現有湖倉一體架構是以MaxCompute為中心讀寫Hadoop叢集資料,有些線下IDC情境,客戶不願意對公網暴露叢集內部資訊,需要從Hadoop叢集發起訪問雲上的資料。本文以開源巨量資料開發平台E-MapReduce(雲上Hadoop)方式類比本地Hadoop叢集,為您介紹如何讀寫MaxCompute資料。
背景資訊
實踐架構圖如下所示。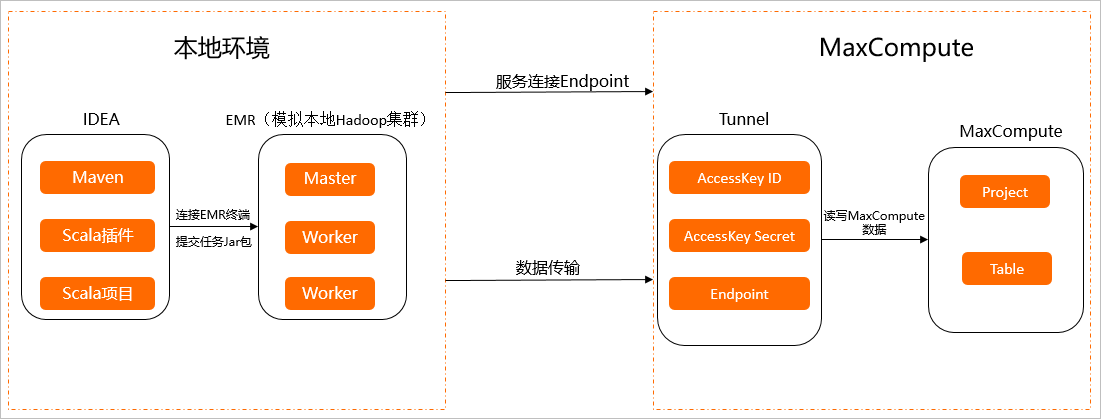
準備開發環境
- 準備E-MapReduce(EMR)環境。
- 購買EMR叢集。
詳情請參見E-MapReduce快速入門。
- 登入EMR叢集。說明 登入E-MapReduce叢集詳情請參見登入叢集。
本實踐登入ECS執行個體進行操作,串連ECS執行個體請參見串連ECS執行個體。
- 購買EMR叢集。
- 準備本地IDEA。
- 安裝IntelliJ IDEA。
本實踐在IntelliJ IDEA運行,需要安裝IntelliJ IDEA,詳情請參見Install IntelliJ IDEA。
- 安裝Maven。
詳情請參見安裝Maven。
- 建立Scala專案。
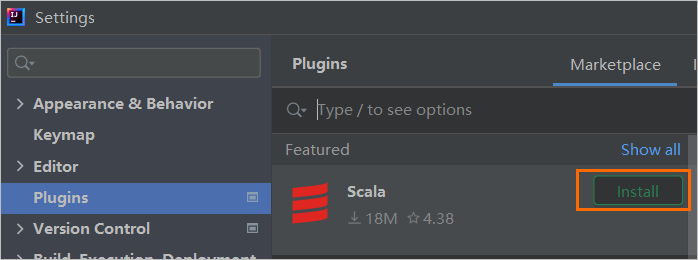
- 下載Scala外掛程式。開啟IDEA,選擇File>Settings。在Settings對話方塊左側導覽列單擊Plugins,單擊Scala後的Install。
- 安裝Scala JDK
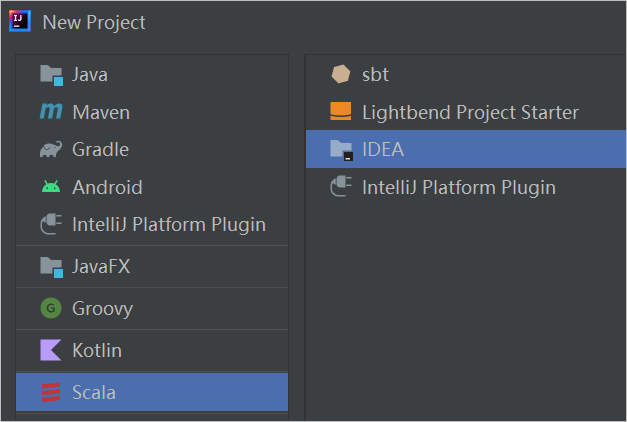
- 建立Scala專案在IDEA裡建立專案,選擇Scala>IDEA,即可建立Scala專案。
- 下載Scala外掛程式。
- 安裝IntelliJ IDEA。
- 準備MaxCompute資料
- 建立專案
MaxCompute建立Project請參見建立MaxCompute專案。
- 擷取AccessKey
您可以進入AccessKey管理頁面擷取AccessKey ID和AccessKey Secret。
- 擷取Endpoint
MaxCompute服務的串連地址。您需要根據建立MaxCompute專案時選擇的地區以及網路連接方式配置Endpoint。各地區及網路對應的Endpoint值,請參見Endpoint。
- 建立Table
