到壓縮空間的作用。如何設定行列值(-column_num和-row_num)?
Proxima CE屬於分布式離線向量處理引擎,當前主要依託MaxCompute平台的MapReduce(簡稱MR)來處理超大規模資料。在build過程,需要分列(column),將doc劃分到每個列上構建索引;在seek過程中,需要分行(row),將query劃分到每個行上檢索。通過分行分列來處理超大規模的資料。
- 列(column)影響build階段,列越多,每列索引大小降低,單列構建檢索速度提高,加速build階段,但使用的叢集機器資源變多。
- 行(row)影響seek階段,行越多,每行檢索的query變少,單行檢索速度提升,加速seek階段,同樣使用的叢集機器資源變多。
- 預設叢集的資源限制。需要聯絡使用者所在MaxCompute Project對應的Project Owner瞭解。
- MapReduce的執行個體限制。目前MaxCompute MR的reduce任務限制99999個執行個體,執行個體個數在build階段個數為
column_num,在seek階段個數為column_num * row_num。因此需要保證column_num * row_num<99999。
考慮到上述架構以及相關限制,我們通常推薦使用者使用預設的行列數配置。即不需要指定,Proxima CE會根據使用者輸入的相關參數計算出預設的行列數,具體的計算方式請參考多類目檢索。
當然系統計算出的行列是保障正常啟動並執行資源要求,即當使用者需要加速時,可以增加行列,或者當叢集資源不夠時,可以減少行列,這些都需要根據自己所在MaxCompute Project的情況具體分析,包括下述如何加速任務的運行速度?均是提供一個通用的原則與思路。
如何加速任務的運行速度?
- 多類目情況下,任務整體分成兩部分,一部分是單類目doc個數小於100萬(預設閾值,可配置)的類目,另一部分是單類目doc個數大於100萬的類目,所有小於100萬的類目會一起用線性方法進行檢索,要加快這部分的速度,可以設定如下兩個命令列參數 -category_row_num和-category_col_num。對於大類目部分的加速,可以通過設定這兩個參數-row_num和-column_num。大體上的原則是增大列數和增加行數,這是由於增大列數,每列索引大小降低,單列檢索速度提高;增大行數,每行 query 數量減少,同一批的檢索速度提升,但是相應的資源的消耗就增加,具體需要結合業務與資源情況進行分析。詳情請參考多類目檢索。
- 非多類目情況下,可以通過設定-row_num和-column_num參數,提高任務整體的並發度。
為什麼有query沒有達到指定的topn?
- 可以通過降低recall 。該方法解決不徹底,如果是底層演算法構圖不連通,那麼無論減少多少也可能不會得到200個,另外如果有,為特例case降低召回率對其他向量召回的效果也有影響,需要自行評估。
- 改變構造索引演算法。例如採用HC方式構圖,可通過-algo_model命令列參數指定。
- 補全topk。對於proxima2.4以上的版本,如果指定為HnswSearcher的hnsw的圖演算法,通過添加參數
{"proxima.hnsw.searcher.force_padding_result_enable" : True}補全search結果到指定的topk,對極端case的相似性的效果有一定影響,需要根據具體業務自行評估影響是否可接受。
Proxima CE可以設定cosine(餘弦)距離嗎?
Proxima CE支援cosine距離,且對內積的支援有最佳化,詳情參考內積和餘弦距離。
為什麼提交的Proxima CE任務執行緩慢?
Proxima CE的主體是運行在MaxCompute MapReduce job,在任務正常編譯啟動並執行情況下,可能是MaxCompute調度和資源的問題,您可以通過申請連結或搜尋(DingTalk群號:11782920)加入MaxCompute開發人員社區釘群聯絡MaxCompute支援人員團隊擷取支援。
建立暫存資料表異常是什麼問題?
該情況通常伴隨invalid table name: xxx.yyy報錯,主要原因是輸出表命名出現問題。
對於Proxima CE的輸入輸出表,其命名需要符合MaxCompute的命名規定,注意名稱中不能帶點號.,該符號為MaxCompute的特殊字元,會導致後續流程錯誤。通常發生在建立output表為xxx.output_table_name的情況。
多個任務同時執行會有問題嗎?
- 底層OSS Volume Filesystem相關的錯誤。
- build過程失敗,提示
jni write index失敗相關的錯誤。 - seek過程失敗,提示
jni load index失敗相關的錯誤。
為什麼我啟動並執行離線任務影響線上任務?
- 限制離線任務的資源使用。可以限制任務的並發,通過指定Proxima離線任務的行列,也可以在自己的MaxCompute Project控制台加限制,這些都會導致離線任務運行變慢。
- 盡量分離兩個任務。可以嘗試分時使用叢集,或者嘗試申請新的資源。
RunLog與Logview是什麼含義?有什麼區別?
- RunLog支援人員介面人經常使用的作業記錄、runLog通常是指在DataWorks節點運行後產生的作業記錄下的全部內容。使用者可以複製runlog資訊發送給介面人定位問題。如果使用odpscmd運行指令碼,通常也會在用戶端產生作業記錄,可以複製用戶端上的全部日誌發送給介面人,也可以將日誌重新導向到一個記錄檔,將檔案發送給介面人。
- logview
Logview是一個在MaxCompute Job提交後查看任務和Debug任務的工具,對於Proxima CE來講,通常指的是在整體任務運行過程中,中間的SQLTask、MapReduce Task等運行時產生的Web日誌狀態資訊,可以協助使用者查看基於MaxCompute啟動並執行SQL、MR、Graph等任務的狀態或調試運行出現的問題。詳情請參考使用Logview查看作業運行資訊。
任務被killed(ERROR: KILLED)怎麼辦?
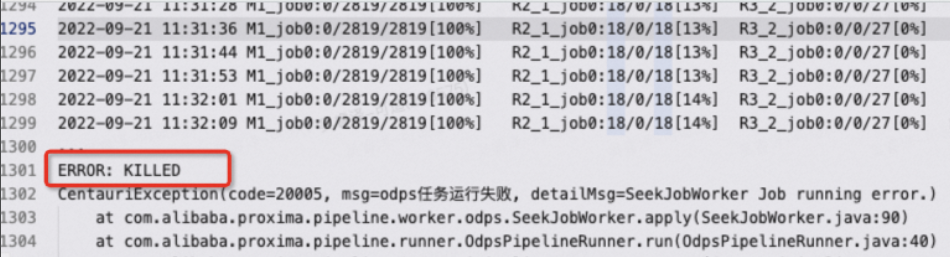 任務被kill有以下幾種可能:
任務被kill有以下幾種可能:- 任務已耗用時間過久,MaxCompute上單個SQL任務預設運行超過24小時會被kill,您可以通過設定以下參數使SQL作業延長至72小時:
set odps.sql.job.max.time.hours=72; - 叢集負載過大,資源被某個高優任務長期搶佔,系統調度kill。
- 人為kill,可以詢問Project Owner是否處理過,或者其他具有Project管理員權限的人是否處理過。
- 提高任務優先順序,通過設定-odps_task_priority參數改變任務優先順序。詳情請參考選擇性參數。重要 該操作風險較大,因為這樣會搶佔其他高優任務的資源,需要聯絡Project Owner 或者相關負責人,確定當前Project所在叢集沒有高優的線上或離線任務。
- 等待高優任務資源洪峰過後再執行Proxima CE任務。
為什麼-odps_task_priority設定的任務優先順序不起作用?
如果您的Project設定了基準優先順序,當您設定的優先順序高於基準優先順序時,所設定的優先順序將會失效。基準詳情請參考基準管理。