本文為您介紹MaxCompute如何訪問Hologres。
背景資訊
Hologres是阿里雲即時互動式分析產品。Hologres具備高並發地即時寫入和查詢資料的能力,同時支援資料無需遷移就能高效能加速分析MaxCompute資料,通過聯邦分析Hologres即時資料與MaxCompute離線資料,實現離線即時一體化的資料倉儲產品解決方案。您可以使用MaxCompute和Hologres的組合方案,來滿足大規模離線分析、即時營運分析、互動式查詢等多業務情境。
MaxCompute SQL外部表格的方式訪問Hologres,詳情請參見MaxCompute SQL外部表格方式訪問Hologres。
MaxCompute Spark方式訪問Hologres,如下所示。
前提條件
已準備MaxCompute相應的環境。
已開通MaxCompute服務並建立Hologres外部表格的目標MaxCompute專案。
開通MaxCompute服務以及建立MaxCompute專案的操作指導,請參見開通MaxCompute和建立MaxCompute專案。
已安裝MaxCompute用戶端。
安裝MaxCompute用戶端的操作指導,請參見安裝並配置MaxCompute用戶端。
已搭建MaxCompute Spark開發環境。
本實踐的MaxCompute Spark開發環境搭建在Linux作業系統下,使用的是Spark2.4.5發布包。具體的操作指導,請參見搭建MaxCompute Spark開發環境。
已開通DataWorks服務。
開通DataWorks服務的操作指導,請參見開通DataWorks服務。
已開通Hologres服務並串連HoloWeb。
開通Hologres並串連HoloWeb的操作指導,請參見開通Hologres和串連HoloWeb並執行查詢。
已下載PostgreSQL的JDBC驅動包。
本實踐使用的是
postgresql-42.2.16.jar驅動包,並且將該JAR包存放在Linux的/home/postgreSQL路徑下。您可以通過PostgreSQL驅動官網下載。
MaxCompute SQL外部表格方式訪問Hologres
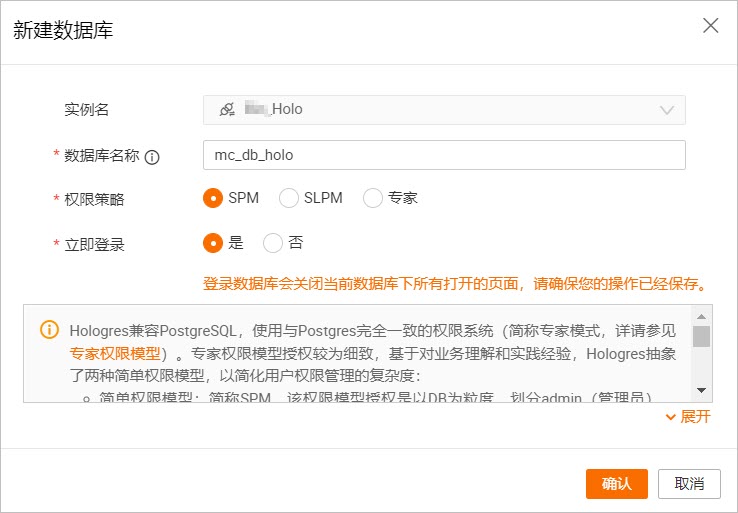
在Hologres管理主控台,選擇目標執行個體並建立Hologres資料庫
mc_db_holo。建立Hologres資料庫的操作指導,請參見建立Hologres資料庫。
在HoloWeb開發介面的
mc_db_holo資料庫下,執行如下語句建立Hologres表mc_sql_holo並插入資料。建立Hologres表的操作指導,請參見建立Hologres表。
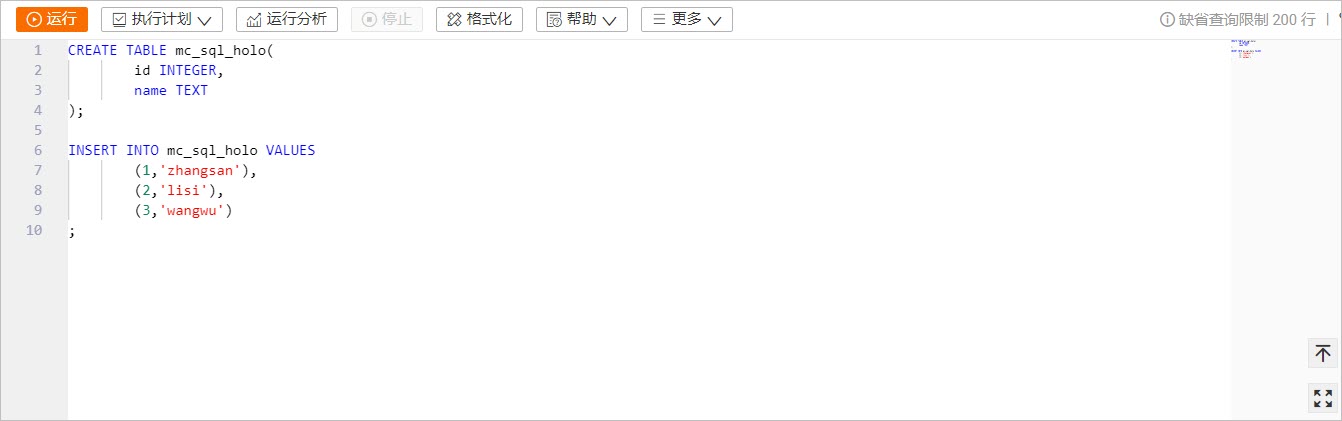
CREATE TABLE mc_sql_holo( id INTEGER, name TEXT ); INSERT INTO mc_sql_holo VALUES (1,'zhangsan'), (2,'lisi'), (3,'wangwu') ;在RAM存取控制台建立RAM角色