本實踐需準備分區表和非分區表供測試使用,建立表詳情請參見建立表。
- 建立專案
讀寫MaxCompute資料
- 代碼開發。本實踐提供如下讀非分區表代碼開發樣本。說明 讀分區表、寫非分區表和寫分區表程式碼範例請參見PartitionDataReaderTest.scala、DataWriterTest.scala和PartitionDataWriterTest.scala,可以根據實際業務情況進行代碼開發。
/* * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ import org.apache.spark.sql.SparkSession /** * @author renxiang * @date 2021-12-20 */ object DataReaderTest { val ODPS_DATA_SOURCE = "org.apache.spark.sql.odps.datasource.DefaultSource" val ODPS_ENDPOINT = "http://service.cn.maxcompute.aliyun.com/api" def main(args: Array[String]): Unit = { val odpsProject = args(0) val odpsAkId = args(1) val odpsAkKey = args(2) val odpsTable = args(3) val spark = SparkSession .builder() .appName("odps-datasource-reader") .getOrCreate() import spark._ val df = spark.read.format(ODPS_DATA_SOURCE) .option("spark.hadoop.odps.project.name", odpsProject) .option("spark.hadoop.odps.access.id", odpsAkId) .option("spark.hadoop.odps.access.key", odpsAkKey) .option("spark.hadoop.odps.end.point", ODPS_ENDPOINT) .option("spark.hadoop.odps.table.name", odpsTable) .load() df.createOrReplaceTempView("odps_table") println("select * from odps_table") val dfFullScan = sql("select * from odps_table") println(dfFullScan.count) dfFullScan.show(10) Thread.sleep(72*3600*1000) } } - 代碼打包和上傳。
- Maven打包代碼。
- 在IDEA的代碼開發頁面右側邊欄,單擊Maven。
- 在Maven對話方塊,雙擊Lifecycle目錄下的package進行打包。
- 本地編譯jar包。
- 進入Project目錄。在系統的命令列執行視窗(例如Windows的cmd視窗)執行如下命令。
cd ${project.dir}/spark-datasource-v3.1 - 使用
mvn命令構建spark-datasource。mvn clean package jar:test-jar - 查看
target目錄下是否有dependencies.jar和tests.jar。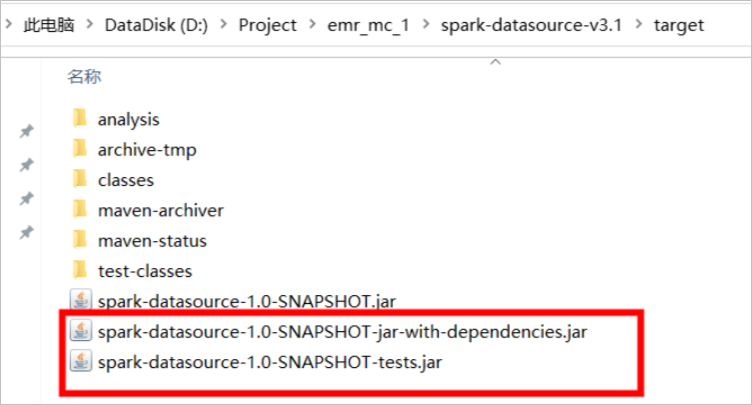
- 進入Project目錄。
- 上傳jar包至伺服器。
- 在本地使用
scp命令上傳已經打包好的jar包和依賴的jar包至伺服器,命令文法如下。
樣本如下。scp <本地jar包路徑> root@<ECS執行個體公網IP>:<伺服器存放jar包路徑>scp D:\Project\emr_mc_1\spark-datasource-v3.1\target\spark-datasource-1.0-SNAPSHOT-tests.jar root@8.xx.xx.xx:/root/emr_mc
- 查看jar包。在伺服器
emr_mc目錄下使用ll命令查看jar包。
- 使用如下命令在各節點之間上傳jar包。
scp -r [本伺服器存放jar包路徑] root@ecs執行個體私網IP:[接收的伺服器存放jar包地址]
- 在本地使用
- Maven打包代碼。
- 運行代碼。
- 運行模式。
- Local模式。
