資料跨境傳輸合規聲明
如果在使用 XCOPY 時涉及跨境資料轉送,需符合相關地區的法律法規要求。
請注意,該功能將使您在雲上的業務資料轉送至您所選擇的地區或產品部署地區,可能會涉及資料跨境。您同意並確認,您完全擁有該份業務資料的所有處置許可權,對資料轉送的行為全權負責。
您應確保您的資料轉送符合所有適用法律,包括提供充分的資料安全保護技術和策略,履行獲得個人充分明示同意、完成資料出境安全評估和申報等法定義務,且您承諾您的業務資料不含任何所適用法律限制、禁止傳輸或披露的內容。
如您未遵守前述聲明與保證,您將承擔對應的法律後果,導致阿里雲和或其他關係企業遭受任何損失的,您應承擔賠償責任。
功能介紹
跨地區資料複製(XCOPY)功能支援錶快照(Snapshot)差異複寫,適用於跨Region資料備份、遷移、共用等情境。
採用檔案級差異複寫,拷貝列壓縮的位元據檔案,兼顧傳輸效率、降低傳輸成本及資料一致性。
基於錶快照(SnapShot)複製,複製後的資料與原表解耦,獨立管理備份生命週期。
錶快照(Snapshot)副本的資料可恢復點明確,即Point-in-Time Recovery(PITR)。可以從上遊資料來源補全最近遺失資料。
差異複寫為分區(Partition)級,前後兩次複製基於同一個表的兩個Snapshot。如果有重複的分區,將不會觸發重複復制,只複製差異的分區。
計費參考:跨地區資料複製費用。
適用範圍
地區限制:中國香港、新加坡、日本(東京)。
跨Region頻寬:初始值為10Gbps,按需調整。
XCOPY對象:錶快照(SnapShot)。
錶快照支援對普通表(包括分區/非分區/聚簇表)、PK/Append Delta Table 建立,不支援對 Transaction Table 建立。
XCOPY任務數上限:
每個專案最多並發執行128個XCOPY Snapshot,超過限制後任務提交會失敗。
許可權限制:
待覆制資料來源的專案和複製目標的專案必須歸屬於同一個主帳號。
在待覆制資料來源的專案中,具備待覆製表快照(SnapShot)的
SELECT許可權。在複製目標的專案中,具備
CREATE TABLE許可權。
備Region的備份Project建議只用於儲存備份資料和臨時查詢,如需在備Region跑生產業務建議另外建立Project。
XCOPY功能開通
開通步驟
通過提交工單,提供待備份的專案名稱。
在控制台開啟XCOPY通道開關。
在資料來源Region開啟XCOPY通道开关,允許資料來源Region中的資料被有許可權的使用者通過XCOPY方式複製到其他Region。
登入MaxCompute控制台,在左上方選擇地區。
在左側導覽列,選擇 。
在租户管理頁面,單擊租户属性頁簽。
在租户属性頁簽,開啟XCOPY通道开关。
XCOPY命令說明
命令格式
XCOPY SNAPSHOT <src_remote_project_name>.<src_remote_snapshot_name>
TO SNAPSHOT [<dest_local_project_name>.]<dest_local_snapshot_name>
OPTIONS(src_region=<region_name>); 參數說明
src_remote_project_name:待覆制資料來源的專案名稱。
src_remote_snapshot_name:待覆制資料來源專案中的錶快照(SnapShot)名稱。
dest_local_project_name:選填。複製目標的專案名稱。