AliyunOdpsHoloRole並修改信任策略配置內容。建立RAM角色並修改信任策略配置內容的操作指導,請參見建立RAM角色。
說明本實踐建立的RAM角色可信實體類型為阿里雲帳號。
添加
AliyunOdpsHoloRoleRAM角色至Hologres執行個體並授權。添加RAM角色至Hologres執行個體並授權的操作指導,請參見添加RAM角色至Hologres執行個體並授權。
在MaxCompute用戶端,按照如下語句建立Hologres外部表格
mc_externaltable_holo。create external table if not exists mc_externaltable_holo ( id int , name string ) stored by 'com.aliyun.odps.jdbc.JdbcStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::13969******5947:role/aliyunodpsholorole') LOCATION 'jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80/mc_db_holo?currentSchema=public&useSSL=false&table=mc_sql_holo/' TBLPROPERTIES ( 'mcfed.mapreduce.jdbc.driver.class'='org.postgresql.Driver', 'odps.federation.jdbc.target.db.type'='holo', 'odps.federation.jdbc.colmapping'='id:id,name:name' );說明建立外部表格參數說明,請參見Hologres外部表格。
建立完成後,在MaxCompute用戶端執行如下語句,擷取Hologres外部表格的資料。
set odps.sql.split.hive.bridge=true; set odps.sql.hive.compatible=true; select * from mc_externaltable_holo limit 10;說明SET操作的屬性說明,詳情請參見SET操作。
結果如下所示:
+----+----------+ | id | name | +----+----------+ | 1 | zhangsan | | 2 | lisi | | 3 | wangwu | +----+----------+在MaxCompute用戶端執行如下語句,寫資料至Hologres外部表格。
set odps.sql.split.hive.bridge=true; set odps.sql.hive.compatible=true; insert into mc_externaltable_holo values (4,'alice');在HoloWeb開發介面,查詢Hologres表
mc_sql_holo中資料。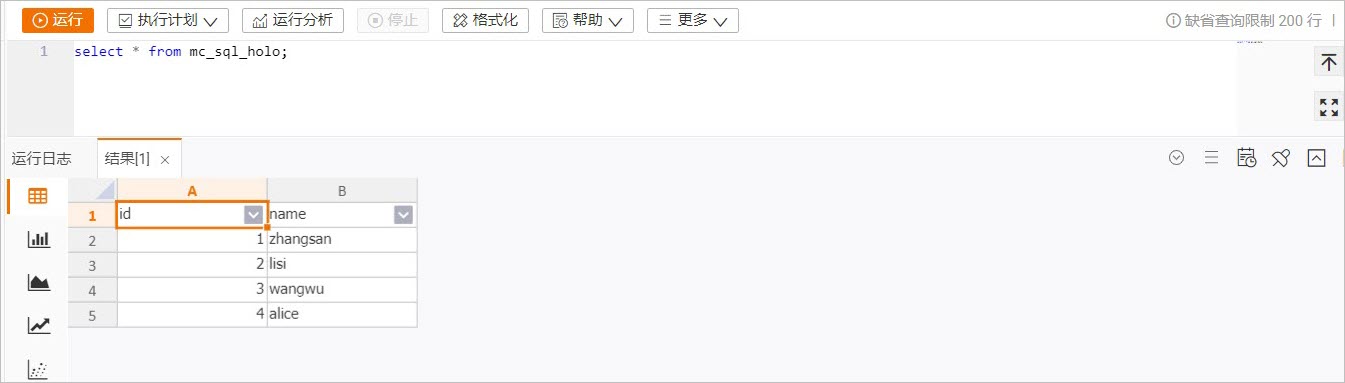
select * from mc_sql_holo;
