本文主要為您介紹使用Spark串連Phoenix,並將HBase中的資料寫入到MaxCompute的實踐方案。
背景資訊
Phoenix是HBase提供的SQL層,主要為瞭解決高並發、低延遲、簡單查詢等情境。為了滿足使用者在Spark on MaxCompute環境下訪問Phoenix的資料需求,本文從Phoenix表的建立與資料寫入,再到IDEA上的Spark代碼編寫以及DataWorks上代碼的煙霧測試 (Smoke Test),完整的描述了Spark on MaxCompute訪問Phoenix的資料實踐方案。
前提條件
在實踐之前,您需要提前做好以下準備工作:
已開通MaxCompute服務並建立MaxCompute專案。詳情請參見開通MaxCompute服務和建立MaxCompute專案。
已開通DataWorks服務。詳情請參見DataWorks購買指導。
已開通HBase服務,詳情請參見HBase購買指導。
說明本實踐內容是以HBase 1.1版本為例。實際開發中,您也可以配套其他HBase版本。
已下載並安裝Phoenix 4.12.0版本。詳情請參見HBase SQL(Phoenix) 4.x使用說明。
說明HBase 1.1版本對應的Phoenix版本為4.12.0,實際開發過程中需要注意版本對應關係。
已開通Virtual Private Cloud,並配置了HBase叢集安全性群組。詳情請參見網路開通流程。
說明本實踐中,HBase是在VPC的網路環境下,所以安全性群組開放連接埠為2181、10600、16020。
操作步驟
進入Phoenix的
bin目錄,執行如下樣本命令啟動Phoenix用戶端。./sqlline.py hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181說明hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181為ZooKeeper的串連地址。您可以通過登入HBase控制台,在HBase叢集執行個體詳情頁的資料庫連接頁面擷取ZooKeeper的串連地址。在Phoenix用戶端,執行如下語句建立表users,並插入資料。
CREATE TABLE IF NOT EXISTS users( id UNSIGNED_INT, username char(50), password char(50) CONSTRAINT my_ph PRIMARY KEY (id)); UPSERT INTO users(id,username,password) VALUES (1,'kongxx','Letmein');說明Phoenix文法詳情,請參見HBase SQL(Phoenix) 入門。
在Phoenix用戶端,執行如下語句查看users表的資料。
select * from users;在IDEA編譯工具編寫Spark代碼邏輯並打包。
使用Scala程式設計語言編寫Spark代碼邏輯進行測試。
在IDEA中按照對應的Pom檔案配置本地開發環境。您可以先使用公網串連地址進行測試,待代碼邏輯驗證成功後再調整程式碼範例中spark.hadoop.odps.end.point參數內容。公網串連地址請通過登入HBase控制台,在HBase叢集執行個體詳情頁的資料庫連接頁面擷取。具體代碼如下:
package com.phoenix import org.apache.hadoop.conf.Configuration import org.apache.spark.sql.SparkSession import org.apache.phoenix.spark._ /** * 本樣本適用於Phoenix 4.x版本。 */ object SparkOnPhoenix4xSparkSession { def main(args: Array[String]): Unit = { //HBase叢集的ZooKeeper串連地址。 val zkAddress = hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181,hb-2zecxg2ltnpeg8me4-master*-***.hbase.rds.aliyuncs.com:2181 //Phoenix側的表名。 val phoenixTableName = users //Spark側的表名。 val ODPSTableName = users_phoenix val sparkSession = SparkSession .builder() .appName("SparkSQL-on-MaxCompute") .config("spark.sql.broadcastTimeout", 20 * 60) .config("spark.sql.crossJoin.enabled", true) .config("odps.exec.dynamic.partition.mode", "nonstrict") // 需設定spark.master為local[N]才能直接運行,N為並發數。 //.config("spark.master", "local[4]") .config("spark.hadoop.odps.project.name", "***") .config("spark.hadoop.odps.access.id", "***") .config("spark.hadoop.odps.access.key", "***") //.config("spark.hadoop.odps.end.point", "http://service.cn.maxcompute.aliyun.com/api") .config("spark.hadoop.odps.end.point", "http://service.cn-beijing.maxcompute.aliyun-inc.com/api") .config("spark.sql.catalogImplementation", "odps") .getOrCreate() var df = sparkSession.read.format("org.apache.phoenix.spark").option("table", phoenixTableName).option("zkUrl",zkAddress).load() df.show() df.write.mode("overwrite").insertInto(ODPSTableName) } }對應的POM檔案如下。