- 使用Local模式啟動並執行命令文法如下。
./bin/spark-submit \ --master local \ --jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \ --class DataReaderTest \ ${jar-path} \ ${maxcompute-project-name} \ ${aliyun-access-key-id} \ ${aliyun-access-key-secret} \ ${maxcompute-table-name} - 參數說明如下。
參數 說明 master 運行模式,取值如下。 - Local:運行代碼只調用當前ECS的計算資源。
- Yarn:運行代碼使用EMR叢集所有ECS的計算資源,運行效率比Local模式高。
jars 依賴的jar包路徑。 class 需要執行的類名稱。 jar-path 需要執行的jar包路徑。 maxcompute-project-name MaxCompute的專案(Project)名稱。 aliyun-access-key-id 阿里雲帳號或RAM使用者的AccessKey ID。 您可以進入AccessKey管理頁面擷取AccessKey ID。
aliyun-access-key-secret AccessKey ID對應的AccessKey Secret。 您可以進入AccessKey管理頁面擷取AccessKey Secret。
maxcompute-table-name 進行讀或寫的MaxCompute表名稱。
- 使用Local模式啟動並執行命令文法如下。
- Yarn模式。
- 使用yarn模式啟動並執行命令文法如下。
val ODPS_ENDPOINT = "http://service.cn-beijing.maxcompute.aliyun-inc.com/api" ./bin/spark-submit \ --master yarn \ --jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \ --class DataReaderTest \ ${jar-path} \ ${maxcompute-project-name} \ ${aliyun-access-key-id} \ ${aliyun-access-key-secret} \ ${maxcompute-table-name} - 參數說明如下。