MaxCompute Spark訪問Hologres:Local提交模式
在HoloWeb開發介面的
mc_db_holo資料庫下,執行如下語句建立Hologres表mc_jdbc_holo。建立Hologres表的操作指導,請參見建立Hologres表。
CREATE TABLE mc_jdbc_holo( id INTEGER, name TEXT );在Linux作業系統的/home/pythoncode路徑下,建立Python檔案
holo_local.py。Python指令碼內容如下所示:
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Spark_local") \ .config("spark.eventLog.enabled","false") \ .getOrCreate() jdbcDF = spark.read.format("jdbc"). \ options( url='jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou.hologres.aliyuncs.com:80/mc_db_holo', dbtable='mc_jdbc_holo', user='LTAI****************', password='********************', driver='org.postgresql.Driver').load() jdbcDF.printSchema()指令碼內容參數說明如下所示:
url:使用Spark的JDBC串連方式,驅動為
postgresql。hgprecn-cn-2r42******-cn-hangzhou.hologres.aliyuncs.com:80:Hologres執行個體的公網訪問網域名稱。擷取方式,請參見執行個體配置。
mc_db_holo:串連的Hologres資料庫名稱。本實踐命名為mc_db_holo。
dbtable:Hologres源表名稱。本實踐命名為mc_jdbc_holo。
user:阿里雲帳號或RAM使用者的AccessKey ID。您可以進入AccessKey管理頁面擷取AccessKey ID。
password:AccessKey ID對應的AccessKey Secret。您可以進入AccessKey管理頁面擷取AccessKey Secret。
driver:PostgreSQL驅動,固定值為org.postgresql.Driver。
在Linux系統任意目錄下,使用spark-submit提交本地作業。
spark-submit --master local --driver-class-path /home/postgreSQL/postgresql-42.2.16.jar --jars /home/postgreSQL/postgresql-42.2.16.jar /home/pythoncode/holo_local.py查看Spark列印日誌,列印Schema資訊與Hologres中建立的
mc_jdbc_holo表一致,即訪問成功。
