Centauri是Proxima CE的前身。本文為您介紹Centauri在不同情境下的效能表現。
1億*1億 BINARY512
doc表與query表資料量均為1億,資料類型為BINARY,維度為512,手動指定50行,4列檢索。
測試結論
CE雜湊分區相較Centauri效能提升約20%左右。
- | Kmeans耗時(秒) | AutoTuning耗時(秒) | Build耗時(秒) | Seek耗時(秒) | 總時間(分鐘) |
Centauri | - | 1524 | 12653 | 5914 | 336分鐘 |
CE hash | - | - | 9647 | 6431 | 268分鐘 |
Kmeans是Proxima CE聚類分區特有的一個階段,用於擷取原始doc表的聚類中心點表。AutoTuning是Centauri特有的階段,用於計算索引演算法的參數。Build為索引構建階段。Seek為檢索階段。
測試過程
Build比較。
Centauri
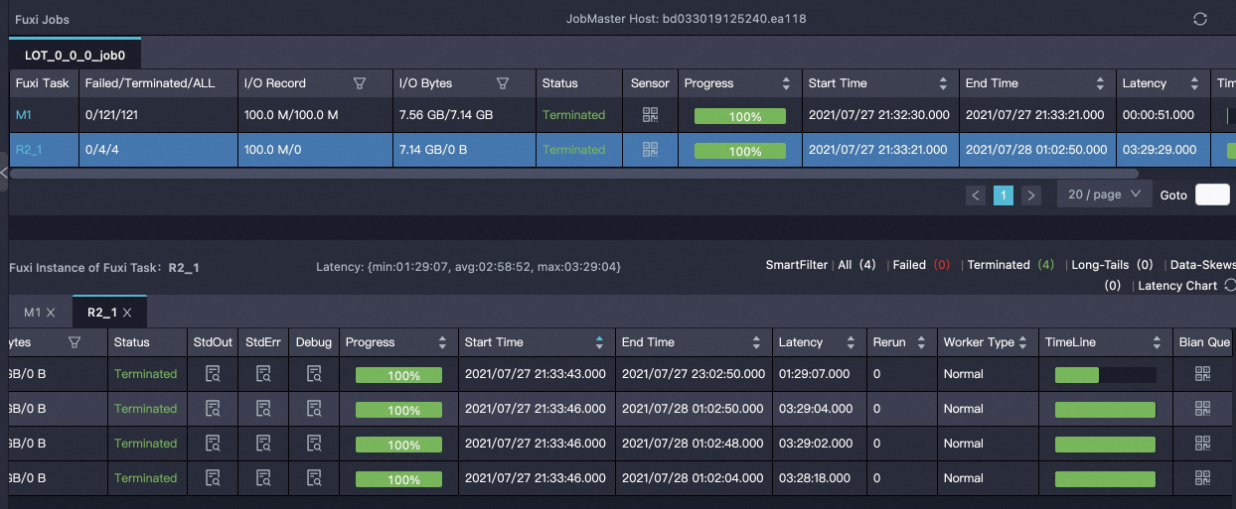
CE hash
結果分析:Centauri一個build節點特別快,剩餘三個耗時差不多。CE hash兩個相對快,兩個相對慢。
Seek比較。
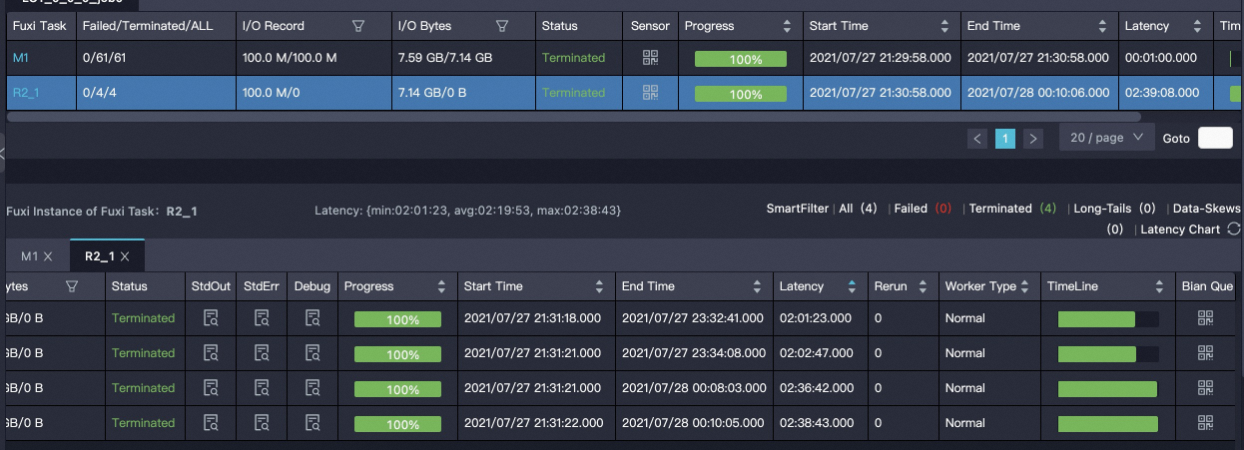
Centauri

CE hash

結果分析:
索引seek部分耗時接近。
結果merge部分:CE hash比Centauri多12分鐘左右。
CE hash最快8分鐘,最慢20分鐘。
Centauri最快4分鐘,最慢9分鐘。
運行詳情。
Centauri
向量檢索 資料類型:binary , 向量維度:512 , 檢索方式:graph , 計算方法:hamming , 構建模式build:seek doc表資訊 表名: doc_table_pailitao_binary , 分區:20210712 , doc數量:100000000 , 向量分隔字元:~ query表資訊 表名: doc_table_pailitao_binary , 分區:20210712 , query數量:100000000 , 向量分隔字元:~ 輸出表資訊 表名: output_table_pailitao_binary_centauri , 分區:20210712 行列資訊 行數: 50 , 列數:4 , 每列索引doc數量:25000000 是否清楚Volume索引:false 是否進行Autotuning Normal訓練參數和召回率:true 各個worker的耗時(單位:秒): worker:TmpDataTableJoinWorker , times:0 worker:TmpTableWorker , times:16 worker:CleanUpWorker , times:4 worker:AutotuningFastWorker , times:46 worker:RowColWorker , times:53 worker:SeekJobWorker , times:5914 worker:BuildJobWorker , times:12653 worker:AutotuningNormalWorker , times:1478 總耗時(單位:分鐘):336 Top召回率 使用者佈建 train: top200:0.95 Top召回率 normal train: top200:98.061% Autotuning Fast Build Params: proxima.general.builder.memory_quota=0 proxima.graph.common.max_doc_cnt=27500000 proxima.general.builder.thread_count=15 proxima.hnsw.builder.efconstruction=400 proxima.graph.common.neighbor_cnt=100 Autotuning Normal Search Params: proxima.hnsw.searcher.ef=400 運行命令 jar -resources centauri-1.1.5.jar,libcentauri-1.1.5.so -classpath /data/jiliang.ljl/centauri_1.1.5/centauri-1.1.5.jar com.alibaba.proxima.CentauriRunner -proxima_version 1.1.5 -doc_table doc_table_pailitao_binary -doc_table_partition 20210712 -query_table doc_table_pailitao_binary -query_table_partition 20210712 -output_table output_table_pailitao_binary_centauri -output_table_partition 20210712 -data_type binary -dimension 512 -app_id 201220 -pk_type int64 -clean_build_volume false -distance_method hamming -binary_to_int true -row_num 50 -column_num 4;CE hash
向量檢索 資料類型:1 , 向量維度:512 , 檢索方式:hnsw , 計算方法:Hamming , 構建模式build:seek doc表資訊 表名: doc_table_pailitao_binary2 , 分區:20210712 , doc數量:100000000 , 向量分隔字元:~ query表資訊 表名: doc_table_pailitao_binary2 , 分區:20210712 , query數量:100000000 , 向量分隔字元:~ 輸出表資訊 表名: output_table_pailitao_binary_ce , 分區:20210712 行列資訊 行數: 50 , 列數:4 , 每列索引doc數量:25000000 是否清除Volume索引:false 各個worker的耗時(單位:秒): SegmentationWorker: 2 TmpTableWorker: 1 KmeansGraphWorker: 0 BuildJobWorker: 9647 SeekJobWorker: 6431 TmpResultJoinWorker: 0 RecallWorker: 0 CleanUpWorker: 3 總耗時(單位:分鐘):268 運行命令 jar -resources proxima_ce_g.jar -classpath /data/jiliang.ljl/project/proxima2-java/proxima-ce/target/binary/proxima-ce-0.1-SNAPSHOT-jar-with-dependencies.jar com.alibaba.proxima2.ce.ProximaCERunner -doc_table doc_table_pailitao_binary2 -doc_table_partition 20210712 -query_table doc_table_pailitao_binary2 -query_table_partition 20210712 -output_table output_table_pailitao_binary_ce -output_table_partition 20210712 -data_type binary -dimension 512 -app_id 201220 -pk_type int64 -clean_build_volume false -distance_method Hamming -binary_to_int true -row_num 50 -column_num 4;
10億*10億 FLOAT128
doc表與query表的資料量均為10億,資料類型為FLOAT,維度為128,手動指定50行,60列。
測試結論
CE雜湊方式相較Centauri效能提升30%左右,聚類分區方式相較Centauri效能提升2倍左右,seek部分提升7.5倍左右,INT8量化相較未經處理資料效能提升約10%。
測試方法 | 聚類/AutoTunning耗時(秒) | Build耗時(秒) | Seek耗時(秒) |
