MaxCompute提供資料移轉工具MMA(MaxCompute Migration Assist)4.0版本,允許您將其他資料來源(如Hive、BigQuery等)的資料通過MMA遷移至MaxCompute。本文為您介紹如何使用MMA 4.0進行資料移轉。
功能介紹
MMA(MaxCompute Migration Assistant) 是一款用於向MaxCompute遷移資料的工具。目前支援的資料來源如下:
Hive
DataBricks
BigQuery
使用MMA向MaxCompute遷移資料的大致流程如下:

遷移原理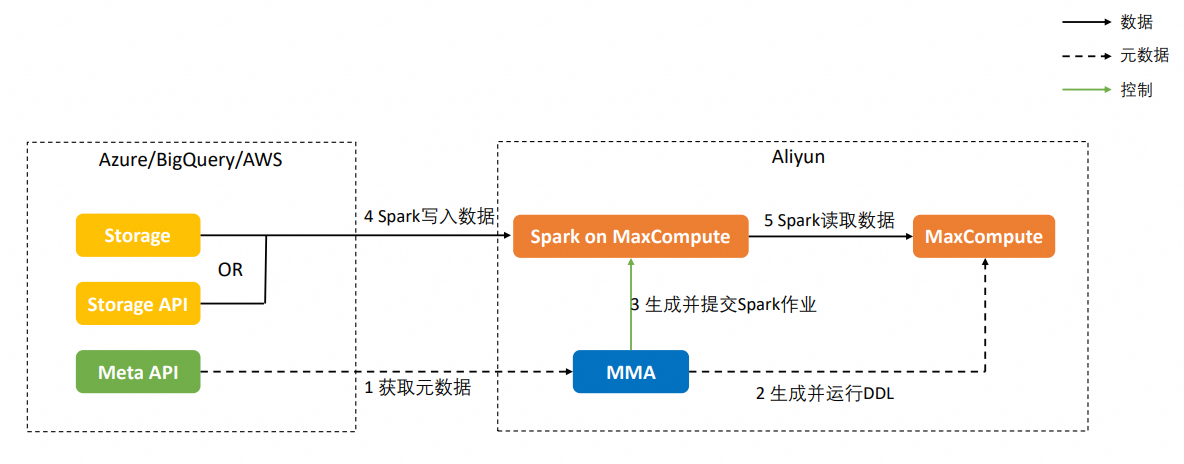
中繼資料遷移:
MMA通過中繼資料API擷取資料來源的中繼資料,具體是通過使用BigQuery SDK、Hive Metastore SDK、DataBricks SDK來調用API的。
MMA根據擷取到的中繼資料產生MaxCompute DDL語句,並在MaxCompute中執行DDL,完成中繼資料遷移。
資料移轉:
方式1:拉模式,MMA通過Spark作業指定要遷移的對象,Spark作業運行在MaxCompute上,從資料來源讀取資料,並將其寫入MaxCompute。對於不同的資料來源,Spark讀取資料的方式不同,具體如下:
資料來源
讀取資料方式
Bigquery
Read API
Hive on AWS s3
s3
Hive on HDFS
HDFS
方式2:推模式,MMA向資料來源提交SQL、Spark作業,作業運行在資料來源端,將資料從資料來源讀取後寫入到MaxCompute,具體實現如下:
資料來源
讀取資料方式
Hive
運行UDTF,通過Tunnel將資料寫入MaxCompute。
DataBricks
運行DataBricks Spark,通過Storage API將資料寫入MaxCompute。
MMA名詞解釋
MMA架構圖如下: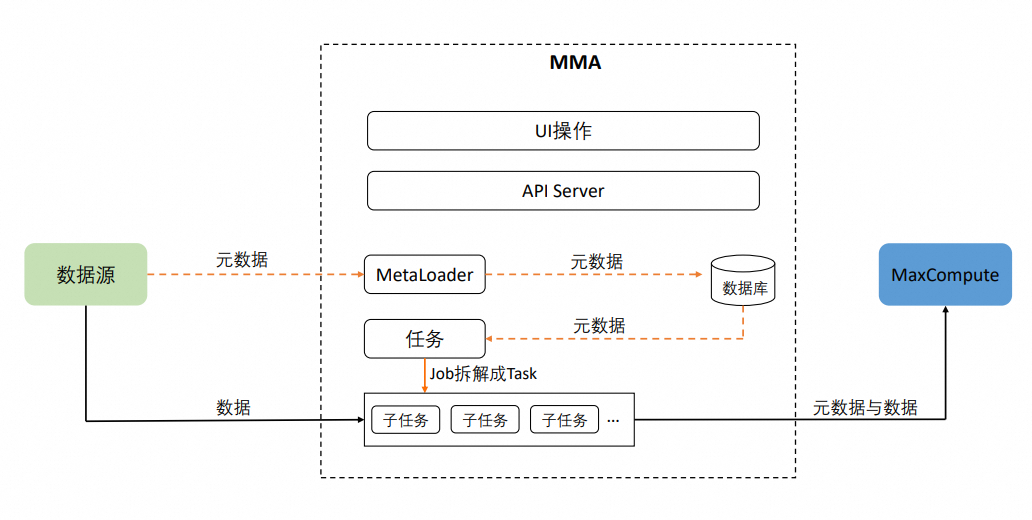
資料來源
要遷移的對象,例如Hive的一個或多個Database、 BigQuery的一個或多個Project、DataBricks的一個Catalog。不同的資料來源有不同的資料層級表示(如下表),目前MMA會將不同資料來源的資料層級映射為Database、Schema和Table三層表示,其中Schema作為Table的屬性存在。
資料來源 | 資料層級 |
Hive | Database、Table |
Bigquery | Catalog、Schema、Table |
Databricks | Project、Dataset、Table |
任務與子任務
MMA遷移操作的對象可以是一個Database,多個Table或多個partition。選定操作對象,並建立遷移任務後,MMA會產生任務與子任務,其中任務中包含了遷移操作的配置資訊(操作對象、遷移方法等)。任務會進一步被劃分為子任務,子任務是實際遷移操作的執行單元。一個子任務會對應一個非分區表或一個分區表的多個分區。子任務執行的過程包含遷移中繼資料、遷移資料和資料校正三個階段。
資料校正
MMA將資料移轉到MaxCompute後,會對資料進行校正。目前支援的校正方法比較簡單,即在源端和MaxCompute端分別執行SELECT COUNT(*)命令擷取操作對象(例如表或分區)的行數,然後進行對比。