參數 說明 master 運行模式,取值如下。 - Local:運行代碼只調用當前ECS的計算資源。
- Yarn:運行代碼使用EMR叢集所有ECS的計算資源,運行效率比Local模式高。
jars 依賴的jar包路徑。 class 需要執行的類名稱。 jar-path 需要執行的jar包路徑。 maxcompute-project-name MaxCompute的專案(Project)名稱。 aliyun-access-key-id 阿里雲帳號或RAM使用者的AccessKey ID。 您可以進入AccessKey管理頁面擷取AccessKey ID。
aliyun-access-key-secret AccessKey ID對應的AccessKey Secret。 您可以進入AccessKey管理頁面擷取AccessKey Secret。
maxcompute-table-name 進行讀或寫的MaxCompute表名稱。
- 使用yarn模式啟動並執行命令文法如下。
- Local模式。
- 讀非分區表示例。
- 命令文法如下。
-- 進入spark執行環境 cd /usr/lib/spark-current -- 提交任務 ./bin/spark-submit \ --master local \ --jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \ --class DataReaderTest \ ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \ ${maxcompute-project-name} \ ${aliyun-access-key-id} \ ${aliyun-access-key-secret} \ ${maxcompute-table-name} - 執行介面如下。
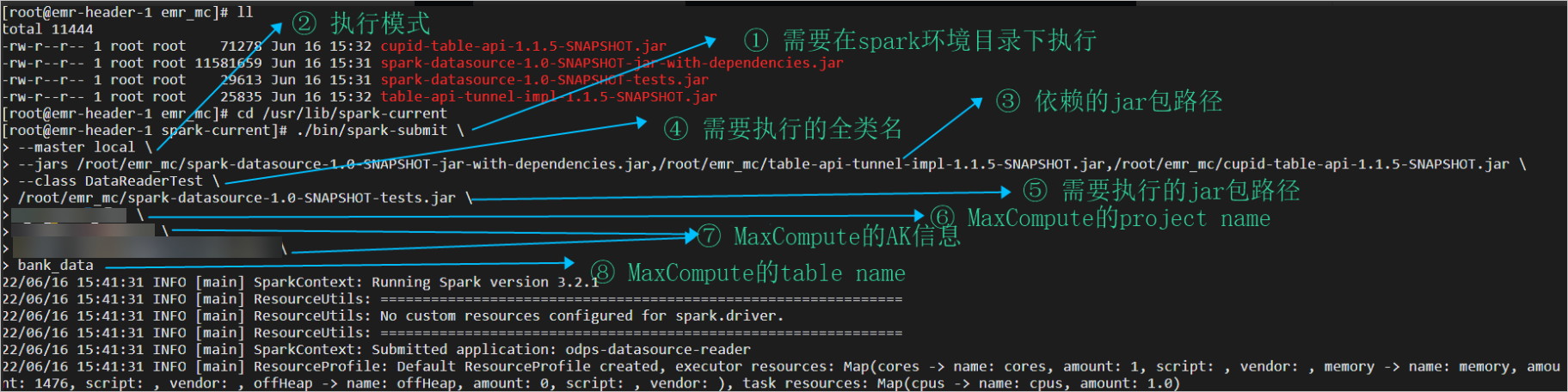
- 執行結果如下。
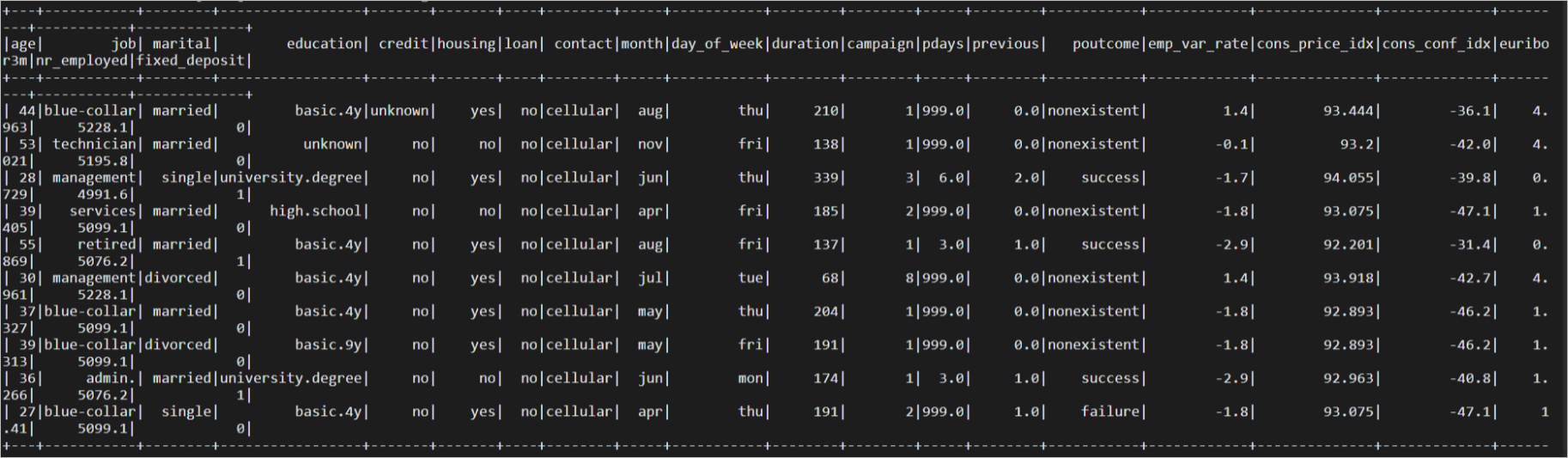
- 命令文法如下。
- 讀分區表示例。
- 命令文法如下。