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <properties> <spark.version>2.3.0</spark.version> <cupid.sdk.version>3.3.8-public</cupid.sdk.version> <scala.version>2.11.8</scala.version> <scala.binary.version>2.11</scala.binary.version> <phoenix.version>4.12.0-HBase-1.1</phoenix.version> </properties> <groupId>com.aliyun.odps</groupId> <artifactId>Spark-Phonix</artifactId> <version>1.0.0-SNAPSHOT</version> <packaging>jar</packaging> <dependencies> <dependency> <groupId>org.jpmml</groupId> <artifactId>pmml-model</artifactId> <version>1.3.8</version> </dependency> <dependency> <groupId>org.jpmml</groupId> <artifactId>pmml-evaluator</artifactId> <version>1.3.10</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> <exclusions> <exclusion> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> </exclusion> <exclusion> <groupId>org.scala-lang</groupId> <artifactId>scalap</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.binary.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.aliyun.odps</groupId> <artifactId>cupid-sdk</artifactId> <version>${cupid.sdk.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-core</artifactId> <version>4.12.0-AliHBase-1.1-0.8</version> <exclusions> <exclusion> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-mapred</artifactId> </exclusion> <exclusion> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-commons</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-spark</artifactId> <version>4.12.0-AliHBase-1.1-0.8</version> <exclusions> <exclusion> <groupId>com.aliyun.phoenix</groupId> <artifactId>ali-phoenix-core</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <minimizeJar>false</minimizeJar> <shadedArtifactAttached>true</shadedArtifactAttached> <artifactSet> <includes> <!-- Include here the dependencies you want to be packed in your fat jar --> <include>*:*</include> </includes> </artifactSet> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>**/log4j.properties</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>reference.conf</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/services/org.apache.spark.sql.sources.DataSourceRegister</resource> </transformer> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.3.2</version> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile-first</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>在IDEA中將代碼以及依賴檔案打成JAR包,並通過MaxCompute用戶端上傳至MaxCompute專案環境中。詳情請參見添加資源。
說明由於DatadWork介面方式上傳JAR包有50 MB的限制,因此採用MaxCompute用戶端上傳JAR包。
在DataWorks上進行煙霧測試 (Smoke Test)。
按照如下建表語句,在DataWorks上建立MaxCompute表。詳情請參見建立並使用MaxCompute表。
CREATE TABLE IF NOT EXISTS users_phoenix ( id INT , username STRING, password STRING ) ;在DataWorks上,選擇對應的MaxCompute專案環境,將上傳的JAR包添加到資料開發環境中。詳情請參見建立並使用MaxCompute資源。
建立ODPS Spark,並設定任務參數。詳情請參見開發ODPS Spark任務。
提交Spark任務的配置參數如下圖所示。
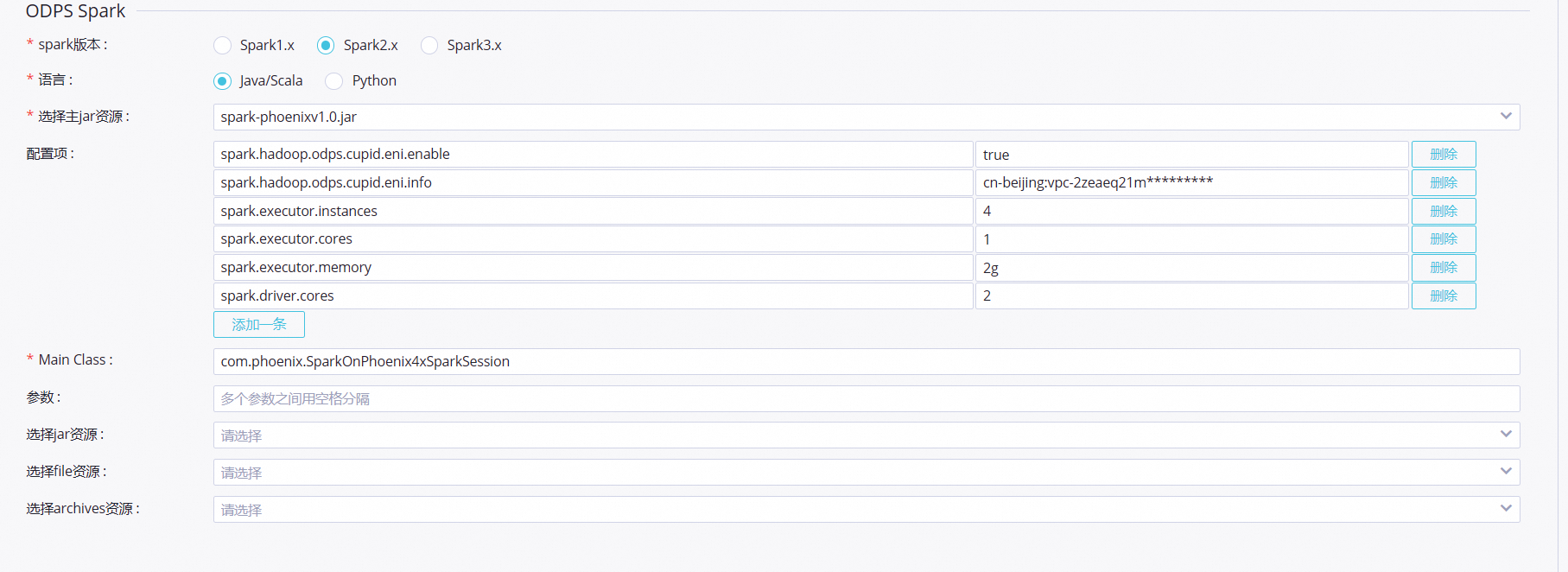
spark.hadoop.odps.cupid.eni.enable = true spark.hadoop.odps.cupid.eni.info=cn-beijing:vpc-2zeaeq21mb1dmkqh0****單擊
 表徵圖開始煙霧測試 (Smoke Test)。
表徵圖開始煙霧測試 (Smoke Test)。
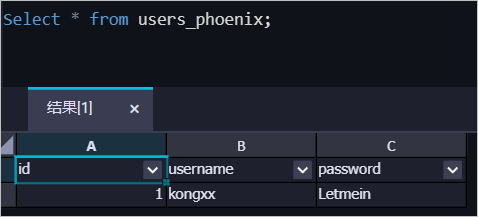
煙霧測試 (Smoke Test)成功後,在臨時查詢節點中執行如下查詢語句。
SELECT * FROM users_phoenix;可以看到資料已經寫入MaxCompute的表中。