前提條件
已建立MaxCompute專案。具體操作,請參見建立MaxCompute專案。
已為對應的使用者授予目標MaxCompute專案的如下操作許可權:
客體(Object)
許可權
Project
List、CreateTable、CreateInstance
Table
Describe、Select、Alter、Update、Drop
Instance
Read、Write
關於具體的授權方案可以參考授權方案,或者直接將admin角色綁定到阿里雲帳號。操作過程如下:
進入MaxCompute控制台專案管理頁面,在左上方選擇地區。
單擊目標專案操作列的管理,進入專案配置頁面。
切換至角色許可權頁簽,然後單擊admin角色操作列的成員管理,將admin角色賦予相應的使用者。
已準備如下作業環境:
作業系統:
需準備Linux作業系統。
系統配置:若表的分區數≤500W,建議使用8核16 GB的配置,若表的分區數>500W,則需要更高的配置。
JDK版本需要為Java 8或者Java 11。
MySQL需要為V5.7或以上版本。
使用限制
BigQuery遷移限制如下:
資料類型
暫不支援BIGNUMERIC、JSON、INTERVAL、GEOGRAPHY和RANGE類型。
遷移時,TIME類型會被轉換為STRING類型。
表Schema
表名和列名僅支援長度小於或等於128的大小寫字母、數字和底線。
表中列的數量上限為1200。
安裝與配置
進入MMA_Releases,根據不同的資料來源類型選擇對應的
mma-<3.x.x>-<datasource>.jar,例如mma-3.1.0-bigquery.jar。單擊下載lib.zip檔案並解壓。
建立一個名config.ini的檔案,並添加如下參數配置,樣本config.ini檔案內容如下:
[mysql] host = mysql-host port = 3306 ; can be any database name db = mmav3 username = user password = pass [mma] listening_port = 6060參數說明:
類別
參數名
描述
mysql
host
登入MySQL所使用的IP地址。
port
MySQL伺服器的連接埠號碼,預設為3306。
db
MySQL資料庫名稱。
username
MySQL資料庫的登入使用者名稱。
password
MySQL資料庫的登入密碼。
mma
listening_port
MMA所在伺服器的監聽連接埠號碼,預設為6060。
將檔案目錄調整為如下結構:
/path/to/mma | ├── mma-3.1.0-<datasource>.jar # MMA 主程式 ├── config.ini # MMA設定檔 └── lib/ └── spark/ # Spark 遷移任務依賴目錄 ├── log/ # 程式運行時自動產生,spark 提交日誌 ├── spark-3.1.1-odps0.34.1/ # Maxcompute Spark-3.1.1 依賴 ├── bigquery-spark-job.jar # Spark 遷移任務 └── mma-spark-client.jar # Spark 提交程式