MaxCompute Spark訪問Hologres:Cluster提交模式
在HoloWeb開發介面的
mc_db_holo資料庫下,執行如下語句建立Hologres表mc_jdbc_holo。建立Hologres表的操作指導,請參見建立Hologres表。
CREATE TABLE mc_jdbc_holo( id INTEGER, name TEXT );在Linux作業系統的/home/pythoncode路徑下,建立Python檔案
holo_yarncluster.py。Python指令碼內容如下所示:
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Spark_yarn") \ .getOrCreate() jdbcDF = spark.read.format("jdbc"). \ options( url='jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80/mc_db_holo', dbtable='mc_jdbc_holo', user='LTAI****************', password='********************', driver='org.postgresql.Driver').load() jdbcDF.printSchema()指令碼內容參數說明如下所示:
url:使用Spark的JDBC串連方式,驅動為postgresql。
hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80:Hologres執行個體的傳統網路訪問網域名稱。擷取方式,請參見執行個體配置。
mc_db_holo:串連的Hologres資料庫名稱。本實踐命名為mc_db_holo。
dbtable:Hologres源表名稱。本實踐命名為mc_jdbc_holo。
user:阿里雲帳號或RAM使用者的AccessKey ID。您可以進入AccessKey管理頁面擷取AccessKey ID。
password:AccessKey ID對應的AccessKey Secret。您可以進入AccessKey管理頁面擷取AccessKey Secret。
driver:PostgreSQL驅動,固定值為org.postgresql.Driver。
配置MaxCompute Spark用戶端解壓目錄/home/spark2.4.5/spark-2.4.5-odps0.33.2/conf下的spark-defaults.conf檔案。
#需配置以下配置項 spark.hadoop.odps.project.name = <MaxCompute_Project_Name> spark.hadoop.odps.end.point = <Endpoint> spark.hadoop.odps.runtime.end.point = <VPC_Endpoint> spark.hadoop.odps.access.id = <AccessKey_ID> spark.hadoop.odps.access.key = <AccessKey_Secret> spark.hadoop.odps.cupid.trusted.services.access.list = <Hologres_Classic_Network> #以下內容保持不變 spark.master = yarn-cluster spark.driver.cores = 2 spark.driver.memory = 4g spark.dynamicAllocation.shuffleTracking.enabled = true spark.dynamicAllocation.shuffleTracking.timeout = 20s spark.dynamicAllocation.enabled = true spark.dynamicAllocation.maxExecutors = 10 spark.dynamicAllocation.initialExecutors = 2 spark.executor.cores = 2 spark.executor.memory = 8g spark.eventLog.enabled = true spark.eventLog.overwrite = true spark.eventLog.dir = odps://admin_task_project/cupidhistory/sparkhistory spark.sql.catalogImplementation = hive spark.sql.sources.default = hive設定檔參數說明如下所示:
MaxCompute_Project_Name:待訪問MaxCompute專案的名稱。
此處為MaxCompute專案名稱,非工作空間名稱。您可以登入MaxCompute控制台,左上方切換地區後,在左側導覽列選擇工作區 > 專案管理,查看MaxCompute專案名稱。
AccessKey_ID:具備目標MaxCompute專案存取權限的AccessKey ID。
您可以進入AccessKey管理頁面擷取AccessKey ID。
AccessKey_Secret:AccessKey ID對應的AccessKey Secret。
Endpoint:MaxCompute專案所屬地區的公網Endpoint。
各地區的公網Endpoint資訊,請參見各地區Endpoint對照表(公網串連方式)。
VPC_Endpoint:MaxCompute專案所屬地區的VPC網路的Endpoint。
各地區的VPC網路Endpoint資訊,請參見各地區Endpoint對照表(阿里雲VPC網路連接方式)。
Hologres_Classic_Network:Hologres傳統網路類型。配置此項主要是為了在MaxCompute安全運行沙箱環境中,開啟到對應Hologres執行個體的網路原則,否則MaxCompute叢集無法訪問外部服務。
在Linux系統任意目錄下,使用spark-submit提交作業。