-- 進入spark執行環境 cd /usr/lib/spark-current -- 提交任務 ./bin/spark-submit \ --master local \ --jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \ --class PartitionDataReaderTest \ ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \ ${maxcompute-project-name} \ ${aliyun-access-key-id} \ ${aliyun-access-key-secret} \ ${maxcompute-table-name} \ ${partition-descripion} - 執行介面如下。
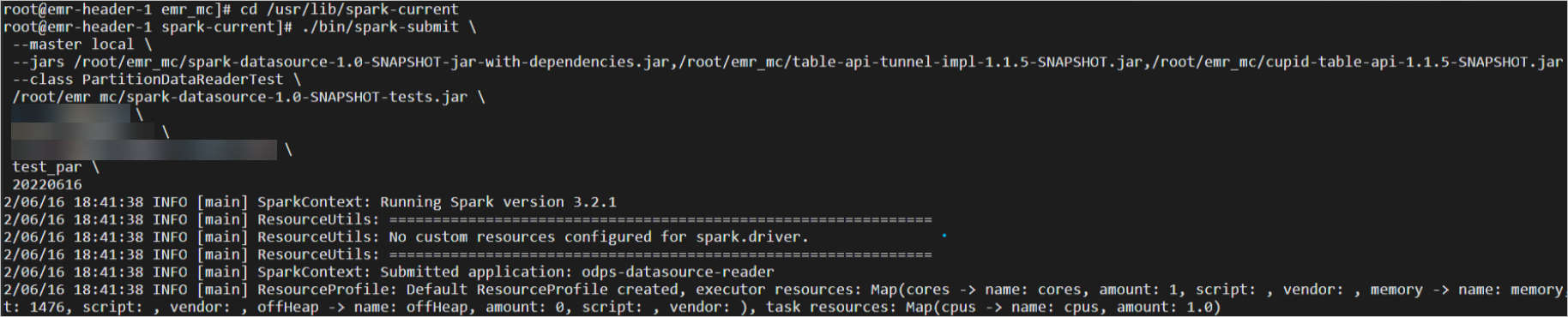
- 執行結果如下。
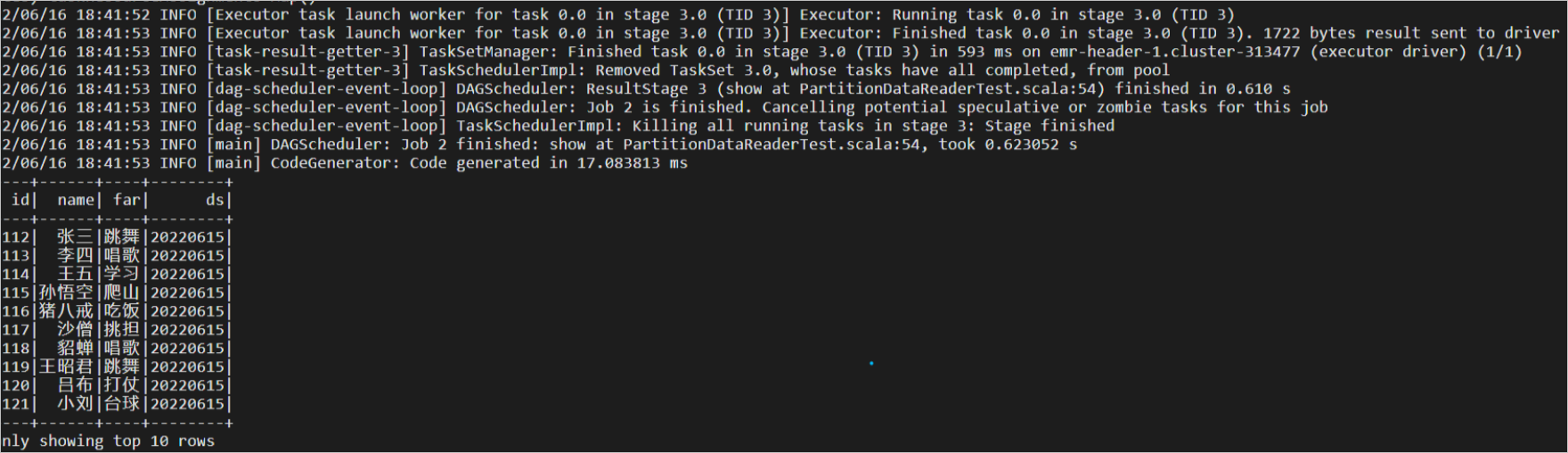
- 命令文法如下。
- 寫非分區表測試。
- 命令文法如下。
./bin/spark-submit \ --master local \ --jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \ --class DataWriterTest \ ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \ ${maxcompute-project-name} \ ${aliyun-access-key-id} \ ${aliyun-access-key-secret} \ ${maxcompute-table-name} - 執行介面如下。

- 執行結果如下。
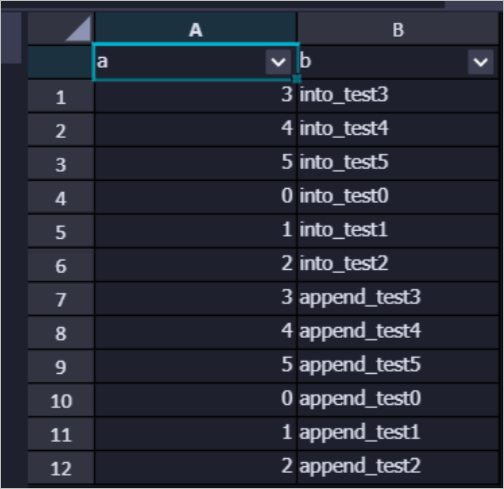
- 命令文法如下。
- 寫分區表測試。
- 命令文法如下。