dest_local_snapshot_name:複製目標的專案中待建立或覆蓋的錶快照(SnapShot)名稱。
region_name:待覆制資料來源的地區名稱。例如中國香港:cn-hongkong,日本(東京):ap-northeast-1。更多region name參考Region name。
使用樣本
該樣本實現新加坡(SGP)主 Region 到中國香港(HK)備 Region 的資料容災備份。如下圖所示:
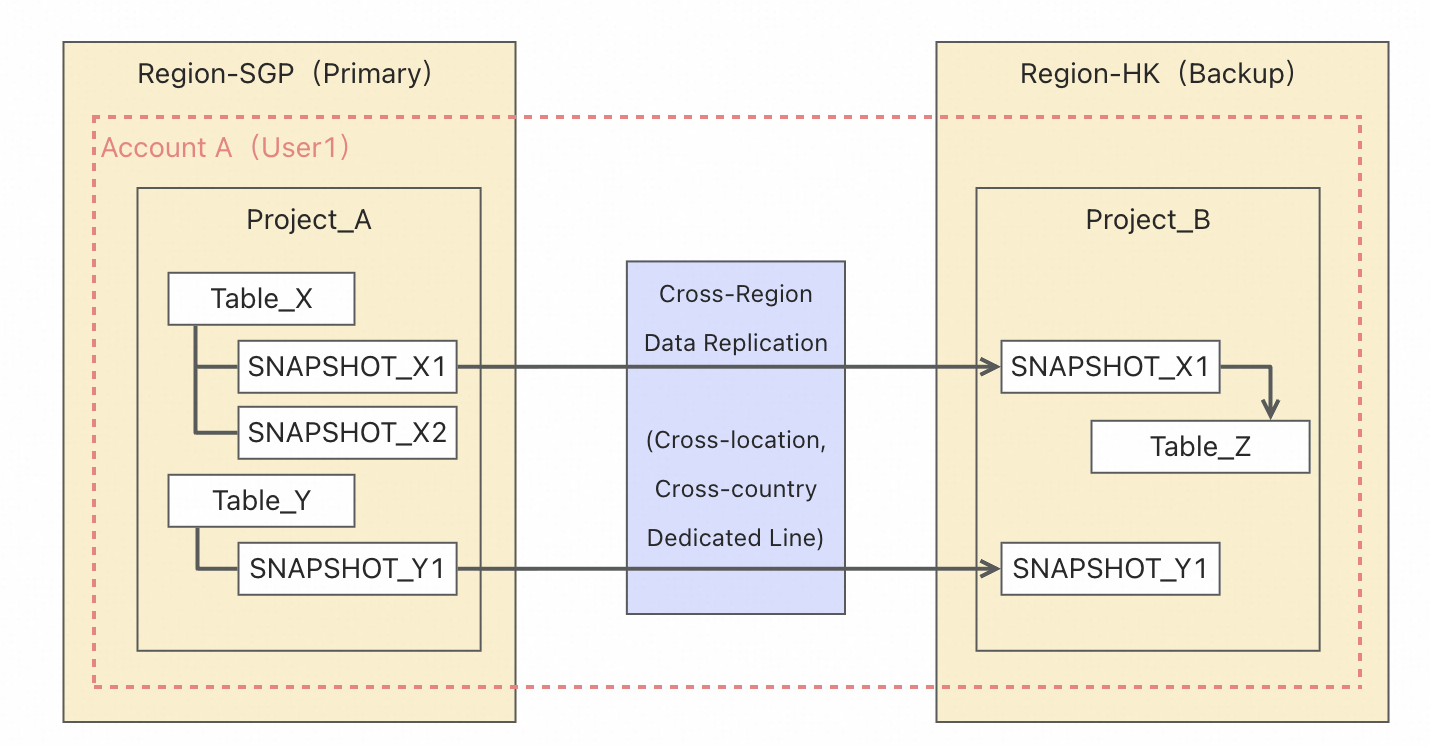
備份階段
主地區(Region-SGP):Account A(User1)下的 Project_A 包含源表 Table_X 和 Table_Y,分別建立快照 SNAPSHOT_X1/X2 和 SNAPSHOT_Y1。
-- 備份階段 -- User在 Region-SGP 建立快照 CREATE SNAPSHOT TABLE Project_A.table_x_snapshot_20260101 CLONE Project_A.table_x;跨域複製
通過跨地、跨國專線將快照資料從主 Region複製到備 Region。
-- User在 Region-HK Copy Region-SGP 建立的快照 XCOPY SNAPSHOT Project_A.table_x_snapshot_20260101 TO SNAPSHOT Project_B.table_x_snapshot_20260101 OPTIONS( src_region =” ap-southeast-1”);恢複階段
備地區(Region-HK):Project_B 接收複製後的快照,可基於快照恢複為 Table_Z 等目標表。
-- 恢複階段 -- User在 Region-HK 臨時查詢備份資料 SELECT * FROM Project_B.table_x_snapshot_20260101; -- User在 Region-HK 恢複資料 CREATE TABLE table_x CLONE table_x_snapshot_20260101;
每日跨Region備份固定的Table
步驟一:在主Region建立Snapshot
進入 DataWorks 開發環境
登入DataWorks控制台,在左上方選擇地區。
在左側導覽列選擇工作空間。
選擇工作空間,單擊進入Data Studio。
建立MaxCompute SQL 節點
在Data Studio左側,單擊
 ,選擇。
,選擇。節點名稱:create_daily_snapshots
節點描述:每日為表建立快照
編寫 SQL 指令碼
-- 表a快照命名方式為a_snapshot_20260101 -- var1、var2 在右側導覽列回合組態中,配置為$[yyyymmdd],表示目前時間 CREATE SNAPSHOT TABLE a_snapshot_${var1} CLONE a; CREATE SNAPSHOT TABLE b_snapshot_${var2} CLONE b;配置調度屬性
點擊節點右上方調度配置,單擊調度時間,配置屬性如下:
配置項
填寫樣本
調度周期
日
調度時間
01:00
生效日期
永久生效
指定時間:2026-01-01 ~ 9999-12-31(長期有效)
步驟二:在備Region XCOPY Snapshot
進入 DataWorks 開發環境
登入DataWorks控制台,在左上方選擇地區。
在左側導覽列選擇工作空間。