spark-submit --master yarn-cluster --driver-class-path /home/postgreSQL/postgresql-42.2.16.jar --jars /home/postgreSQL/postgresql-42.2.16.jar /home/pythoncode/holo_yarncluster.py提交後可以查看Spark列印日誌,作業正常完成會列印工作的Logview以及Spark-UI的Jobview連結地址,可供開發人員進一步診斷作業。
作業的Logview連結地址。

Spark-UI的Jobview連結地址。

開啟Logview連結,如果作業執行狀態為success,選擇,查看
jdbcDF.printSchema()的返回結果。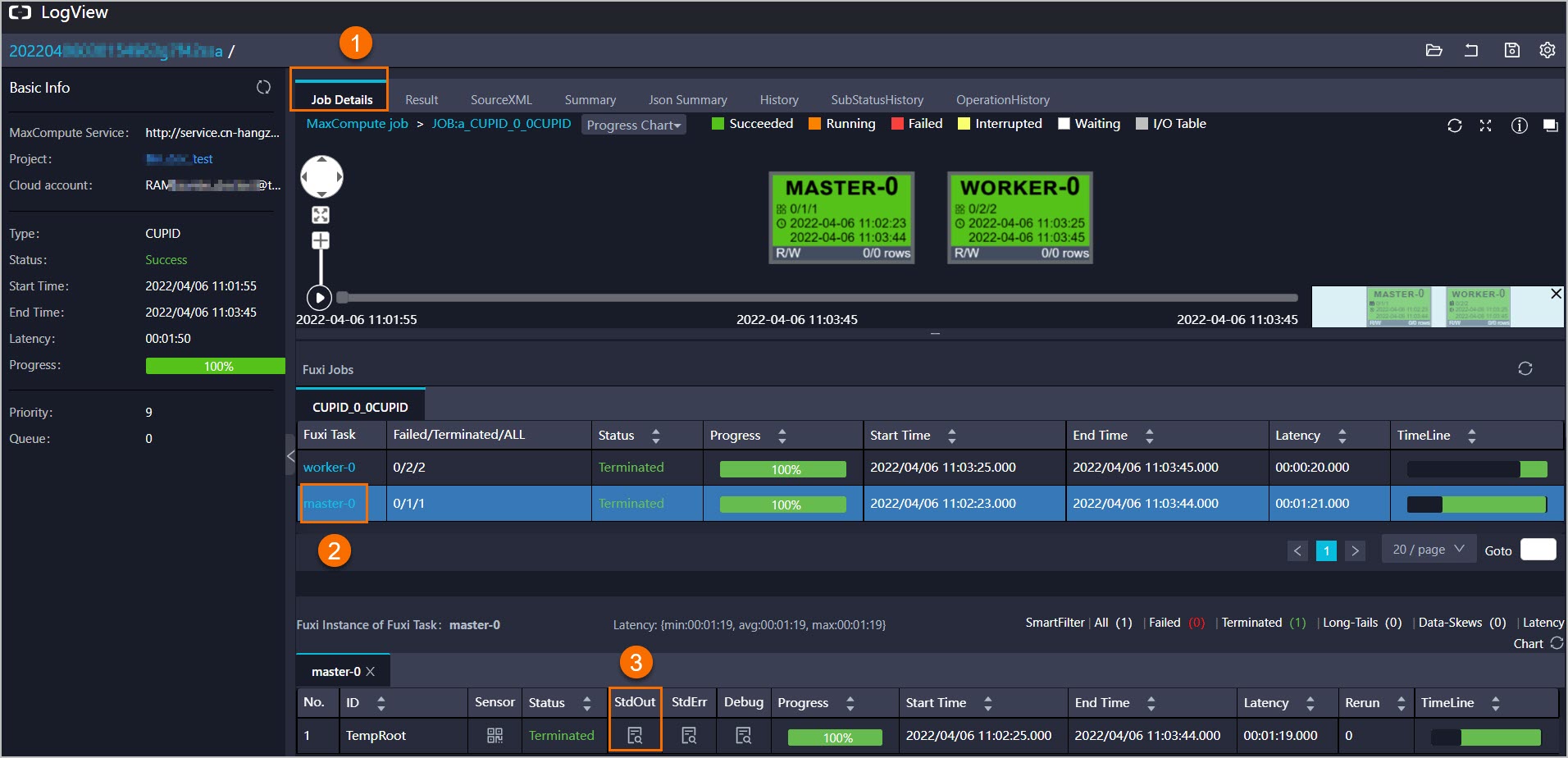
查看Stdout,列印的Schema資訊與Hologres中建立的
mc_jdbc_holo表一致,即訪問成功。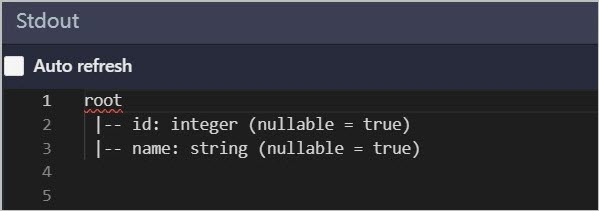 說明
說明您也可以開啟Spark-UI的Jobview連結地址,進行作業的查看與診斷。
MaxCompute Spark訪問Hologres:DataWorks提交模式
在HoloWeb開發介面的
mc_db_holo資料庫下,執行如下語句建立Hologres表mc_jdbc_holo。建立Hologres表的操作指導,請參見建立Hologres表。
CREATE TABLE mc_jdbc_holo( id INTEGER, name TEXT );配置MaxCompute Spark用戶端解壓目錄/home/spark2.4.5/spark-2.4.5-odps0.33.2/conf下的spark-defaults.conf檔案。
#需配置以下配置項 spark.hadoop.odps.project.name = <MaxCompute_Project_Name> spark.hadoop.odps.end.point = <Endpoint> spark.hadoop.odps.runtime.end.point = <VPC_Endpoint> spark.hadoop.odps.access.id = <AccessKey_ID> spark.hadoop.odps.access.key = <AccessKey_Secret> spark.hadoop.odps.cupid.trusted.services.access.list = <Hologres_Classic_Network> #以下內容保持不變 spark.master = yarn-cluster spark.driver.cores = 2 spark.driver.memory = 4g spark.dynamicAllocation.shuffleTracking.enabled = true spark.dynamicAllocation.shuffleTracking.timeout = 20s spark.dynamicAllocation.enabled = true spark.dynamicAllocation.maxExecutors = 10 spark.dynamicAllocation.initialExecutors = 2 spark.executor.cores = 2 spark.executor.memory = 8g spark.eventLog.enabled = true spark.eventLog.overwrite = true spark.eventLog.dir = odps://admin_task_project/cupidhistory/sparkhistory spark.sql.catalogImplementation = hive spark.sql.sources.default = hive設定檔參數說明如下所示:
MaxCompute_Project_Name:待訪問MaxCompute專案的名稱。
此處為MaxCompute專案名稱,非工作空間名稱。您可以登入MaxCompute控制台,左上方切換地區後,在左側導覽列選擇工作區 > 專案管理,查看MaxCompute專案名稱。
AccessKey_ID:具備目標MaxCompute專案存取權限的AccessKey ID。
您可以進入AccessKey管理頁面擷取AccessKey ID。
AccessKey_Secret:AccessKey ID對應的AccessKey Secret。
Endpoint:MaxCompute專案所屬地區的公網Endpoint。
各地區的公網Endpoint資訊,請參見各地區Endpoint對照表(公網串連方式)。
VPC_Endpoint:MaxCompute專案所屬地區的VPC網路的Endpoint。
各地區的VPC網路Endpoint資訊,請參見各地區Endpoint對照表(阿里雲VPC網路連接方式)。
Hologres_Classic_Network:Hologres傳統網路類型。配置此項主要是為了在MaxCompute安全運行沙箱環境中,開啟到對應Hologres執行個體的網路原則,否則MaxCompute叢集無法訪問外部服務。
登入DataWorks控制台。
在左側導覽列,單擊工作空間列表。
在工作空間列表頁面,單擊相應工作空間後操作列的快速進入 > 資料開發。
建立PostgreSQL JDBC資源以及ODPS Spark節點。
在目標商務程序下,右鍵選擇,在彈出的建立資源對話方塊,上傳PostgreSQL JDBC的JAR包檔案後,單擊建立。
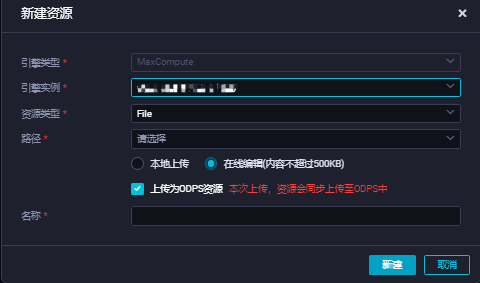 說明
說明DataWorks商務程序建立,詳情請參見建立商務程序。
DataWorks上的MaxCompute資源建立,詳情請參見建立並使用MaxCompute資源。
在目標商務程序下,右鍵選擇,在建立資源對話方塊,填寫資源名稱後,單擊建立。
本實踐將資源名稱命名為
read_holo.py。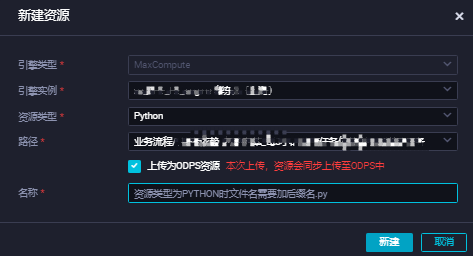
按照如下指令碼內容,編寫
read_holo.py,並單擊 。