Centauri | 1220 | 9822 | 37245 |
CE 雜湊 | 無 | 9841 | 23462 |
CE 雜湊 + INT8量化 | 無 | 7600 | 21624 |
CE 聚類 | 1247 | 14404 | 5028 |
測試過程
build詳情。
測試方法
Mapper
Build Reducer
總耗時(秒)
Centauri
-
-
-
CE 雜湊
00:01:23.116
Latency:{min:00:00:03, avg:00:00:23, max:00:01:00}
02:41:43.563
Latency:{min:00:02:40, avg:01:32:33, max:02:41:33}
9841
CE 雜湊 + INT8量化
00:01:36.166
Latency:{min:00:00:09, avg:00:00:25, max:00:01:09}
02:04:11.440
Latency:{min:00:06:56, avg:01:06:06, max:02:03:53}
7600
CE 聚類
00:15:33.022
Latency:{min:00:00:03, avg:00:03:24, max:00:15:21}
03:43:37.529
Latency:{min:00:03:57, avg:01:33:32, max:03:43:35}
14404
seek詳情。
測試方法
Mapper
Topn Reducer
Merge Reducer
總耗時(秒)
問題/備忘
Centauri
00:15:45.000
34秒-11分鐘之間
08:33:50.000
98分鐘-489分鐘之間
01:30:20.000
30分鐘-70分鐘之間
37245
reducer打完日誌後30-40分鐘後結束。
mapper/topn/merge的單節點已耗用時間是另外一次logview的。
CE 雜湊
00:06:29.791
Latency:{min:00:00:02, avg:00:01:39, max:00:05:56}
04:50:42.422
Latency:{min:00:01:48, avg:01:54:33, max:03:47:54}
04:50:42.422
Latency:{min:00:00:35, avg:00:33:39, max:01:32:16}
23462
mapper和merge reducer總耗時和max差不多,接近理想,只受長尾影響。
topn reducer最後結束的兩個節點因為FO啟動比較晚,忽略這兩個節點的話總時間還能減少一小時。
CE 雜湊 + INT8量化
00:06:25.718
Latency:{min:00:00:17, avg:00:01:27, max:00:06:02}
03:58:00.566
Latency:{min:00:00:25, avg:01:06:41, max:02:40:07}
01:54:35.620
Latency:{min:00:01:56, avg:00:20:54, max:01:39:55}
21624
無
CE 聚類
00:23:51.623
Latency:{min:00:00:04, avg:00:03:01, max:00:08:34}
01:00:38.382
Latency:{min:00:05:15, avg:00:18:00, max:01:00:10}
00:12:39.341
Latency:{min:00:00:31, avg:00:07:08, max:00:12:33}
5028
無
16億*16億 FLOAT128 聚類分區
doc表與query表的資料量均為16億,資料類型為FLOAT,維度為128,自動計算行列。
16億*16億資料集規模過大,只有CE的聚類分區方式可以成功運行,以下為基本運行資料資訊。
測試方法 | 聚類/AutoTunning耗時(秒) | Build耗時(秒) | Seek耗時(秒) |
Centauri | 1127 | 19962 | 跑了兩次均失敗,OOM。 |
CE 雜湊 | 無 | 14637 | 跑了一次均失敗,超出暫存資料表限制。 |
CE 聚類 | 5478 | 17911 | 6801 |