選擇工作空間,單擊進入Data Studio。
建立MaxCompute SQL 節點
在Data Studio左側,單擊
,選擇。節點名稱:create_daily_snapshots
節點描述:每日為表建立快照
編寫 SQL 指令碼
-- 表a快照命名方式為a_snapshot_20260101 -- var1、var2 在右側導覽列回合組態中,配置為$[yyyymmdd],表示目前時間 CREATE SNAPSHOT TABLE a_snapshot_${var1} CLONE a; CREATE SNAPSHOT TABLE b_snapshot_${var2} CLONE b; -- 表a快照命名方式為a_snapshot_20260101 XCOPY SNAPSHOT src_project.a_snapshot_$[yyyymmdd] TO SNAPSHOT a_snapshot_$[yyyymmdd] options(src_region="cn-hongkong"); XCOPY SNAPSHOT src_project.b_snapshot_$[yyyymmdd] TO SNAPSHOT b_snapshot_$[yyyymmdd] options(src_region="cn-hongkong");配置調度屬性
點擊節點右上方調度配置,單擊調度時間,配置屬性如下:
配置項
填寫樣本
調度周期
日
調度時間
02:00
生效日期
永久生效
指定時間:2026-01-01 ~ 9999-12-31(長期有效)
步驟三:在備Region檢查Snapshot完整性
在租戶層級Information Schema中檢查備 Region Snapshot 是否全部建立完成。
在備 Region 中執行如下代碼,查看Snapshot建立數量是否與 XCOPY 複製的Snapshot 數量一致。
SET odps.namespace.schema=true; SELECT * FROM SYSTEM_CATALOG.INFORMATION_SCHEMA.tables WHERE table_catalog = <dest_project> AND table_type = 'SNAPSHOT_TABLE' AND table_name LIKE "%_snapshot_20260101";資料內容抽樣驗證(按需執行)
在主、備Region 計算Snapshot的統計資訊和 MD5,驗證資料一致性。
-- 通過count、sum、distinct、min、max統計對比。 -- 把Table分1000個桶進行細分對比,確保每個桶內資料每行的MD5求和結果一致。每行的MD5計算方式為該行每列資料拼裝成字串算MD5。 WITH table_hashs AS ( SELECT COUNT(1) row_count, MD5( SUM( MD5( CONCAT_WS('|', <column_name_1>, <column_name_n>) ) ) ) AS bucket_hash FROM <snapshot_name> GROUP BY HASH(<column_name_1>) % 1000 ) SELECT SUM(row_count) AS row_count, MD5(WM_CONCAT(',', bucket_hash ) WITHIN GROUP (ORDER BY bucket_hash)) AS table_hash FROM table_hashs;