./bin/spark-submit \ --master local \ --jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \ --class PartitionDataWriterTest \ ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \ ${maxcompute-project-name} \ ${aliyun-access-key-id} \ ${aliyun-access-key-secret} \ ${maxcompute-table-name} \ ${partition-descripion} - 執行介面如下。

- 執行結果如下。
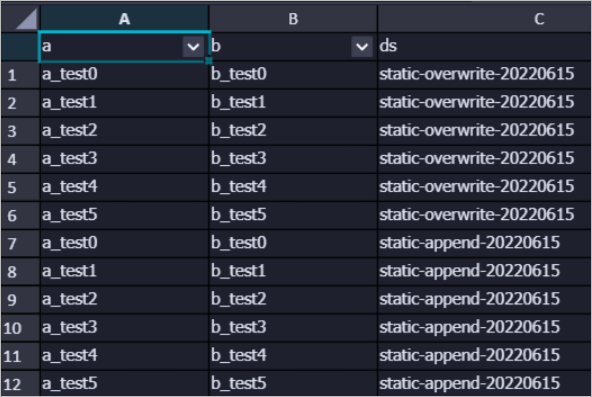
- 命令文法如下。
- 運行模式。
效能測試
本實踐效能測試環境是E-MapReduce和MaxCompute,屬於雲上互聯。如果IDC網路與雲上相連效能取決於tunnel資源或者專線頻寬。
- 執行個體規格。
執行個體 規格 E-MapReduce叢集 - Master節點數量:2個。
- ECS規格:計算型(ecs.c6.2xlarge)8 vCPU,16 GiB,2.5 Gbps。
- 系統硬碟:ESSD雲端硬碟 120GiB。
- 資料盤:ESSD雲端硬碟 80GiB。
- Core節點數量:2個。
- ECS規格:計算型(ecs.c6.2xlarge)8 vCPU,16 GiB,2.5 Gbps。
- 系統硬碟:ESSD雲端硬碟 120GiB。
- 資料盤:ESSD雲端硬碟 80GiB * 4。
MaxCompute 隨用隨付標準版。 - Master節點數量:2個。
- 大表讀測試。資料表規格如下。
結果如下。參數 規格 表名稱 dwd_product_movie_basic_info 說明 此表為MaxCompute公開資料集MAXCOMPUTE_PUBLIC_DATA專案下的表,詳情請參見公開資料集。表大小 4829258484 Byte。 分區數 593 個。 讀取的分區名稱 20170422。 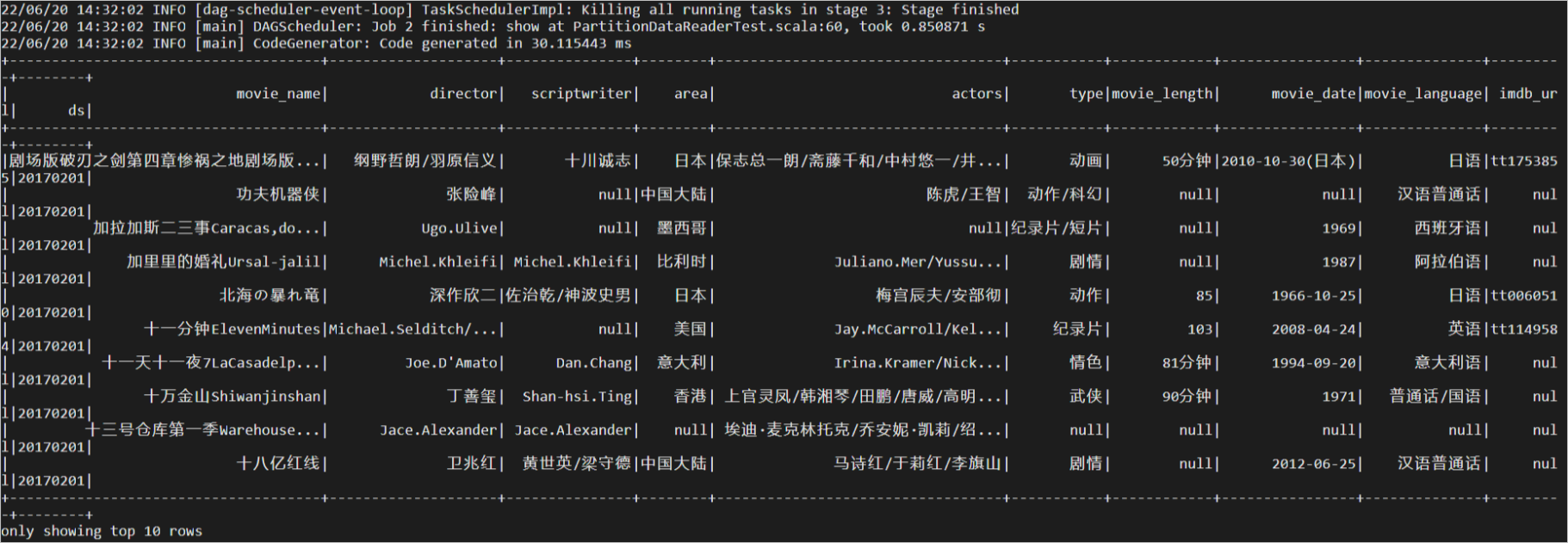 耗時 0.850871秒。
耗時 0.850871秒。 - 大表寫測試。
- 分區寫入萬條資料。
 耗時2.533892秒。
耗時2.533892秒。 - 分區寫入十萬條資料。
 耗時8.441193秒。
耗時8.441193秒。 - 分區寫入百萬條資料。
 耗時73.28秒。
耗時73.28秒。
- 分區寫入萬條資料。