。from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Spark") \ .getOrCreate() jdbcDF = spark.read.format("jdbc"). \ options( url='jdbc:postgresql://hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80/mc_db_holo', dbtable='mc_jdbc_holo', user='LTAI****************', password='********************', driver='org.postgresql.Driver').load() jdbcDF.printSchema()指令碼內容參數說明如下所示:
url:使用Spark的JDBC串連方式,驅動為
postgresql。hgprecn-cn-2r42******-cn-hangzhou.hologres.aliyuncs.com:80:Hologres執行個體的公網訪問網域名稱。擷取方式,請參見執行個體配置。
mc_db_holo:串連的Hologres資料庫名稱。本實踐命名為mc_db_holo。
dbtable:Hologres源表名稱。本實踐命名為mc_jdbc_holo。
user:阿里雲帳號或RAM使用者的AccessKey ID。您可以進入AccessKey管理頁面擷取AccessKey ID。
password:AccessKey ID對應的AccessKey Secret。您可以進入AccessKey管理頁面擷取AccessKey Secret。
driver:PostgreSQL驅動,固定值為org.postgresql.Driver。
在目標商務程序下,右鍵選擇,在建立節點對話方塊,填寫節點名稱後,單擊確認。
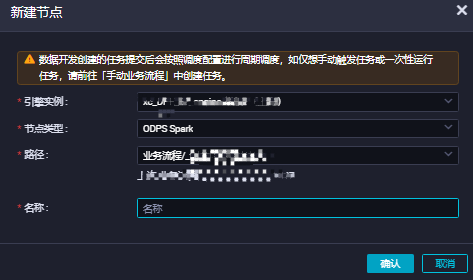
按照下圖指引,配置
spark_read_holo。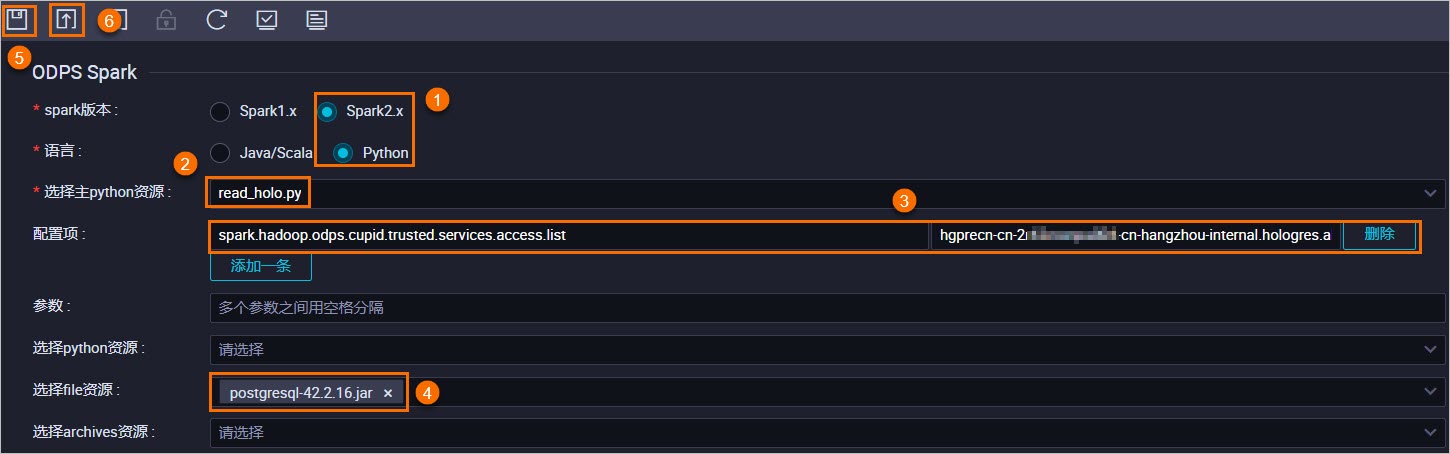
配置項:
spark.hadoop.odps.cupid.trusted.services.access.list。配置項取值:
hgprecn-cn-2r42******-cn-hangzhou-internal.hologres.aliyuncs.com:80。Hologres傳統網路類型。說明配置此項主要是為了在MaxCompute安全運行沙箱環境中,開啟到對應Hologres執行個體的網路原則,否則MaxCompute叢集無法訪問外部服務。
在目標商務程序畫板,右鍵選擇。
作業運行後,將會列印工作日誌,其中包含MaxCompute作業的診斷資訊、Logview連結地址、Spark-UI的Jobview連結地址等。
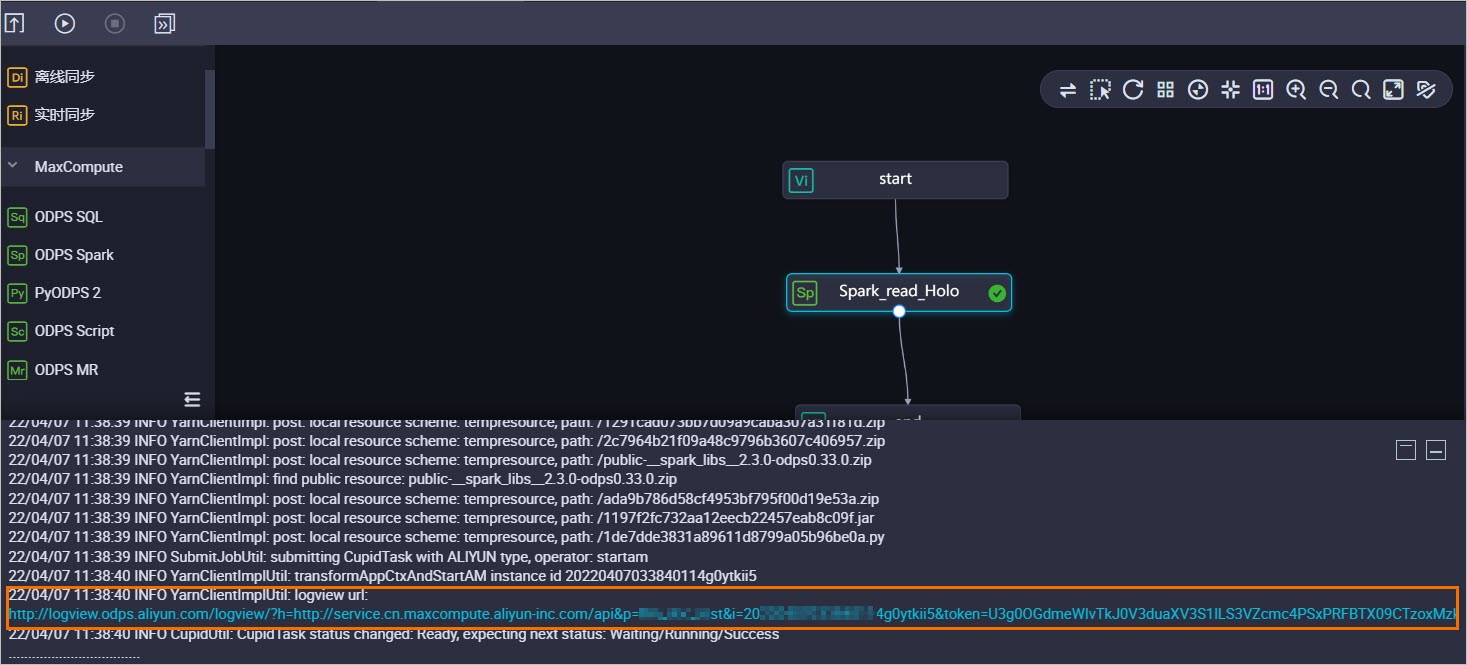
開啟Logview連結,如果作業執行狀態為success,選擇,查看
jdbcDF.printSchema()的返回結果。查看Stdout,列印的Schema資訊與Hologres中建立的
mc_jdbc_holo表一致,即訪問成功。說明您也可以開啟Spark-UI的Jobview連結地址,進行作業的查看與診斷。