運行程式
您可以通過命令啟動MMA程式,並訪問MMA頁面,也可停止MMA。
運行程式時,您需將下述命令中的<datasource>替換為相應的資料來源類型。
啟動MMA
建議使用nohup啟動程式,啟動命令如下。
nohup java -jar mma-3.1.0-<datasource>.jar -c config.ini > nohup.log 2>&1 &停止MMA
如果需要停止MMA程式,可以使用如下命令直接終止已經啟動的MMA程式。停止MMA程式會導致正在啟動並執行遷移任務中斷,但是重新啟動MMA後,被中斷的任務會被重新執行,並且不影響最終的遷移結果。
ps aux | grep mma-3.1.0-<datasource>.jar | grep -v grep | awk '{print $2}' | xargs kill -9訪問MMA
MMA程式啟動後,您可瀏覽器端輸入http://拉起服務的ip:6060(6060通過config.ini中的listening_port進行配置)訪問MMA。瀏覽器開啟MMA後,您需要在MMA配置頁面配置以下參數:
MMA目前沒有提供訪問認證,您需要通過網路原則限定MMA的訪問。比如,如果MMA運行在阿里雲ECS上,需要通過ECS的安全性群組來控制哪些IP可以訪問MMA。
配置項 | 配置說明 |
mc.endpoint | 用於MMA訪問MaxCompute的Endpoint,要求MMA所在伺服器能夠連通mc.endpoint,具體的Endpoint資訊可以參考Endpoint。 |
mc.data.endpoint | (可選)通過Hive UDTF遷移資料時⽤於UDTF訪問MaxCompute,此時要求Hive叢集的節點能夠連通該地址。 |
mc.tunnel.endpoint | (可選)通過Hive UDTF遷移資料時用於UDTF訪問MaxCompute,此時要求Hive叢集的節點能夠連通該地址。 |
mc.auth.access.id | ⽤於訪問MaxCompute的AccessKey ID。 您可以進入AccessKey管理頁面擷取AccessKey Secret。 |
mc.auth.access.key | 用於訪問MaxCompute的AccessKey Secret。 |
mc.default.project | MMA會使⽤該項⽬的配額在MaxCompute上執⾏SQL命令。 |
mc.tunnel.quota | (可選)通常用不到,可忽略。 |
mc.projects | 要遷往的MaxCompute項⽬名列表。多個項⽬名之間以英⽂逗號分隔。 |
task.max.num | 用於遷移資料的MMA任務最大並發數,該參數是調節遷移速度的重要參數之一。 |
auth.type | (可選)僅用於通過Hive UDTF遷移Hive資料。
|
auth.ak.hdfs.path | (可選)當 |
spark.dependency.root | Spark依賴根目錄。 |
不同資料來源的遷移操作
目前僅支援遷移BigQuery資料。
遷移BigQuery
添加資料來源
在資料來源頁面右側,單擊添加資料來源,進入添加資料來源頁面。
資料來源類型選擇BIGQUERY,並單擊下一步。
