本文以E-MapReduce的Serverless Spark叢集為例,為您介紹在MaxCompute中如何使用Schemaless Query的方式讀取Spark SQL產生的Parquet檔案,並在計算完成後將結果通過UNLOAD命令傳回至OSS。
前提條件
本文以華東1(杭州)地區為例,假設建立的工作空間名稱為
schemaless_test,OSS Bucket名稱為oss-mc-test。
步驟一:基於Serverless Spark產生Parquet資料
登入E-MapReduce控制台。在左側導覽列,選擇。
在Spark頁面單擊已建立的工作空間名稱,進入EMR Serverless Spark頁面後,單擊左側的資料開發。
建立Spark SQL任務,輸入如下SQL命令以建立Parquet格式表並寫入資料,然後單擊運行。
重要執行下述命令前,請確保頁面右上方已選擇的資料目錄和資料庫所關聯的路徑為已建立的OSS Bucket路徑。
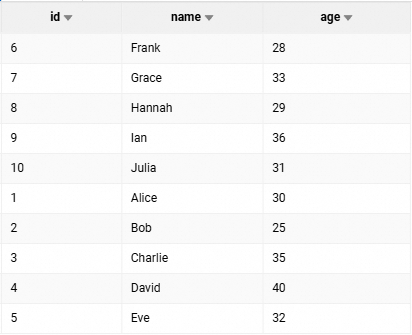
CREATE TABLE example_table01 ( id INT, name STRING, age INT ) USING PARQUET; INSERT INTO example_table01 VALUES (1, 'Alice', 30), (2, 'Bob', 25), (3, 'Charlie', 35), (4, 'David', 40), (5, 'Eve', 32), (6, 'Frank', 28), (7, 'Grace', 33), (8, 'Hannah', 29), (9, 'Ian', 36), (10, 'Julia', 31); SELECT * FROM example_table01;返回結果如下:
運行成功後,您可在DLF資料湖構建控制台的中繼資料管理頁面查看已產生的
example_table01表。
也可在OSS Bucket目錄下查看產生的Parquet檔案。

步驟二:通過Schemaless Query讀取資料
在MaxCompute中讀取Parquet檔案,詳情請參見特色功能:Schemaless Query。
由於在寫入Parquet表時會產生一個名為_SUCCESS的檔案,您需要配合file_pattern_blacklist參數,將_SUCCESS檔案添加至黑名單中不讀取該檔案,如未添加該參數,則會報錯。
SELECT * FROM
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/example_table01/'
(
'file_format'='parquet',
'file_pattern_blacklist'='.*_SUCCESS.*'
);返回結果如下:
+------------+------------+------------+
| id | name | age |
+------------+------------+------------+
| 1 | Alice | 30 |
| 2 | Bob | 25 |
| 3 | Charlie | 35 |
| 4 | David | 40 |
| 5 | Eve | 32 |
| 6 | Frank | 28 |
| 7 | Grace | 33 |
| 8 | Hannah | 29 |
| 9 | Ian | 36 |
| 10 | Julia | 31 |
+------------+------------+------------+步驟三:使用SQL進行計算
查詢年齡大於30歲的總人數。
SELECT COUNT(*) FROM
LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/example_table01/'
(
'file_format'='parquet',
'file_pattern_blacklist'='.*_SUCCESS.*'
)
WHERE age>30;返回結果如下:
+------------+
| _c0 |
+------------+
| 6 |
+------------+步驟四:將計算結果通過UNLOAD命令回傳至OSS
MaxCompute支援您將MaxCompute專案中的資料匯出至外部儲存OSS,以供其他計算引擎使用。具體使用請參見UNLOAD。
在MaxCompute中執行如下命令,將步驟三:使用SQL進行計算的計算結果以Parquet格式匯出至OSS。
執行下述代碼前,您需在OSS Bucket
oss-mc-test下建立unload_schemaless目錄。UNLOAD FROM ( SELECT COUNT(*) FROM LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/example_table01/' ('file_format'='parquet','file_pattern_blacklist'='.*_SUCCESS.*') WHERE age>30 ) INTO LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/unload_schemaless/' ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::<uid>:role/AliyunODPSDefaultRole') STORED AS PARQUET PROPERTIES('mcfed.parquet.compression'='SNAPPY') ;登入OSS控制台,查看是否UNLOAD成功。