根據如下參數說明配置資料來源。
參數名稱
描述
資料來源名稱
資料來源名稱,可自訂,不能包含字元、數字、漢字之外的特殊字元。
BigQuery service account key file json
通過BigQuery IAM控制台建立服務帳號,下載鑒權JSON,詳情請參見服務帳號概述。
BigQuery project name
服務帳號授權的專案名。
定界分割表(Range Partition Table)遷移方式
BigQuery定界分割表遷移方式,當前只支援遷移到MaxCompute分區表。
預設值為Partition。
時間單位列分區表(Time-unit Column-partitioned Table)是否保留分區列作為普通列,預設保留
BigQuery單位列分區表,是否保留分區列作為普通列儲存到MaxCompute。
預設保留。
注入時間分區表(Ingestion-time Partitioned Table)是否保留偽列作為普通列,預設不保留
BigQuery注入時間分區表,是否保留偽列作為普通列儲存到MaxCompute。
預設為false(不保留)。
MaxCompute Spark NetworkLink Name: region:name
網路連接名稱,詳情請參見網路開通流程的“訪問VPC方案(專線直連)”部分。
配置格式為
<regionId>:<vpcId>。樣本:如果VPC ID為vpc-uf68aeg673p0k********,Region為上海,則此處應配置為cn-hanghai:vpc-uf68aeg673p0k********。關於Region和RegionId對應關係,請參見地區與地區ID的對應關係。定時更新
配置資料來源中繼資料定時拉取,有以下兩種定時方式:
每天:定時器每天運行一次,運行時刻為選定的24小時內的某一時間(精確到分鐘)。
每小時:定時器每小時運行一次,運行時刻為選定的60分鐘內的某一分鐘。
meta api訪問並發量
訪問資料來源中繼資料API的並發量,預設值為10。
資料庫白名單
需要遷移的BigQuery資料庫,多個值之間以英文逗號分隔。
資料庫黑名單
不需要遷移的BigQuery資料庫,多個值之間以英⽂逗號分隔。
表黑名單, 格式為db.table
不需要遷移的BigQuery資料庫表。單個表的格式為
dbname.tablename,多個表之間以英文逗號分隔。表白名單, 格式為db.table
需要遷移的BigQuery資料庫表。單個表的格式為
dbname.tablename,多個表之間以英文逗號分隔。
更新資料來源
若資料來源的中繼資料有變動,您需要在MMA的資料來源頁面,單擊目標資料來源操作列的更新,以手動更新資料來源並拉取最新中繼資料。
修改資料來源配置
您也可以修改資料來源的相關配置,操作如下:
在MMA的資料來源頁面,單擊目標資料來源的名稱,進入資料來源詳情頁面。
在配置資訊頁簽修改資料來源的相關配置。
建立遷移任務
遷移多個Table
在MMA的資料來源頁面,單擊目標資料來源名稱,進入資料來源詳情頁面。
在資料資訊頁簽,單擊目標庫名,進入資料庫詳情頁面。
在資料庫詳情頁面的Table列表頁簽,選中要遷移的表,然後單擊建立遷移任務。
在建立遷移任務對話方塊中配置如下參數,並單擊確定。
參數名
描述
名稱
任務名稱。
任務類型
遷移方式,通過BigQuery Storage Read API進行資料移轉。
MC專案
資料移轉的目標Maxompute專案。
MC Schema
可選,目標MaxCompute專案下的Schema。Schema詳情請參見Schema操作。
table列表
要遷移的Table名稱列表,多個Table名稱之間以英文逗號分隔。
只遷新分區
如果開啟,則建立任務將忽略已經遷移成功的分區。
定時執行
配置任務定製執行,定時方式有兩種
每天:定時器每天運行一次,運行時刻為選定的24小時內的某一時間(精確到分鐘)。
每小時:定時器每小時運行一次,運行時刻為選定的60分鐘內的某一分鐘。
只遷Schema
只在MaxCompute建立相應的表和分區, 不遷移資料。
開啟校正
如果開啟,MMA將在源、目標端分區執行
select count(*)擷取遷移對象的行數,根據行數驗證資料是否遷移成功。合并分區
通常用不到,可忽略。
分區過濾
詳情請參見分區過濾運算式說明。
表名映射
一個Table遷移到目標MaxCompute Project後的名稱。
列名映射
Table列名中遷移到MaxCompute後的名稱。
表名映射規則
表名映射配置需要對每個表分別進行配置,如果要遷移的多個表在遷移到MaxCompute後,名稱變動方式是固定的,可以使用該配置。
配置格式為
prefix${table}suffix。例如:該項值為pre_${table}_1時,如果源表名為test,則遷移到MaxCompute後,表名將會為pre_test_1。prefix和suffix可以為空白。進入遷移任務>工作清單,可對已建立的遷移任務進行管理。具體請參見遷移任務管理。
遷移單個Database
在MMA的資料來源頁面,單擊目標資料來源名稱,進入資料來源詳情頁面。
在資料資訊頁簽,單擊目標庫名操作列的遷移。
在建立遷移任務對話方塊中配置如下參數:
參數名
描述
名稱
任務名稱。
任務類型
遷移方式,選擇通過Bigquery Storage Read API 進行資料移轉。
MC專案
資料移轉的目標MaxCompute專案。
MC Schema
可選,目標MaxCompute專案下的Schema。Schema詳情請參見Schema操作。
table白名單
要遷移的table名稱列表,如果不為空白,則只會遷移該列表內的table。
table黑名單
黑名單內的table將不會被遷移。
只遷新分區
如果開啟,則建立任務將忽略已經遷移成功的分區。
定時執行
配置任務定製執行,定時方式有兩種
每天:定時器每天運行一次,運行時刻為選定的24時內的某一時間(精確到分鐘)。
每小時:定時器每小時運行一次,運行時刻為選定的60分鐘內的某一分鐘。
只遷Schema
只在MaxCompute建立相應的表、分區,不遷移資料。
開啟校正
如果開啟,MMA將在源、目標端分區執行
select count(*)擷取遷移對象的行數,根據行數驗證資料是否遷移成功。合并分區
通常用不到,可忽略。
分區過濾
詳情請參見分區過濾運算式說明。
表名映射
一個table遷移到目標MaxCompute Project後的名稱。
列名映射
table列名中遷移到MaxCompute後的名稱。
表名映射規則
表名映射配置需要對每個表分別進行配置,如果要遷移的多個表在遷移到MaxCompute後,名稱變動方式是固定的,可以使用該配置。
配置格式為
prefix${table}suffix。例如:該項值為pre_${table}_1時,如果源表名為test,則遷移到MaxCompute後,表名將會為pre_test_1。prefix和suffix可以為空白。進入遷移任務>工作清單,可對已建立的遷移任務進行管理。具體請參見遷移任務管理。
遷移任務管理
管理工作
在MMA的頂部功能表列單擊遷移任務>工作清單,可進入工作清單頁面查看所有狀態的任務,您可針對不同狀態下的任務執行刪除、停止、啟動和重試等操作。
管理子任務
您可在子任務列表頁面管理所有子任務。
進入子任務列表頁面,有如下兩種方式:
在MMA的頂部功能表列單擊遷移任務>子任務列表,可進入子任務列表頁面查看所有任務的子任務。
在工作清單頁面,單擊目標任務名,也可進入該任務的子任務列表頁面。
您可在過濾欄根據任務名、資料來源、源庫、源表及狀態等條件對子任務進行過濾。
單擊目標子任務操作列的詳情,可查看或下載該子任務的執行日誌。
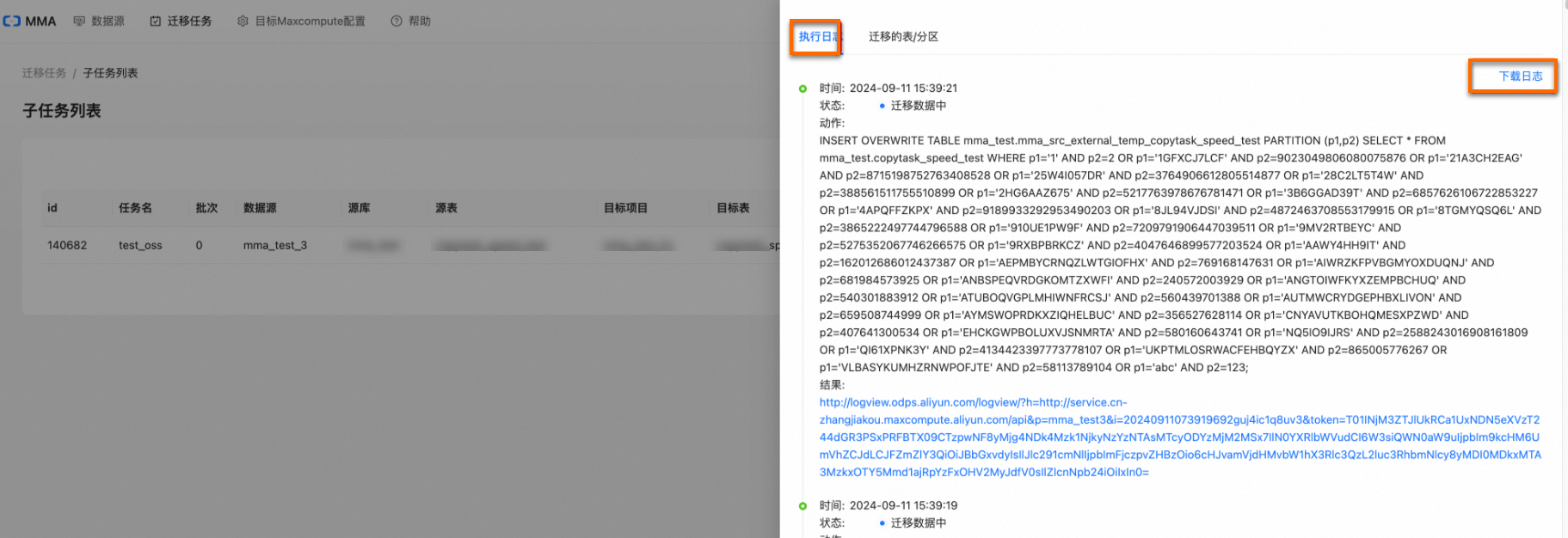
對於狀態為遷移資料失敗的子任務,您可執行重試或重新運行操作。
子任務的運行會涉及遷移Schema、遷移資料、資料校正三個階段,如果某個子任務“遷移資料”失敗,執行重試操作時,子任務會重新執行“遷移資料”操作;執行重新運行操作時,子任務會從“遷移Schema”開始重新運行。
附錄
分區過濾運算式說明
此處以一個具體樣本為您介紹分區過濾運算式的含義,如:p1 >= '2022-03-04' and (p2 = 10 or p3 > 20) and p4 in ('abc', 'cde')。
樣本說明:
p1、p2和p3均為分區名。
分區值僅包含字串和數字,字串被雙引號或單引號包裹。除INT/BIGINT類型的分區列值外,其他類型的分區值都只能取字串值。
比較操作符包括:
>、>=、= 、<、<=、<>。分區過濾運算式支援
IN操作符。邏輯操作符包括:
AND和OR。支援使用括弧。
地區與地區ID的對應關係
地區 | RegionID |
華東1(杭州) | cn-hangzhou |
華東2(上海) | cn-shanghai |
華北2(北京) | cn-beijing |
華北3(張家口) | cn-zhangjiakou |
華北6(烏蘭察布) | cn-wulanchabu |
華南1(深圳) | cn-shenzhen |
西南1(成都) | cn-chengdu |
中國香港 | cn-hongkong |
華東 2 金融雲 | cn-shanghai-finance-1 |
華北 2 阿里政務雲 1 | cn-north-2-gov-1 |
華南 1 金融雲 | cn-shenzhen-finance-1 |
日本(東京) | ap-northeast-1 |
新加坡 | ap-southeast-1 |
馬來西亞(吉隆坡) | ap-southeast-3 |
印尼(雅加達) | ap-southeast-5 |
德國(法蘭克福) | eu-central-1 |
英國(倫敦) | eu-west-1 |
美國(矽谷) | us-west-1 |
美國(維吉尼亞) | us-east-1 |
阿聯酋(杜拜) | me-east-1 |